Hadoop-3.3.4完全分布式安装(包含VMware16和Ubuntu22的下载安装及配置)、搭建、配置教程,以及Hadoop基础简介
一、Hadoop简介
1、Hadoop项目基础结构
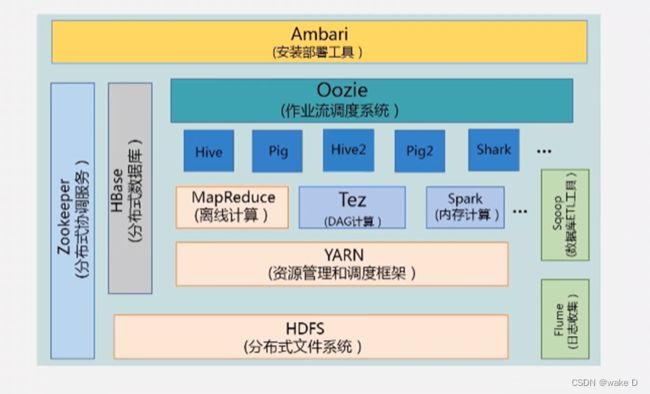
注:本篇文章主要涉及到:HDFS(分布式文件系统)、YARN(资源管理和调度框架)、以及MapReduce(离线计算)。以下就是本篇文章所采用的的架构。
2、Hadoop组成架构
(1)HDFS架构简述
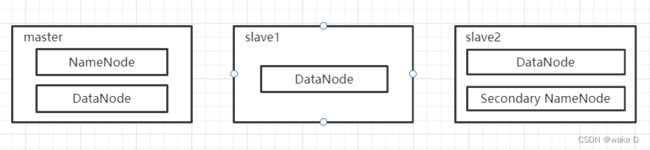 HDFS架构图
HDFS架构图
注:上述的master、slave1、slave2均是主机名(结点名),可以和本篇文章不一致,但下面所有涉及到的地方均需和你这里的主机名一致,如何修改文章后面部分会进行介绍。
① NameNode :NameNode是HDFS部分的核心;NameNode又称为Master,储存着HDFS的元数据(即分布式文件系统中所有文件的目录树,并且跟踪追查整个Hadoop集群中的文件);NameNode本身不储存实际的数据或者是数据集,数据本身是储存在DataNode中;注意当NameNode这个节点关闭之后整个Hadoop集群将无法访问。
② DataNode:DataNode负责将实际的数据储存在HDFS中,DataNode也称作Slave,并且NameNode和DataNode会保持通信不断;如果某个DataNode关闭了之后并不会影响数据和整个集群的可用性,NameNode会将后续的任务交给其他启动着的DataNode;DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向 NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效;block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时。
③ Secondary NameNode:Secondary NameNode主要是用于定期合并并且命名空间镜像的编辑日志;Secondary NameNode中保存了一份和NameNode一致的镜像文件(fsimage)和编辑日志(edits);如果NameNode发生故障是则可以从Secondary NameNode恢复数据。
(2)YARN架构简述
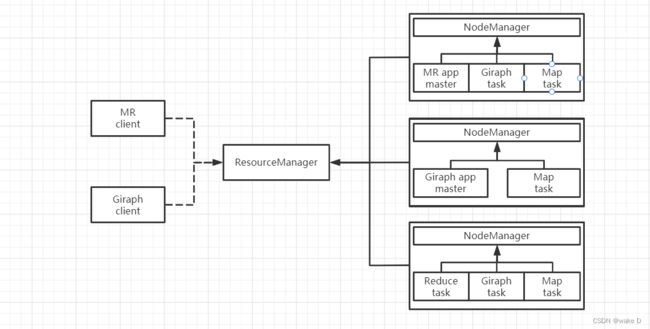 YARN架构图
YARN架构图
① ResourceManager:ResourceManager主要是负责与客户端交互,处理来自客户端的请求;启动和管理ApplicationMaster,并且在其运行失败的时候再重新启动它;管理NodeManager,接收来自NodeManager的资源汇报信息,并向NodeManager下达管理指令;资源管理与调度,接收来自ApplicationMaster的资源申请请求,并为之分配资源。
② NodeManager:NodeManager主要负责启动后向ResourceManager注册,然后与之保持通信,通过心跳汇报自己的状态以及接受来自RM的指令;监控节点的健康状态,并与ResourceManager同步;管理节点上所有的Container的生命周期,监控Container的资源使用情况,以及Container运行产生的日志,NodeManager会向ResourceManager汇报Container的状态信息;管理分布式缓存,以及不同应用程序的其他附属要求。
(3)MapReduce架构简述
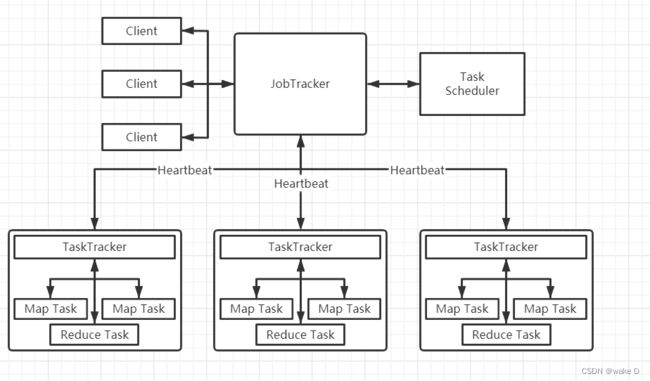 MapReduce架构图
MapReduce架构图
① Client客户端:用户可以通过Client客户端将自己编写的一些MapReduce程序给提交到JobTracker;也可以通过其提供的一些API查看一些作业的运行状态。
② JobTracker:JobTracker主要是负责作业调度和资源的监控;JobTracker如果发现有一些作业失败的情况,就会将对应任务给转移到其他的结点;JobTracker同时也会追踪任务的执行进度和资源的使用情况,并将这些情况转发给Task Scheduler(任务调度器),Task Scheduler调度器在资源出现空闲的时候会将这些资源分配给合适的作业。
③ TaskTracker:TaskTracker会周期性的通过心跳(Heartbeat)将自己结点的资源使用情况以及作业的运行进度发送给JobTracker,同时也会接收JobTracker发送回来的指令并执行;TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等),一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用;slot分为Map slot和Reduce slot两种,分别供Map Task和Reduce Task使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
④ Map Task:Map Task会将对应的数据解析成一个键值对(key/value),最后调用用户的map()函数处理,将临时的结果储存在本地的磁盘上,其中一个临时的结果会被划分成若干块,每一块会被一个Reduce Task处理。
⑤ Reduce Task:将排序好了的键值对一次读取,再调用用户的reduce()函数进行处理,最后将处理结果储存在HDFS上面。
二、VMware下载安装及Linux虚拟机配置(Ubuntu22.04.1)
1、VMware_16.2.4下载安装
VMware_16.2.4下载(官网):https://www.vmware.com/cn/products.html

点击下载试用版,后面会给出许可证密钥。
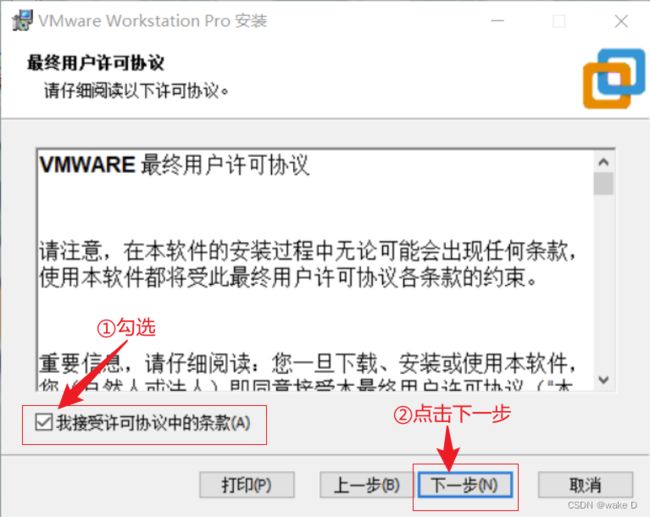
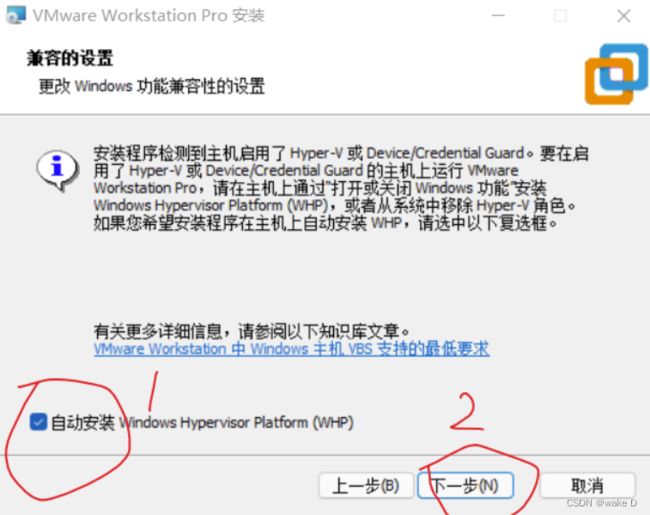
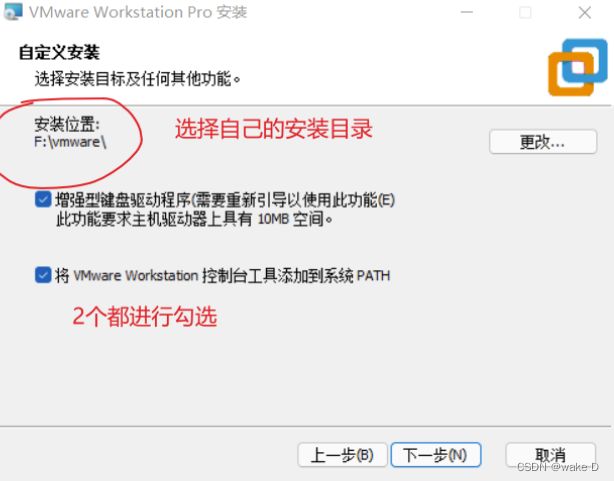


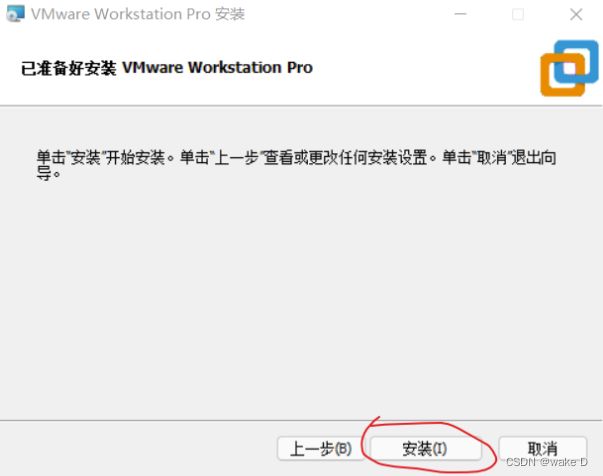
安装完后一定要点击许可证,不然只能试用30天,密钥在下面给出。
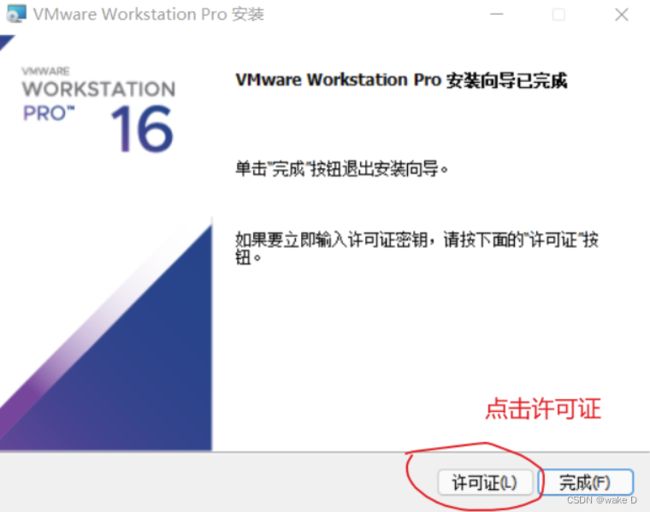
这里许可证的密钥可以去网上找一个填起,网上很多这种一搜就出来了。
2、在VMware_16.2.4上安装Linux虚拟机(Ubuntu22.04.1)
(1)下载Ubuntu22.04.1
Ubuntu22.04.1官网下载地址:https://ubuntu.com/download/desktop
① 点击Download下载最新的Ubuntu版本。
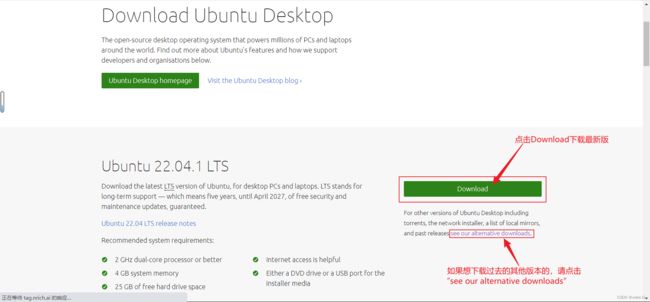
如果想下载过去的其他版本,就点击“see our alternative downloads”,然后进入新页面,向下滑动,找到如下区域,然后点击Past relases。
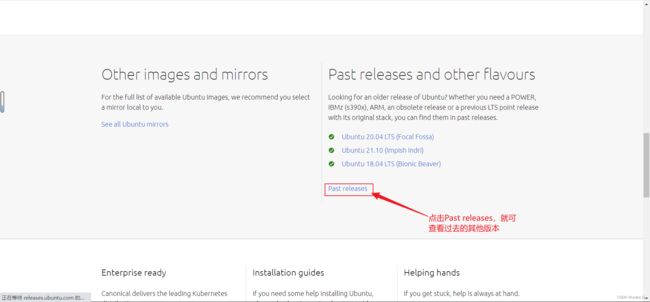
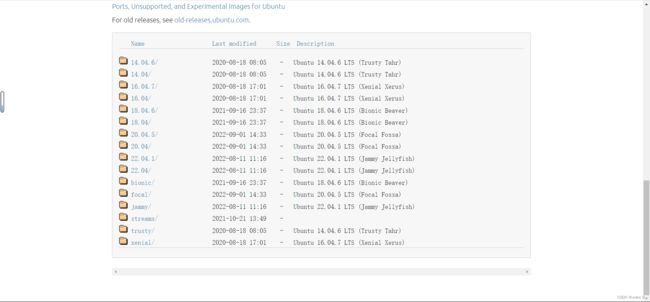
点击Past releases后进入新的页面后下滑,就可以看到如下列表,然后根据个人需要选择下载。
(2)创建并配置Linux虚拟机
① 打开VMware_16.2.4,点击创建新的虚拟机。

② 先选择自定义,然后点击下一步。
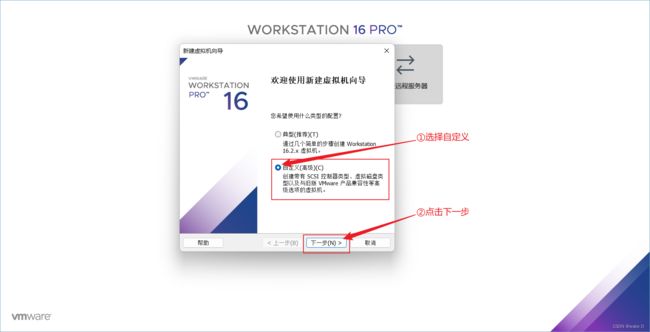
③ 默认选择,直接点击下一步。
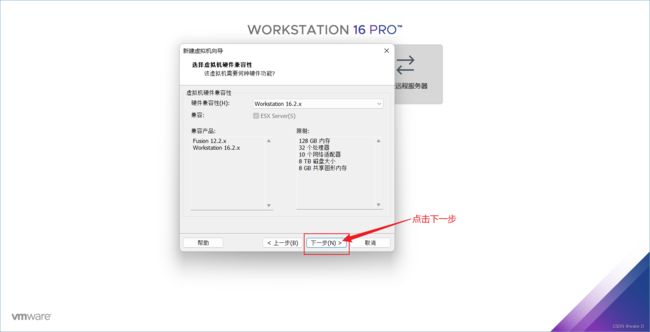
④ 在这里我们先选择稍后安装操作系统(后面会直接指定上面下载好了的Ubuntu22.04.1源文件),然后选择下一步。
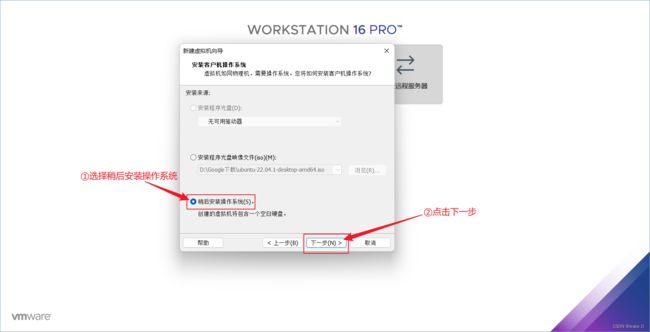
⑤ 选择Linux系统,然后再根据自己电脑实际配置选择Ubuntu操作系统版本,最后点击下一步。
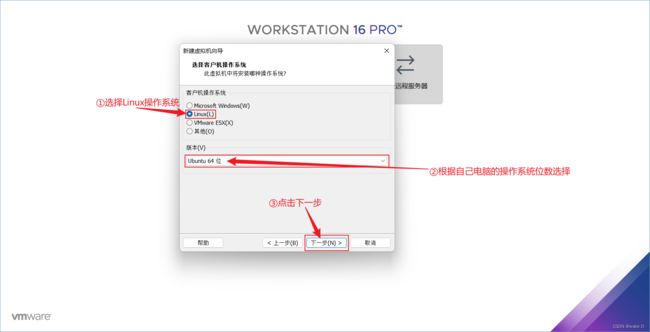
⑥ 选择虚拟机的名字(和主机名不一样,可以自由选择),这里我们取名为Hadoop_m,选择安装目录(自由选择),最后点击下一步。
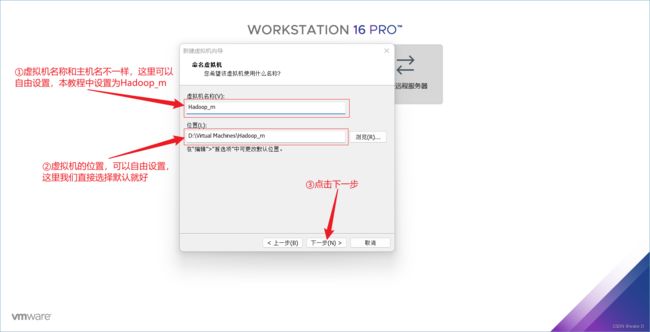
⑦ 选择处理器数量和内核数,我的电脑是8核16线程的,所以我选个2、4,如果你的电脑的配置更高一些可以考虑酌情增加一些。
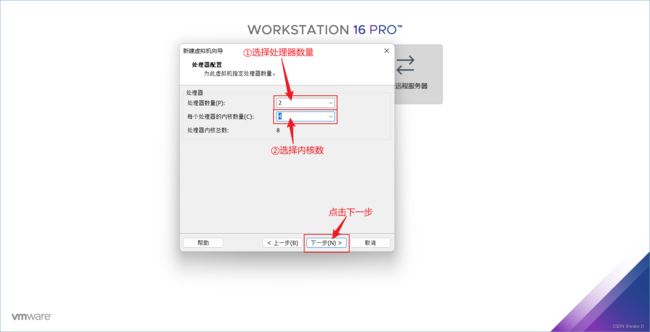
⑧ 选择虚拟机的内存,根据自己需要选择不得低于最低推荐内存,建议直接按照它的推荐内存设置就好,然后点击下一步。
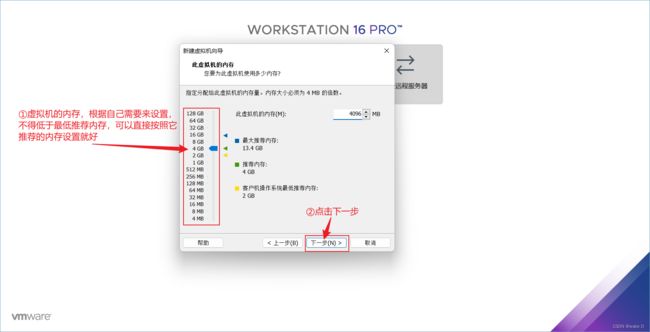
⑨ 选择使用网络地址转换(NAT),然后点击下一步。
⑩ 选择LSI Logic的I/O控制器类型。
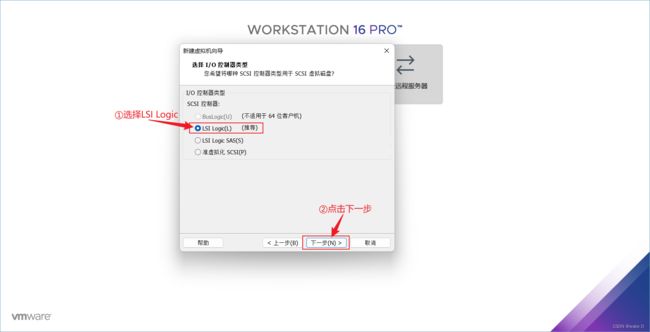
⑪ 选择SCSI的磁盘类型,然后点击下一步。
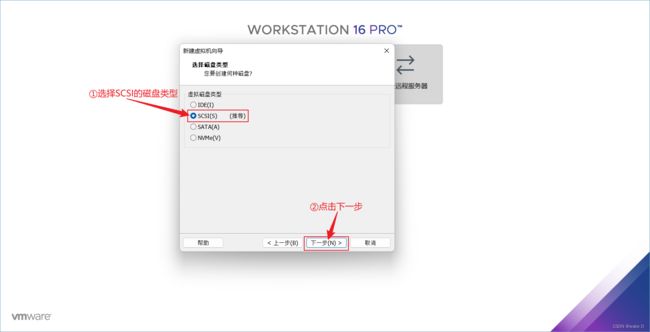
⑫ 选择创建虚拟磁盘,然后点击下一步。
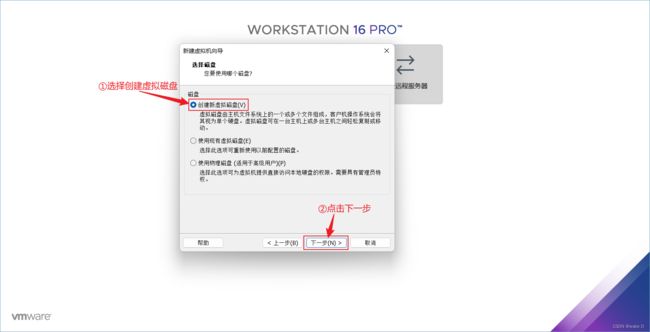
⑬ 选择磁盘的大小,根据自己的电脑实际配置来选择,最好不要低于它的推荐大小,然后选择将虚拟磁盘拆分为多个文件,最后点击下一步。
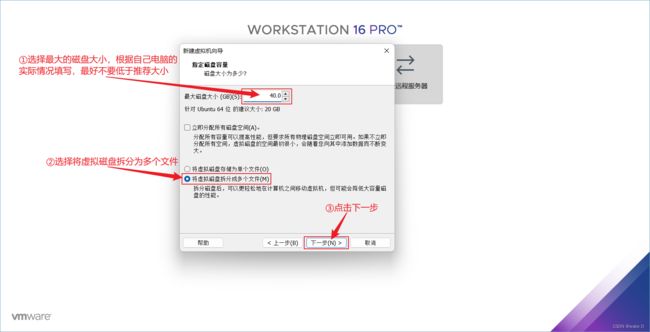
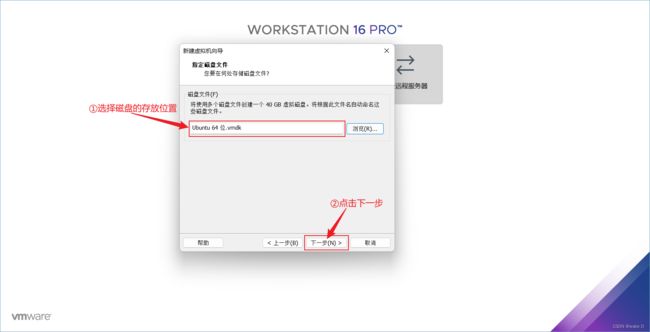
⑭ 选择磁盘的存放位置,然后点击下一步。
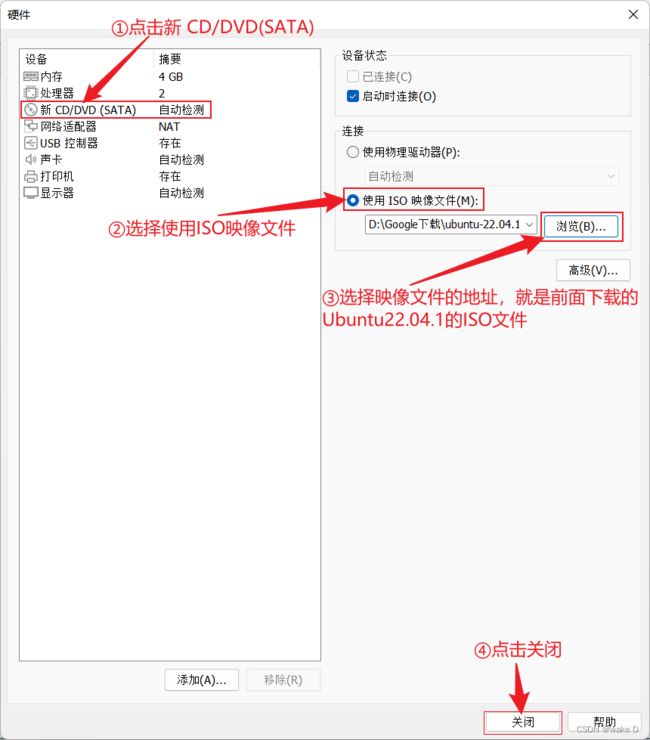
⑮ 点击自定义硬件,配置映像文件的位置。
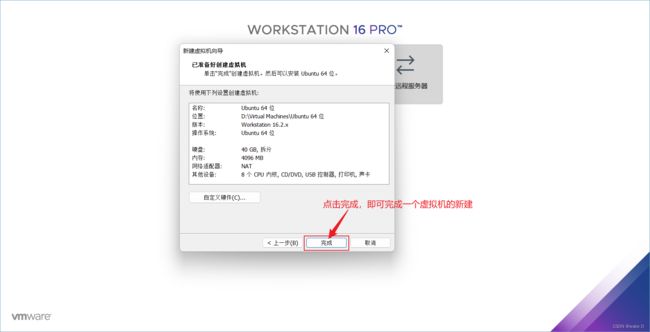
⑯ 点击完成,即完成了一个Linux虚拟机的新建。
(3)安装配置Ubuntu22.04.1
① 打开刚新建好的Linux虚拟机。
② 直接回车。

③ 选择语言,然后点击安装Ubuntu。
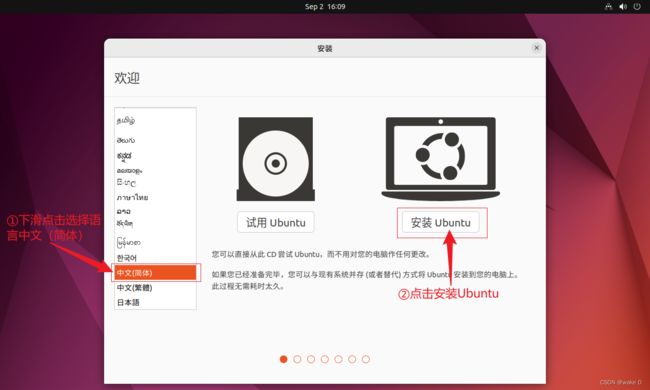
④ 选择中文键盘布局,然后点击继续。
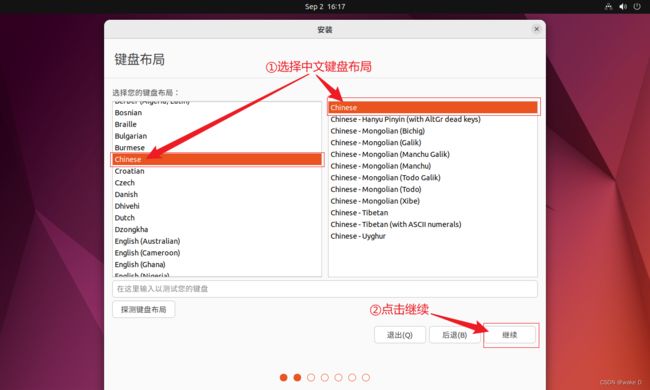
⑤ 点击选择正常安装,然后尽量勾选上安装时下载更新,最后点击继续。
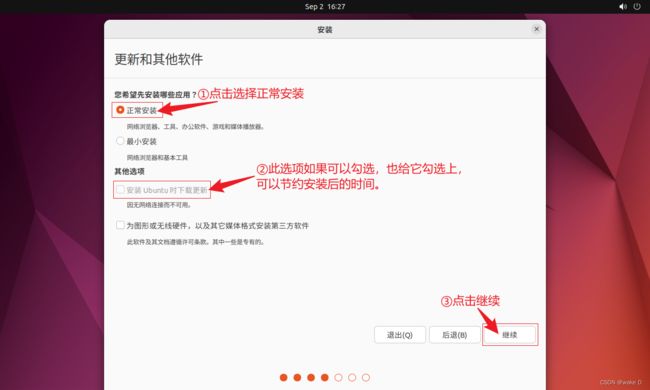
⑥ 先选中清除整个磁盘并安装Ubuntu,然后点击现在安装。

⑦ 点击继续。
⑧ 选择自己所在的地区,然后点击继续。
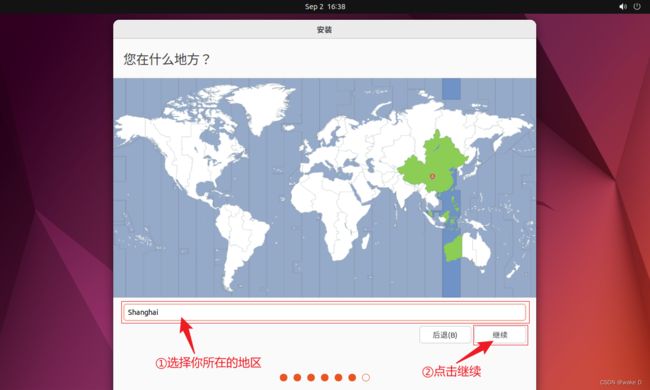
⑨ 这里需要注意一下主机名的设置,主机名可以和我的不一样但是后面一定要和你自己的主机名统一,其他的选项自己随便填就好。
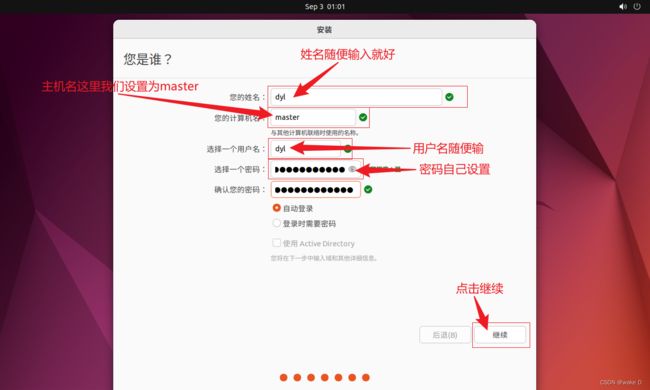
⑩ 安装完成后,点击现在重启。
最后启动成功输入密码进入下面的桌面

(4)网络配置 (IP设置)
| 主机名 | IP地址 |
| master | ***.***.***.130 |
| slave1 | ***.***.***.131 |
| slave2 | ***.***.***.132 |
注:打*号的部分就和你们自己电脑上VMware中的虚拟网络配置里的VMnet8里的子网IP的前三位一样,每个人的不一样,所以你们自行替换。文章下面点会提到IP设置,这里有个印象就好。
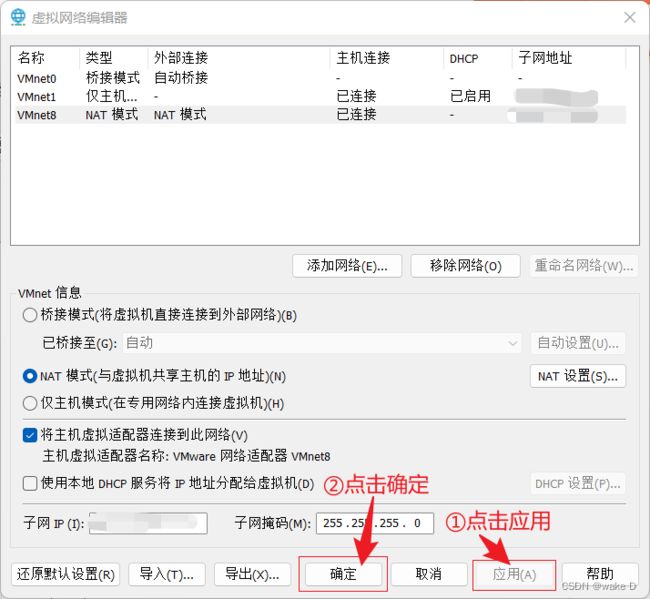
① 在VMware主页点击编辑 。
② 选择虚拟网络编辑器。
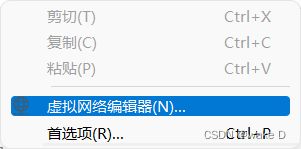
③ 先点击选择VMnet8,再选择更改设置。
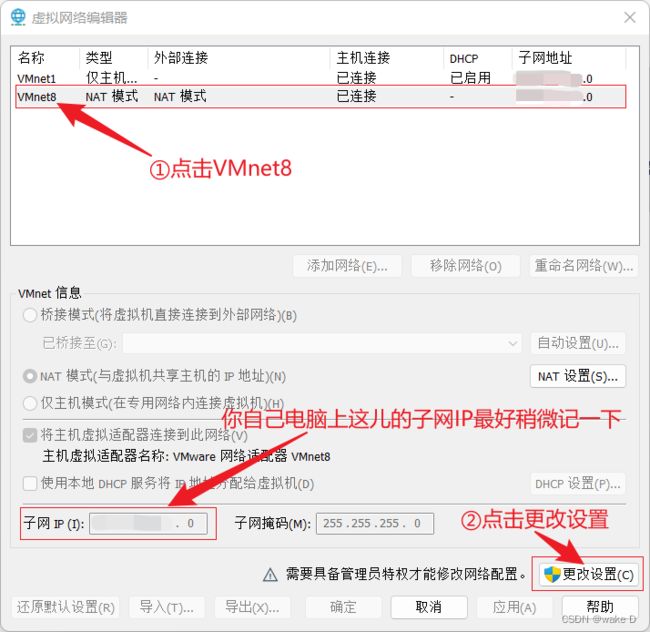
④ 先点击VMnet8,后面再点击NAT设置。
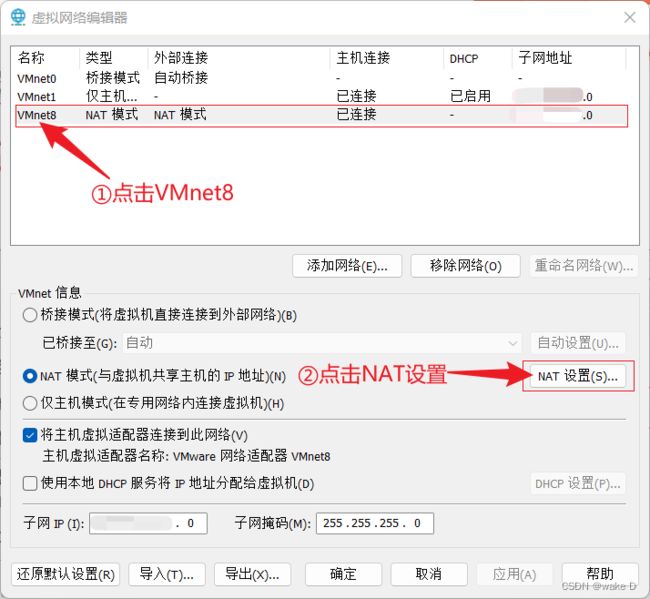
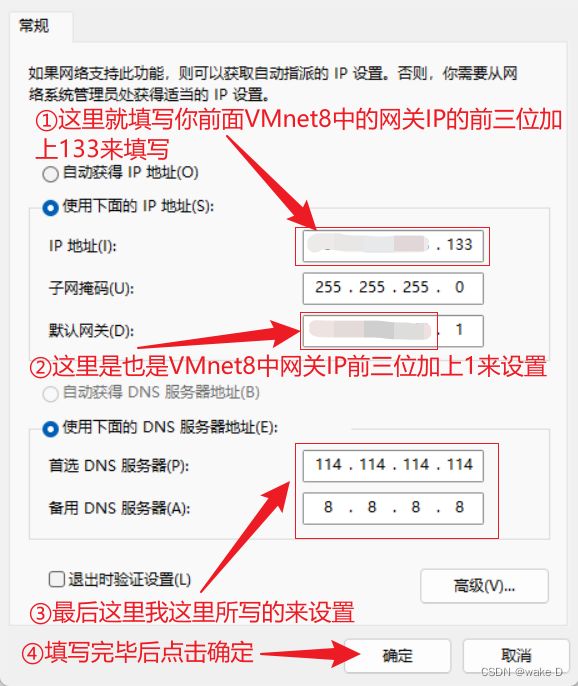
⑤ 先把网关IP填上,前三位就直接按照子网IP的前三位直接复制粘贴,最后一位补一个2,最后点击确定。
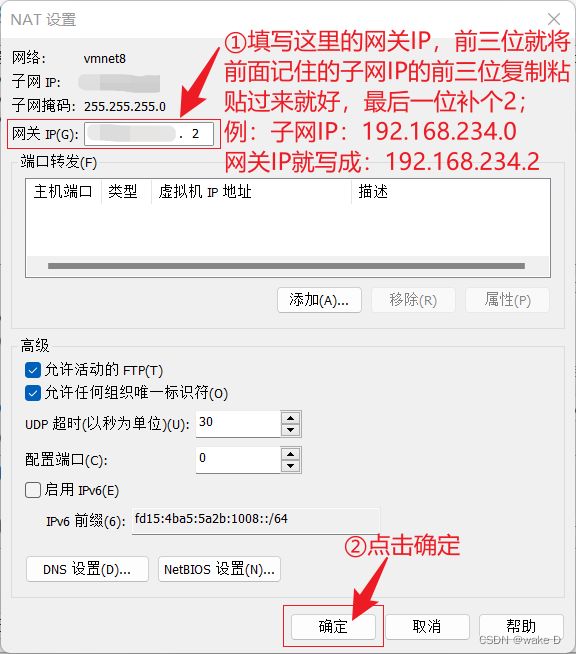
注:这里的网关IP最好记下来后面还得用。
⑥ 点击应用,再点击确定。
⑦ netplan中网络配置文件修改,打开Linux虚拟机Hadoop_m(master),Ctrl+Alt+t打开命令行输入如下命令。
cd /etc/netplan #转移目录到netplan文件夹中
ls #ls是查看当前目录下的文件的命令
sudo chmod 777 01-network-manager-all.yaml #给文件添加可读、写、运行的权限
vi 01-network-manager-all.yaml #vi是查看(修改)文件内容的命令例:
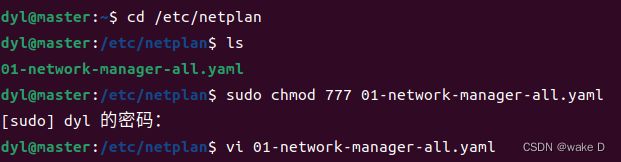
sudo是以管理员的权限来执行命令,chmod 777是给文件添加一个可读、写、运行的权限,vi是查看(修改)一个文件,这里输入的密码就是你的用户密码(输入的密码是不可见的,所以不必疑惑)。
也可以直接点击文件->其他位置->计算机->etc->netplan目录下去修改对应文件。
然后进入到如下页面,在将如下内容填写到文件里,因为可能存在格式问题,建议直接复制粘贴,最后在修改,修改的时候并不能直接输入,按一下键盘上的Insert(Ins)键就可以进入插入模式,按一下ESC就可以退出插入模式,当复制粘贴后,再修改了你的IP和网关后,点击ESC,然后在输入英文冒号,在输入wq,最后点击回车就可以退出文本编辑,如果不行,就输入wq!,加一个感叹号强行执行再回车,要是再不行就直接Ctrl+z强制停止。
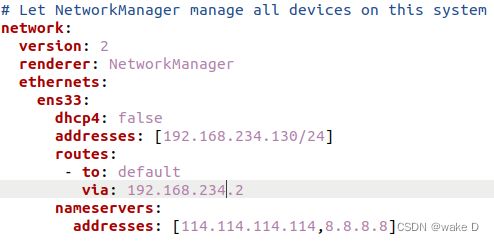
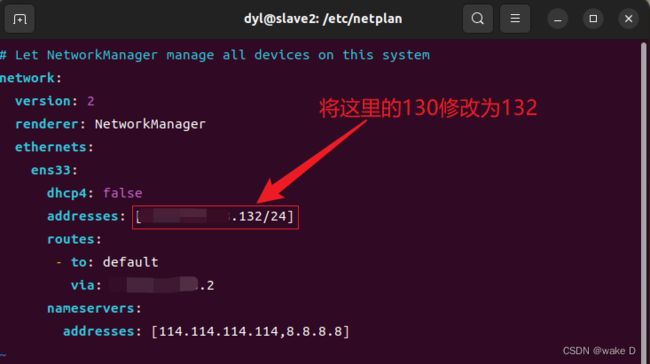
注:虚拟机的IP地址前三位必须得和前面配置VMnet8里的网关IP的前三位一样,最后一位自己自由选择但是不能和前面VMnet8里的IP或者自己电脑本机的IP一样,而且也不能和后面其他两个slave结点的主机IP一样;例:前面的网关IP是:192.168.234.2,那么本结点的主机IP就可设置为:192.168.234.130。
ethernets:
ens33:
dhcp4: false
addresses: [***.***.***.130/24] #打*号部分就是你前面VMnet8的网关IP的前三位
routes:
- to: default
via: ***.***.***.* #打*号的部分填写前面你的VMnet8的网关IP
nameservers:
addresses: [114.114.114.114,8.8.8.8]注:上面打*号的部分记得替换成自己VMnet8中设置的。address后面的中括号中除开“/24”其它的部分就是你这台虚拟机的IP;via后面的就是前面的网关IP。
这个文件里填写的IP最好按照你自己电脑上VMware上的虚拟网络配置里的子网IP和网关IP的前三位来修改,我这里的例子只是做个参考。
例:
⑧ 配置完netplan文件夹中的网络配置文件后,保存退出文本编辑,退出命令行编辑文本退出方式就按本文章上面提到的来就好;退出文本编辑回到命令行后再输出如下命令,将刚才修改的网络配置文件进行应用。
sudo netplan apply #应用刚修改的网络配置文件应用完后输入以下命令查看是否配置成功。
ip a #查看本机的ip地址可以用这段命令如果出现以下结果,则说明成功了
转到你自己的windows系统下打开以下目录:
控制面板\网络和 Internet\网络连接
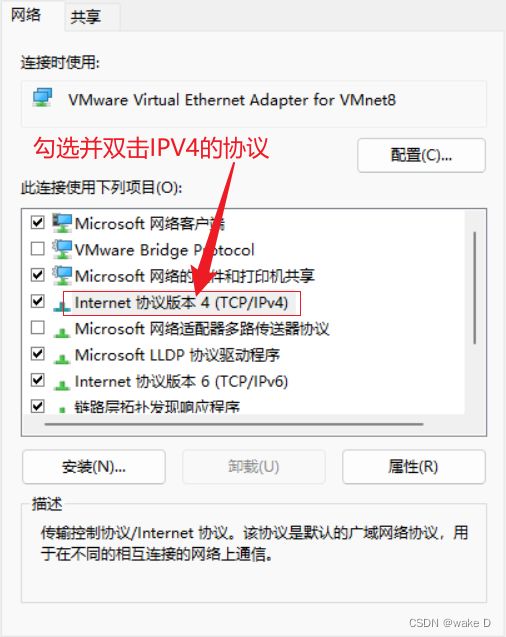
然后一直确定就好。
最后回到虚拟机下,如果不放心可以重启一下虚拟机。
打开你的火狐浏览器,测试一下能否正常上网。
⑨ 安装open-vm-tools
连上网后,我们先换一下软件安装更新的源

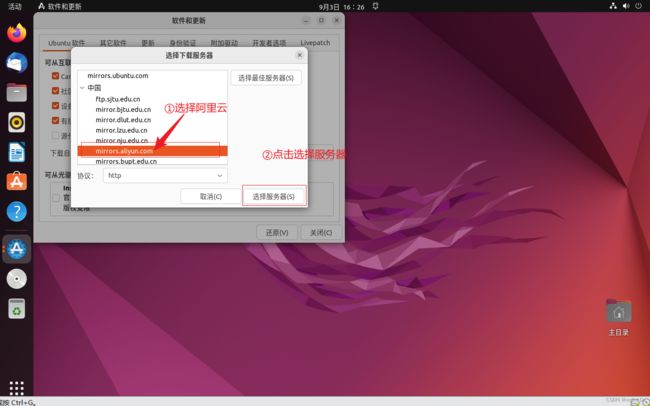
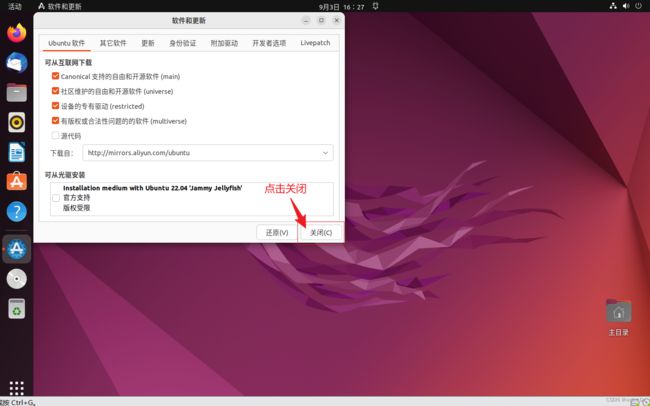
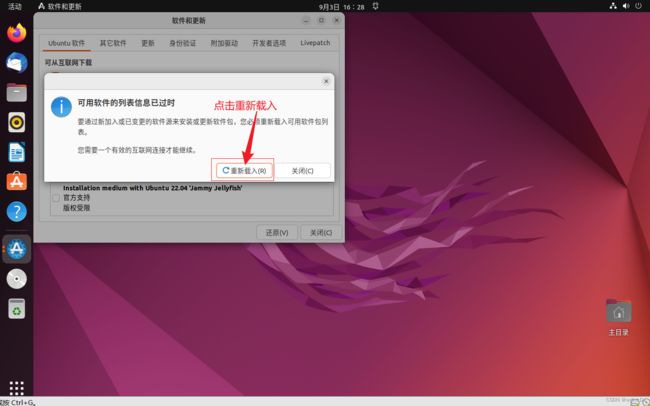
然后,我们打开命令行,输入下面的命令:
sudo apt-get update #更新一下系统源
#输入了上面的代码可能会弹出一个让你更新的窗口,如果有就直接点击现在安装就可以了
sudo apt-get upgrade等待安装更新完后再输入下面的命令:
sudo apt-get install open-vm-tools
#安装open-vm-tools,中间遇到的停顿除了空间请求需要yes一下其他的都直接默认回车
sudo apt-get install open-vm-tools-desktop
#安装open-vm-tools-desktop,用于支持文件双向拖放安装完成后重启虚拟机,然后虚拟机界面就可以自适应了,在自己电脑下复制的东西,也可以直接粘贴到Linux虚拟机上了,也可以直接双向拖拽文件了,十分方便。
最后在安装一个Vim编辑器,感觉比较方便:
sudo apt-get install vim #安装时如果需要确认直接输入Y就好三、Hadoop-3.3.4下载安装、配置,以及JDK下载、配置
1、Hadoop-3.3.4、以及JDK下载
(1)Hadoop-3.3.4下载
由于上一步我们已经连上网了,所以这里我们直接在我们的Hadoop_m虚拟机中打开火狐浏览器下载。
注:本文使用清华大学的开源镜像网站提供的地址下载
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
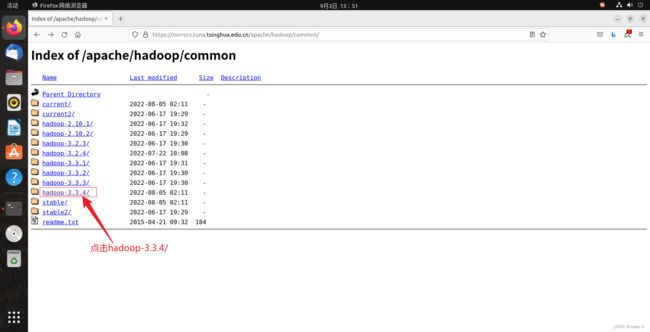
然后进入下一个页面,点击hadoop-3.3.4.tar.gz下载压缩包。
 下载的文件在下载目录下
下载的文件在下载目录下
(2)JDK下载(JDK1.8.0_341)
Oracle官网下载:https://www.oracle.com/java/technologies/downloads/
进入Oracle官网JDK下载页面后下滑到如下页面:
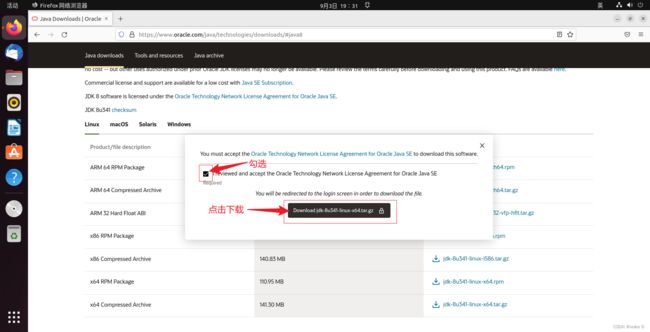
点击下载后需要提供一个Oracle的账号登录才能下载,因为这是Oracle官网,没有的话可以先注册一个。
下载完成后的文件依然在下载目录里面
2、Hadoop-3.3.4以及JDK1.8.0_341的解压缩安装以及环境变量和重要XML文件的配置
(1)JDK1.8.0_341的解压缩安装以及环境变量的配置
① JDK1.8.0_341解压缩
首先我们需要创建一个“/usr/lib/jvm”目录来存放JDK的文件
cd /usr/lib #先来到lib目录下面
sudo mkdir jvm #然后在创建一个jvm文件夹mkdir就是创建文件夹的命令,如果需要创建一个文件使用touch命令。
创建好了文件夹后我们再进行如下操作:
cd ~ #首先进入用户的主目录
cd /home/dyl/下载 #然后进入下载目录,我这里的dyl是我的用户名,
#你们记得改成自己的用户名
sudo tar -zxf ./jdk-8u341-linux-x64.tar.gz -C /usr/lib/jvm
#将JDK的压缩文件解压缩到/usr/lib/jvm目录中,tar zxpf是解压缩命令,
#如果在最后不跟上解压缩的路径则会默认解压缩到当前的目录下面注:如果想安装中文输入法的请参考后面的链接:Ubuntu 安装中文输入法_Chamico的博客-CSDN博客_ubuntu中文输入法
如果不想安装的可以直接shift键也可以进行系统自带的中英文切换
注:有些文件时默认不可见的,可以在文件管理器中设置隐藏文件可见,例:
② JDK的环境变量配置
在命令行中输入以下命令:
vim ~/.bashrc #进入主目录下编辑环境变量配置文件进入文件编辑后就像上面说过的那样,点击一下键盘Insert(Ins)键,然后用方向键来操控上下左右,在文件末尾添加如下内容,进入Insert(插入)模式后可以直接鼠标右键复制粘贴,也可以Ctrl+shift+V粘贴:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export JRE_HOME=${JAVA_HOME}/jre
export PATH=${JAVA_HOME}/bin:$PATH
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib添加完毕后,按一下ESC键退出Insert(插入模式),然后再点击英文冒号,输入wq!退出文本编辑
在编辑完.bashrc文件过后,再输入以下命令来使添加的配置生效:
source ~/.bashrc最后在输入下面这段命令,检查JDK是否安装成功:
java -version如果出现以下画面则是安装配置成功:
(2)Hadoop-3.3.4的解压缩安装、以及环境变量的配置
① Hadoop-3.3.4解压缩安装
先将Hadoop-3.3.4解压缩到、/usr/local目录下面:
sudo tar -zxf ~/下载/hadoop-3.3.4.tar.gz -C /usr/local
#将Hadoop3.3.4解压缩到/usr/local目录下面然后输入以下命令进入.bashrc文件配置环境变量:
vim ~/.bashrc在.bashrc文件末尾插入以下语句:
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export PATH=${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH插入完成后退出.bashrc的文本编辑,然后输入以下语句来应用环境变量以及测试是否配置成功:
source ~/.bashrc #应用环境变量
cd ~ #回到主目录
hadoop version #查看hadoop的信息,测试是否成功安装配置出现以下情况则说明配置成功:
(3)Hadoop-3.3.4的核心文件配置
可以直接在文件系统中打开文件直接修改,也可以在命令行中修改,本篇文章采用命令行的形式进行核心文件的修改。
① hadoop-env.sh
首先打开命令行输入以下的命令进入hadoop-env.sh文件中:
cd /usr/local/hadoop-3.3.4/etc/hadoop
#先进入上述目录下,因为hadoop-env.sh文件在这个目录下面
vim hadoop-env.sh #修改文件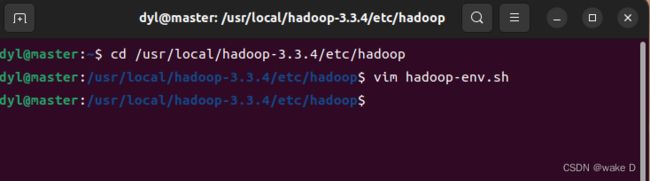
在hadoop-env.sh文件末尾追加以下的内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export HDFS_NAMENODE_USER=dyl
export HDFS_DATANODE_USER=dyl
export HDFS_SECONDARYNAMENODE_USER=dyl
export YARN_RESOURCEMANAGER_USER=dyl
export YARN_NODEMANAGER_USER=dyl
#我这里的dyl是我自己的用户名,你们记得换成你们自己的用户名注:如果在退出文本编辑的时候,出现警告,那么久直接Ctrl+Z终止进程,再输入以下的命令来赋予hadoop目录下所有的文件可更改的权限:
sudo chmod 777 * #赋予当前目录下的所有文件可更改的权限然后再进入文件进行修改保存
② core-site.xml
打开core-site.xml文件:
再在configuration中输入以下内容:
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/usr/local/hadoop-3.3.4/tmp
hadoop.http.staticuser.user
dyl
注:这里面的dyl是我的用户名,请修改成你们自己的用户名
添加完后退出编辑
③ hdfs-site.xml
先打开hdfs-site.xml文件:
然后再在文件的configuration中输入以下内容:
dfs.namenode.http-address
master:9870
dfs.namenode.secondary.http-address
slave2:9868
添加完后退出文件编辑
④ yarn-site.xml
先打开yarn-site.xml文件:
然后再在文件中的configuration中输入以下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
slave1
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.application.classpath
/usr/local/hadoop-3.3.4/etc/hadoop:/usr/local/hadoop-3.3.4/share/hadoop/common/lib/*:/usr/local/hadoop-3.3.4/share/hadoop/common/*:/usr/local/hadoop-3.3.4/share/hadoop/hdfs:/usr/local/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.3.4/share/hadoop/hdfs/*:/usr/local/hadoop-3.3.4/share/hadoop/mapreduce/*:/usr/local/hadoop-3.3.4/share/hadoop/yarn:/usr/local/hadoop-3.3.4/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.3.4/share/hadoop/yarn/*
yarn.log-aggregation-enable
true
yarn.log.server.url
http://slave1:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
yarn.nodemanager.vmem-check-enabled
false
添加完后退出文本编辑
⑤ mapred-site.xml
打开mapred-site.xml文件进行编辑:
在文件中的configuration中输入以下内容:
mapreduce.framework.name
yarn
mapreduce.application.classpath
/usr/local/hadoop-3.3.4/share/hadoop/mapreduce/*:/usr/local/hadoop-3.3.4/share/hadoop/mapreduce/lib/*
mapreduce.jobhistory.address
slave1:10020
mapreduce.jobhistory.webapp.address
slave1:19888
添加完之后退出文本编辑
⑥ workers
打开workers文件:
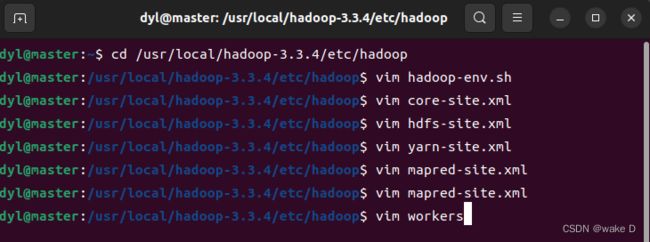
然后再在文件中输入以下内容:
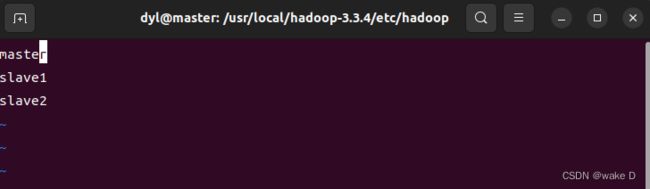
这里的master是此台虚拟机的主机名,slave1、slave2是后面我们将会克隆的另外两台虚拟机的主机名。
设置好后退出文本编辑。
注 :不能有空格也不能有空行
(4)Hadoop从属结点虚拟机克隆、以及配置
① 关闭master主结点的虚拟机,然后进行如下操作:


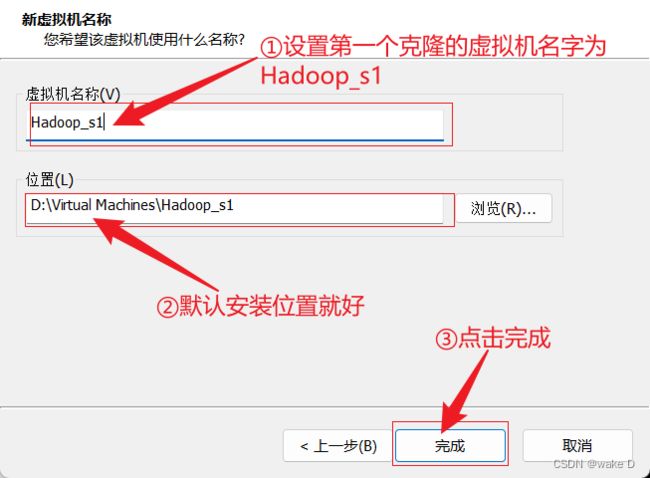
第一个从属结点的虚拟机就克隆完了,接下来第二个从属结点的虚拟机模仿这第一个的步骤来,只不过把虚拟机的名字改成Hadoop_s2就好了。
最终的结果如下三台虚拟机:
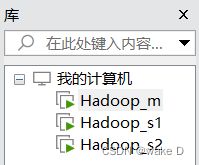
⑤ 依次打开三台虚拟机配置主机名和IP地址
首先先进入Hadoop_s1(slave1)虚拟机下,修改Hadoop_slave1的主机名以及IP地址(因为Hadoop_s1,Hadoop_s2这两台机器是由Hadoop_m这台机器克隆来的,所以主机名和IP都一样,需要修改,否则无法联网),步骤如下:
在Hadoop_s1虚拟机下:
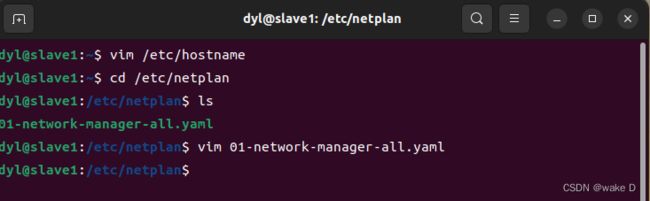
首先在命令行输入以下命令进入hostname文件中来修改主机名:
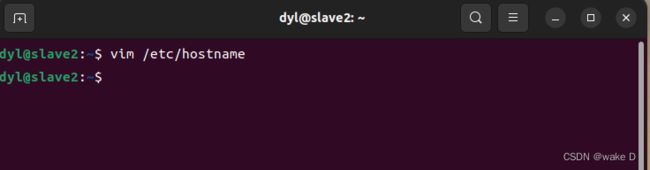
将hostname文件中的主机名修改为slave1(注意不要有空格或者是空行),修改的主机名要重启虚拟机后才会生效,但是我们后面可能还会涉及到重启,所以我们这里先不必重启,最后修改完所有的文件再重启虚拟机。
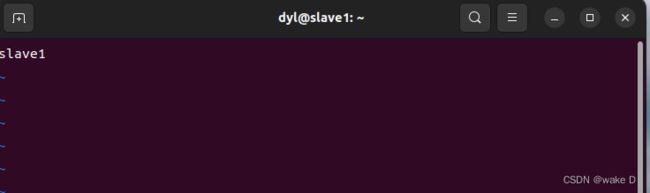
修改完后退出这个文件的编辑。
修改完Hadoop_s1的主机名后就修改IP地址:
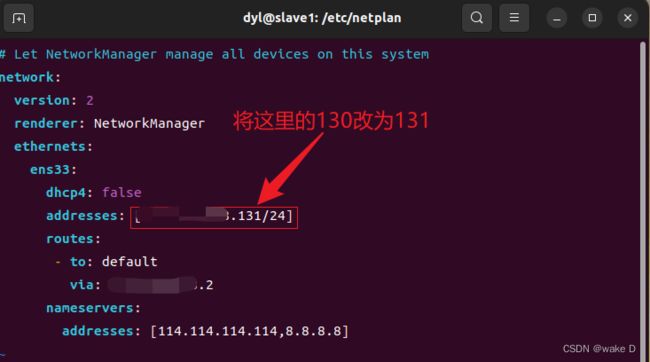
编辑IP地址后退出文件编辑。
而Hadoop_s2这台虚拟机的文件修改也和Hadoop_s1一样:
⑥ 配置三台虚拟机之间的IP映射
首先进入Hadoop_m中确认一下hadoop_m的主机名是不是master:
然后进入hosts文件中配置虚拟机之间的IP映射:
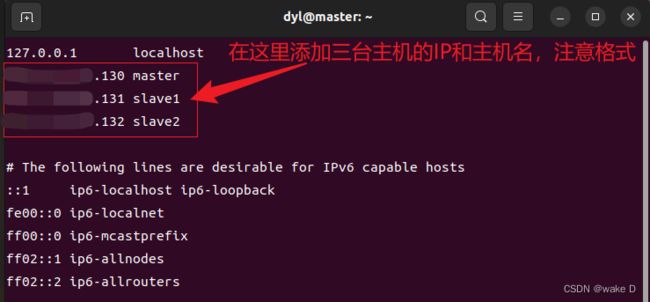
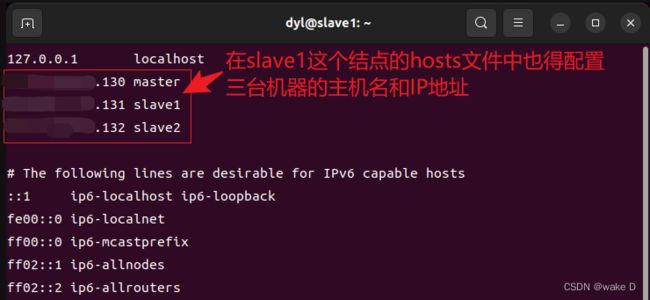
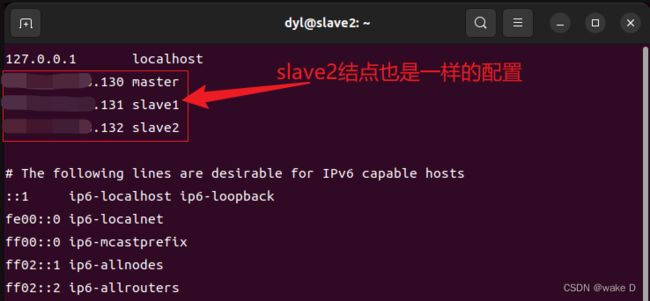
同理,Hadoop_s1,Hadoop_s2这两台虚拟机也要配置IP地址的映射:
Hadoop_s1:
Hadoop_s2:
到此三台机器的IP映射就配置完成了。
(5)三台虚拟机之间的SSH免密登录访问
① 首先分别在三台机器的命令行中输入以下命令安装SSH服务端,因为Ubuntu操作系统已经默认安装了SSH的客户端,所以这里只需要安装SSH服务端就好了:
sudo apt-get install openssh-server② 打开登录到Hadoop_m(master),然后依次输入以下的命令(这里中间需要输入的地方直接一直回车就好了):
cd ~/.ssh/ #将目录转到密钥的生成目录.ssh下面
ssh-keygen -t rsa #生成密钥
cat ./id_rsa.pub >> ./authorized_keys
#将生成的密钥添加到同一目录下的authorized_keys授权文件中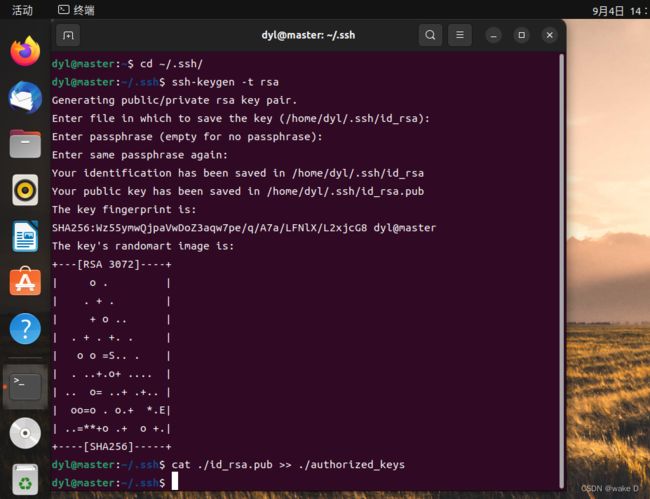
然后在将master的公钥发送到slave1和slave2两台机器上去(这里由于还没建立SSH无密登录,所以连接传送文件的时候还是要输密码,需要输yes的地方只管输yes就是了):
scp id_rsa.pub dyl@slave1:~/.ssh/master_rsa.pub
scp id_rsa.pub dyl@slave2:~/.ssh/master_rsa.pub
#我这里的dyl是我的用户名,你们换成自己的用户名就可以了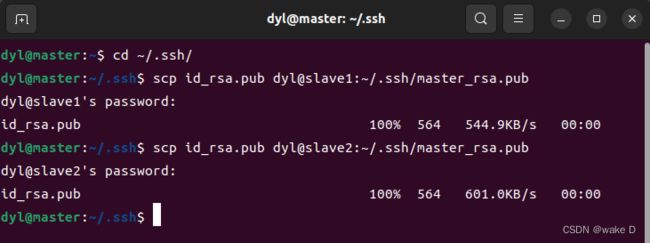
最后在Hadoop_s1和Hadoop_s2的.ssh目录下会出现以下的这个文件:

③ Hadoop_s1和Hadoop_s2的密钥生成以及与Hadoop_m之间的相互映射
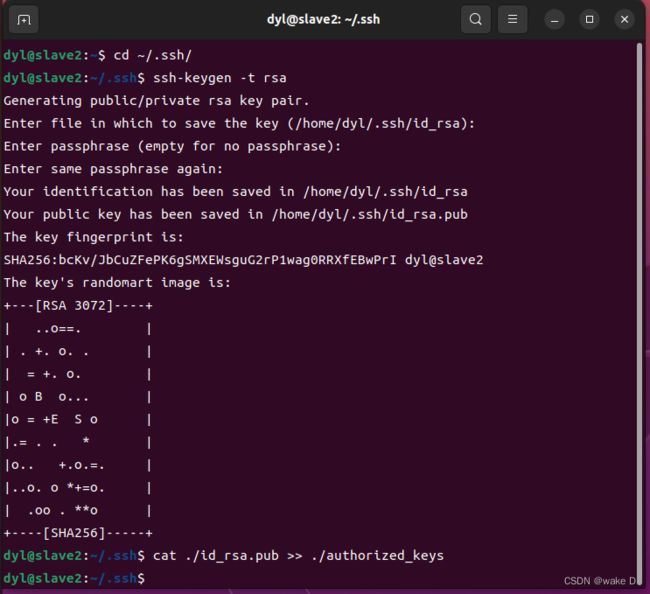
分别在Hadoop_s1和Hadoop_s2的命令行中执行以下命令:
cd ~/.ssh/ #将目录转到密钥的生成目录.ssh下面
ssh-keygen -t rsa #生成密钥
cat ./id_rsa.pub >> ./authorized_keys
#将生成的密钥添加到同一目录下的authorized_keys授权文件中Hadoop_s1:
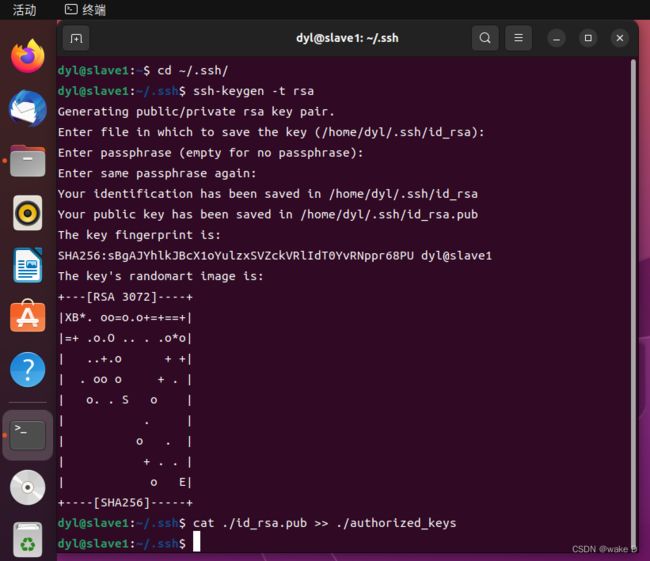
Hadoop_s2:
然后转到Hadoop_s1中将slave1的密钥发送到master和slave2中:
scp id_rsa.pub dyl@master:~/.ssh/slave1_rsa.pub
scp id_rsa.pub dyl@slave2:~/.ssh/slave1_rsa.pub
#我这里的dyl是我的用户名,你们换成自己的用户名就可以了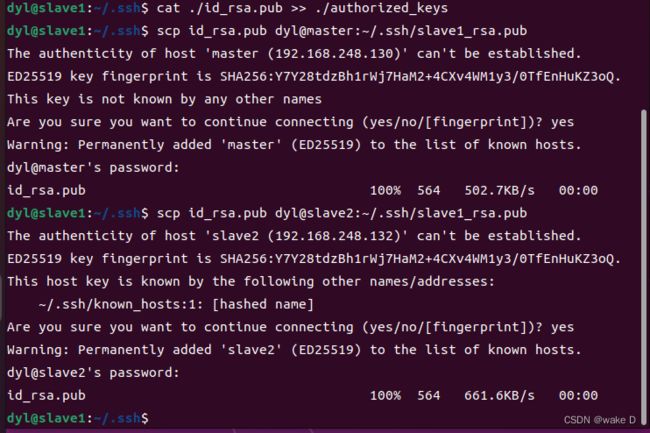
然后在Hadoop_m(master)和Hadoop_s2(slave2)的.ssh目录下就会出现以下文件:

然后转到Hadoop_s2中将slave2的密钥发送给master和slave1:
scp id_rsa.pub dyl@master:~/.ssh/slave2_rsa.pub
scp id_rsa.pub dyl@slave1:~/.ssh/slave2_rsa.pub
#我这里的dyl是我的用户名,你们换成自己的用户名就可以了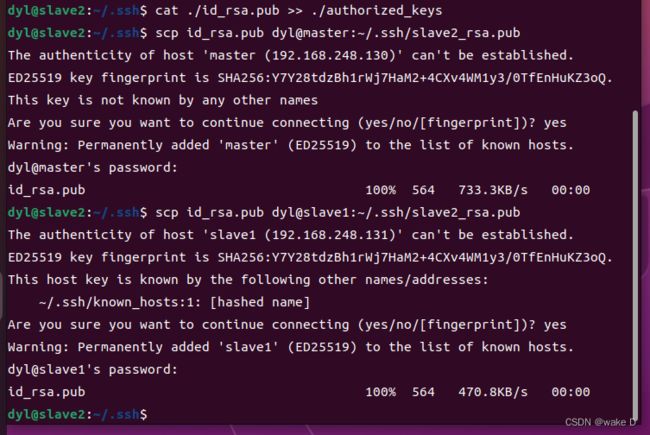 然后在Hadoop_m(master)和Hadoop_s1(slave1)的.ssh目录下就会出现以下文件:
然后在Hadoop_m(master)和Hadoop_s1(slave1)的.ssh目录下就会出现以下文件:

接下来还有最后几步:
在hadoop_m中执行以下命令将slave1和slave2的密钥添加到授权文件当中:
cat ./slave1_rsa.pub >> ./authorized_keys #添加slave1的密钥到授权文件中
cat ./slave2_rsa.pub >> ./authorized_keys #添加slave2的密钥到授权文件中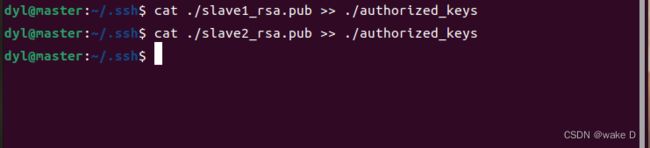
在hadoop_s1中执行以下命令将master和slave2的密钥添加到授权文件当中:
cat ./master_rsa.pub >> ./authorized_keys #添加master的密钥到授权文件中
cat ./slave2_rsa.pub >> ./authorized_keys #添加slave2的密钥到授权文件中
在hadoop_s2中执行以下命令将master和slave1的密钥添加到授权文件当中:
cat ./master_rsa.pub >> ./authorized_keys #添加master的密钥到授权文件中
cat ./slave1_rsa.pub >> ./authorized_keys #添加slave1的密钥到授权文件中 
到此SSH无密登录连接就配置完成了。最后如果不放心的话可以重启一下三台虚拟机
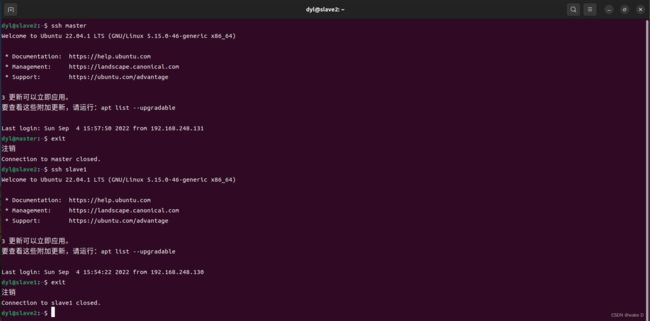
配置好了之后可以分别测试一下配置成功没(第一次连接会输一次密码,后面就不会让你输密码了,可以第一次连上后再exit断开,再测试第二次,看看效果):
master:
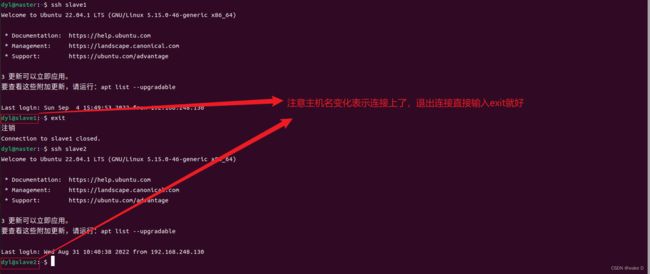
slave1:
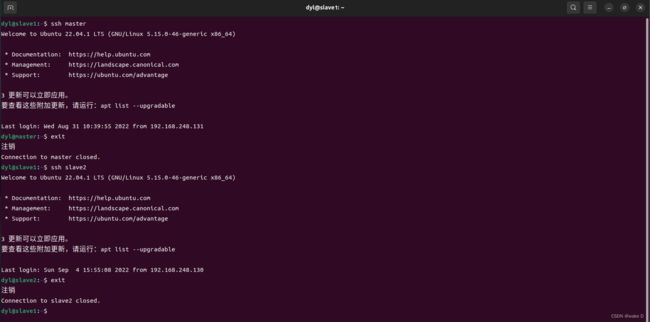
slave2:
到此hadoop集群的基本配置就结束了
四、Hadoop集群测试
1、下面使本篇文章采用的Hadoop集群规划:
| 主机名 | NN | JJN | DN | RM | NM | SNN |
| master | NameNode | DataNode | NodeManager | |||
| slave1 | JournalNode | DataNode | ResourceManager | NodeManager | ||
| slave2 | DataNode | NodeManager | SecondaryNameNode |
2、测试
(1)进入master虚拟机中:
因为是第一次启动集群所以我们需要将文件系统初始化,输入以下命令:
cd /usr/local/hadoop-3.3.4 #进入hadoop-3.3.4的安装目录
./bin/hdfs namenode -format #初始化HDFS文件系统注意:只有第一次启动集群需要初始化HDFS文件系统,如果后续再执行初始化文件系统(格式化NameNode)由于每次初始化都会产生新的集群id,会导致NameNode和DataNode的集群id不一样,导致集群找不到以往的数据。如果非要再格式化一次,那就把三台机器下的/usr/local/hadoop-3.3.4/目录下的tmp和logs文件夹删除,再格式化NameNode。
初始化完文件系统后,继续输入,启动HDFS:
sbin/start-dfs.sh 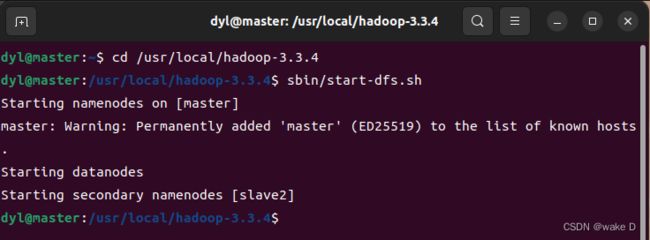
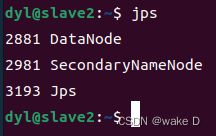
然后在三台虚拟机中分别输入jps命令查看是否启动成功:
master:
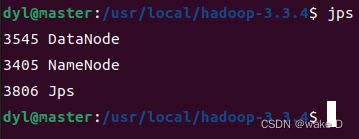
slave1:

slave2:
(2)进入slave1中启动YARN:
因为我们配置的ResourceManager结点是slave1所以我们在slave1中执行下面的命令:
cd /usr/local/hadoop-3.3.4 #转到hadoop-3.3.4的安装目录下
sbin/start-yarn.sh #启动yarn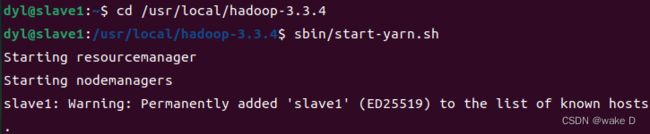
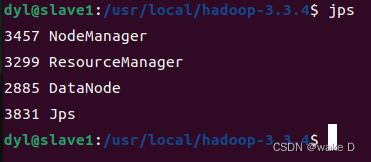
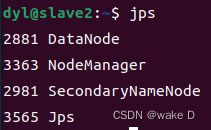
再在三台机器中执行jps查看是否启动成功:
master:

slave1:
slave2:
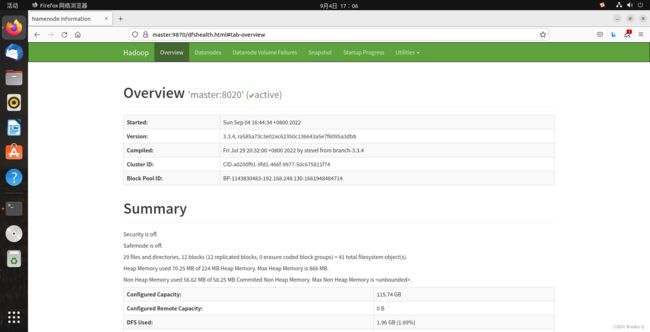
(3)在Web端验证HDFS和YARN是否启动成功
打开火狐浏览器输入 :http://master:9870
如果出现以下hadoop页面则说明HDFS配置成功:
再输入网址(ResourceManager):http://slave1:8088
出现以下页面则说明启动成功:
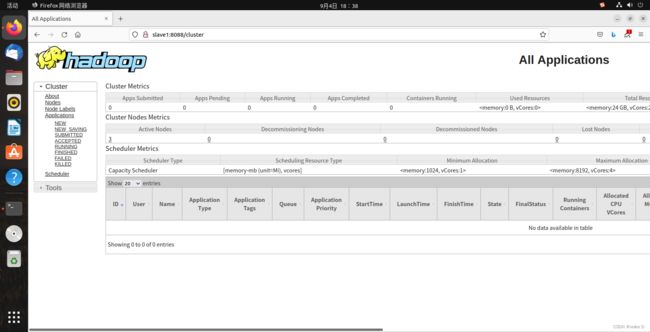
(4)文件上传文件测试,以及Wordcount功能测试
按照以下命令创建并进入word.txt文件:
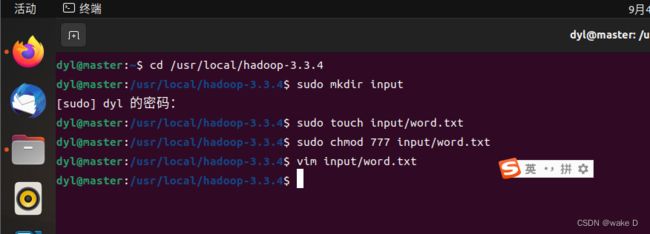
然后在文件中添加以下内容以供测试:
hello hadoop hive hbase spark flink
hello hadoop hive hbase spark
hello hadoop hive hbase
hello hadoop hive
hello hadoop
hello添加完成后退出文本编辑,然后再输入以下命令:
hadoop fs -put /usr/local/hadoop-3.3.4/input/word.txt /input
#将word.txt文件传送到HDFS下的/input目录下
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
#执行wordcount程序来对文件中的单词计数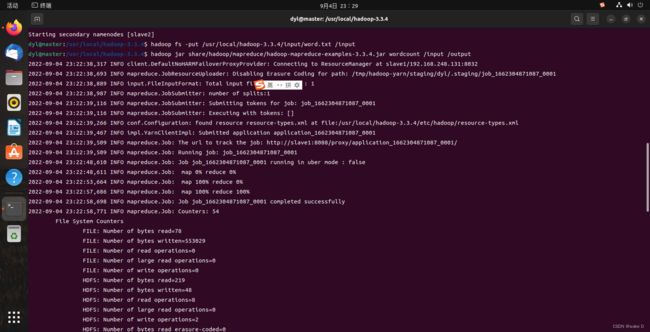
然后可以输入一下语句来查看统计的结果:
hdfs dfs -ls /output #转到我们运行程序是设置的输出目录下面并查看其中的文件
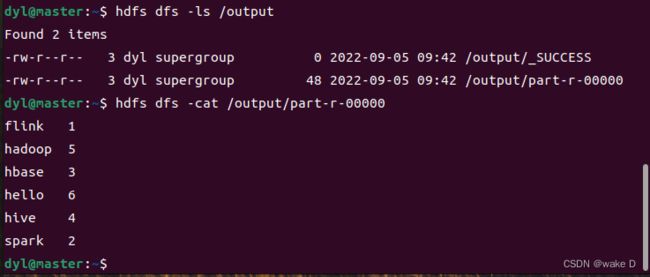
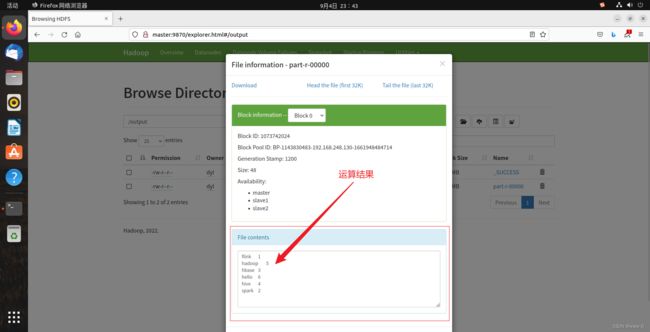
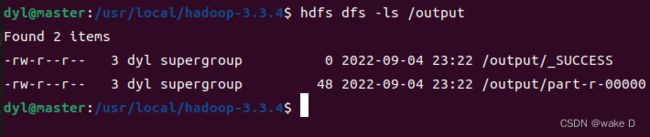 这里的part-r-00000文件就是Wordcount程序运行的结果所在:
这里的part-r-00000文件就是Wordcount程序运行的结果所在:
hdfs dfs -cat /output/part-r-00000 #查看这个结果储存文件最后的统计结果就如下图所示:
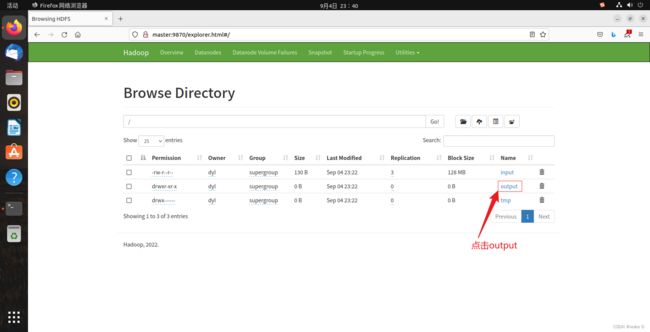
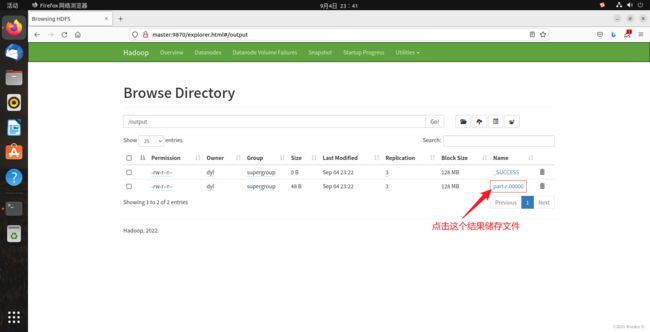
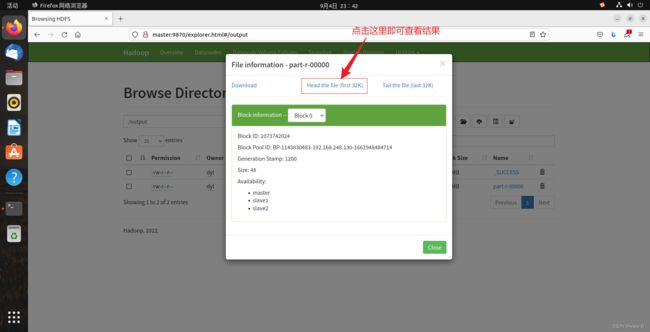
除了命令行这种查看方式也可以在web端查看:
打开浏览器输入:http://master:9870
进入到如下页面:

(5)启动历史服务器
首先转到Hadoop_s1(slave1)这台虚拟机下启动历史服务器服务:
mapred --daemon start historyserver #启动历史服务器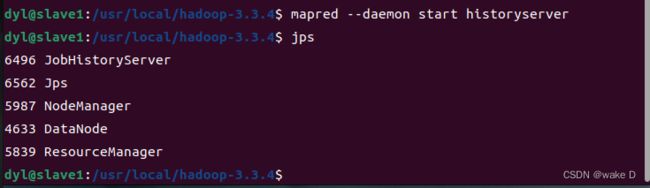
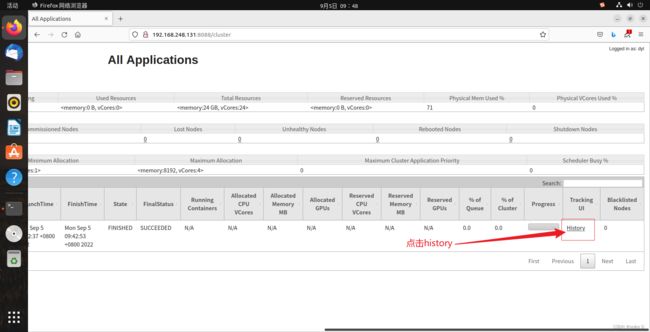
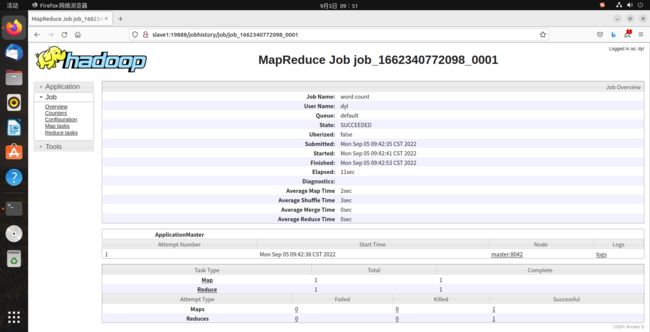
然后回到火狐浏览器输入以下网址:http://slave1:8088/cluster
然后再点击history可查看此任务执行的历史信息:
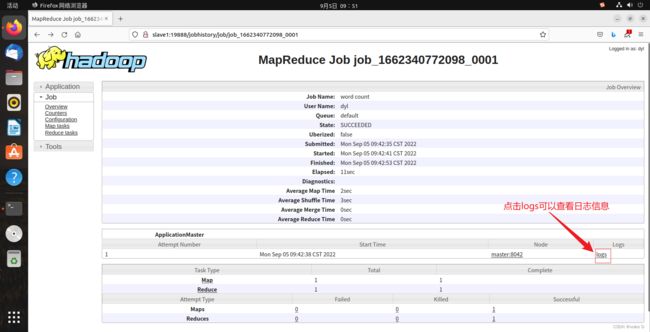
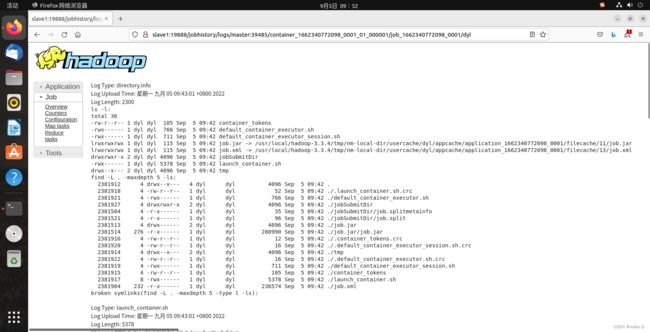
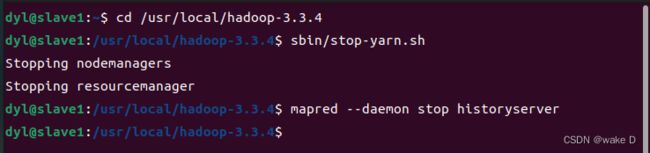
(6)关闭hadoop集群操作
首先进入Hadoop_m(master)结点,进入命令行输入以下命令关闭HDFS:
stop-dfs.sh
然后进入Hadoop_s1(slave1)结点下去输入以下命令关闭YARN和历史服务器:
cd /usr/local/hadoop-3.3.4
sbin/stop-yarn.sh
mapred --daemon stop historyserver