VGGNet模型解读
原博文:深度学习论文随记(二)---VGGNet模型解读
Very Deep Convolutional Networks forLarge-Scale Image Recognition
Author: K Simonyan , A Zisserman
Year: 2014
1、 导引
VGGNet是2014年ILSVRC竞赛的第二名,没错你没听错它是第二名,第一名是GoogLeNet(真不是我打错google,是谷歌为了纪念LeNet,所以用的大写L).为什么先讲VGG,因为它这个模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
为什么叫VGG?
是牛津大学 Visual Geometry Group(视觉几何组)的同志写的论文,所以叫VGG.
2、 模型解读

这张图的意思是他们一共建了A, B, C, D, E, F 6个不同的网络进行效果的比对。
注:在你看这里的时候我已经假设你看懂了AlexNet,已经对神经网络的结构有了个大致的印象。结构A:和AlexNet类似,卷积层分为了5个stage,全连接层还是3层。只不过卷积层用的都是3x3大小的filter,具体的细节我会在下文接着阐述。
结构A-LRN:保留AlexNet里面LRN操作,其他与结构A无区别。
结构B:在A的stage2和stage3分别增加一个3x3的卷积层,共有10个卷积层。
结构C:在B的基础上,stage3,stage4,stage5分别增加一个1x1的卷积层,有13个卷积层,总计16层。
结构D:在B的基础上,stage3,stage4,stage5分别增加一个3x3的卷积层,有13个卷积层,总计16层。
结构E:在D的基础上,stage3,stage4,stage5分别再增加一个3x3的卷积层,有16个卷积层,总计19层。
对比:
·A与A-LRN比较:A-LRN结果没有A好,说明LRN作用不大。
·A与B, C, D, E比较,A是这当中layer最少的,相比之下A效果不如B,C,D,E,说明Layer越深越好;
·B与C比较:增加1x1filter,增加了额外的非线性提升效果;
·C与D比较:3x3 的filter(结构D)比1x1(结构C)的效果好
3、 特点分析:(我们以最终的结构E来进行分析)
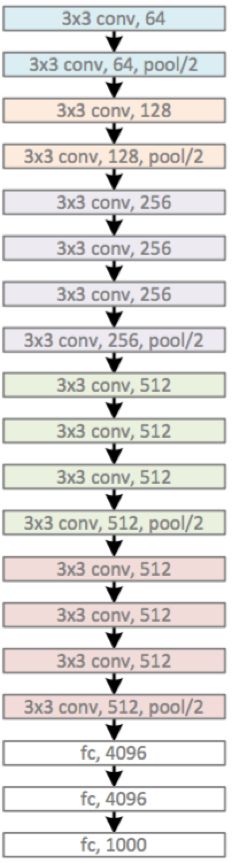
①可以看到共有5个池化层,所以可以把卷积部分视为5个部分,和AlexNet一样,只不过每一个部分他用了不止一层卷积层。
②所有卷积层都是同样大小的filter!尺寸3x3,卷积步长Stirde = 1,填充Padding = 1!
为什么这么搞?
A、3x3是最小的能够捕获左、右、上、下和中心概念的尺寸;
B、两个3x3的卷积层连在一起可视为5x5的filter,三个连在一起可视为一个7x7的
这是卷积的性质,受过#信号系统#这门课摧残的同学应该记忆犹新…
C、多个3x3的卷积层比一个大尺寸的filter卷积层有更多的非线性,使得判决函数更加具有判断性。
D、多个3x3的卷积层笔一个大尺寸的filter具有更少的参数。
③卷积层变多了。结构E有16层卷积层,加上全连接层共19层。这也是对深度学习继续往深处走的一个推动。
实际上卷积层越多的话,图像的细节信息的就能得到更好的提取,可以想象成拿放大镜把细节放大再放大?我不知道我这个比喻是否恰当,但是便于理解。
4、 Multi-scale训练
首先对原始图片进行等比例缩放,使得短边要大于224,然后在图片上随机提取224x224窗口,进行训练。由于物体尺度变化多样,所以多尺度(Multi-scale)可以更好地识别物体。
方法1:在不同的尺度下,训练多个分类器:
参数S为短边长。训练S=256和S=384两个分类器,其中S=384的分类器用S=256的进行初始化,且将步长调为10e-3
方法2:直接训练一个分类器,每次数据输入的时候,每张图片被重新缩放,缩放的短边S随机从[256,512]中选择一个。
Multi-scale其实本身不是一个新概念,学过图像处理的同学都知道,图像处理中已经有这个概念了,我们学过图像金字塔,那就是一种多分辨率操作
只不过VGG网络第一次在神经网络的训练过程中提出也要来搞多尺寸。目的是为了提取更多的特征信息。像后来做分割的网络如DeepLab也采用了图像金字塔的操作。