Hive sql : 查询连续登录天数
查询连续登录天数
- 1.问题描述
- 2.在Hive中建表
- 3.查询最大连续登录天数
1.问题描述
目前有两列数据,分别是用户ID和用户登录的时间,现需要统计用户连续登录的最大天数,中间如有断开,则不算连续,如下图示例。

2.在Hive中建表
在Hive中进行操作,首先启动Hadoop集群环境,进入到Hadoop安装目录,
sbin/start-dfs.sh ,jps查看Hadoop集群有无正常启动

正常启动后,输入hive启动hive。使用之前建立的test数据库,没有可以自行创建一个数据库,在test数据库下新建一个表user_login,这里的日期使用date数据类型
create table user_login(
id int,
login_time date)
row format delimited
fields terminated by ',' --分隔符是逗号
lines terminated by '\n'; --行与行之间使用换行符
建立好表结构后,向该表中到入数据,在root权限下新建一个user_login.txt,使用命令vi user_login.txt,将数据粘贴到user_login.txt中,如下图:

注意数据前后不能有空格,不然导入的数据会变成NULL。使用命令:
load data local inpath '/usr/local/hive/tmp/user_login.txt' overwrite into table user_login;
导入数据到user_login表中,查询一下有无正确导入select * from user_login;,我第一次导的时候因为数据后面有空格,导致导入错误了,后经过修正,没有问题了,如下图:

3.查询最大连续登录天数
下面主要参考了另一位博主的思想。
第一步:使用ROW_NUMBER() 窗口函数 按id分组,按login_time降序排序,得到如下结果
select login_time,id,row_number() over(partition by id) as rank
from user_login
group by login_time,id;

第二步:判断是否连续:用login_time-rank 如果连续则做差后值一样,然后再用id,login_time分组算出每个id下连续的天数,得到如下结果:
SELECT
id,
date_sub(login_time,sort) as login_group,
min(login_time) as start_login_time,
max(login_time) as end_login_time,
count(1) as continuous_days
FROM (
SELECT
id,
login_time,
row_number() OVER(PARTITION BY id order by login_time) as sort
FROM user_login
) a
GROUP BY id,date_sub(login_time,sort);
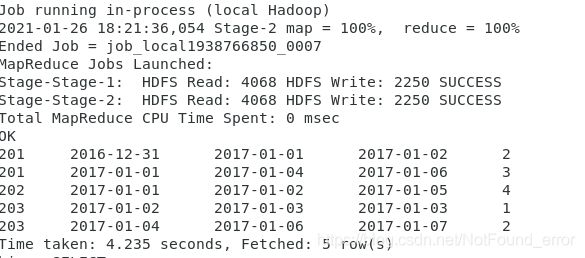
第三步:再以id分组,取最大的连续登录天数,得到如下结果:
SELECT
id,
max(continuous_days) as maxday
FROM
(
SELECT
id,
date_sub(login_time,sort) as login_group,
min(login_time) as start_login_time,
max(login_time) as end_login_time,
count(1) as continuous_days
FROM (
-- 第一段首先根据用户分组,登陆时间排序,结果按照登陆时间升序排列
SELECT
id,
login_time,
row_number() OVER(PARTITION BY id order by login_time) as sort
FROM user_login
) a
GROUP BY id,date_sub(login_time,sort)
)b
GROUP BY id;

可以看到已经得到了想要的结果了,在此仅记录一下在Hive中的学习过程,原博客地址见参考。
参考:
https://blog.csdn.net/ganghaodream/article/details/100083543