python正则表达式
python正则表达式
作者:AOAIYI
创作不易,如果觉得文章不错或能帮到你学习,记得点赞收藏评论一下哦
文章目录
- python正则表达式
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 总结
一、实验目的
学会使用常见的正则表达式
二、实验原理
一、 正则表达式基础
1.1.概念介绍
正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。
其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。
它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的。
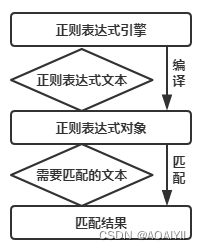
下图展示了使用正则表达式进行匹配的流程:
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。
贪婪模式,总是尝试匹配尽可能多的字符;
非贪婪模式则相反,总是尝试匹配尽可能少的字符。
Python里数量词默认是贪婪的。
例如:正则表达式"ab*“如果用于查找"abbbc”,将找到"abbb"。
而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的问题
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":
第一个和第三个用于在编程语言里将第二个和第四个转义成反斜杠,
转换成两个反斜杠\后再在正则表达式里转义成一个反斜杠用来匹配反斜杠\。
这样显然是非常麻烦的。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。
同样,匹配一个数字的"\d"可以写成r"\d"。
三、实验环境
Python 3.6.1以上
PyCharm
四、实验内容
掌握常用的正则表达式是爬虫的基础,练习常用的正则表达式。
五、实验步骤
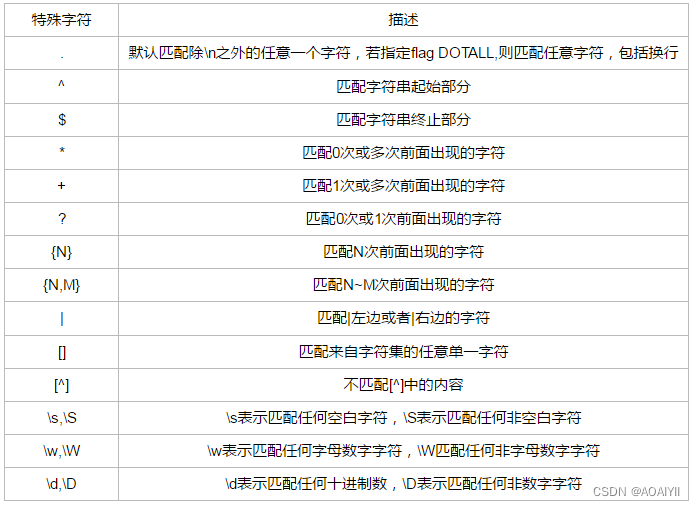
1.在python中有个re包,它是专门用来做正则表达式的,使用时应先import添加re包。在正则表达式中最常用的是".“和”",".“代表匹配任意字符,”“代表匹配0或多次前面出现的字符。
举例,现在有数据abcde,我们使用”."来匹配中间的bcd三个字母。
import re
data = 'abcde'
reg = 'a...e'
out = re.findall(reg,data)
print(out)
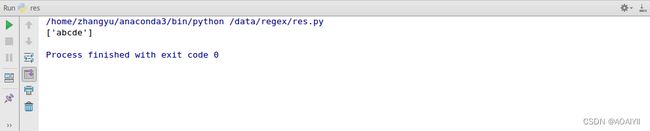
可以在下面看到输出了abcde,说明成功用三个".“代替了bcd,那么当中间字符不止是三个而是更多时,就不能简单的重复”.“了,我们应该使用”*"。
例如:使用".*“来表示0或无限次的”.",修改代码为:
import re
data = 'abcde'
reg = 'a.*e'
out = re.findall(reg,data)
print(out)

输出与上次的结果相同,证明匹配成功。
注意:"+“与”“的功能相同,区别在于”“可以匹配到0次,也就是说匹配的字符可以不出现,而”+"匹配的字符最少要出现一次。
2."^“和”$"分别代表匹配字符串起始部分和匹配字符串终止部分。
例如:我们定义的规则是匹配出以h开头的字符串。
import re
data = 'hadoopandspark'
reg = '^h.*'
out = re.findall(reg,data)
print(out)
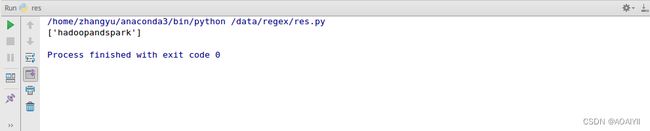
可以看到我们将开头为h的"hadoopandspark"匹配出来了,如果我们匹配其他开头字母,那么该字符串将不会匹配出来。
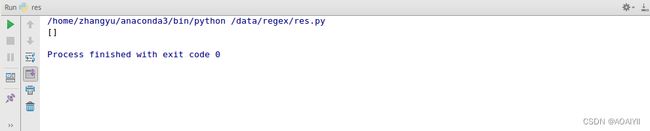
例如:我们定义规则为匹配以a开头的字符串,则不会返回结果。
import re
data = 'hadoopandspark'
reg = '^a.*'
out = re.findall(reg,data)
print(out)
3.同理的,"$"的用法是匹配终止字符
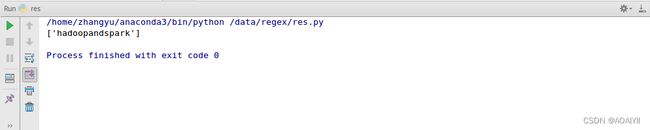
例如:我们匹配以k结尾的字符串,将会匹配出"hadoopandspark",如果改为匹配其他字母,则不会返回结果
import re
data = 'hadoopandspark'
reg = '.*k$'
out = re.findall(reg,data)
print(out)
4."?“也是正则表达式中的一个常用符号,它有两种用法,一是表示”?"前的字符出现0次或1次。
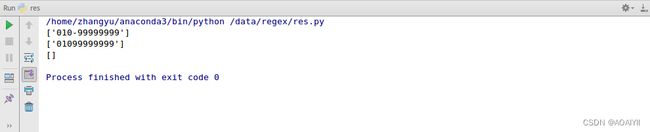
例如:北京某地的电话号为010-99999999,定义区号和后面号码之间可以存在一个或零个"-",当"-"多于一个时,将不会返回结果。
import re
data = '010-99999999'
data1 = '01099999999'
data2 = '010--99999999'
reg = '^010-?\d{8}$'
out = re.findall(reg,data)
out1 = re.findall(reg,data1)
out2 = re.findall(reg,data2)
print(out)
print(out1)
print(out2)
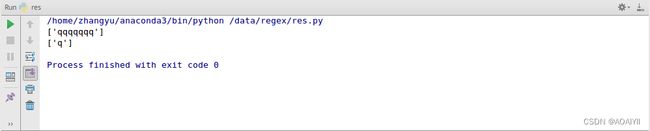
第二种用法是它表示非贪婪模式,贪婪模式是指只要有符合条件的字符就全部匹配出来,它将匹配出所有q,非贪婪模式是指只要匹配到一个符合要求的字符就停止,不再继续贪婪更多的q。
import re
data = 'qqqqqqqaabbaccc'
reg = '^q+'
reg1 = '^q+?'
out = re.findall(reg,data)
out1 = re.findall(reg1,data)
print(out)
print(out1)
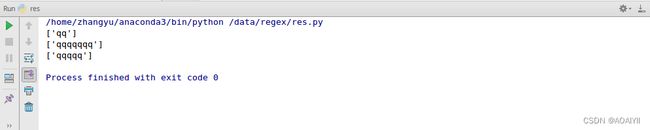
5.{N}和{N,M}的用法,{N}代表匹配N次前面出现的字符,{N,M}代表匹配N~M次前面出现的字符。
例如:reg代表匹配两次q,reg1代表匹配2次以上的q,reg2代表匹配2次以上,5次以下的q。
import re
data = 'qqqqqqqaabbacccqq'
reg = '^q{2}'
reg1 = '^q{2,}'
reg2 = '^q{2,5}'
out = re.findall(reg,data)
out1 = re.findall(reg1,data)
out2 = re.findall(reg2,data)
print(out)
print(out1)
print(out2)
6."|“代表匹配”|“左边或右边的字符,”|"两边只要有一边成立就可以匹配出来。
例如:"|“左边匹配以010-开头的前6位字符,”|"右边匹配以9结尾的后4位字符。
import re
data = '010-99999999'
reg = '^010-.{2}|.{3}9$'
out = re.findall(reg,data)
print(out)

注意:"|"的左右两侧,如果左侧匹配失败则匹配右侧,如果右侧匹配失败则匹配左侧。
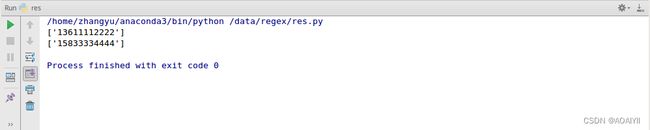
7."[ ]"表示匹配来自字符集的任意单一字符。
例如:[136 139 182 158],[ ]内包含四个电话号码的前三位,在数据中只要满足这四个电话号码中的任意一个,就可以匹配出来。
import re
data = '13611112222'
data1 = '15833334444'
reg = '[136 139 182 158].*'
out = re.findall(reg,data)
out1 = re.findall(reg,data1)
print(out)
print(out1)
8."[^] "表示不匹配 [^]中的内容。
例如:我们定义的规则是匹配出以1开头,第二位为3、5、8,第三位任意,第四位不能为1的电话号码。
import re
data = '13611112222,15833334444,18255556666'
reg = '1[3 5 8].[^1]{8}'
out = re.findall(reg,data)
print(out)

9.\s表示匹配任何空白字符,\S表示匹配任何非空白字符。
例如,\s将匹配出三个空格,\S将匹配出其他非空白字符。
import re
data = 'abc 123 ABC -'
reg = '\s'
reg1 = '\S'
out = re.findall(reg,data)
out1 = re.findall(reg1,data)
print(out)
print(out1)

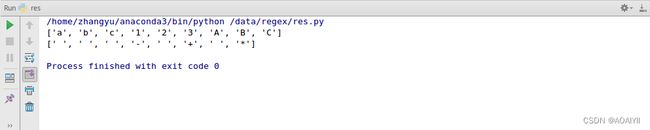
10.\w表示匹配任何字母数字字符,\W匹配任何非字母数字字符。
例如:\w匹配出了字母和数字,\W略过了非字母和数字,匹配出了空格和符号。
import re
data = 'abc 123 ABC - + *'
reg = '\w'
reg1 = '\W'
out = re.findall(reg,data)
out1 = re.findall(reg1,data)
print(out)
print(out1)
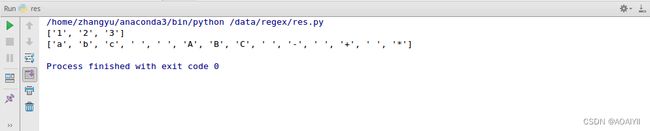
11.\d表示匹配任何十进制数,\D表示匹配任何非数字字符。
例如:\d匹配出了123,\D略过了123,匹配出了字母,空格和符号。
import re
data = 'abc 123 ABC - + *'
reg = '\d'
reg1 = '\D'
out = re.findall(reg,data)
out1 = re.findall(reg1,data)
print(out)
print(out1)
总结
以上就是本文要讲的内容,本文介绍了正则表达式的使用,正则表达式是用于处理字符串的强大工具,它并不是Python的一部分。
其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。
它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的。