Pandas——Series操作【建议收藏】
pandas——Series操作
作者:AOAIYI
创作不易,觉得文章不错或能帮助到你学习,可以点赞收藏评论哦
文章目录
- pandas——Series操作
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
-
- 1.创建Series
- 2.从具体位置的Series中访问数据
- 3.使用标签检索数据(索引)
- 4.简单运算
- 5.Series的自动对齐
- 6.Series增删改
一、实验目的
熟练掌握pandas中Series的创建、查询和简单运算方法
二、实验原理
Series的定义:Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
Series对象本质上是一个NumPy的数组,因此NumPy的数组处理函数可以直接对Series进行处理。但是Series除了可以使用位置作为下标存取元素之外,还可以使用标签下标存取元素,这一点和字典相似。每个Series对象实际上都由两个数组组成:
index: 它是从NumPy数组继承的Index对象,保存标签信息。
values: 保存值的NumPy数组。
注意三点:
-
Series是一种类似于一维数组(数组:ndarray)的对象
-
它的数据类型没有限制(各种NumPy数据类型)
-
它有索引,把索引当做数据的标签(key)看待,这样就类似字典了(只是类似,实质上是数组)
4.Series同时具有数组和字典的功能,因此它也支持一些字典的方法
三、实验环境
Python 3.6.1以上
jupyter
四、实验内容
练习Series的创建、查看数据与简单运算操作。
五、实验步骤
1.创建Series
1.创建一个空的Series。
import pandas as pd
s=pd.Series()
print(s)

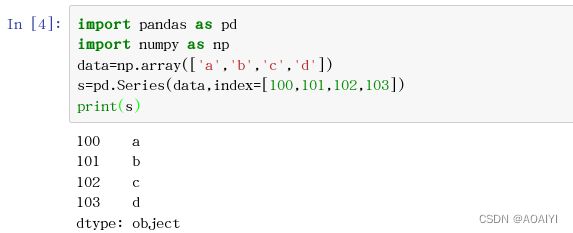
2.从ndarray创建一个Series,并规定索引为[100,101,102,103]。
import pandas as pd
import numpy as np
data=np.array(['a','b','c','d'])
s=pd.Series(data,index=[100,101,102,103])
print(s)
3.从字典创建一个Series,字典键用于构建索引。
import pandas as pd
data={'a':0,'b':1,'c':2,'d':3}
s=pd.Series(data)
print(s)

4.从标量创建一个Series,此时,必须提供索引,重复值以匹配索引的长度。
import pandas as pd
s=pd.Series(5,index=[0,1,2,3])
print(s)

2.从具体位置的Series中访问数据
1.检索Series中的第一个元素。
import pandas as pd
s=pd.Series([1,2,3,4,5],index=['a','b','c','d','e'])
print(s[0])

2.检索Series中的前三个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[:3])

3.检索Series中最后三个元素。
import pandas as pd
s= pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])

3.使用标签检索数据(索引)
使用标签检索数据(索引):一个Series就像一个固定大小的字典,可以通过索引标签获取和设置值。
1.使用索引标签检索单个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s['a'])

2.使用索引标签列表检索多个元素。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(['a','b','c','d'])

3.如果不包含标签,检索会出现异常。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s['f'])

4.简单运算
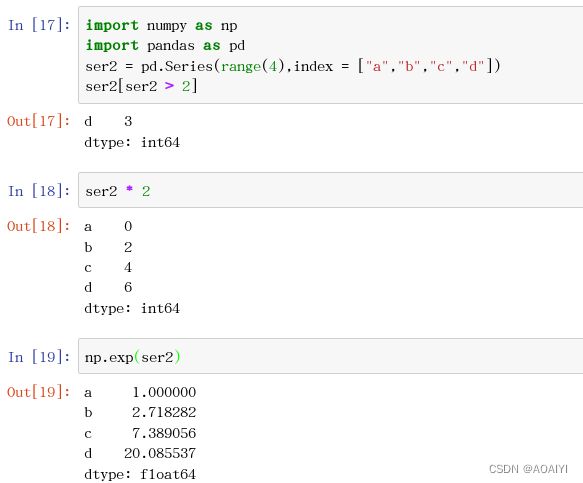
1.在pandas的Series中,会保留NumPy的数组操作(用布尔数组过滤数据,标量乘法,以及使用数学函数),并同时保持引用的使用
import numpy as np
import pandas as pd
ser2 = pd.Series(range(4),index = ["a","b","c","d"])
ser2[ser2 > 2]
ser2 * 2
np.exp(ser2)
5.Series的自动对齐
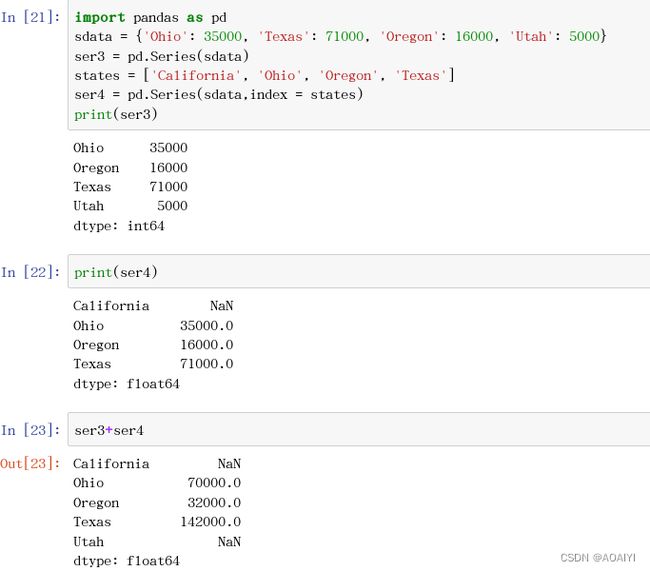
Series的一个重要功能就是自动对齐(不明觉厉),看看例子就明白了。 差不多就是不同Series对象运算的时候根据其索引进行匹配计算。
1.创建两个Series名为ser3与ser4.
import pandas as pd
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
ser3 = pd.Series(sdata)
states = ['California', 'Ohio', 'Oregon', 'Texas']
ser4 = pd.Series(sdata,index = states)
print(ser3)
print(ser4)
ser3+ser4
6.Series增删改
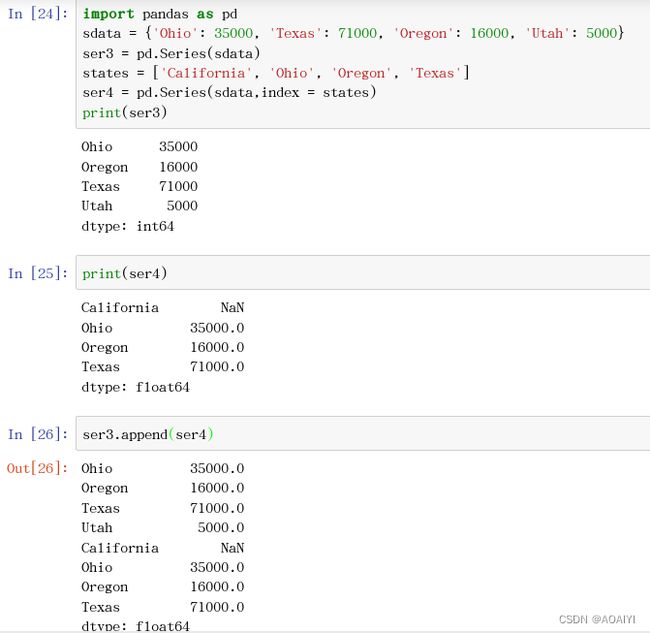
1.增:Series的add()方法是加法计算不是增加Series元素用的,使用append连接其他Series。
import pandas as pd
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
ser3 = pd.Series(sdata)
states = ['California', 'Ohio', 'Oregon', 'Texas']
ser4 = pd.Series(sdata,index = states)
print(ser3)
print(ser4)
ser3.append(ser4)
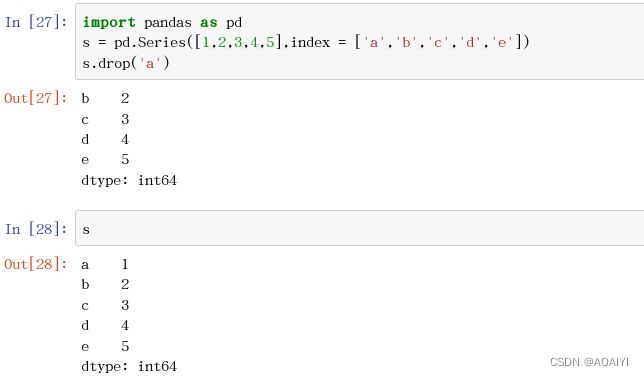
2.删:Series的drop()方法可以对Series进行删除操作,返回一个被删除后的Series,原来的Series不改变。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
s.drop('a')
s
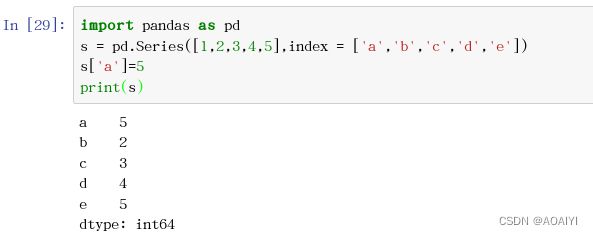
3.改:通过索引的方式查找到某个元素,然后通过“=”赋予新的值。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
s['a']=5
print(s)