如何保证Redis缓存和数据库的双写一致性?
在数据库+缓存模式下,当数据库中的数据需要更新时,缓存里的数据怎么处理?如何保证缓存和数据库中数据的一致性?常用的解决方案有两种(其他渣渣的方案这里不讨论):
1、先删除缓存,再更新数据库;
2、先更新数据库,再删除缓存;
下面我们就来看一下这两种方案,看看它们是怎么保证数据一致性的?
一、先删除缓存,再更新数据库
理想的流程是这样的:先删除缓存,再更新数据库,更新完数据库后,当有请求进来的时候发现缓存中没有数据,于是去查数据库,读取到更新后的新数据放回缓存再返回。这只是理想化的流程,如果只是简单的这样做,我们看看会存在什么问题呢?
在高并发场景下,假设有两个线程,线程A先删除缓存,再去更新数据库,在线程A删除缓存成功但更新数据库还未提交的时候,进来了一个线程B读取数据,发现缓存中没有数据,于是去读数据库,这时B读到的是旧数据,然后再将这个旧数据放回缓存,等A更新数据库完成以后,数据库和缓存中的数据就是不一致的。如果该缓存还没有设置过期时间,那这个数据将一直脏下去。
这个问题可以用"延时双删策略"来解决,A线程先删除缓存,再更新数据库,数据库更新完成后休眠200ms,再次删除缓存,这样做的目的就是保证中间产生的脏数据最后被再次删除。但这个200ms要根据自己的业务情况来确定。
还有一个问题,在延时双删策略第二次删除缓存的时候删除失败怎么办?这种情况可以提供一个"重试保障机制",如果删除失败,可以将删除失败的key发送到消息队列,再次重试操作。
二、先更新数据库,再删除缓存
理想的流程是这样的:先更新数据库,再删除缓存,当再有请求进来的时候发现缓存中没有数据,于是去查数据库,再将更新后的新数据放到缓存返回。
这种策略就是典型的“Cache Aside 模式”,更新缓存的设计模式有四种:Cache aside, Read through, Write through和Write behind caching。这四种模式并不仅仅适用于数据库和缓存之间的更新,它们设计的初衷是基于计算机体系结构的,比如CPU的缓存,硬盘文件系统中的缓存,硬盘上的缓存,数据库中的缓存等。所以,它们都是非常权威的,而且历经了长时间考验的最佳实践,我们直接遵从就可以了,没必要重复造轮子。
推荐阅读:《缓存更新的套路-https://coolshell.cn/articles/17416.html》
FaceBook在论文《Scaling Memcache at Facebook》中说过,他们采用的就是Cache Aside 策略。
※ 先更新数据库,再删除缓存有什么问题?
1、并发问题
从理论上来讲,Cache Aside也有可能发生并发问题,假设有两个线程,A线程读取数据,没有命中缓存,然后就去查数据库,在A查询数据库还没有返回结果的时候,另一个线程B执行一个写操作,更新完数据库后,让缓存失效(实际上这时候缓存已经是失效的,因为A在读的时候就没有命中缓存),然后,之前的线程A读取数据库返回了结果,再把老的数据放进缓存,这时候缓存中放得是A读出来的老数据,而数据库中存的是B更新后的新数据,数据库和缓存数据不一致。
这种情况理论上会出现,不过,实际上出现的概率可能非常非常低。因为上述并发场景的出现,需要同时具备条件:1、某线程在读缓存时缓存失效了,而且刚好并发着有一个写操作;2、读操作在写操作之前开始,在写操作之后结束,也就是说读操作的耗时大于写操作;出现这种场景的概率还是很低的。
如果要解决Cache Aside的并发问题,可以通过2PC或是Paxos协议保证一致性,或者尽力的降低并发时脏数据的概率,而Facebook使用的就是降低概率的玩法,因为2PC太慢,而Paxos太复杂。
2、数据库更新成功,删除缓存失败怎么办?
如果发生这种情况,数据库中存放的是更新后的数据,缓存因为没有删除成功存放的还是老数据,这个问题怎么解决呢,我们可以提供一种保障性的"重试机制"。
方案一、基于MO实现
 (1).更新数据库数据;
(1).更新数据库数据;
(2).删除缓存失败;
(3).当删除缓存数据失败时,应用程序发送消息,将需要删除的 Key 发送到MQ中;
(4).应用程序自己消费消息;
(5).应用接收到消息后,再次尝试删除缓存,如果再次删除失败,可重发消息多次尝试;
方案二,基于 阿里Canal 实现
Canal是阿里开发的基于数据库增量日志解析,提供增量数据的订阅&消费的中间件,目前主要支持MySQL的binlog解析。从下图可以看出,基于Canal的实现方案完全避免了对业务代码的侵入,核心业务代码只管更新数据库,其他的不用care。
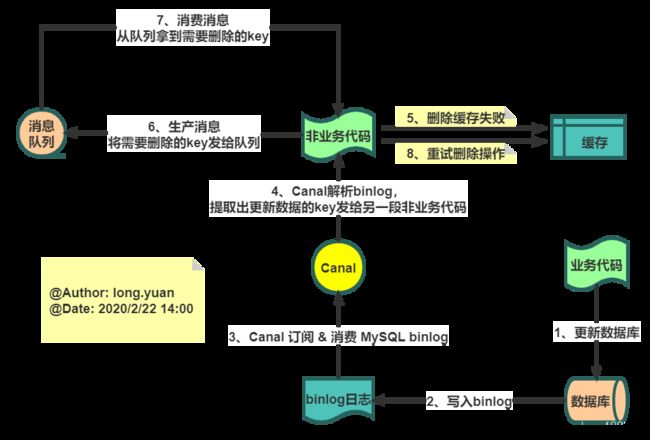
(1).更新数据库数据;
(2).MySQL 将数据更新日志写入 binlog 中;
(3).Canal 订阅 & 消费 MySQL binlog;
(4).Canal 解析binlog,提取出更新数据的key发送给另一段非业务代码;
(5).非业务代码尝试删除缓存操作,发现删除失败;
(6).将需要删除缓存的 Key 发送到消息队列 (MQ) 中;
(7).消费消息,从队列中拿到要删除的缓存key;
(8).拿到要删除的key后,再次尝试删除缓存,如果再次删除失败,可重发消息多次尝试;
总的来说就是先更新数据库,再删除缓存,提供一个"重试保障机制",如果删除缓存失败时,可以将删除失败的key发送到消息队列,再进行重试删除操作。
感兴趣的小伙伴可以关注一下博主的公众号,1W+技术人的选择,致力于原创技术干货,包含Redis、RabbitMQ、Kafka、SpringBoot、SpringCloud、ELK等热门技术的学习&资料。
