浅谈mysql的主键和索引
在上一篇文章《count(1)、count(*)、count(字段)哪个更靠谱》中,我们提到过主键是优化不了count的查询效率的,需要建索引才可以,那么,是不是意味着主键的效率还不如一般的索引呢?怀着这个疑问,我们一起来了解下mysql主键和索引的相关知识。
mysql数据库的MYISAM和InnoDB引擎所采用的索引的数据存储结构是不一样的,本文所阐述的内容都是基于InnoDB引擎下。
什么是主键
我们引用上一篇文章最后的一段内容:
-
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
-
主键创建后一定包含一个特殊的唯一性索引,唯一性索引不一定就是主键。
-
唯一性索引列允许空值, 而主键列不允许为空值。
-
主键可以被其他表引用为外键,而唯一索引不能。
-
一个表最多只能创建一个主键,但是可以创建多个唯一索引。
-
主键更适合那些不容易改变的唯一标识,如自动递增列,身份证号等。
划重点:
1、主键是一种约束,从本质上来说并不是索引。
2、一个表最多只有一个主键。
3、主键定义后一定会按主键顺序生成一个唯一性的索引,所以一般来说,我们会把主键和主键索引等同看待。
索引的类型
关于索引的类型说法有很多,如聚簇索引、非聚簇索引、主键索引、辅助索引、二级索引、次级索引、唯一索引、单列索引、复合索引等等。我们先引用mysql官方的一段话来解释:
-
在InnoDB,每张表都有一个特殊的索引叫聚簇索引(也叫聚集索引),聚簇索引的B+Tree的叶子节点存的是主键值和整行数据,整张表的数据其实就是存储在聚簇索引中,实际上聚簇索引就是一张按主键顺序存储的表。主键一定是聚簇索引。
-
除了聚簇索引外的其它索引都叫二级索引,与聚簇索引的区别在于二级索引的叶子节点中只存了索引列和主键值,索引和数据是分开的。非聚簇索引、辅助索引、次级索引都是二次索引的不同说法,唯一索引、单列索引、复合索引都属于二次索引,只是从逻辑角度进行的分类。
-
通过主键可以直接在聚簇索引找到对应的行数据,通过二级索引需要先找到主键值,再根据主键值到聚簇索引找到对应的行,也就是平常说的要进行一次回表操作,因此,要获取行数据,主键索引效率是最高的(注意:这里强调的是获取到行数据)。
-
InnoDB要求每张表都要定义主键,并建议主键采用自增ID的形式,这样可以减少二级索引占用空间,提升索引效率。
下面是聚簇索引和二级索引的结构:

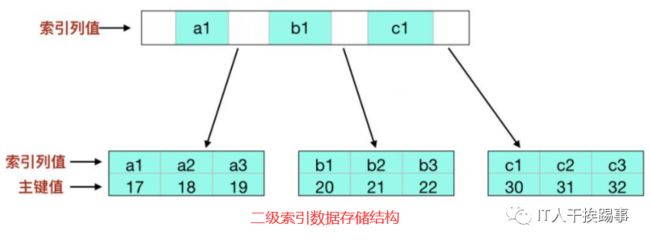
通过上面的索引结构可以看出,聚簇索引保存了整张表的数据,所以要获取行数据通过聚簇索引是最快的,但如果只是获取索引列和主键列数据,二次索引结构更小,通过二级索引的效率是最高的。
-
聚簇索引的建立遵循以下的原则:
1、如果一个主键被定义了,那么这个主键就是作为聚簇索引。
2、如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚簇索引。
3、如果没有主键也没有合适的唯一索引,那么InnoDB内部会生成一个隐藏的主键作为聚簇索引,这个隐藏的主键是一个6个字节的列,该列的值会随着数据的插入自增,但用户不可见且不能用于查询。
那么,我们思考两个问题:
1、主键一定是聚簇索引,聚簇索引是否一定是主键?
2、聚簇索引不是主键,那二级索引叶子节点存放的主键值是什么?
带着这两个问题,我们来做个实验,先建个测试表:
create table test(
id int not null,
c1 varchar(10) not null,
c2 varchar(10) null);
查看索引情况:
select i.* from information_schema.INNODB_SYS_INDEXES i join information_schema.INNODB_SYS_TABLES t on i.table_id=t.table_id where t.name='ecos/test';

可以看到,未定义主键的情况下,mysql自动创建了一个隐藏的、用户不可见的主键并作为聚簇索引,符合聚簇索引建立的第3条原则。(在INNODB_SYS_INDEXES系统表中type代表索引的类型,0:一般的索引,1:(GEN_CLUST_INDEX)系统生成的隐藏主键索引,2:唯一索引,3:主键索引)
再创建一个唯一索引:
create unique index unx_c1 on test(c1);
再查看索引情况:

可以看到创建的唯一索引自动转变成了主键索引,那么c1是否也转成了主键呢,我们再看表的情况:
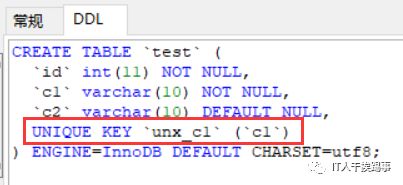
c1并没有变成primary key,改变的只是索引的类型,这时候从用户视角主键实际上是不存在的。
我们再给表添加主键:
alter table test add PRIMARY key(id);
再看索引和表的主键情况:

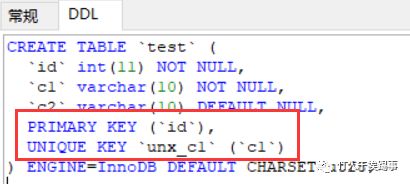
可以看到原来的主键索引已经变成了唯一索引,新加的主键ID成了主键索引。
总结:
1、主键一定是聚簇索引,聚簇索引不一定是主键,但一定是主键索引(我们暂且把系统自动生成的也当主键索引)。
2、二次索引叶子节点存放的主键值准确的说是主键索引值。
3、在mysql的官方文档里面,一直都是以primary key出现的,并且也不支持以create index方式创建,primary key既代表了主键也代表了主键索引,这也造成了我们在理解上的困惑,所以在了解mysql索引结构的时候建议还是把primary key理解为主键索引。
4、在建表的时候就应该定义好主键,并且不再修改,特别是生产环境,主键的修改会影响到所有索引的重建。
5、官方建议主键用自增ID,但在实际业务场景中,应该结合业务实际需要来定义主键,更好的利用主键索引的优势,但要避免用uuid等无序的值。如在订单数据表,订单号本身就按递增规则生成,且具有唯一性,那么用订单号做主键更符合业务需要。
最后回到最开始的问题,count(*)之所以在只有主键的情况下查询效率无法提升,正是由于mysql InnoDB索引结构导致的,count在where条件没有的情况下是要走全表扫描,而主键索引是聚簇索引,包含了整个表的数据,占用空间和分页更多,查询优化器在有二级索引的情况下会优先查找二级索引,二级索引的B+Tree更小,查找效率会更高,覆盖索引优化同样是利用的二级索引的这种优势。
思考:id为主键,下面两个查询返回的结果是一样的吗?
1、select a.* from tbl_order a limit 1;
2、select a.* from tbl_order a where id=(select b.id from tbl_order b limit 1);
浅谈mysql的主键和索引 (qq.com)