人脸识别SVM
目录
-
- 一.实验准备
- 二、Dlib提取人脸特征
-
- 2、微笑识别
- 4、相机检测模型
- 三、参考博客
一.实验准备
下载实验所需包
pip install scikit-image
pip install playsound
pip install pandas
pip install sklearn
二、Dlib提取人脸特征
# 从人脸图像文件中提取人脸特征存入 CSV
# Features extraction from images and save into features_all.csv
# return_128d_features() 获取某张图像的128D特征
# compute_the_mean() 计算128D特征均值
from cv2 import cv2 as cv2
import os
import dlib
from skimage import io
import csv
import numpy as np
# 要读取人脸图像文件的路径
path_images_from_camera = "D:/myworkspace/JupyterNotebook/Smile/files2/test/"
# Dlib 正向人脸检测器
detector = dlib.get_frontal_face_detector()
# Dlib 人脸预测器
predictor = dlib.shape_predictor("D:/shape_predictor_68_face_landmarks.dat")
# Dlib 人脸识别模型
# Face recognition model, the object maps human faces into 128D vectors
face_rec = dlib.face_recognition_model_v1("D:/dlib_face_recognition_resnet_model_v1.dat")
# 返回单张图像的 128D 特征
def return_128d_features(path_img):
img_rd = io.imread(path_img)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_BGR2RGB)
faces = detector(img_gray, 1)
print("%-40s %-20s" % ("检测到人脸的图像 / image with faces detected:", path_img), '\n')
# 因为有可能截下来的人脸再去检测,检测不出来人脸了
# 所以要确保是 检测到人脸的人脸图像 拿去算特征
if len(faces) != 0:
shape = predictor(img_gray, faces[0])
face_descriptor = face_rec.compute_face_descriptor(img_gray, shape)
else:
face_descriptor = 0
print("no face")
return face_descriptor
# 将文件夹中照片特征提取出来, 写入 CSV
def return_features_mean_personX(path_faces_personX):
features_list_personX = []
photos_list = os.listdir(path_faces_personX)
if photos_list:
for i in range(len(photos_list)):
# 调用return_128d_features()得到128d特征
print("%-40s %-20s" % ("正在读的人脸图像 / image to read:", path_faces_personX + "/" + photos_list[i]))
features_128d = return_128d_features(path_faces_personX + "/" + photos_list[i])
# print(features_128d)
# 遇到没有检测出人脸的图片跳过
if features_128d == 0:
i += 1
else:
features_list_personX.append(features_128d)
i1=str(i+1)
add="D:/myworkspace/JupyterNotebook/Smile/feature/face_feature"+i1+".csv"
print(add)
with open(add, "w", newline="") as csvfile:
writer1 = csv.writer(csvfile)
writer1.writerow(features_128d)
else:
print("文件夹内图像文件为空 / Warning: No images in " + path_faces_personX + '/', '\n')
# 计算 128D 特征的均值
# N x 128D -> 1 x 128D
if features_list_personX:
features_mean_personX = np.array(features_list_personX).mean(axis=0)
else:
features_mean_personX = '0'
return features_mean_personX
# 读取某人所有的人脸图像的数据
people = os.listdir(path_images_from_camera)
people.sort()
with open("D:/myworkspace/JupyterNotebook/Smile/feature/features2_all.csv", "w", newline="") as csvfile:
writer = csv.writer(csvfile)
for person in people:
print("##### " + person + " #####")
# Get the mean/average features of face/personX, it will be a list with a length of 128D
features_mean_personX = return_features_mean_personX(path_images_from_camera + person)
writer.writerow(features_mean_personX)
print("特征均值 / The mean of features:", list(features_mean_personX))
print('\n')
print("所有录入人脸数据存入 / Save all the features of faces registered into: D:/myworkspace/JupyterNotebook/Smile/feature/features2_all.csv")
2、微笑识别
# pandas 读取 CSV
import pandas as pd
# 分割数据
from sklearn.model_selection import train_test_split
# 用于数据预加工标准化
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # 线性模型中的 Logistic 回归模型
from sklearn.neural_network import MLPClassifier # 神经网络模型中的多层网络模型
from sklearn.svm import LinearSVC # SVM 模型中的线性 SVC 模型
from sklearn.linear_model import SGDClassifier # 线性模型中的随机梯度下降模型
import joblib
# 从 csv 读取数据
def pre_data():
# 41 维表头
column_names = []
for i in range(0, 40):
column_names.append("feature_" + str(i + 1))
column_names.append("output")
# read csv
rd_csv = pd.read_csv("D:/myworkspace/JupyterNotebook/Smile/data/data_csvs/data.csv", names=column_names)
# 输出 csv 文件的维度
# print("shape:", rd_csv.shape)
X_train, X_test, y_train, y_test = train_test_split(
# input 0-40
# output 41
rd_csv[column_names[0:40]],
rd_csv[column_names[40]],
# 25% for testing, 75% for training
test_size=0.25,
random_state=33)
return X_train, X_test, y_train, y_test
path_models = "D:/myworkspace/JupyterNotebook/Smile/data/data_models/"
# LR, logistic regression, 逻辑斯特回归分类(线性模型)
def model_LR():
# get data
X_train_LR, X_test_LR, y_train_LR, y_test_LR = pre_data()
# 数据预加工
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导
ss_LR = StandardScaler()
X_train_LR = ss_LR.fit_transform(X_train_LR)
X_test_LR = ss_LR.transform(X_test_LR)
# 初始化 LogisticRegression
LR = LogisticRegression()
# 调用 LogisticRegression 中的 fit() 来训练模型参数
LR.fit(X_train_LR, y_train_LR)
# save LR model
joblib.dump(LR, path_models + "model_LR.m")
# 评分函数
score_LR = LR.score(X_test_LR, y_test_LR)
print("The accurary of LR:", score_LR)
# print(type(ss_LR))
return (ss_LR)
model_LR()
# MLPC, Multi-layer Perceptron Classifier, 多层感知机分类(神经网络)
def model_MLPC():
# get data
X_train_MLPC, X_test_MLPC, y_train_MLPC, y_test_MLPC = pre_data()
# 数据预加工
ss_MLPC = StandardScaler()
X_train_MLPC = ss_MLPC.fit_transform(X_train_MLPC)
X_test_MLPC = ss_MLPC.transform(X_test_MLPC)
# 初始化 MLPC
MLPC = MLPClassifier(hidden_layer_sizes=(13, 13, 13), max_iter=500)
# 调用 MLPC 中的 fit() 来训练模型参数
MLPC.fit(X_train_MLPC, y_train_MLPC)
# save MLPC model
joblib.dump(MLPC, path_models + "model_MLPC.m")
# 评分函数
score_MLPC = MLPC.score(X_test_MLPC, y_test_MLPC)
print("The accurary of MLPC:", score_MLPC)
return (ss_MLPC)
model_MLPC()
# Linear SVC, Linear Supported Vector Classifier, 线性支持向量分类(SVM支持向量机)
def model_LSVC():
# get data
X_train_LSVC, X_test_LSVC, y_train_LSVC, y_test_LSVC = pre_data()
# 数据预加工
ss_LSVC = StandardScaler()
X_train_LSVC = ss_LSVC.fit_transform(X_train_LSVC)
X_test_LSVC = ss_LSVC.transform(X_test_LSVC)
# 初始化 LSVC
LSVC = LinearSVC()
# 调用 LSVC 中的 fit() 来训练模型参数
LSVC.fit(X_train_LSVC, y_train_LSVC)
# save LSVC model
joblib.dump(LSVC, path_models + "model_LSVC.m")
# 评分函数
score_LSVC = LSVC.score(X_test_LSVC, y_test_LSVC)
print("The accurary of LSVC:", score_LSVC)
return ss_LSVC
model_LSVC()
# SGDC, Stochastic Gradient Decent Classifier, 随机梯度下降法求解(线性模型)
def model_SGDC():
# get data
X_train_SGDC, X_test_SGDC, y_train_SGDC, y_test_SGDC = pre_data()
# 数据预加工
ss_SGDC = StandardScaler()
X_train_SGDC = ss_SGDC.fit_transform(X_train_SGDC)
X_test_SGDC = ss_SGDC.transform(X_test_SGDC)
# 初始化 SGDC
SGDC = SGDClassifier(max_iter=5)
# 调用 SGDC 中的 fit() 来训练模型参数
SGDC.fit(X_train_SGDC, y_train_SGDC)
# save SGDC model
joblib.dump(SGDC, path_models + "model_SGDC.m")
# 评分函数
score_SGDC = SGDC.score(X_test_SGDC, y_test_SGDC)
print("The accurary of SGDC:", score_SGDC)
return ss_SGDC
model_SGDC()
4、相机检测模型
# use the saved model
import joblib
import smile_test1
import dlib # 人脸处理的库 Dlib
import numpy as np # 数据处理的库 numpy
import cv2 # 图像处理的库 OpenCv
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('D:/shape_predictor_68_face_landmarks.dat')
# OpenCv 调用摄像头
cap = cv2.VideoCapture(0)
# 设置视频参数
cap.set(3, 480)
def get_features(img_rd):
# 输入: img_rd: 图像文件
# 输出: positions_lip_arr: feature point 49 to feature point 68, 20 feature points / 40D in all
# 取灰度
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 计算68点坐标
positions_68_arr = []
faces = detector(img_gray, 0)
landmarks = np.matrix([[p.x, p.y] for p in predictor(img_rd, faces[0]).parts()])
for idx, point in enumerate(landmarks):
# 68点的坐标
pos = (point[0, 0], point[0, 1])
positions_68_arr.append(pos)
positions_lip_arr = []
# 将点 49-68 写入 CSV
# 即 positions_68_arr[48]-positions_68_arr[67]
for i in range(48, 68):
positions_lip_arr.append(positions_68_arr[i][0])
positions_lip_arr.append(positions_68_arr[i][1])
return positions_lip_arr
while cap.isOpened():
# 480 height * 640 width
flag, img_rd = cap.read()
kk = cv2.waitKey(1)
img_gray = cv2.cvtColor(img_rd, cv2.COLOR_RGB2GRAY)
# 人脸数 faces
faces = detector(img_gray, 0)
# 检测到人脸
if len(faces) != 0:
# 提取单张40维度特征
positions_lip_test = get_features(img_rd)
# path of models
path_models = "D:/myworkspace/JupyterNotebook/Smile/data/data_models/"
# ######### LR ###########
LR = joblib.load(path_models+"model_LR.m")
ss_LR = smile_test1.model_LR()
X_test_LR = ss_LR.transform([positions_lip_test])
y_predict_LR = str(LR.predict(X_test_LR)[0]).replace('0', "no smile").replace('1', "with smile")
print("LR:", y_predict_LR)
# ######### LSVC ###########
LSVC = joblib.load(path_models+"model_LSVC.m")
ss_LSVC = smile_test1.model_LSVC()
X_test_LSVC = ss_LSVC.transform([positions_lip_test])
y_predict_LSVC = str(LSVC.predict(X_test_LSVC)[0]).replace('0', "no smile").replace('1', "with smile")
print("LSVC:", y_predict_LSVC)
# ######### MLPC ###########
MLPC = joblib.load(path_models+"model_MLPC.m")
ss_MLPC = smile_test1.model_MLPC()
X_test_MLPC = ss_MLPC.transform([positions_lip_test])
y_predict_MLPC = str(MLPC.predict(X_test_MLPC)[0]).replace('0', "no smile").replace('1', "with smile")
print("MLPC:", y_predict_MLPC)
# ######### SGDC ###########
SGDC = joblib.load(path_models+"model_SGDC.m")
ss_SGDC = smile_test1.model_SGDC()
X_test_SGDC = ss_SGDC.transform([positions_lip_test])
y_predict_SGDC = str(SGDC.predict(X_test_SGDC)[0]).replace('0', "no smile").replace('1', "with smile")
print("SGDC:", y_predict_SGDC)
print('\n')
# 按下 'q' 键退出
if kk == ord('q'):
break
# 窗口显示
# cv2.namedWindow("camera", 0) # 如果需要摄像头窗口大小可调
cv2.imshow("camera", img_rd)
# 释放摄像头
cap.release()
# 删除建立的窗口
cv2.destroyAllWindows()
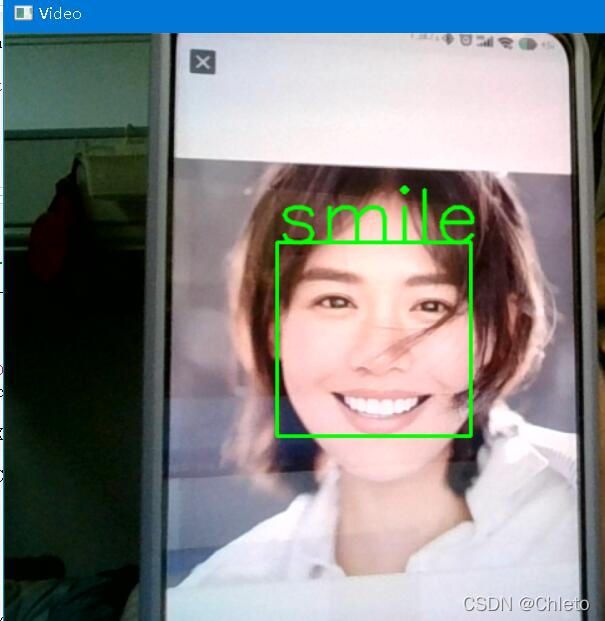
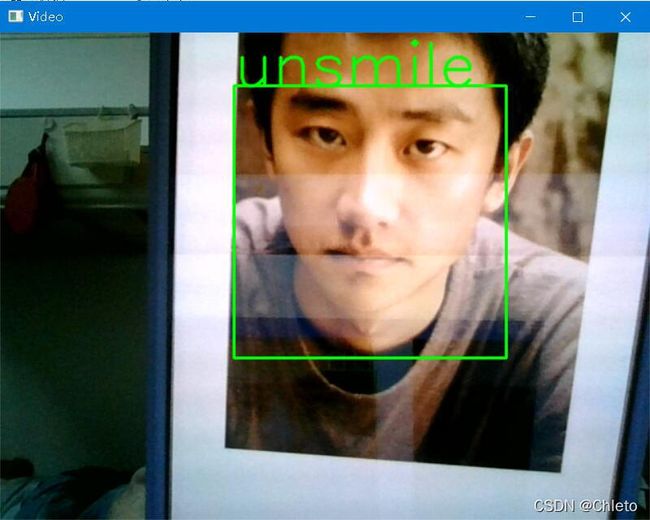
三、参考博客
https://blog.csdn.net/qq_41133375/article/details/107141898