数据结构讲解 ---- 概述
引言
数据结构(data structure)是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。简而言之,数据结构是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。“结构”就是指数据元素之间存在的关系,分为逻辑结构和存储结构。

导航
- 数据结构
- 逻辑结构:数据之间的相互关系。 (和实现无关)
- 分类1:从逻辑上可以将其分为线性结构和非线性结构
- 分类2:逻辑结构有四种基本类型:集合结构,线性结构,树状结构,网络结构
- 物理结构/存储结构:数据在计算机中的表示
- 顺序存储方法
- 链式存储方法
- 索引存储方法
- 散列存储方法
- 逻辑结构:数据之间的相互关系。 (和实现无关)
- 算法
- 什么是算法?
- 时间复杂度
- 空间复杂度
- 总结
数据结构:
有哪些数据结构:
常用数据结构 : 数组(静态数组、动态数组)、线性表、链表(单向链表、双向链表、循环链表)、队列、栈、树(二叉树、查找树、平衡树、线索树、线索树、堆)、 图等的定义、存储和操作 、Hash(存储地址计算,冲突处理)。
数据: 所有能被输入到计算机中,且能被计算机处理的符号的集合。是计算机操作的对象的总称。
数据项: 数据的不可分割的最小单位。一个数据元素可由若干个数据项组成。
数据元素: 数据(集合)中的一个“个体”,数据及结构中讨论的基本单位。
数据对象: 性质相同的数据元素的集合(类似于数组一般)。
数据类型: 在一种程序设计语言中,变量所具有的数据种类。整型、浮点型、字符型等等。
注意:数据元素之间不是独立的,存在特定的关系,这些关系及结构,数据结构指数据对象中数据元素之间的关系。
关系图:

如图所示:

PS:红色:数据项,蓝色:数据元素,黄色:数据对象
数据结构分为逻辑结构和物理结构:
关系图:

PS:逻辑结构唯一,存储结构不唯一,
运算的实现依赖于存储结构。
一、逻辑结构: 数据之间的相互关系。 (和实现无关)
分类图:

1、1 分类1: 从逻辑上可以将其分为线性结构和非线性结构
- 线性结构:
有且只有一个开始结点和终端结点,并且所有结点都最多只有一个直接前驱和一个直接后继。线性表就是一个典型的线性结构。 - 非线性结构:相对于线性结构,他的特征是
一个结点元素可能对应多个直接前驱和多个直接后继。图结构,树结构就是典型的非线性结构。
1、2 分类2: 逻辑结构有四种基本类型:集合结构,线性结构,树状结构,网络结构。
-
集合结构: 集合结构中的数据元素除了同属于一个集合外,它们之间没有其他关系。
(1)
确定性:(集合中的元素必须是确定的)。(2)
唯一性:(集合中的元素互不相同。例如:集合A={1,a},则a不能等于1)。(3)
无序性:(集合中的元素没有先后之分),如集合{3,4,5}和{3,5,4}算作同一个集合。该结构的数据元素间的关系是”属于同一个集合“,别无其他关系。

- 线性结构: 线性结构中的数据元素之间是
一对一的关系。
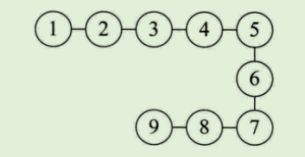
- 树状结构: 除了一个数据元素(元素A)以外每个数据元素
有且只有一个直接前驱元素,但是可以有多个直接后继元素。存在一种一对多的层次关系。

- 网络结构: 每个数据元素可以有
多个直接前驱元素,也可以有多个直接后继元素,存在多对多的关系。

二、 物理结构/存储结构: 数据在计算机中的表示。
物理结构是描述数据具体在内存中的存储(如:顺序存储结构、链式存储结构、索引存储结构、散列(哈希)存储结构)
2、1 顺序存储方法:
它是把逻辑上相邻的结点存储在物理位置相邻的存储单元里,结点间的逻辑关系由存储单元的邻接关系来体现,由此得到的存储表示称为顺序存储结构。顺序存储结构是一种最基本的存储表示方法,通常借助于程序设计语言(例如:C/C++)中的数组来实现。
(数据元素的存储对应于一块
连续的存储空间,数据元素之间的前驱和后继关系通过数据元素,在存储器中的相对位置来反映)

- 优点: 是
节省存储空间,因为分配给数据的存储单元全用存放节点的数据(不考虑c/c++语言中数组需指定大小的情况),结点之间的逻辑关系没有占用额外的存储空间。采用这种方式时,可实现对结点的随机存取,即每一个结点对应一个序号,由该序号直接就可以计算出结点的存储地址。` - 缺点: 插入删除需要移动元素,效率低,大小固定。
2、2 链式存储方法:
它不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系是由附加的指针字段表示的。每个存储结点对应一个需要存储的数据元素。由此得到的存储表示称为链式存储结构,链式存储结构通常借助于程序设计语言中的指针类型来实现。
(每个结点是由
数据域和指针域组成,元素之间的逻辑关系通过存储节点之间的链接关系反映出来)

-
优点:
1、比顺序存储结构中的存储密度小(每个节点都有
数据域和指针域组成,所以相同空间内假设全存满的话顺序比链式存储更多)。2、逻辑上相邻的节点物理上不比相邻。
3、大小动态扩展,插入删除灵活(
不必移动节点,只要改变节点中的指针即可)。 -
缺点: 查找节点时要比顺序存储效率慢,不能随机访问。
2、3 索引存储方法:
除建立存储结点信息外,还建立附加的索引表来标识结点的地址。
比如图书,字典的目录。

(为了方便查找,整体无序,但
索引块之间有序,需要额外空间,存储索引表。)
- 优点: 对顺序查找的一种改进,查找效率高。
- 缺点:
需额外空间存储索引。
2、4 散列存储方法:
就是根据结点的关键字直接计算出该结点的存储地址。

(选取某个函数,数据元素根据函数计算存储位置可能存在多个数据元素存储在同一位置,引起地址冲突)。
- 优点: 查找基于数据本身即可找到,查找效率高,存取效率高。
- 缺点: 存取随机,不便于顺序查找。
总结:
逻辑上(逻辑结构:数据元素之间的逻辑关系)可以把数据结构分成
线性结构和非线性结构。线性结构的顺序存储结构是一种顺序存取的存储结构,线性表的链式存储结构是一种随机存取的存储结构。线性表若采用链式存储表示时所有结点之间的存储单元地址可连续可不连续。逻辑结构与数据元素本身的形式、内容、相对位置、所含结点个数都无关。数据结构的基本操作的设置的最重要的准则是,实现应用程序与存储结构的独立。实现应用程序是“逻辑结构”,存储的是“物理结构”。逻辑结构主要是对该结构操作的设定,物理结构是描述数据具体在内存中的存储(如:顺序结构、链式结构、索引结构、散列结构)等。
算法:
一、什么是算法?
1)算法就是定义良好的计算过程;例如取出一组值作为输出,产生一个值作为输入。
2)算法就是一系列的计算步骤,用来将输入数据转换成输出结果。
3)是指令的集合,是为解决特定问题而规定的一系列操作。
简单的的说:算法就是计算机解题的过程。在这个过程中,无论是形成解题思路还是编写程序,都是在实施某种算法。前者是算法的逻辑形式,后者是算法的代码形式。
算法的特性:
1)有穷性:有限步骤内正常结束,不能无限循环。
2)确定性:每个步骤都必须有确定的含义,无歧义。
3)可行性:原则上能精确进行,操作能通过有限次完成。
4)输入:有0或多个输入。
5)输出:至少有一个输出。
算法优劣衡量:
(正确性,可读性,健壮性,时间效率高,空间使用率低,简单)
在我看来,要评价一个算法的好坏有四个要点:
-
算法正确性:这个算法要可以正确解答问题,不能在运行中频繁出现误差。
-
具有良好的可读性和可维护性,这样有利于后期维护。
-
时间复杂度:即一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
-
空间复杂度:一个程序的空间复杂度是指运行完一个程序所需内存的大小;
对一个算法的评价主要从时间复杂度和空间复杂度来考虑 ,算法在时间的高效性和空间的高效性之间通常是矛盾的 。所以一般只会取一个平衡点。通常我们假设程序运行在足够大的内存空间中,所以研究更多的是算法的时间复杂度。
举例:
然后求1+2+3+4+…+100=?
算法1:依次累加 使用 while do while for。
算法2:高斯解法:首尾相加*50 梯形面积算法((上底+下底)*高/2) 。
算法3:使用递归实现:sum(100)=sum(99)+100 sum(99)=sum(98)+99 … sum(1)=1。
二、时间复杂度:
语句频度或时间频度:
- 一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。
-
一个算法中的语句执行次数称为语句频度或时间频度。记为T(n),n表示问题的规模。
时间复杂度O(n):
在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
T(n)=O(f(n))–>这样用大写O来体现时间复杂度的的记法,我们称为大O表示法。
PS:这里的T(n)表示的就是代码运行的时间,只是这个(n)表示的是数据规模,f(n)表示的是计算代码执行次数的表达式,O则表示执行时间T(n)和代码执行次数总和f(n)成正比。或者说:时间复杂度就是时间频度去掉低阶项和首项常数。
注意:时间频度和时间复杂度时不同的,时间频度可能不同,但时间复杂度可能相同。
例如:T(n) 不同,但时间复杂度可能相同。 如:T(n)=n²+5n+6 与 T(n)=3n²+3n+2 它们的T(n) 不同,但时间复杂度相同,都为O(n²);
简单来讲,我们只需要计算大概执行次数,这里使用大O的渐进表示法。
时间复杂度为什么不使用时间来衡量而使用基本语句的运行次数来衡量?
- 一个程序在不同的运行环境,执行时间不同,但是程序单语句的执行次数不变。
时间复杂度最优,平均,最差情况:
- 最优情况:任意输入规模下最下运行次数。
- 最差情况:任意输入规模下最大运行次数。
- 平均情况:任意输入规模的期望运行次数。
例如:
在一个长度为N数组中搜索一个数据X,最优情况:1次找到,最差情况:N次找到,平均情况:(1+2+3+4+…N)/2N,用渐进法表示,为N/2次。
为什么时间复杂度看的是最差情况?
- 一般不特别说明,讨论的时间复杂度均是最坏情况下的时间复杂度。因为平均复杂度比较难计算。
- 这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的上界,这就保证了算法的运行时间不会比任何更长。
- 如果最差情况下的复杂度符合我们的要求,我们就可以保证所有的情况下都不会有问题。
比如:我要求你在字典里查一个字,并告诉我在字典的那一页。如果一页一页的翻,你需要多少时间呢?
最优的情况是这个字在字典的第一页,最坏的情况是在最后一页。所以即使我为难你,你也不会花比找整个字典最后一个字还长的时间,但当然聪明的你,肯定会根据部首,笔画去找,才不会傻乎乎的一页一页的找,此时的你肯定会择优选择,因为此时你最坏的情况也就是我给您的字部首,笔画最多,除了部首外笔画最多的一个超级复杂的字,但显然比翻整本字典快的多。
为了更好的说明算法的时间复杂度,我们定义了O,Ω,Θ符号:
O(欧米可荣)符号算法时间复杂度的上界(最坏的情况<=),比如T(n)=O(n2)。Ω(欧米伽)符号算法时间复杂度的下界(最好的情况>=),比如T(n)=Ω(n2)。Θ(西塔)符号算法时间复杂度的精确阶(最好和最坏是同一个阶=),比如T(n)=Θ(n2)。
时间复杂度的计算技巧:
- 只关注循环次数最多的那一段代码(基本语句)。通常是最内层循环的循环体,由于我们最终也会忽略常数、系数(包括所有低次幂和最高次幂的系数)、低阶等等,所以我们在初步计算的时候就直接忽略它们,没毛病。
- 如果存在方法嵌套的情况,最终的复杂度就是嵌套内外复杂度的积。这个也好理解,外层运行m次,里层运行n次,那么里层则运行m*n次,外层较内层属于低阶,可以忽略。
- 计算基本语句的执行次数的数量级:只需要计算基本语句执行次数的数量级,这就意外着只要保证基本语句执行次数的函数中的最高次幂正确即可。可以忽略系数(包括所有低次幂和最高次幂的系数)。这样能够简化算法分析,并且使注意力集中在最重要的一点:增长率。
- 用大O符号表示算法的时间性能:将基本语句执次数的数量级放到大O符号中即可。
- 如果我们的方法很复杂,比如几十上百行,我们只需要计算最“复杂”的那一段代码的复杂度即可,原理类似于忽略低阶。
- 不论代码有多少行,一般如果没有循环、递归等可能涉及到迭代操作的,时间复杂度都是O(1)。
时间复杂度举例:
1)时间复杂度为O(1)的简单语句:
int i=10;
2)100个简单语句的时间复杂度也是O(1),(100是常数,不是趋向无穷大的n)
3)时间复杂度为O(n)的循环语句:
public int calculate(int n) {
2 int result = 1;
3 for (int i = 1; i <= n; i++) {
4 result *= i;
5 }
6 return result;
7 }
基本操作次数T(n)为n。
用大O渐进法表示,它的时间复杂度为: O(n)。
public int calculate(int n) {
2 int result = 1;
3 for (int i = 1; i <= n; i+=2) {
4 result *= i;
5 }
6 return result;
7 }
基本操作次数T(n)为n/2。
用大O渐进法表示,它的时间复杂度为: O(n)。
4)时间复杂度为O(log2n)的循环语句:
int count = 0;
for (int i = 0; i < n; i*=2) {
count++;
}
基本操作次数T(n)为log2n。
用大O渐进法表示,它的时间复杂度为: O(log2n);
5)时间复杂度为O(nlog2n)的循环语句:
int count = 0;
for (int i = 0; i < n; i*=2) {
for(int j=0;i<=n;j++){
count++;
}
}
基本操作次数T(n)为nlog2n。
用大O渐进法表示,它的时间复杂度为: O(nlog2n)。
6)时间复杂度为O(n2)的循环语句:
public int calculate(int n) {
2 int result = 1;
3 for (int i = 1; i <=100 n; i++) {
for(int j=1;j<=10n;j++){
result *= i;
}
4
5 }
for(int k=1;k<=2*n;k++){
result *= i;
}
6 return result;
7 }
基本操作次数T(n)为100n10n+2n。
用大O渐进法表示,它的时间复杂度为: O(n2)。
public int calculate(int n) {
2 int result = 1;
3 for (int i = 1; i <=n; i++) {
for(int j=1;j<=i;j++){
result *= i;
}
6 return result;
7 }
PS:j的运算次数取决于i的值,即当i=1时,j循环1次,i=2时,j循环2次,依次类推。即T(n)=1+2+3+…+n;
基本操作次数T(n)为n2/2+n/2。
用大O渐进法表示,它的时间复杂度为: O(n2)。
常见时间复杂度 :

常见时间复杂度大小:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
PS:时间复杂度级别越大,执行效率就越低。
三、空间复杂度:
1) 空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。空间复杂度不是计算程序占用了多少空间,而是临时变量的个数。
2) 其实空间复杂度和时间复杂度是类似的,时间复杂度表征的是随输入数据规模的变化,其时间消耗的变化趋势。
3) 空间复杂度则为随输入数据规模的变化,其空间消耗的变化趋势。
4) 算法临时所需存储空间的度量,记作: S(n)=O( g(n) ) 其中 n 为问题的规模。 临时变量的个数与问题的规模n无关。
一个算法在计算机存储器上所占用的存储空间包括:
- 存储算法本身所占用的存储空间。
- 算法的输入输出数据所占用的存储空间。
- 算法在运行过程中临时(辅助)占用的存储空间。
PS: 如果额外空间相对于输入数据量来说是个常数,则称此算法是原地工作。
算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随本算法的不同而改变,与算法无关,则只需要分析出输入输出和存储算法本身的辅助存储空间即可。存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。
空间复杂度分析1:
int count ,i,j,k;
for (int i = 1; i < n; i++) {
for(int j=1;j<=i;j++){
for(int k=1;k<=j;k++){
count++;
}
}
}
由于算法中
临时变量的个数与问题的规模n无关,所以空间复杂度均为S(n)=O(1)。
空间复杂度分析2:
void fun(int i,int j,int k){ int count ,i,j,k; for (int i = 1; i < n; i++) { for(int j=1;j<=i;j++){ for(int k=1;k<=j;k++){ fun(i,j,k); } }} }
此算法属于递归算法,每次调用本身都要分配空间,所以
fun(i,j,k)的空间复杂度为O(n)。
注意:
- 空间复杂度比时间复杂度分析要少。
- 对于递归算法来说,代码一般比较简短,算法本身占用的存储空间较少,但运行时需要占用较多的临时工作单元,若写成非递归算法,代码一般比较简长,算法本身占用的存储空间较多,但运行时需要占用较少的临时工作单元。
总结:
我们要明确一点,时间复杂度和空间复杂度是一个理论上的模型,它们的目的是提供给我们一种可以在短时间内评估代码在大多数情况下的一个性能消耗随数据集规模变化的走势,让我们对代码的“优劣”有一个大致的了解,但是这种了解是感性的,它并不代表最终的结果。比如理论上,O(logn)是要优于O(n)的,但是根据输入数据的不同,结果可能会不符合我们的“预期”(后面讲解具体的算法的时候会提到),我们在选择算法的时候要根据实际情况综合分析。而我们提到的复杂度有很多,什么最好情况、最坏情况、加权平均、均摊等等,看起来还是很复杂,其实我们在绝大多数情况下,只用一种分析方式分析就可以了,不要忘记我们的初衷,除非你需要这么做。
好了,这篇文章我们大概了解到了数据结构和算法相关的概念,下篇文章我们将继续探讨 线性结构【史上最全的数据结构讲解 ---- 线性结构 (2)】相关的知识。