kubectl常用命令大全详解
这是我转载的一个博主写的 K8s 常用命令大全,里面详细介绍了 K8s 的命令。如果看了我写的入门基础篇文章,想了解更多命令可以看以下的文章。
说明
Kubernetes kubectl 命令表【中文网址】
Kubernetes kubectl 命令表
要使用和维护Kubernetes集群,最常用且直接的方式,就是使用自带的命令行工具Kubectl。
下面图片是一个总览,熟悉后可以用于勾起记忆。

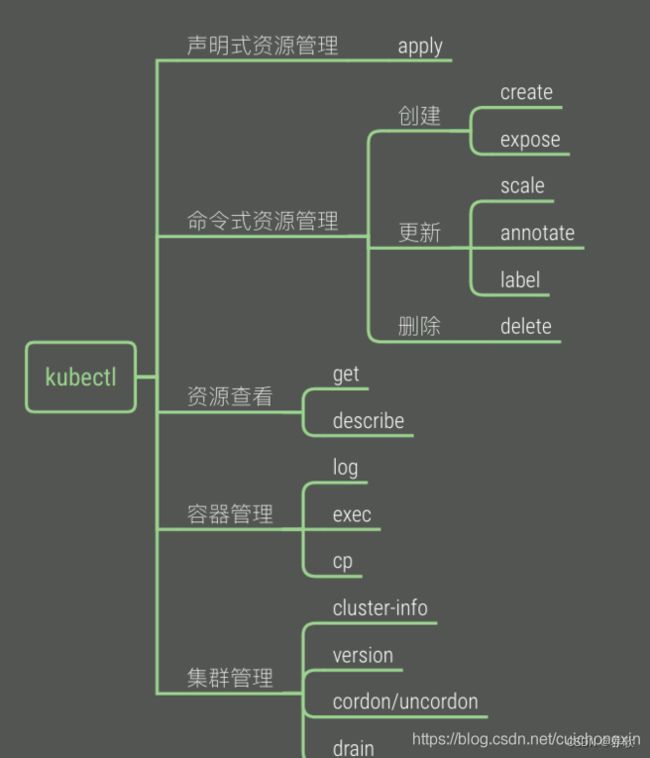
注:下面命令虽然整理的相对较全,但知道这些命令并不等于知道kucectl的使用了,还是很有必要系统的学习k8s,熟悉整个流程,下面命令更适合当手册使用,你知道你要干什么,记不住命令,ok没问题,来这ctrl+f搜索关键字即可,也可以当复习用,加深命令的作用。
基础命令详解:create、delete、get、run、expose、set、explain、edit
create 命令:根据文件或者输入来创建资源
创建Deployment和Service资源
[root@master ~]# kubectl create -f demo-deployment.yaml
[root@master ~]# kubectl create -f demo-service.yaml
delete 命令:删除资源
根据yaml文件删除对应的资源,但是yaml文件并不会被删除,这样更加高效
[root@master ~]# kubectl delete -f demo-deployment.yaml
[root@master ~]# kubectl delete -f demo-service.yaml
也可以通过具体的资源名称来进行删除,使用这个删除资源,同时删除deployment和service资源
[root@master ~]# kubectl delete 具体的资源名称
get 命令 :获得资源信息
查看所有ns空间的pod
kubectl get pod --all-namespaces和kubectl get pods -A一样效果,都是查看所有命名空间的pod【可以加上-owide,查看运行在哪个主机上】。
[root@master ~]# kubectl get all
[root@master ~]# kubectl get pod --all-namespaces
#下面就是详细信息了
[root@master1-163 ~]# kubectl get pods -A -owide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-78d6f96c7b-nwbmt 1/1 Running 0 16h 10.244.139.67 worker-165 <none> <none>
kube-system calico-node-nh977 1/1 Running 0 16h 192.168.59.162 master2-162 <none> <none>
kube-system calico-node-s89tx 1/1 Running 1 16h 192.168.59.163 master1-163 <none> <none>
kube-system calico-node-vt5dn 1/1 Running 0 16h 192.168.59.165 worker-165 <none> <none>
kube-system coredns-545d6fc579-6l9xs 1/1 Running 0 22h 10.244.139.66 worker-165 <none> <none>
kube-system coredns-545d6fc579-mrm2w 1/1 Running 0 22h 10.244.139.65 worker-165 <none> <none>
kube-system kube-apiserver-master1-163 1/1 Running 2 22h 192.168.59.163 master1-163 <none> <none>
kube-system kube-apiserver-master2-162 1/1 Running 1 21h 192.168.59.162 master2-162 <none> <none>
kube-system kube-controller-manager-master1-163 1/1 Running 2 22h 192.168.59.163 master1-163 <none> <none>
kube-system kube-controller-manager-master2-162 1/1 Running 1 21h 192.168.59.162 master2-162 <none> <none>
kube-system kube-proxy-kp8p6 1/1 Running 1 21h 192.168.59.162 master2-162 <none> <none>
kube-system kube-proxy-kqg72 1/1 Running 2 22h 192.168.59.163 master1-163 <none> <none>
kube-system kube-proxy-nftgv 1/1 Running 0 17h 192.168.59.165 worker-165 <none> <none>
kube-system kube-scheduler-master1-163 1/1 Running 2 22h 192.168.59.163 master1-163 <none> <none>
kube-system kube-scheduler-master2-162 1/1 Running 1 21h 192.168.59.162 master2-162 <none> <none>
[root@master1-163 ~]#
查看指定命名空间 pod 列表
查看所有命名空间
[root@master ~]# kubectl get ns
NAME STATUS AGE
default Active 4d6h
kube-node-lease Active 4d6h
kube-public Active 4d6h
kube-system Active 4d6h
[root@master ~]#
在-n跟上命名空间【如果不知道为什么要指定,接着往下看即可】
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
...
kube-scheduler-master 1/1 Running 12 4d6h
metrics-server-bcfb98c76-w87q9 1/1 Running 0 35m
[root@master ~]#
查看pod列表
这个命令查看的默认名称是:kube-public
[root@master ~]# kubectl get pod
但如果pod不是运行在kube-public上,就需要指定名称才能查看了,否则报错。
查看pod报错:No resources found in kube-public namespace.
先说一下查看pod运行在哪个命名空间上的命令:kubectl get pod --all-namespaces -o wide【不加 --all-namespaces就是仅查看当前所在命名空间的pod了】
结果中NAMESPACE就是了。
[root@master ~]# kubectl get pod --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system calico-kube-controllers-78d6f96c7b-p4svs 1/1 Running 0 4d5h 10.244.219.67 master <none> <none>
...
上面说过,如果pod运行的空间不是kube-public,直接执行 kubectl get pod就会报错,这时候需要加上-n并跟上命名名称【这个名称就是上面看到的NAMESPACE】
[root@master ~]# kubectl get ns # 这个命令是查看所有命名空间
NAME STATUS AGE
default Active 4d6h
kube-node-lease Active 4d6h
kube-public Active 4d6h
kube-system Active 4d6h
[root@master ~]#
[root@master ~]# kubectl get pod
No resources found in default namespace.
[root@master ~]#
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-78d6f96c7b-p4svs 1/1 Running 0 4d5h
calico-node-cc4fc 1/1 Running 18 4d4h
calico-node-stdfj 1/1 Running 20 4d5h
calico-node-zhhz7 1/1 Running 1 4d5h
coredns-545d6fc579-6kb9x 1/1 Running 0 4d6h
coredns-545d6fc579-v74hg 1/1 Running 0 4d6h
etcd-master 1/1 Running 1 4d6h
kube-apiserver-master 1/1 Running 1 4d6h
kube-controller-manager-master 1/1 Running 11 4d6h
kube-proxy-45qgd 1/1 Running 1 4d4h
kube-proxy-fdhpw 1/1 Running 1 4d6h
kube-proxy-zf6nt 1/1 Running 1 4d6h
kube-scheduler-master 1/1 Running 12 4d6h
metrics-server-bcfb98c76-w87q9 1/1 Running 0 25m
[root@master ~]#
显示pod节点的标签信息
[root@master ~]# kubectl get pod --show-labels
根据指定标签匹配到具体的pod
[root@master ~]# kubectl get pods -l app=example
查看node节点列表
[root@master ~]# kubectl get node
[root@master ~]# kubectl get nodes
显示node节点的标签信息
[root@master ~]# kubectl get node --show-labels
查看pod详细信息,也就是可以查看pod具体运行在哪个节点上(ip地址信息)
[root@master ~]# kubectl get pod -o wide
查看服务的详细信息,显示了服务名称,类型,集群ip,端口,时间等信息
[root@master ~]# kubectl get svc
[root@master ~]# kubectl get svc -n kube-system
查看所有命名空间
[root@master ~]# kubectl get ns
[root@master ~]# kubectl get namespaces
查看所有pod所属的命名空间
[root@master ~]# kubectl get pod --all-namespaces
查看所有pod所属的命名空间并且查看都在哪些节点上运行
[root@master ~]# kubectl get pod --all-namespaces -o wide
查看目前所有的replica set,显示了所有的pod的副本数,以及他们的可用数量以及状态等信息
[root@master ~]# kubectl get rs
查看已经部署了的所有应用,可以看到容器,以及容器所用的镜像,标签等信息
[root@master ~]# kubectl get deploy -o wide
[root@master ~]# kubectl get deployments -o wide
查看事件【get ev】
具体使用场景未知,我是在做【Kubernetes】k8s的健康性检查详细说明中readiness probe时候使用到这个命令了,记录一下。
[root@master probe]# kubectl get ev | tail -n 10
15m Normal Scheduled pod/pod6 Successfully assigned probe/pod6 to node2
15m Normal Pulled pod/pod6 Container image "nginx" already present on machine
15m Normal Created pod/pod6 Created container liveness
15m Normal Started pod/pod6 Started container liveness
13m Normal Killing pod/pod6 Stopping container liveness
12m Normal Scheduled pod/pod6 Successfully assigned probe/pod6 to node2
12m Normal Pulled pod/pod6 Container image "nginx" already present on machine
12m Normal Created pod/pod6 Created container liveness
12m Normal Started pod/pod6 Started container liveness
1s Warning Unhealthy pod/pod6 Readiness probe failed: cat: /tmp/healthy: No such file or directory
[root@master probe]#
run 命令:在集群中创建并运行一个或多个容器镜像。
语法:
run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] [--overrides=inline-json] [--command] -- [COMMAND] [args...]
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例
[root@master ~]# kubectl run nginx --replicas=3 --labels="app=example" --image=nginx:1.10 --port=80
# 示例,运行一个名称为nginx,副本数为3,标签为app=example,镜像为nginx:1.10,端口为80的容器实例,并绑定到k8s-node1上
[root@master ~]# kubectl run nginx --image=nginx:1.10 --replicas=3 --labels="app=example" --port=80 --overrides='{"apiVersion":"apps/v1","spec":{"template":{"spec":{"nodeSelector":{"kubernetes.io/hostname":"k8s-node1"}}}}}'
更详细用法参见:http://docs.kubernetes.org.cn/468.html
expose 命令:创建一个service服务,并且暴露端口让外部可以访问
创建一个nginx服务并且暴露端口让外界可以访问
[root@master ~]# kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service
更多expose详细用法参见:http://docs.kubernetes.org.cn/475.html
set 命令:配置应用的一些特定资源,也可以修改应用已有的资源
语法
[root@master ~]# set SUBCOMMAND
使用 kubectl set --help查看
它的子命令
- env
- image
- resources
- selector
- serviceaccount
- subject。
set 命令详情参见:http://docs.kubernetes.org.cn/669.html
kubectl set resources 命令
语法:
resources (-f FILENAME | TYPE NAME) ([--limits=LIMITS & --requests=REQUESTS]
- 这个命令用于设置资源的一些范围限制。
- 资源对象中的Pod可以指定计算资源需求(CPU-单位m、内存-单位Mi),即使用的最小资源请求(Requests),限制(Limits)的最大资源需求,Pod将保证使用在设置的资源数量范围。
- 对于每个Pod资源,如果指定了Limits(限制)值,并省略了Requests(请求),则Requests默认为Limits的值。
- 可用资源对象包括(支持大小写):replicationcontroller、deployment、daemonset、job、replicaset。
# 将deployment的nginx容器cpu限制为“200m”,将内存设置为“512Mi”
[root@master ~]# kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 设置所有nginx容器中 Requests和Limits
[root@master ~]# kubectl set resources deployment nginx --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
# 删除nginx中容器的计算资源值
[root@master ~]# kubectl set resources deployment nginx --limits=cpu=0,memory=0 --requests=cpu=0,memory=0
kubectl set selector 命令
- 设置资源的 selector(选择器)。如果在调用"set selector"命令之前已经存在选择器,则新创建的选择器将覆盖原来的选择器。
- selector必须以字母或数字开头,最多包含63个字符,可使用:字母、数字、连字符" - " 、点".“和下划线” _ "。如果指定了–resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
- 注意:目前selector命令只能用于Service对象。
selector (-f FILENAME | TYPE NAME) EXPRESSIONS [--resource-version=version]
kubectl set image 命令
- 用于更新现有资源的容器镜像。
- 可用资源对象包括:pod (po)、replicationcontroller (rc)、deployment (deploy)、daemonset (ds)、job、replicaset (rs)。
# 将deployment中的nginx容器镜像设置为“nginx:1.9.1”
[root@master ~]# kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
# 所有deployment和rc的nginx容器镜像更新为“nginx:1.9.1”
[root@master ~]# kubectl set image deployments,rc nginx=nginx:1.9.1 --all
# 将daemonset abc的所有容器镜像更新为“nginx:1.9.1”
[root@master ~]# kubectl set image daemonset abc *=nginx:1.9.1
# 从本地文件中更新nginx容器镜像
[root@master ~]# kubectl set image -f path/to/file.yaml nginx=nginx:1.9.1 --local -o yaml
explain 命令:用于显示资源文档信息
[root@master ~]# kubectl explain rs
edit 命令: 用于编辑资源信息
编辑Deployment nginx的一些信息
[root@master ~]# kubectl edit deployment nginx
编辑service类型的nginx的一些信息
[root@master ~]# kubectl edit service/nginx
设置命令说明label,annotate,completion
label命令: 用于更新(增加、修改或删除)资源上的 label(标签)
- label 必须以字母或数字开头,可以使用字母、数字、连字符、点和下划线,最长63个字符。
- 如果 --overwrite 为 true,则可以覆盖已有的label,否则尝试覆盖label将会报错。
- 如果指定了--resource-version,则更新将使用此资源版本,否则将使用现有的资源版本。
label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
给名为foo的Pod添加label unhealthy=true
[root@master ~]# kubectl label pods foo unhealthy=true
给名为foo的Pod修改label 为 ‘status’ / value ‘unhealthy’,且覆盖现有的value
[root@master ~]# kubectl label --overwrite pods foo status=unhealthy
给 namespace 中的所有 pod 添加 label
[root@master ~]# kubectl label pods --all status=unhealthy
仅当resource-version=1时才更新 名为foo的Pod上的label
[root@master ~]# kubectl label pods foo status=unhealthy --resource-version=1
删除名为“bar”的label 。(使用“ - ”减号相连)
[root@master ~]# kubectl label pods foo bar-
annotate命令:更新一个或多个资源的Annotations信息。也就是注解信息,可以方便的查看做了哪些操作。
- Annotations由key/value组成。
- Annotations的目的是存储辅助数据,特别是通过工具和系统扩展操作的数据,更多介绍在这里。
- 如果–overwrite为true,现有的annotations可以被覆盖,否则试图覆盖annotations将会报错。
- 如果设置了–resource-version,则更新将使用此resource version,否则将使用原有的resource version。
annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version]
更新Pod“foo”,设置annotation “description”的value “my frontend”,如果同一个annotation多次设置,则只使用最后设置的value值
[root@master ~]# kubectl annotate pods foo description=‘my frontend’
根据“pod.json”中的type和name更新pod的annotation
[root@master ~]# kubectl annotate -f pod.json description='my frontend'
更新Pod"foo",设置annotation“description”的value“my frontend running nginx”,覆盖现有的值
[root@master ~]# kubectl annotate --overwrite pods foo description='my frontend running nginx'
更新 namespace中的所有pod
[root@master ~]# kubectl annotate pods --all description='my frontend running nginx'
只有当resource-version为1时,才更新pod ‘foo’
[root@master ~]# kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
通过删除名为“description”的annotations来更新pod ‘foo’。 不需要 -overwrite flag。
[root@master ~]# kubectl annotate pods foo description-
completion命令:用于设置 kubectl 命令自动补全
BASH
# 在 bash 中设置当前 shell 的自动补全,要先安装 bash-completion 包
[root@master ~]# source <(kubectl completion bash)
# 在您的 bash shell 中永久的添加自动补全
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
ZSH
# 在 zsh 中设置当前 shell 的自动补全
[root@master ~]# source <(kubectl completion zsh)
# 在您的 zsh shell 中永久的添加自动补全
[root@master ~]# echo "if [ [root@master ~]#commands[kubectl] ]; then source <(kubectl completion zsh); fi" >> ~/.zshrc
kubectl 部署命令:rollout,rolling-update,scale,autoscale
rollout 命令: 用于对资源进行管理
- 可用资源包括:deployments,daemonsets。
- 子命令:
- history(查看历史版本)
- pause(暂停资源)
- resume(恢复暂停资源)
- status(查看资源状态)
- undo(回滚版本)
[root@master ~]# kubectl rollout SUBCOMMAND
回滚到之前的deployment
[root@master ~]# kubectl rollout undo deployment/abc
查看daemonet的状态
[root@master ~]# kubectl rollout status daemonset/foo
rolling-update命令: 执行指定ReplicationController的滚动更新。
该命令创建了一个新的RC, 然后一次更新一个pod方式逐步使用新的PodTemplate,最终实现Pod滚动更新,new-controller.json需要与之前RC在相同的namespace下。
语法:
rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] --image=NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC)
使用frontend-v2.json中的新RC数据更新frontend-v1的pod
[root@master ~]# kubectl rolling-update frontend-v1 -f frontend-v2.json
使用JSON数据更新frontend-v1的pod
[root@master ~]# cat frontend-v2.json | kubectl rolling-update frontend-v1 -f -
其他的一些滚动更新
[root@master ~]# kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2
[root@master ~]# kubectl rolling-update frontend --image=image:v2
[root@master ~]# kubectl rolling-update frontend-v1 frontend-v2 --rollback
scale命令:扩容或缩容 Deployment、ReplicaSet、Replication Controller或 Job 中Pod数量
scale也可以指定多个前提条件,如:当前副本数量或 --resource-version ,进行伸缩比例设置前,系统会先验证前提条件是否成立。这个就是弹性伸缩策略。
语法:
kubectl scale [--resource-version=version] [--current-replicas=count] --replicas=COUNT (-f FILENAME | TYPE NAME)
将名为foo中的pod副本数设置为3。
[root@master ~]# kubectl scale --replicas=3 rs/foo
kubectl scale deploy/nginx --replicas=30
将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3
[root@master ~]# kubectl scale --replicas=3 -f foo.yaml
如果当前副本数为2,则将其扩展至3。
[root@master ~]# kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
设置多个RC中Pod副本数量
[root@master ~]# kubectl scale --replicas=5 rc/foo rc/bar rc/baz
autoscale命令:这个比scale更加强大,也是弹性伸缩策略 ,它是根据流量的多少来自动进行扩展或者缩容。
指定Deployment、ReplicaSet或ReplicationController,并创建已经定义好资源的自动伸缩器。使用自动伸缩器可以根据需要自动增加或减少系统中部署的pod数量。
语法:
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU] [flags]
使用 Deployment “foo”设定,使用默认的自动伸缩策略,指定目标CPU使用率,使其Pod数量在2到10之间
[root@master ~]# kubectl autoscale deployment foo --min=2 --max=10
使用RC“foo”设定,使其Pod的数量介于1和5之间,CPU使用率维持在80%
[root@master ~]# kubectl autoscale rc foo --max=5 --cpu-percent=80
集群管理命令:certificate,cluster-info,top,cordon,uncordon,drain,taint
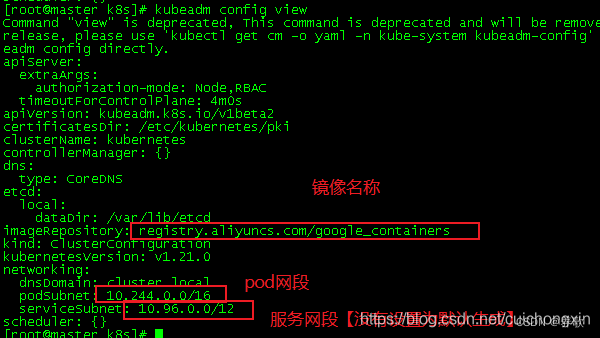
查看集群的初始化信息【pod使用镜像和网段等】
[root@master ~]# kubeadm config view
certificate命令:用于证书资源管理,授权等
例如,当有node节点要向master请求,那么是需要master节点授权的
[root@master ~]# kubectl certificate approve node-csr-81F5uBehyEyLWco5qavBsxc1GzFcZk3aFM3XW5rT3mw node-csr-Ed0kbFhc_q7qx14H3QpqLIUs0uKo036O2SnFpIheM18
cluster-info 命令:显示集群信息
[root@master ~]# kubectl cluster-info
top 命令:用于查看资源的cpu,内存磁盘等资源的使用率
以前需要heapster,后替换为metrics-server 【如果不装这个服务,会有error报错】

安装metrics以后,error报错就成使用率展示了
我博客分类中有一篇是:k8s安装metric server和了解ns,想了解的可以自己去看看学习学习。

查看pod的使用情况
查看所有
[root@master ~]# kubectl top pod --all-namespaces
查看指定pod
[root@master ~]# kubectl top pod -n 命名名称 【命名名称查看:kubectl get ns】
查看node的使用情况
[root@master ~]# kubectl top nodes
cordon命令:用于标记某个节点不可调度
标记 my-node 为 unschedulable,禁止pod被调度过来。注意这时现有的pod还会继续运行,不会被驱逐。
[root@master ~]# kubectl cordon my-node
uncordon命令:用于标签节点可以调度
与cordon相反,标记 my-node 为 允许调度。
[root@master ~]# kubectl uncordon my-node
drain命令: 用于在维护期间排除节点。
drain字面意思为排水,实际就是把my-node的pod平滑切换到其他node,同时标记pod为unschedulable,也就是包含了cordon命令。
[root@master ~]# kubectl drain my-node
但是直接使用命令一般不会成功,建议在要维护节点时,加上以下参数:
kubectl drain my-node --ignore-daemonsets --force --delete-local-data
- --ignore-daemonsets 忽略daemonset部署的pod
- --force 直接删除不由workload对象(Deployment、Job等)管理的pod
- --delete-local-data 直接删除挂载有本地目录(empty-dir方式)的pod
taint命令:用于给某个Node节点设置污点
1、污点 ( Taint ) 的组成
- 使用kubectl taint命令可以给某个Node节点设置污点,Node被设置上污点之后就和Pod之间存在了一种相斥的关系,可以让Node拒绝Pod的调度执行,甚至将Node已经存在的Pod驱逐出去
- 每个污点的组成如下:
key=value:effect每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。 - 当前 taint effect 支持如下三个选项:
- NoSchedule :表示k8s将不会将Pod调度到具有该污点的Node上
- NoExecute :表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去
- PreferNoSchedule :表示k8s将尽量避免将Pod调度到具有该污点的Node上
2、污点的设置、查看和去除
设置污点
kubectl taint nodes k8s-node2 check=yuanzhang:NoExecute
节点说明中,查找Taints字段
kubectl describe nodes k8s-node2
去除污点
kubectl taint nodes k8s-node2 check:NoExecute-
集群故障排查和调试命令:describe,logs,exec,attach,port-foward,proxy,cp,auth
describe命令:显示特定pod资源的详细信息
要先知道所有的命名空间,你的pod可能不是在默认default中
[root@master ~]# kubectl get ns
NAME STATUS AGE
ccx Active 15h
ccxhero Active 15h
default Active 5d
kube-node-lease Active 5d
kube-public Active 5d
kube-system Active 5d
ns1 Active 16h
[root@master ~]#
这时需要获取指定命名空间中的pod名称,如我获取ccx下的pod
[root@master ~]# kubectl get pods -n ccx
NAME READY STATUS RESTARTS AGE
nginx-test-795d659f45-j9m9b 0/1 ImagePullBackOff 0 26m
nginx-test-795d659f45-txf8l 0/1 ImagePullBackOff 0 26m
[root@master ~]#
查看某个 pod的详细状态
得到上面的pod名称后,加上-n 后面跟上命名空间,如果不加-n,则是使用默认的命名空间,会报错。
语法:kubectl describe pod -n pod所属ns podNAME
如下
[root@master ~]# kubectl describe pod -n ccx nginx-test-795d659f45-j9m9b
...
logs命令:用于在一个pod中打印一个容器的日志,如果pod中只有一个容器,可以省略容器名
语法:
kubectl logs [-f] [-p] POD [-c CONTAINER]
返回仅包含一个容器的pod nginx的日志快照
[root@master ~]# kubectl logs nginx
返回pod ruby中已经停止的容器web-1的日志快照
[root@master ~]# kubectl logs -p -c ruby web-1
持续输出pod ruby中的容器web-1的日志
[root@master ~]# kubectl logs -f -c ruby web-1
仅输出pod nginx中最近的20条日志
[root@master ~]# kubectl logs --tail=20 nginx
输出pod nginx中最近一小时内产生的所有日志
[root@master ~]# kubectl logs --since=1h nginx
参数选项:
- -c, --container="": 容器名。
- -f, --follow[=false]: 指定是否持续输出日志(实时日志)。
- --interactive[=true]: 如果为true,当需要时提示用户进行输入。默认为true。
- --limit-bytes=0: 输出日志的最大字节数。默认无限制。
- -p, --previous[=false]: 如果为true,输出pod中曾经运行过,但目前已终止的容器的日志。
- --since=0: 仅返回相对时间范围,如5s、2m或3h,之内的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
- --since-time="": 仅返回指定时间(RFC3339格式)之后的日志。默认返回所有日志。只能同时使用since和since-time中的一种。
- --tail=-1: 要显示的最新的日志条数。默认为-1,显示所有的日志。
- --timestamps[=false]: 在日志中包含时间戳。
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
命令选项:
- -c, --container="": 容器名。如果未指定,使用pod中的一个容器。
- -p, --pod="": Pod名。
- -i, --stdin[=false]: 将控制台输入发送到容器。
- -t, --tty[=false]: 将标准输入控制台作为容器的控制台输入。
- 进入nginx容器,执行一些命令操作
[root@master ~]# kubectl exec -it nginx-deployment-58d6d6ccb8-lc5fp bash
attach命令:连接到一个正在运行的容器。
语法:
kubectl attach POD -c CONTAINER
参数选项:
- - `-c, --container=""`: 容器名。如果省略,则默认选择第一个 pod。
- - `-i, --stdin[=false]`: 将控制台输入发送到容器。
- - `-t, --tty[=false]`: 将标准输入控制台作为容器的控制台输入。
获取正在运行中的pod 123456-7890的输出,默认连接到第一个容器
[root@master ~]# kubectl attach 123456-7890
获取pod 123456-7890中ruby-container的输出
[root@master ~]# kubectl attach 123456-7890 -c ruby-container
切换到终端模式,将控制台输入发送到pod 123456-7890的ruby-container的“bash”命令,并将其结果输出到控制台
错误控制台的信息发送回客户端。
[root@master ~]# kubectl attach 123456-7890 -c ruby-container -i -t
cp命令:拷贝文件或者目录到pod容器中
用于pod和外部的文件交换,类似于docker 的cp,就是将容器中的内容和外部的内容进行交换。
语法:
kubectl cp <file-spec-src> <file-spec-dest> [options]
拷贝宿主机本地文件夹到pod
[root@master ~]# kubectl cp /tmp/foo_dir <some-pod>:/tmp/bar_dir
指定namespace的拷贝pod文件到宿主机本地目录
[root@master ~]# kubectl cp <some-namespace>/<some-pod>:/tmp/foo /tmp/bar
对于多容器pod,用-c指定容器名
[root@master ~]# kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>
其他命令:api-servions,config,help,plugin,version
api-servions命令:打印受支持的api版本信息
打印当前集群支持的api版本
[root@master ~]# kubectl api-versions
help命令:用于查看命令帮助
显示全部的命令帮助提示
[root@master ~]# kubectl --help
具体的子命令帮助,例如
[root@master ~]# kubectl create --help
config 命令: 用于修改kubeconfig配置文件(用于访问api,例如配置认证信息)
设置 kubectl 与哪个 Kubernetes 集群进行通信并修改配置信息。查看 使用 kubeconfig 跨集群授权访问 文档获取详情配置文件信息。
显示合并的 kubeconfig 配置信息
为啥要加个合并呢,是因为如果配置了多集群,那么这里面的配置信息是很多的,如下,我配置了2个集群的config文件内容就如下【我博客中有一篇是:【Kubernetes】k8s多集群切换【含上下文作用详解】,这里面说了如何配置多集群,感兴趣的可以去看看。
[root@master ~]# kubectl config view
[root@master ~]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.59.142:6443
name: master
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.59.151:6443
name: master1
contexts:
- context:
cluster: master
namespace: default
user: ccx
name: context
- context:
cluster: master1
namespace: default
user: ccx1
name: context1
current-context: context
kind: Config
preferences: {}
users:
- name: ccx
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
- name: ccx1
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
[root@master ~]#
同时使用多个 kubeconfig 文件并查看合并的配置
[root@master ~]# KUBECONFIG=~/.kube/config:~/.kube/kubconfig2 kubectl config view
获取 e2e 用户的密码
[root@master ~]# kubectl config view -o jsonpath='{.users[?(@.name == "e2e")].user.password}'
查看当前所处的上下文
[root@master ~]# kubectl config current-context
查看多集群上下文等信息
CURRENT是当前所处集群
[root@master ~]# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* context master ccx default
context1 master1 ccx1 default
[root@master ~]#
设置默认的上下文【多集群切换】
使用:kubectl config get-contexts查看现在有的上下文【一般多集群才需要切换】
语法
kubectl config use-context 上下文名称【NAME】
如,我现在在context上,我切换到context1这个上下文上【也就切换到另一个集群了】
[root@master ~]# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* context master ccx default
context1 master1 ccx1 default
[root@master ~]#
[root@master ~]# kubectl config use-context context1
Switched to context "context1".
[root@master ~]#
[root@master ~]# kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
context master ccx default
* context1 master1 ccx1 default
[root@master ~]#
添加新的集群配置到 kubeconf 中,使用 basic auth 进行鉴权
[root@master ~]# kubectl config set-credentials kubeuser/foo.kubernetes.com --username=kubeuser --password=kubepassword
使用特定的用户名和命名空间设置上下文。
[root@master ~]# kubectl config set-context gce --user=cluster-admin --namespace=foo \
&& kubectl config use-context gce
version 命令:打印客户端和服务端版本信息
打印客户端和服务端版本信息【详细版】
[root@master ~]# kubectl version
精简版【仅显示版本号】
[root@master ~]# kubectl version --short
plugin 命令:运行一个命令行插件
docker plugin命令用于管理插件。
用法
docker plugin COMMAND
Shell
编号 命令 描述
| IP | 操作系统 |
|---|---|
| docker plugin create | 从rootfs和配置创建一个插件。插件数据目录必须包含config.json和rootfs目录。 |
| 192.168.2.125 | centos7.9 |
| docker plugin enable | 启用插件 |
| docker plugin inspect | 显示一个或多个插件的详细信息 |
| docker plugin install | 安装一个插件 |
| docker plugin ls | 列出所有插件 |
| docker plugin push | 将插件推送到注册表 |
| docker plugin rm | 删除一个或多个插件 |
| docker plugin set | 更改插件的设置 |
| docker plugin upgrade | 升级现有插件 |
高级命令:apply,patch,replace,convert
apply命令:通过文件名或者标准输入对资源应用配置
通过文件名或控制台输入,对资源进行配置。 如果资源不存在,将会新建一个。可以使用 JSON 或者 YAML 格式。
语法:
kubectl apply -f FILENAME
将pod.json中的配置应用到pod
[root@master ~]# kubectl apply -f ./pod.json
将控制台输入的JSON配置应用到Pod
[root@master ~]# cat pod.json | kubectl apply -f -
参数选项:
语法:
kubectl patch (-f FILENAME | TYPE NAME) -p PATCH
- -f, --filename=[]: 包含配置信息的文件名,目录名或者URL。
- --include-extended-apis[=true]: If true, include definitions of new APIs via calls to the API server. [default true]
- -o, --output="": 输出模式。"-o name"为快捷输出(资源/name).
- --record[=false]: 在资源注释中记录当前 kubectl 命令。
- -R, --recursive[=false]: Process the directory used in -f, --filename recursively. Useful when you want to manage related manifests organized within the same directory.
- --schema-cache-dir="~/.kube/schema": 非空则将API schema缓存为指定文件,默认缓存到’[root@master ~]#HOME/.kube/schema’
- --validate[=true]: 如果为true,在发送到服务端前先使用schema来验证输入。
patch命令:使用补丁修改,更新资源的字段,也就是修改资源的部分内容
Partially update a node using strategic merge patch
[root@master ~]# kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'
Update a container’s image; spec.containers[*].name is required because it’s a merge key
[root@master ~]# kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'
replace命令: 通过文件或者标准输入替换原有资源
语法:
kubectl replace -f FILENAME
Replace a pod using the data in pod.json.
[root@master ~]# kubectl replace -f ./pod.json
Replace a pod based on the JSON passed into stdin.
[root@master ~]# cat pod.json | kubectl replace -f -
Update a single-container pod’s image version (tag) to v4
[root@master ~]# kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*[root@master ~]#/\1:v4/' | kubectl replace -f -
Force replace, delete and then re-create the resource
[root@master ~]# kubectl replace --force -f ./pod.json
convert命令:不同的版本之间转换配置文件
语法:
kubectl convert -f FILENAME
Convert ‘pod.yaml’ to latest version and print to stdout.
[root@master ~]# kubectl convert -f pod.yaml
Convert the live state of the resource specified by ‘pod.yaml’ to the latest version and print to stdout in json format.
[root@master ~]# kubectl convert -f pod.yaml --local -o json
Convert all files under current directory to latest version and create them all.
[root@master ~]# kubectl convert -f . | kubectl create -f -
格式化输出
要以特定格式将详细信息输出到终端窗口,可以将-o或–output 参数添加到支持的 kubectl 命令。

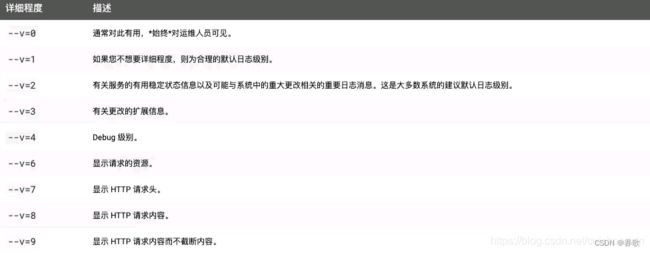
Kubectl 日志输出详细程度和调试
Kubectl 日志输出详细程度是通过 -v 或者 --v 来控制的,参数后跟了一个数字表示日志的级别。
Kubernetes 通用的日志习惯和相关的日志级别在 这里 有相应的描述。