【C++】入门(下)
继续来学习吧:
一、引用
1.1 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。
具体操作:类型 & 引用变量名(对象名) = 引用实体
举个栗子:
int main()
{
int a = 10;
//给变量a取别名
int& b = a;
int& c = a;
int& d = c;
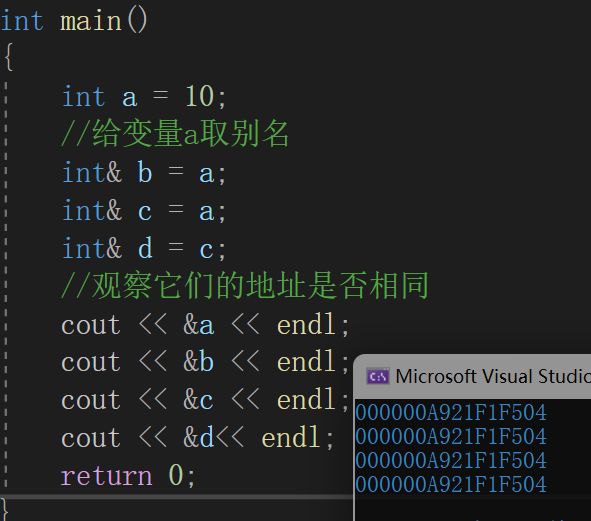
//观察它们的地址是否相同
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d<< endl;
return 0;
}我们现在来看一下运行结果(可以看到abcd所指向的都是同一块空间):
❗注意:引用类型必须和引用实体必须是同种类型的
在这里我们可以看到:一个变量可以有多个引用
1.2 引用的特性
接下来我们直接看例子:
int main()
{
int a = 10;
//给变量a取别名
int& b = a;
cout << &a << endl;
cout << &b << endl;
int x = 10;
b = x;
cout << &b << endl;
return 0;
}运行效果:

可以看到将a的引用的b重新赋值为x,b所在的地址并没有发生改变
这可以说明:引用一旦引用一个实体,再不能引用其他实体
再看这里:

在引用时不设定初始值,这样子编译器过不去
这可以说明:引用一旦引用一个实体,再不能引用其他实体
1.3 引用使用的场景
1.3.1 输出型参数(想要形参影响实参)
在我们在C语言中使用函数传参时,想要形参影响实参必须要用到指针。
在C++中引用能很好的做到这样点。
类似于交换函数:
//指针
void swap(int* p1, int* p2)
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
//引用
void swap(int& r1, int& r2)
{
int temp = r1;
r1 = r2;
r2 = temp;
}运行结果:

我们可以发现引用比指针更易于理解,就是在函数swap中给两个变量取别名直接交换即可,不需要再像指针一样进行解引用操作了。
1.3.2 引用返回
我们在调用函数时,如果这个函数有返回值的话,在返回返回值时需要临时开辟一个临时空间来保存返回值再将其返回。那我们能不能提升一下效率呢?
当然可以,只要使用引用返回即可!
1.3.2.1 减少拷贝
//传值返回
int Func()
{
static int a = 0;
return a;
}
int main()
{
int c = Func();
return 0;
}
//引用返回
int& FUNC()
{
static int a = 0;
return a;
}
int main()
{
int c = FUNC();
return 0;
}接下来仔细对比这两个函数,它们唯一的区别就是返回值类型的不同,那它们到底有什么区别呢?
我们现在来画出其对应的函数栈帧深入理解一下:

上面是传值返回的Func的函数栈帧:我们可以看到虽然a是静态区的变量(出了Func的函数栈帧不会被销毁)但是在返回时还是要开辟一个空间来临时保存a的值,这就造成了空间上的浪费(直接传a的空间的值不好吗)

上面是传值返回的FUNC的函数栈帧:在返回时没有开辟空间来临时保存a的值,相当于直接将a的别名拿去给了c,c被赋值成了a别名的值(就是a的值)。
经过两者函数栈帧的对比我们可以发现:引用返回相对于直接返回可以减少空间的额外开辟,减少了拷贝提升了效率。
❗注意:引用返回时,传的变量的一定是出了传引用返回的函数的函数栈帧还未销毁的变量,不然将会造成空间的非法访问。
1.3.2.2 调用者可以修改返回对象
我们再来看一个实际操作:
#define N 10
typedef struct Arry//静态顺序表
{
int a[N];
int size;
}AY;
int& PosAt(AY& ay,int n)//该函数可以对顺序表内的数组第n个数据进行访问
{
assert(n < N);
return ay.a[n];
}
int main()
{
AY arr;
for (int i = 0; i < N; i++)
{
PosAt(arr, i) = i;
}
for (int i = 0; i < N; i++)
{
cout << PosAt(arr, i) << endl;
}
return 0;
}我们来看一下运行结果

我们发现创建的顺序表arr中的数组每一个都被赋值了。
现在来看一下main函数中的两个for循环到底起了什么样的作用:
第一个for循环:在每一次循环中都将PosAt函数传回的顺序表中的数组元素的引用赋值了。
第二个for循环:在每一次循环中都将PosAt函数传回的顺序表中的数组元素的引用打印了。
现在我们从这个例子中可以知道引用返回时,我们可以对返回的引用进行修改。
1.3.3 常引用
引用也可以用const来进行修饰
❗下面要注意一点:引用和指针一样,只能进行权限保持或缩小不能进行权限放大。
下面就是一个错误示范:

a和*p本身就是const常量(只能读不能写),给它们取一个别名就能改变它的本质了吗?
不能!这是极其不合理的!
1.3.3.1 权限保持
如下,a和b,p和p1都是const常量,权限并没有改变(称为权限保持):
//权限保持
const int a = 0;
const int& b = a;
const int* p = NULL;
const int* p1 = p;1.3.3.2 权限缩小
如下,a和p为普通变量,b和p1都是const常量,权限从可读可写变成了只可读不可写,将权限的范围缩小了(称为权限缩小):
//权限缩小
int a = 0;
const int& b = a;
int* p = NULL;
const int* p1 = p;1.3.3.2 不同类型的常引用
我们现在看下面这个例子:
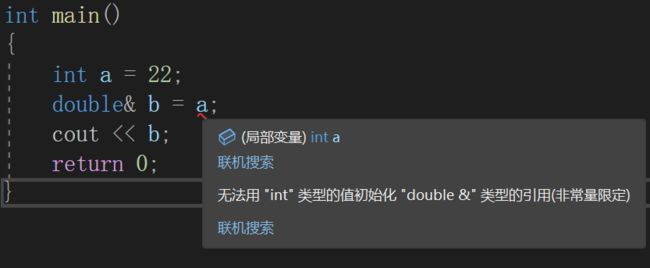
我们可以很好的理解为什么这里会报错,因为int和double根本不是一个类型嘛!
那这样呢:

什么?居然成功通过编译并且运行了?为什么?
在这里我们知道一个知识:a是int类型的变量,在给b引用之前系统首先要临时开辟一块空间来将a的int类型转换为double类型并且将转换结果保存在临时空间中,最后再将这临时空间交给b进行引用,所以b引用的不是a而是保存结果后的临时空间!(由于临时空间是常量,所以这里需要用const来修饰b)
1.4 引用和指针的区别
引用从语法上来说是给别的变量起别名是不需要另外开辟空间的,而指针是储存地址时必须要开辟空间的。
但是从底层汇编来看引用也是需要开辟空间的!
下面是举例:

我们可以看到:在实现*p和b的汇编语言中都存储了a的地址,使用引用的底层就是用指针来实现的。
下面我们来谈谈引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
二、内联函数
在C语言中我们对于不复杂的功能可以使用宏来替代函数提升运行效率
但是由于宏是直接替换,并且不能对所输入的参数类型进行检查,导致其非常难掌握而且使用起来非常复杂。
在C++中为了保有宏的高效率特点,并且避免其缺点,引进了内联函数
2.1 内联函数的使用方法
具体操作:即在普通函数前加上inline关键字
如果在函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用(减少栈帧的使用)
举例:
int Add(int a, int b)//普通函数
{
return a + b;
}
inline int ADD(int a, int b)//内联函数
{
return a + b;
}我们来看一下其运行时函数栈帧的使用情况:
查看方式: 1. 在release模式下,查看编译器生成的汇编代码中是否存在call Add 2. 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不 会对代码进行优化,以下给出vs2022的设置方式)


这两步修改完成后我们来进行调试:
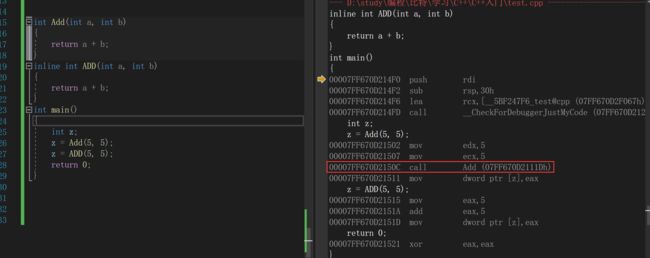
我们可以发现Add函数栈帧中是有call指令的,而ADD函数栈帧中并没有。
2.2 内联函数的特性
1. inline是一种以空间换时间的做法(编译后的.exe运行文件指令会增多),如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址 了,链接就会找不到。
三、关键字auto
我们在初始化的变量的时候除了可以自己定义变量的类型还可以直接交给关键字auto
具体操作为:auto 变量名 = 初始化数据
我们接下来看看这个例子:
int a = 0;
auto b = a;
auto c = 8.0;
auto p = &a;
cout << "b的类型为:" << typeid(b).name() << endl;
cout << "c的类型为:" << typeid(c).name() << endl;
cout << "p的类型为:" << typeid(p).name() << endl;❗注意:typeid( ).name() 可以打印typeid的( )中的变量类型
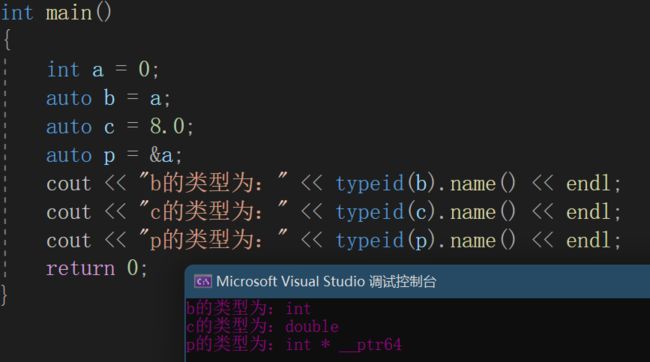
我们可以看到auto自动识别的b、c、p分别为int、double和int*,很好将变量进行了类型的初始化
但是在我们看来int、double这些类型用auto来替代并没有什么实际意义,但是在后期我们在使用C++中的容器时变量名将会非常长,这时用auto自动推导类型就显得方便很多了。
❗另外要注意的是关于auto来推导指针的变量
例如以下代码:
int a;
auto p1 = &a;
auto* p2 = &a;
cout << "p1的类型为:" << typeid(p1).name() << endl;
cout << "p2的类型为:" << typeid(p2).name() << endl;运行结果为:
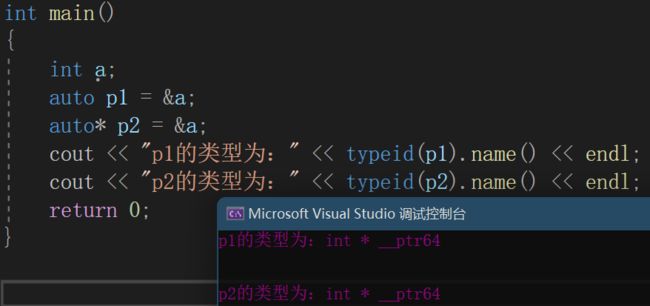
我们可以看到p1和p2都是int*类型的指针,说明初始化指针变量时auto*和auto是等价的
但是用auto声明引用类型时则必须加&
另外介绍以下auto不能推导的场景:
1. auto不能作为函数的参数

2. auto不能直接用来声明数组
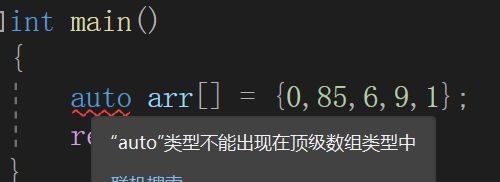
3. auto一行推导多个变量时,其类型必须相同

四、基于范围的for循环(C++11)
我们在C语言中想要遍历一个数组我们需要酱紫:
int arry[] = { 0 ,1,2,6,8,9,45,54 };
for (int i = 0; i < sizeof(arry) / sizeof(int); i++)
{
printf("%d ", arry[i]);
}而在C++中我们可以直接用基于范围的for循环来搞定
下面来举个栗子:
int arry[] = { 0 ,1,2,6,8,9,45,54 };
for (auto a:arry)
{
cout << a << " ";
}
cout << endl;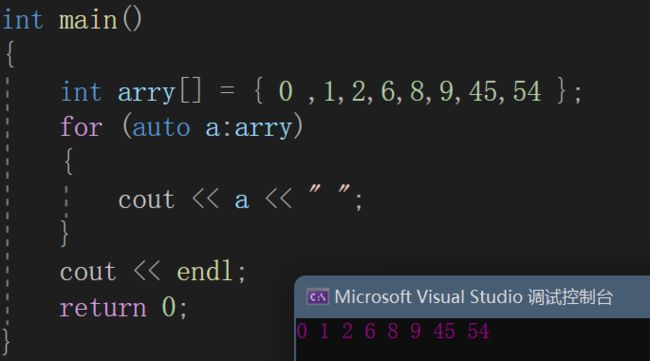
这个for循环的意思就是自动取数组arry中的值赋予可自动识别的变量的a,并且自动判断结束
其中变量a的类型不一定非要是auto,变量名也不一定非要是a,具体自己想怎么取就怎么取,对于这个int类型的arry数组我们也可以直接用int类型的变量来接收:
int arry[] = { 0 ,1,2,6,8,9,45,54 };
for (int x:arry)
{
cout << x << " ";
}
cout << endl;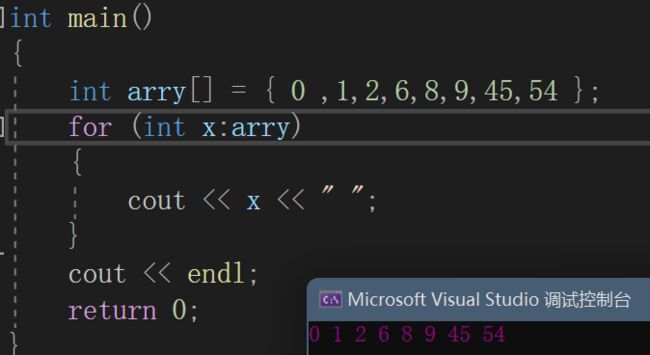
在实际使用中还是推荐auto类型的变量,这样对任何类型的数组都可以接收
现在我们尝试对arry数组的值进行一些改变:

发现我们对x变量进行修改,但是arry数组本身并没有进行改变,这是为什么呢?
这是因为x是单独的变量呀,改变x变量不能修改arry数组本身,它们两压根就不是同一块空间
所以我们想要对数组本身进行修改,在这里可以用到引用:
int arry[] = { 0 ,1,2,6,8,9,45,54 };
for (auto &x:arry)
{
x *= 2;
cout << x << " ";
}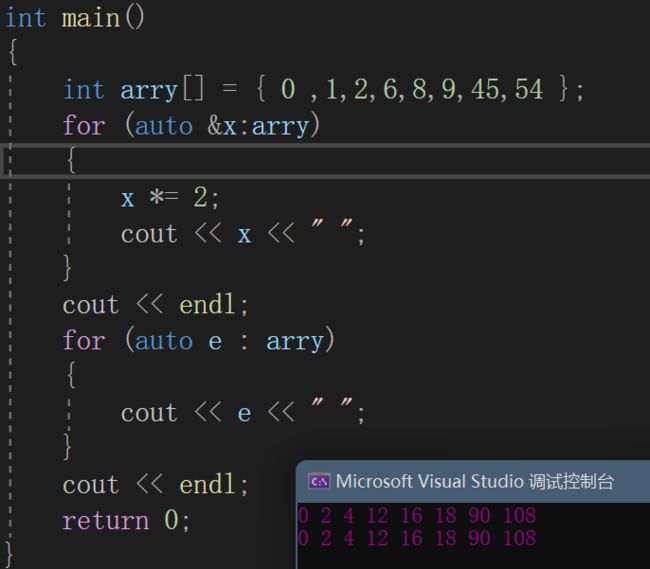
这样子就可以很好对数组本身进行修改了,x就是对数组元素引用,改变x就是改变数组本身
五、指针空值nullptr(C++11)
在C语言中我们一般是这样给指针赋予空值的:
int* p1 = NULL;但是在C++中还可以这样给指针赋予空值:
int* p2 = nullptr;这两种赋值到底有什么区别呢?
我们拿函数重载来举例:
void f(int p)
{
cout << "f(int)" << endl;
}
void f(int* p)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
return 0;
}按函数重载来说,f(0)应该打印"f(int)",f(NULL)应该打印"f(int*)"
可是结果却令人诧异:

为什么传入NULL会被编译器识别为int类型呢?
这是在C++中NULL是这样被定义的:

为了补好这个缺陷,C++11在语法中添加了一个关键字:nullptr
现在我们来使用一下nullptr:

这才符合逻辑嘛~
❗下面要注意三点:
1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
到这里又要和各位看客们说866了~
最后祝大家阖家团圆!元宵节快乐!