数据仓库含义,架构,ETL以及数据仓库的建模
数据仓库
- 一.为什么学习数据仓库(DB)
- 二.什么是数据仓库
-
- 1.面向主题
- 2.集成
- 3.非易失
- 4.随时间变化
- 三.数据仓库和数据库的区别
-
- 1.数据库和数据仓库
- 2.OLTP和OLAP的区别
- 四.数据仓库的架构
-
- 1.Inmon架构
- 2.Kimball架构
- 3.混合型架构
- 五.数据仓库的解决方案
- 六.ETL
-
- 1.ETL含义
- 2.ETL工具
- 七.数据仓库的建模
-
- 1.选择业务流程
- 2.声明粒度
- 3.确认维度
- 4.确认事实
- 八.星型模型和雪花模型
-
- 1.星型模型
-
- (1)星型模型特点
- (2)优点
- (3)缺点
- 2.雪花模型
-
- (1)雪花模型特点
- (2)优点
- (3)缺点
瀑布式开发
3w1h(why,what,where,how)
一.为什么学习数据仓库(DB)
- 数据不兼容, 很难被整合(比如:F/M,女/男进行整合)
- 战略决策需要数据的分析(通过对数据进行分析,获取有效的信息)
- 推荐系统
二.什么是数据仓库
数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合
1.面向主题
- 主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念
- 每一个主题基本对应一个宏观的分析领域
- 在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象
例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”
提取主题
一个面向事务处理的“商场”数据库系统,其数据模式如下
采购子系统:
订单(订单号,供应商号,总金额,日期)
订单细则(订单号,商品号,类别,单价,数量)
供应商(供应商号,供应商名,地址,电话)
销售子系统:
顾客(顾客号,姓名,性别,年龄,文化程度,地址,电话)
销售(员工号,顾客号,商品号,数量,单价,日期)
库存管理子系统:
领料单(领料单号,领料人,商品号,数量,日期)
进料单(进料单号,订单号,进料人,收料人,日期)
库存(商品号,库房号,库存量,日期)
库房(库房号,仓库管理员,地点,库存商品描述)
人事管理子系统:
员工(员工号,姓名,性别,年龄,文化程度,部门号)
部门(部门号,部门名称,部门主管,电话)
在每个主题当中,包含了相关主题的所有信息,又同时抛弃了与分析处理无关的数据
主题:销售
固有信息:员工号,顾客号,商品号,数量,单价,日期
员工信息:员工号,姓名,性别,年龄,文化程度,部门号
顾客信息:顾客号,姓名,性别,年龄,文化程度,地址,电话
商品信息:商品号,商品名称,单价,重量,体积…
2.集成
- 集成性是指数据仓库中数据必须是一致的
数据仓库的数据是从原有的分散的多个数据库、数据文件和数据段中抽取来的
数据来源可能既有内部数据又有外部数据
例如F/M,0/1,A/B - 集成方法
统一:消除不一致的现象
综合:对原有数据进行综合和计算
3.非易失
- 数据仓库中的数据是经过抽取而形成的分析型数据
不具有原始性
主要供企业决策分析之用
执行的主要是‘查询’操作,一般情况下不执行‘更新’操作
一个稳定的数据环境也有利于数据分析操作和决策的制订
4.随时间变化
数据仓库以维的形式对数据进行组织,时间维是数据仓库中很重要的一个维度
不断增加新的数据内容
不断删去旧的数据内容
更新与时间有关的综合数据
三.数据仓库和数据库的区别
1.数据库和数据仓库
- 数据库是为捕获和存储数据而设计 前端
- 数据仓库是为分析数据而设计 内部
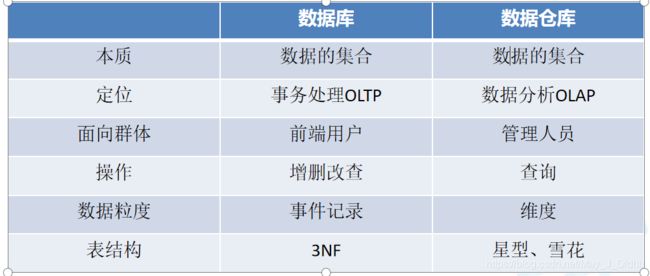
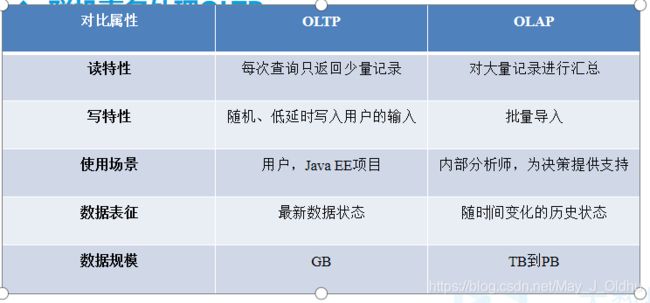
2.OLTP和OLAP的区别
- 联机事务处理OLTP(On-Line Transaction Processing)
OLTP是传统的关系型数据库的主要应用
主要是基本的、日常的事务处理
例如银行交易 - 联机分析处理OLAP(On-Line Analytical Processing)
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结
练习2:OLAP和OLTP
关于OLAP和OLTP的区别描述, 不正确的是(C )
A. OLAP主要是关于如何理解聚集的大量不同的数据. 它与OLTP应用程序不同
B. 与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务
C. OLAP的特点在于事务量大, 但事务内容比较简单且重复率高
D. OLAP是以数据仓库为基础的, 但其最终数据来源与OLTP一样均来自底层的数
四.数据仓库的架构
1.Inmon架构
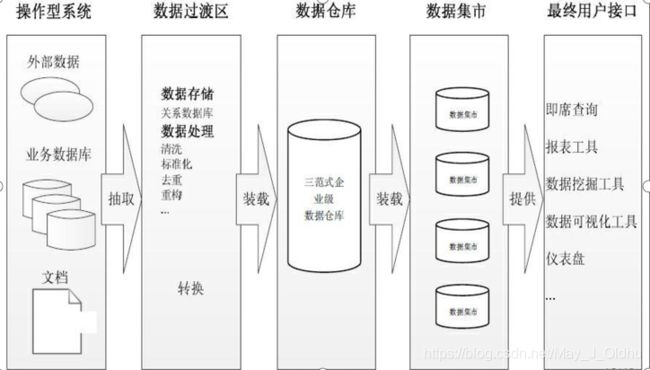
最早的数据仓库是使用关系数据库作为数据仓库
hive只是为数据仓库提供了一种解决方案,并不能说hive是数据仓库
2.Kimball架构
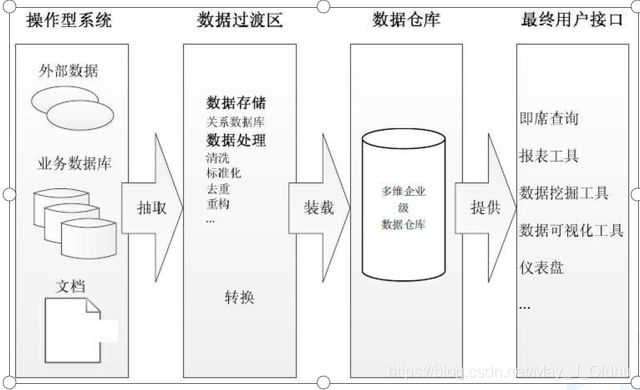
3.混合型架构
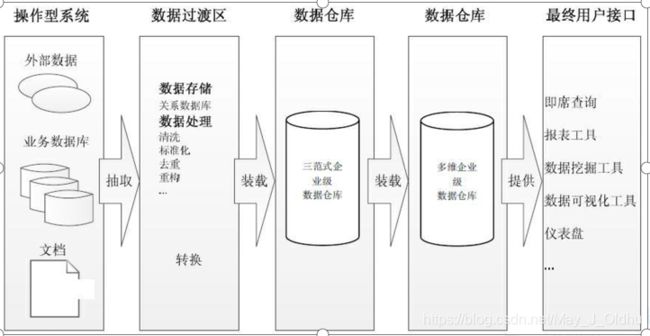
五.数据仓库的解决方案
- 数据采集
Flume,Sqoop,Logstash,Datax - 数据存储
MySQL,HDFS,HBase,Redis,MongoDB - 数据计算
Hive,Tez,Spark,Flink,Storm,Impala - 数据可视化
Tableau,Echarts,Superset,QuickBI,DataV - 任务调度
Oozie,Azkaban,Crontab
六.ETL
1.ETL含义
- 抽取(Extract)
从操作型数据源获取数据(采集) - 转换(Transform)
转换数据,使之转变为适用于查询和分析的形式和结构 - 装载(Load)
将转换后的数据导入到最终的目标数据仓库
2.ETL工具
- Oracle
OWB和ODI - 微软
SQL Server Integration Services - SAP
Data Integrator - IBM
InfoSphere DataStage、Informatica - Pentaho
Kettle
七.数据仓库的建模
数据仓库模型构建
选择业务流程
声明粒度
确认维度
确认事实
1.选择业务流程
选择业务流程
确认主题,建表
- 确认哪些业务处理流程是数据仓库应该覆盖的
例如:了解和分析一个零售店的销售情况 - 记录方式
使用纯文本
使用业务流程建模标注(BPMN)方法
使用同一建模语言(UML)
2.声明粒度
- 用于确定事实中表示的是什么
例如:一个零售店的顾客在购物小票上的一个购买条目 - 选择维度和事实前必须声明粒度
- 建议从原始粒度数据开始设计
原始记录能够满足无法预期的用户查询 - 不同的事实可以有不同的粒度
3.确认维度
- 说明了事实表的数据是从哪里采集来的
- 典型的维度都是名词
例如:日期、商店、库存等 - 维度表存储了某一维度的所有相关数据
例如:日期维度应该包括年、季度、月、周、日等数据
4.确认事实
- 识别数字化的度量,构成事实表的记录
- 和系统的业务用户密切相关
- 大部分事实表的度量都是数字类型的
可累加,可计算
例如:成本、数量、金额
事实表和维度表
举例:张三昨天在京东某家店买了一个ipad,花了3000
解析成事实表:
事实表:用户,日期,商家,商品,数量,金额
指向别的表:维度表,
用户:用户id:1001,用户姓名:张三,用户年龄:20,用户性别:M
日期表:日期id:1001 日期:20200901,周几:周一,一年中的第几天:325…
商家:商家id:1001,店铺名称:xxxx,店铺位置:xxxx,
商品表:商品id,商品名称:xxxx,一级类别:xxx,二级类别:xxx,品牌:xxx
八.星型模型和雪花模型
1.星型模型
(1)星型模型特点
- 由事实表和维度表组成
- 一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维度表
- 星型模式将业务流程分为事实和维度
- 事实包含业务的度量,是定量的数据
如销售价格、销售数量、距离、速度、重量等是事实 - 维度是对事实数据属性的描述
如日期、产品、客户、地理位置等是维度
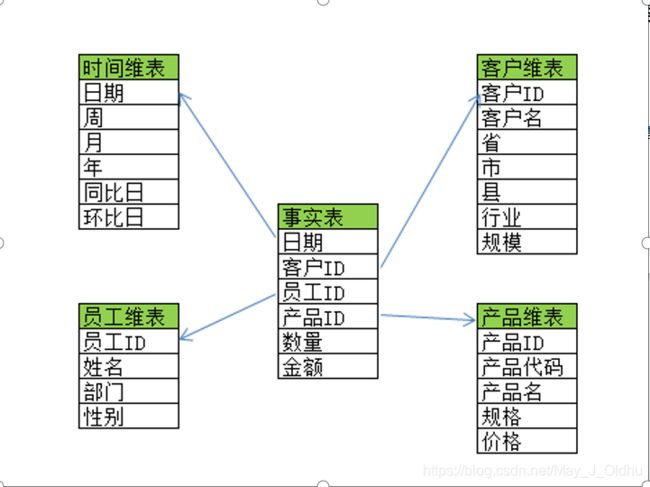
- 事实包含业务的度量,是定量的数据
(2)优点
简化查询
简化业务报表逻辑
获得查询性能
快速聚合
便于向立方体提供数据
(3)缺点
不能保证数据完整性
对于分析需求来说不够灵活
2.雪花模型
(1)雪花模型特点
- 一种多维模型中表的逻辑布局
- 由事实表和维度表所组成
- 将星型模式中的维度表进行规范化处理
把低基数的属性从维度表中移除并形成单独的表 - 一个维度被规范化成多个关联的表

(2)优点
一些OLAP多维数据库建模工具专为雪花模型进行了优化
规范化的维度属性节省存储空间
(3)缺点
维度属性规范化增加了查询的连接操作和复杂度
不确保数据完整性