Spark-mllib源码分析之逻辑回归(Logistic Regression)
-
- 一个例子
- 类关系图
- 创建用LBFGS求解LR的类
- 运行模型
- 模型优化
- 1 损失与梯度的计算
- 2 LR目标函数梯度计算
- 3 LR正则项计算及梯度更新
- 模型预测
- 总结
1. 一个例子
// 0. LogisticRegressionWithLBFGSExample#main()
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("lr").setMaster("local")
val sc = new SparkContext(conf)
// 加载数据集
val data = MLUtils.loadLibSVMFile(sc, "/home/mdu/dataset/sample_libsvm_data.txt")
// 按 6:4 划分训练集和测试集
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// 使用LBFGS求解LR
val model = new LogisticRegressionWithLBFGS() // 1.-2. 创建用LBFGS求解LR的类
.setNumClasses(10)
.run(training) // 3. 运行模型
// 预测测试集
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// 预测结果
val metrics = new MulticlassMetrics(predictionAndLabels)
val precision = metrics.precision
println("Precision = " + precision)
}Spark能够对Logistic Regression进行并行化,因此通过对Spark1.6.1源码的分析,本文期望能解决下述问题:
- Spark在哪里对LR算法进行了并行化?
- 如何并行化?
我们可以先猜测一下可能的并行化的部分是在哪里?我们知道,如果使用一阶方法,通常使用SGD方法进行求解,涉及到梯度的计算,如果使用二阶方法,通常使用Newton方法进行求解,涉及到梯度和Hessian矩阵的计算,二阶的计算量较大,如果使用近似二阶的方法,通常是LBFGS,也涉及到梯度的计算,因此,LR算法的计算量都在梯度的计算上。而梯度计算通常是可以分开同时计算的,因此我们大胆猜测一下Spark可能是在这里对LR进行并行计算的。
2. 类关系图
在开始分析源码之前,先看一下LR相关的类关系图(右键大图),了解类之间的关系有助于我们理解算法(画的不是很标准,就凑合这么看吧(…逃)。
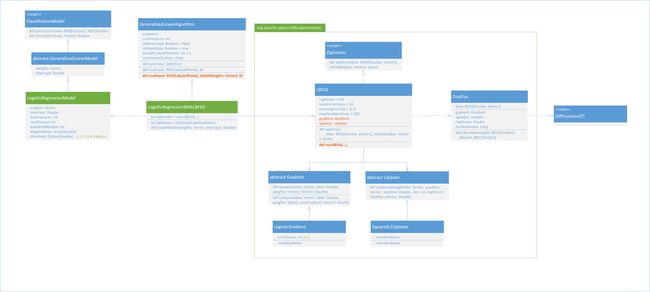
我们的入口是第二列绿色标出的LogisticRegressionWithLBFGS,可以看出它有一个很庞大的成员LBFGS类,其中LBFGS的求解依赖于它的两个成员Gradient和Updater,一个用于梯度的计算,一个用于梯度的更新。这两个类都是抽象类,Gradient的子类可以是LogisticGradient、LeastSquaresGradient、HingeGradient对应逻辑回归、线性回归、SVM的梯度。Updater的子类可以是SimpleUpdater、L1Updater、SquaredL2Updater对应不带正则项的梯度更新、带L1正则项的梯度更新、带L2正则项的梯度更新。图中右侧定义了CostFun,LBFGS算法迭代全依赖这个函数,别看它的名字叫CostFun,实际上他的作用是同时计算出损失和梯度,怎么计算呢?使用定义的Gradient子类,计算出梯度怎么更新呢?使用定义的Updater子类。源码中比较重要的方法就是橙色标出的两个,我们后面分析都会围绕这几个方法。
类关系图大致就是这样,下面我们来深入源码来分析一下。
3. 创建用LBFGS求解LR的类
LR属于广义线性模型(Generalized Linear Models)的特例,因此继承自GeneralizedLinearAlgorithm类。
// 1. GeneralizedLinearAlgorithm
abstract class GeneralizedLinearAlgorithm[M <: GeneralizedLinearModel]
extends Logging with Serializable {
// 主要验证label的有效性,主要有:(1)二分类:label在{0, 1}, (2)多分类:label在{0, 1, ..., k-1}
protected val validators: Seq[RDD[LabeledPoint] => Boolean] = List()
// 主要用来优化算法的类,这里是LBFGS
def optimizer: Optimizer
// 是否添加线性模型的截距项
protected var addIntercept: Boolean = false
// 是否验证数据有效性,默认是要的
protected var validateData: Boolean = true
// 这里就是我们模型参数类数,2分类的话只需要一个权重向量即可(默认),多分类即类别数-1个权重向量。
protected var numOfLinearPredictor: Int = 1
// 是否特征缩放,默认是否,可以设置为true,特征缩放可以加快模型的收敛速度。
private var useFeatureScaling = false
// 特征数
protected var numFeatures: Int = -1这里LBFGS类就是第2节的那个绿框框起来的最重要的类,它需要两个参数Gradient和Updater,可以看到传入的是LogisticGradient和SquaredL2Updater,即使用LR的梯度和L2正则。
// 2. new LogisticRegressionWithLBFGS
class LogisticRegressionWithLBFGS
extends GeneralizedLinearAlgorithm[LogisticRegressionModel] with Serializable {
// 在LR中默认是要特征缩放的,可以减小训练集的条件数,加快收敛
this.setFeatureScaling(true)
// 使用LBFGS算法求解
override val optimizer = new LBFGS(new LogisticGradient, new SquaredL2Updater)
}4. 运行模型
调用创建的LogisticRegressionWithLBFGS类的run方法运行模型,run继承自其父类,从第2节可以看到父类的run方法有两个,第一个方法会根据数据集创建对应的初始化权重调用第二个run方法。
二分类时(K=2),numOfLinearPredictor=1,模型的参数向量长度为numFeatures,如果添加了截距项则长度多一项。多分类时(K>2),这时LR应该称为(Multinomial logistic regression),numOfLinearPredictor=K-1,-1是因为模型输出概率求和为1,所以K类分类K个参数向量实际有1列是冗余的,这列可以由其他参数表示。
注:多分类时参数通常表示为矩阵的形式,不过这里用一个长向量来代替了矩阵。
// 3.GeneralizedLinearAlgorithm#run(input)
def run(input: RDD[LabeledPoint]): M = {
// ...
val initialWeights = {
if (numOfLinearPredictor == 1) {
Vectors.zeros(numFeatures)
} else if (addIntercept) {
Vectors.zeros((numFeatures + 1) * numOfLinearPredictor)
} else {
Vectors.zeros(numFeatures * numOfLinearPredictor)
}
}
run(input, initialWeights) // 4. 运行模型
}下面的根据useFeatureScaling做特征缩放,LR默认是要做的,毕竟能够加快收敛速度。一般将特征缩放到一个区间一般可以有两种方式:1)最大最小归一化;2)z-score标准化
不同的是Spark使用的是后者,而且只对特征除以了标准差,没有减去均值。关于这样做的原因我认为是它不想再对测试集做任何预处理了。只做特征缩放,让模型在缩放的特征空间中进行训练,最后再将训练的参数乘以权重以使权重恢复到原始空间。
其中, g(z) 为sigmoid函数:
可见 w1 是原始空间的权重向量, w2 是缩放空间的权重向量,且有 w1=w2/σ ,二者只差了一个标准差 σ ,从缩放空间恢复到原始空间只需要 w2 除以 σ 。如果减去均值,或者使用最大最小缩放,可能在从 w2 恢复到 w1 时就不是那么好处理了,个人见解。
// 4.GeneralizedLinearAlgorithm#run(input, initialWeights)
def run(input: RDD[LabeledPoint], initialWeights: Vector): M = {
// ...
// 根据是否特征缩放创建StandardScaler,不减去均值
val scaler = if (useFeatureScaling) {
new StandardScaler(withStd = true, withMean = false).fit(input.map(_.features))
} else {
null
}
// 特征缩放
val data =
if (addIntercept) {
if (useFeatureScaling) {
input.map(lp => (lp.label, appendBias(scaler.transform(lp.features)))).cache()
} else {
input.map(lp => (lp.label, appendBias(lp.features))).cache()
}
} else {
if (useFeatureScaling) {
input.map(lp => (lp.label, scaler.transform(lp.features))).cache()
} else {
input.map(lp => (lp.label, lp.features))
}
}
// 添加截距项
val initialWeightsWithIntercept = if (addIntercept && numOfLinearPredictor == 1) {
appendBias(initialWeights)
} else {
initialWeights
}
// 模型优化,这里是最精彩的部分。
val weightsWithIntercept = optimizer.optimize(data, initialWeightsWithIntercept) // 5.
// 获取截距项
val intercept = if (addIntercept && numOfLinearPredictor == 1) {
weightsWithIntercept(weightsWithIntercept.size - 1)
} else {
0.0
}
// 获取模型参数——权重向量
var weights = if (addIntercept && numOfLinearPredictor == 1) {
Vectors.dense(weightsWithIntercept.toArray.slice(0, weightsWithIntercept.size - 1))
} else {
weightsWithIntercept
}
// 将权重从缩放的特征空间恢复到原始特征空间
if (useFeatureScaling) {
if (numOfLinearPredictor == 1) {
weights = scaler.transform(weights)
} else {
var i = 0
val n = weights.size / numOfLinearPredictor
val weightsArray = weights.toArray
while (i < numOfLinearPredictor) {
// 依次拷贝每一个类别下的权重,因为模型参数是以长向量形式存储的,所以循环拷贝
val start = i * n
val end = (i + 1) * n - { if (addIntercept) 1 else 0 }
val partialWeightsArray = scaler.transform(
Vectors.dense(weightsArray.slice(start, end))).toArray
System.arraycopy(partialWeightsArray, 0, weightsArray, start, partialWeightsArray.size)
i += 1
}
weights = Vectors.dense(weightsArray)
}
}
// ...
createModel(weights, intercept) // 10. 创建模型
}5. 模型优化
优化的类是LBFGS,看一下它的定义:
class LBFGS(private var gradient: Gradient, private var updater: Updater)
extends Optimizer with Logging {
private var numCorrections = 10 // 存储的校正矩阵的历史长度
private var convergenceTol = 1E-4 // 收敛终止条件
private var maxNumIterations = 100 // 最大迭代次数
private var regParam = 0.0 // 正则项参数
}optimize调用了runLBFGS,重点关注runLBFGS方法。
// 5.LBFGS#optimize(data, initialWeights)
override def optimize(data: RDD[(Double, Vector)], initialWeights: Vector): Vector = {
val (weights, _) = LBFGS.runLBFGS( // 6.
data,
gradient,
updater,
numCorrections,
convergenceTol,
maxNumIterations,
regParam,
initialWeights)
weights
} // return 4.这个方法核心是CostFun,CostFun实现了breeze线性代数库的DiffFunction接口,实现这个接口的函数需要提供一个calculate(weights: BDV[Double])方法,这个方法返回损失函数值和梯度。这一块儿我们先不看。我们定义好CostFun之后调用LBFGS的iterations方法不断更新权重,最后通过state就可以拿到我们最后优化好的权重,最后返回。
// 6.LBFGS#runLBFGS(...)
def runLBFGS(
data: RDD[(Double, Vector)], // 训练集
gradient: Gradient, // 这里是LogisticGradient
updater: Updater, // 这里是SquaredL2Updater
numCorrections: Int, // LBFGS使用校正矩阵的历史长度
convergenceTol: Double, // 收敛终止条件
maxNumIterations: Int, // 最大迭代次数
regParam: Double, // 正则项参数
initialWeights: Vector): (Vector, Array[Double]) = {
val lossHistory = mutable.ArrayBuilder.make[Double]
val numExamples = data.count()
val costFun = new CostFun(data, gradient, updater, regParam, numExamples)
val lbfgs = new BreezeLBFGS[BDV[Double]](maxNumIterations, numCorrections, convergenceTol)
// LGBGS通过调用iterations方法优化参数
val states = // 7. 内部调用costFun的calculate方法计算loss和grad
lbfgs.iterations(new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector)
var state = states.next()
while (states.hasNext) {
lossHistory += state.value
state = states.next()
}
lossHistory += state.value
// 优化好的权重向量
val weights = Vectors.fromBreeze(state.x)
val lossHistoryArray = lossHistory.result()
logInfo("LBFGS.runLBFGS finished. Last 10 losses %s".format(
lossHistoryArray.takeRight(10).mkString(", ")))
// 返回权重和损失的历史信息。
(weights, lossHistoryArray)
} // return 5.5.1 损失与梯度的计算
该来的还是会来的,我们分析下CostFun的部分,这里是最最精彩的部分(…之一),这里懂了LR的源码就拿下了(…一半)。先看下CostFun的定义,看起来好像没什么特别的。
private class CostFun(
data: RDD[(Double, Vector)], // 训练数据
gradient: Gradient, // 这里是LogisticGradient
updater: Updater, // 这里是SquaredL2Updater
regParam: Double, // 正则项参数
numExamples: Long) extends DiffFunction[BDV[Double]] 我们重点关注它复写的calculate(weights)方法,为什么?因为这里就是Spark数据并行的地方,怎么并行呢?我们来分析一下。代码中不是以batch的方式进行梯度计算的,而是计算全量的梯度。复习一下梯度更新公式:
可以看到梯度求和公式实际可以分开计算的,分开计算的地方就是并行的地方。Spark大多数代码都用到了treeAggregate方法对数据进行聚合,关于这个方法的详细说明见博主另一篇 treeAggregate。聚合的时候我们最前面提到的Gradient子类也就是LogisticGradient将会发挥它计算LR梯度的作用。
聚合操作的初始值为(Vectors.zeros(n), 0.0),分别为初始梯度和初始损失。聚合的第一阶段是seqOp操作,以第一次为例,左侧的c表示(grad, loss)元组;右侧的v来自数据集,表示(label, features)元组,(label, features)被传入给localGradient,进而调用其compute方法得到使用该样本得到的梯度和损失,之后和元组c对应累加。因为grad的累加是(in-place)的,因此经过seqOp操作之后,返回(grad, loss + l)。聚合操作的第二阶段是combOp操作,只是简单的对前面计算的loss和grad的聚合。这样全量样本下的梯度和损失就已经计算好了。不过这些损失和梯度都不含正则项部分,后面是正则项的梯度和损失的求解。
// 7. CostFun#calculate(weights)
override def calculate(weights: BDV[Double]): (Double, BDV[Double]) = {
// Have a local copy to avoid the serialization of CostFun object which is not serializable.
val w = Vectors.fromBreeze(weights) // 权重向量
val n = w.size // 权重向量长度
val bcW = data.context.broadcast(w)
val localGradient = gradient // 这里是LogisticGradient
val (gradientSum, lossSum) = data.treeAggregate((Vectors.zeros(n), 0.0))(
seqOp = (c, v) => (c, v) match { case ((grad, loss), (label, features)) =>
val l = localGradient.compute( // 8. LR的梯度计算
features, label, bcW.value, grad)
(grad, loss + l)
},
combOp = (c1, c2) => (c1, c2) match { case ((grad1, loss1), (grad2, loss2)) =>
axpy(1.0, grad2, grad1)
(grad1, loss1 + loss2)
})
// compute方法返回(更新以后的权重,正则项的损失),这这里只取后者
// 这里传入的梯度是零向量,stepSize=0,iter=1,只计算正则项的损失
val regVal = updater.compute(w, Vectors.zeros(n), 0, 1, regParam)._2 // 9. 正则项梯度更新
// 总损失
val loss = lossSum / numExamples + regVal
// 更新正则项梯度
val gradientTotal = w.copy
// 这里传入的梯度是零向量,stepSize=1,iter=1,只计算正则项的梯度
axpy(-1.0, updater.compute(w, Vectors.zeros(n), 1, 1, regParam)._1, gradientTotal)
// 更新总梯度
axpy(1.0 / numExamples, gradientSum, gradientTotal)
(loss, gradientTotal.toBreeze.asInstanceOf[BDV[Double]])
} // return 6.5.2 LR目标函数梯度计算
上面是从总体上了解LR损失的计算与梯度的更新,细节的东西在gradient.compute和updater.compute中。 先看gradient的计算,在子类LogisticGradient中。
1. 二分类
二分类的部分比较简单,对照二分类的NLL(Negative Log Likelihood)损失函数公式,不过逻辑回归的损失函数通常有两种形式(这里只是对单个样本而言),具体见MLAPP的8.3.1节,不要搞混了:
分别对应 y∈{0, 1} 和 y∈{-1, 1} 。其中,使用式(3)对 w 求梯度:
计算完当前样本的梯度后,使用axpy方法对梯度进行累加。后面的log1pExp部分是计算二分类的损失部分,不过损失是用(4)式计算的(…懵),不过(3)与(4)都是等价的,没关系。计算损失时为了保证数值的稳定性,这里有一个小trick。因为计算margin时可能因为噪声样本的存在使得margin的值非常大,当margin>709.78,exp就溢出了。以计算 log(1+ex) 为例,当 x>0 时,做简单的变换 log(e−x⋅ex+ex)=x+log(e−x) ,这时指数部分 −x<0 就不会溢出了。
// 8.LogisticGradient#compute(...)
// ...
numClasses match {
case 2 =>
val margin = -1.0 * dot(data, weights) // w^T*x
val multiplier = (1.0 / (1.0 + math.exp(margin))) - label // 对应式(5)
axpy(multiplier, data, cumGradient) // 梯度累加
if (label > 0) {
// The following is equivalent to log(1 + exp(margin)) but more numerically stable.
MLUtils.log1pExp(margin)
} else {
MLUtils.log1pExp(margin) - margin
}
} // return 7.2. 多分类
多分类看到想哭,不过没关系,一点点分析。多分类(Multinomial logistic regression),也叫Softmax,作为逻辑回归的一般化形式。使用它的一个好处就是它能处理多类别分类问题。另一个就是它的输出也是一个概率分布。因此深度学习中的多分类问题也经常使用Softmax作为最后一层输出各类别下的预测概率。
一般对K类问题时Softmax可以有K个权重向量作为参数,但实际上一个参数是冗余的,前面也提到了,因为模型输出概率求和为1,所以冗余的这列实际上可以由其他参数表示。在实际应用中,为了使算法实现更简单清楚,往往保留所有的K个参数向量。不过冗余的参数可能会导致模型过拟合,需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决Softmax 回归的参数冗余所带来的数值问题,详见Softmax。Spark在实现Softmax稍微有些不同,它去掉了冗余的这一列权重向量,对一般的K分类问题,其权重参数大小为 numFeature×(K−1) ,选择 K=0 作为Pivot,有:
上式可以写为:
且有:
有了(7)和(8)式我们可以写出Softmax的NLL损失函数,式(9),在代码中会用到:
其中:
到这里就快要接近胜利了,因为损失函数我们已经有了,只要再写下梯度就OK了。不过这里还是刚刚的trick,就是exp的数值溢出的问题,因此我们需要让margins中的最大值maxMargin,对exp做等价变换,详见 Softmax。
上式(10)中有:
不过具体到代码实现的时候我感觉这个sum好像少了最后那个-1哎。
好累…,终于搞定了损失函数了,只差一个梯度,go on…,根据(9)式其实可以很方便的写出梯度公式:
其中:当 y=i+1 时, δy,i+1 取值为1,否则为0。
好了,现在我们手上拿着公式(10)和公式(12)去怼源码, (╯`□′)╯(┻━┻。
// 8.LogisticGradient#compute(...)
numClasses match {
// ...
case _ =>
// ...
// marginY=margins(label - 1),记录了公式10的最后一项
var marginY = 0.0
var maxMargin = Double.NegativeInfinity
var maxMarginIndex = 0
// 记录maxMargin及其下标,减去maxMargin防止exp数值溢出
val margins = Array.tabulate(numClasses - 1) { i =>
var margin = 0.0
data.foreachActive { (index, value) =>
if (value != 0.0) margin += value * weightsArray((i * dataSize) + index)
}
if (i == label.toInt - 1) marginY = margin
if (margin > maxMargin) {
maxMargin = margin
maxMarginIndex = i
}
margin
}
// 计算公式11
val sum = {
var temp = 0.0
if (maxMargin > 0) {
for (i <- 0 until numClasses - 1) {
margins(i) -= maxMargin
if (i == maxMarginIndex) {
temp += math.exp(-maxMargin)
} else {
temp += math.exp(margins(i))
}
}
} else {
for (i <- 0 until numClasses - 1) {
temp += math.exp(margins(i))
}
}
temp
}
// 梯度累加,计算公式12
for (i <- 0 until numClasses - 1) {
val multiplier = math.exp(margins(i)) / (sum + 1.0) - {
if (label != 0.0 && label == i + 1) 1.0 else 0.0
}
data.foreachActive { (index, value) =>
if (value != 0.0) cumGradientArray(i * dataSize + index) += multiplier * value
}
}
// 计算公式10及其最后一项
val loss = if (label > 0.0) math.log1p(sum) - marginY else math.log1p(sum)
// 计算公式10的maxMargin项
if (maxMargin > 0) {
loss + maxMargin
} else {
loss
}
} // return 7.5.3 LR正则项计算及梯度更新
这一部分主要是计算正则项损失,以及梯度的更新。当stepSize=0,iter=1时,可以通过返回值第二项取得正则项的损失,当stepSize=1,iter=1时,可以通过返回值第一项取得正则项的梯度。否则则进行梯度的更新操作,这里第二项为L2正则项的梯度:
注:这里有一点就是步长是随迭代次数衰减的。
// 9. SquaredL2Updater#compute(...)
class SquaredL2Updater extends Updater {
override def compute(
weightsOld: Vector,
gradient: Vector,
stepSize: Double,
iter: Int,
regParam: Double): (Vector, Double) = {
val thisIterStepSize = stepSize / math.sqrt(iter)
val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVector
brzWeights :*= (1.0 - thisIterStepSize * regParam)
brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights)
val norm = brzNorm(brzWeights, 2.0)
(Vectors.fromBreeze(brzWeights), 0.5 * regParam * norm * norm)
}
} // return 7.6. 模型预测
其实模型预测没有什么好讲的了,优化完权重参数后会根据二分类还是多分类创建对应的模型,二分类如果预测概率大于threshold则判定为正类,反之负类。多分类的话会遍历所有的权重,去预测概率最大的类,如果计算的maxMargin为负,则返回第1类。还有就是预测时默认是返回样本所属类别的,可以通过调用model.clearThreshold()方法,返回预测概率,不过多分类想要得到各类概率在这个版本貌似是没有的,不过实现起来也不难。
7. 总结
通过对Spark LR源码的分析,终于了解了它内部是如何实现了,终于不用做LR的调包侠了。到这里我们也能解答文章开始的两个问题了:
Spark在哪里对LR算法进行了并行化?
在计算全量样本的梯度时,是可以分开计算的,之后会对分开计算的梯度做聚合。因此在计算梯度的地方就是并行的地方。当然不只是梯度,损失也是同理。
如何并行化?
Spark使用了RDD的treeAggregate方法对梯度和损失计算进行了并行计算,首先通过seqOp计算出每个RDD分区内的样本的梯度,之后combOp对所有的分区的结果做聚合,从而得到总体的梯度。
如果文章中有什么错误的地方西方大家指出,共同进步,逃~
参考:
1. CS229 Lecture Note
2. MLAPP-Logistic Regression
3. 牛顿法与拟牛顿法学习笔记(五)L-BFGS 算法
4. Softmax回归 - ufldl
5. Multinomial logistic regression - wiki
6. CS231n Softmax classifier
7. Multinomial Logistic Regression with Apache Spark