Feed流之微博系统设计
本文主要阐述feed流的技术方案 ①relation存储 ②发帖订阅/推送
简介
1. 概念:Feed + 流(Feed流将用户主动订阅的若干消息源组合在一起,形成内容聚合器,帮助用户持续的获取最新的订阅内容,Feed流即持续更新并呈现给用户内容的信息流)
Feed:投喂
流:给用户呈现信息的形式
2. 场景
① 社交互动类:微信、微博、Instagram、Facebook ...
② 新闻资讯类:今日头条、腾讯新闻 ...
③ 视频直播类:抖音、快手 ...
3. 主要模式
1. 推模式:用户发帖,对所有粉丝推送该消息(不适合大V)
2. 拉模式:主动拉取用户所有关注这的最近动态列表(不适合关注了很多用户的用户)
3. 推拉模式结合
4. 排序方式
1. TimeLine排序:按照发布时间顺序排序,先发布的先看到,后发布的排列在最顶端,类似于微信朋友圈(产品如果选择 Timeline 类型,那么就是认为 Feed 流中的 Feed 不多,但是每个 Feed 都很重要,都需要用户看到)
2. Rank排序:按照非时间的因子排序,一般按照用户的喜爱好度排序(这种一般假定用户可能看到的 Feed 非常多,而用户花费在这里的时间有限,那么就为用户选择出用户最想看的 Top N 结果,场景的应用场景有微博、头条新闻推荐类、商品、视频推荐等)
3. 智能排序:基于趋势 trending、热门 hot、编辑推荐 PGC 等因素综合考虑
微博系统设计
业务特点
海量数据、高访问量、非均匀
1. 海量用户数据:亿级别的用户数量,每个用户千级别的帖子数量,平均千级别的follower/attention数量
2. 高访问量:每秒十万量级的访问页面,每秒万量级别的帖子发布
3. 用户分布非均匀:部分用户的帖子数量/follower数量,相关页面访问数量会超出其他用户几十个数量级
4. 时间分布非均匀:某个用户在某个时间点成为热点用户,其follower可能徒增数个量级
核心问题1:“关注模型”的存储
最简单的是基于DB的存储,只需要两张表 relation_tab \ user_info_tab
user_info_tab 用户信息表:自增id、用户账号user_id、用户信息(头像、名称、注册时间、大v认证、手机号等)
relation_tab 关系表:自增id、关注者id、被关注者id
==> 所以,只需要查询2张表就可以查询出关注、粉丝、用户信息
// 查询所有“关注者”关注的人
select count(*) from relation_tab where 关注者id='xx'
// 查询“被关注者”所有的粉丝
select count(*) from relation_tab where 被关注者id='xx'
// 根据用户账号,查询user_info
select * from user_info_tab where user_id='xx'
随着用户的增多,relation_tab \ user_info_tab表的行数增多。千万、亿级用户,每个用户相关关系百级,那么就需要水平拆分。
user_info_tab 用户信息表拆分规则:水平拆分
1. 上亿的数据量,拆分成10~20张表,每张表保存约500~1000万个用户:表名user_info_{idx}_tab
2. 按照user_id,hash取模,得到idx,数据存放在user_info_{idx}_tab
relation_tab 关系表拆分规则:垂直拆分+水平拆分
根据2种业务场景进行水平拆分
1. 根据follower进行水平拆分:查询follower关注的列表很简单,但是查询follower的粉丝很难
2. 根据attention进行水平拆分:查询attention的粉丝列表很简单,但是查询attention关注的人很难
针对上述问题,进行垂直拆分,
1. 分为follower表和attention表,分别记录了某个用户的关注者和被关注者。表字段
- follower表:自增id、user_id、follower_id
- attention表:自增id、user_id、attention_id
2. 接下来对follower表和attention表分别基于user_id进行水平拆分
==> 此时,实现查询user_id的关注列表、粉丝列表的user_info
// 查询user_id关注列表、粉丝列表
select count(*) from follower_{idx}_tab where user_id='xx'
select count(*) from attention_{idx}_tab where user_id='xx'
// 查询用户信息
select * from user_info_{idx}_tab where user_id In ('xx', 'yy', ...)分析:前2步可以落在相同的mysql分片上,执行DB操作次数为2次,但是第3步仍然需要查询多个table(因为用户信息散落在不同的user_info_{idx}_tab表中,所以需要遍历各个分片查询)
优化:将user_info_{idx}_tab表中的用户基本信息,全部加载到Redis缓存中。除此之外,可以将① 每个user_id的粉丝数和关注数,也存在用户信息中。②每个用户关注数量有上限,所以也可以将该用户关注列表存在Redis的list结构中。③但是用户的粉丝列表不可以全部存储在Redis的list中,会出现大key问题(根据业务场景分析,可以保存用户最近新增的100个粉丝列表,即将新增的用户放在list的最后面)。
核心问题2:帖子(post)的设计实现与优化
一般存储帖子,通常都是在MySQL中进行存储,数据库字段:post_id、user_id、content、post_time,其中
- post_id:帖子id
- user_id:发帖人
- content:发帖内容
- post_time:发帖时间,精确到秒(同一个用户在1s之内发送的帖子数通常不多余1条)
索引:对user_id+post_time建立联合级索引 ==> 查询某个用户按照时间排列的所有帖子
// 查询某个用户在post_time时间段内发的帖子
select * from post_tab where user_id=? and post_time between ? and ?
// 查询某个帖子
select * from post_tab where post_id=?
核心问题3:大V发帖了,应该如何设计?
业务场景:在微博平台,用户可以对喜欢的人进行关注,关注了之后,这些人发帖子了,用户就会看到,按照时间进行排序和分页。
核心问题:用户关注好友后,如何快速得到所有好友的最新发表的微博内容,即发表 / 订阅问题,是微博的核心业务问题!

简介:每个用户都有一个“收件箱inBox”和“发件箱outBox”
1. 用户刷微博时,查看自己的“收件箱inBox”
2. 用户发微博时,将邮件插入到“发件箱outBox”
方式1:push模式(推模式是在用户发微博的时候推送给所有的粉丝/关注者)
业务场景
1.用户发表的内容插入到所有粉丝的“收件箱inBox”里,粉丝拉取关注流从自己的“收件箱inBox”里拉取
2.用户撤销发表,从每个粉丝的“收件箱inBox”里删除掉
3.新粉丝新关注了此用户,将该用户的发表内容插入到新粉丝的“收件箱inBox”里
4.新粉丝取消关注了此用户,将该用户的有关内容,从该粉丝的“收件箱inBox”里删除
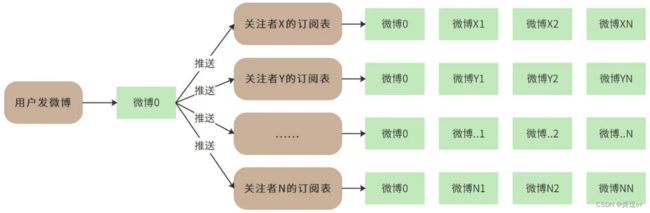
push模式过程:推模式需要把一篇微博推送给所有关注他的人(推给所有的粉丝
① 用户发微博后,push模式,会将该微博推送给所有的粉丝,即在每个粉丝的“收件箱inBox”中插入一条帖子记录
② 每当用户刷新微博时,只需要从收件箱inBox中,查询所有订阅的微博
分析
优点:消除了拉模式的IO集中点,每个用户都读自己的数据,高并发下锁竞争少
缺点:
1.(写放大)极大消耗存储资源,数据会存储很多分,比如大V的粉丝有一百万,他每次发表一次,数据会冗余一百万份,同时,插入到一百万的粉丝的队列中也比较费时。 ==> 拥有千万粉丝的网红/大V发帖,会导致上千万次数据库的插入操作,直接导致系统崩溃
2. 新增关注,取消关,发布,取消发布的业务流程复杂
方式2:pull模式(拉模式是在用户刷微博的时候拉取他关注的所有好友的最新微博)
业务场景
1.用户发表的内容只插入到自己的“发件箱outBox”里去,粉丝拉取关注流里需要从每个关注人的“发件箱outBox”里各取几个,然后进行rank。
2.用户撤销发表,只把自己的“发件箱outBox”对应的删掉即可。
3.新粉丝新关注了此用户,因为是拉模式,不需要额外操作,刷新关注流的时候就会拉取。
4.粉丝取消关注了此用户,因为是拉模式,不需要额外操作。

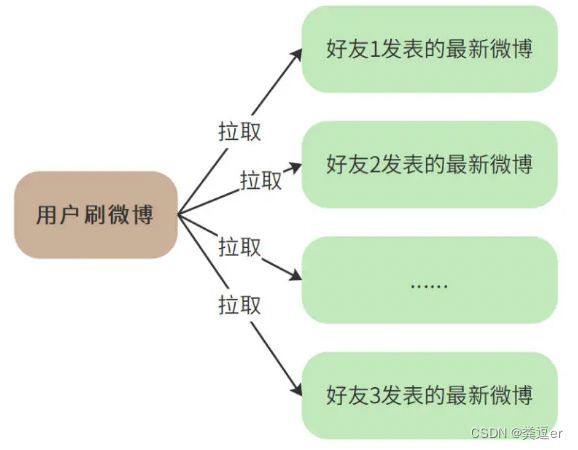
pull模式过程:
① 拉模式只需要用户发表微博时,存储一条微博数据到自己的“发件箱outBox”
② 用户需要查询所有关注者的“发件箱outBox”,组成列表返回
分析:
优点:
1.存储结构简单,数据存储量小,只存一份,无数据冗余。
2.关注,取关,发布,取消发布的业务流程非常简单。
3.存储结构,业务流程都比较容易理解,适合项目早期用户量、数据量、并发量不大时的快速实现。
缺点:
1.拉取业务流程比较复杂:需要查找到关注列表,然后依次查询“发件箱outBox”
2.(读放大):因为所有用户都是关注网红/大V,那么网红/大V的“发件箱outBox”就会被读放大,直接导致系统的崩溃
拉模式优化方案:时间分区
1. 发帖表(feed表)可以按照时间区间分表,一天表、一周表、一个月表、总表等,简单来说就是做几份数据冗余
2. 用户登录时,我们根据用户的上次登录的时间确定他适合查询那个区间表。
举例:
每天都登录的用户定位到一周表
半个月登录一次的定位到一个月表
依次类推

方式3:push\pull模式结合
推拉模式结合:实际上是根据用户是否为大V,进行区别对待(推拉结合虽然很全面,但实现复杂,同时业务量很大时才有用)
1.发帖
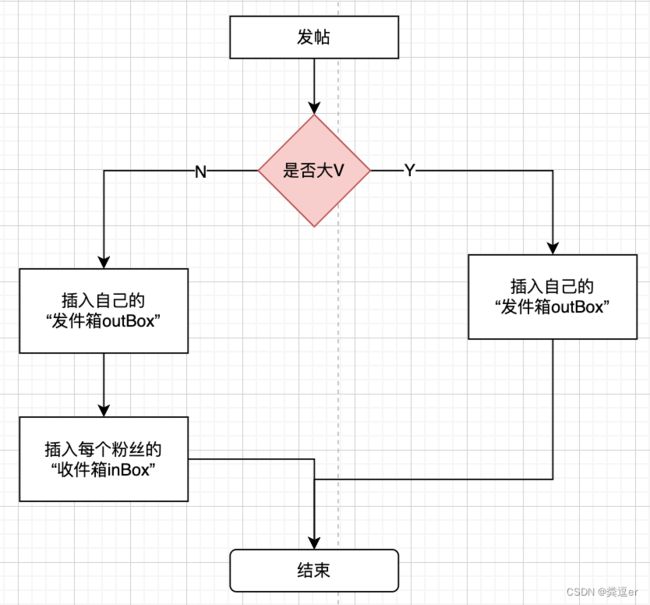
1).发表内容先进入一个队列服务(异步处理)
2).从粉丝列表中读取到自己的粉丝列表,以及判断自己是否大V
3).将发表内容写入个人的“发件箱inBox”(现在就是进入到动态发表库里),如果是大V,就结束了
4)如果不是大V还需要将自己的发表数据插入到自己粉丝的“收件箱outBox”里去
2.拉取
1).去关注表里拉取关注的人,并判断谁是大V
2).去读自己的接收队列
3).如果是大V,还要去遍历大v的发表队列
4).进行rank
3.取消关注
1)取消的如果是大v,见拉模式
2)取消的如果不是大v,见推模式
4.取消发布
同取消关注
5.增加新关注
1)如果新关注的是大v,见拉模式
2)如果关注的不是大v,见推模式。
----------------------------------------------------------------------
除此之外,还要加上缓存对系统进行优化!这里就不再赘述