【自学】Transformer——NLP、计算机视觉常见算法模型
该知识点学自两个视频——
1、Knowing AI知智(b站)
2、李宏毅(YouTube)
目录
一、Knowing AI知智(b站)
1.1什么是Transformer
1.2什么是Attention
1.3什么是BERT
1.4什么是GPT
1.5什么是ViT
二、李宏毅(YouTobe)
2.1Self-Attention的演变
2.2视频链接及其他大牛对Transformer的理解
三、笔者理解
3.1整体架构
3.2Encoder
3.3Decoder
3.4Transformer的训练
建议:①为了更好地帮助自己理解视频内容,我可能会对视频演讲者的说话内容以文字形式记录下来,我也会把视频链接附上,各位读者请注意辨别。②学习Transformer之前最好先学习RNN(循环神经网络)、Seq2Seq模型,有助于理解哦!
一、Knowing AI知智(b站)
1.1什么是Transformer
什么是transformer?【知多少】_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1Zz4y127h1/?spm_id_from=333.337.search-card.all.click&vd_source=23dd4249b2e4e05d2a24fb7ba074103b
https://www.bilibili.com/video/BV1Zz4y127h1/?spm_id_from=333.337.search-card.all.click&vd_source=23dd4249b2e4e05d2a24fb7ba074103b
单词的先后顺序会影响句子的意义,而RNN擅长捕捉序列关系,因此它可以用于处理机器翻译模型。但是对于翻译而言,句子间的单词数量并非是一一对应的,受限于结构。RNN只能实现N to N、1 to N、N to 1的模式,而对于N to M的问题却不能很好地来解决。
后来呢人们找到了Seq2Seq模型,该模型拥有一个编码器Encoder和解码器Decoder,这两种器件均是RNN网络。先由Encoder提取原始句子的意义,再由Decoder将意义转换成相应的语言,其中“意义”是这两个器件之间的中介。但是“意义”单元能存储的信息是十分有限的,如果句子太长,翻译精度就会下降,所以后来人们找到了一种称为“Attention”的注意力机制,在原有的Seq2Seq基础结构上,生成每个单词时,都有意识的从原始句子中提取生成该单词时最需要的信息,成功摆脱输入序列的长度限制。但是这种结构的计算方式还是太慢了,RNN需要逐个“看”过句子中的单词,才能给出输出。
为了解决计算慢速的问题,人们进一步找到了Self-Attention自注意机制——先提取每个单词的意义,再依据生成顺序选取所需要的信息,这样的结构不仅支持并行运算,而且效率高,类似人类翻译句子的过程。此时模型已经由原来的RNN结构演变成现在基于Self-Attention且拥有一个Encoder和一个Decoder的模型,即Transformer。Transformer于2017年由谷歌团队在论文《Attention is All You Need》中提出。Transformer在NLP中得到广泛应用(如文本摘要、文本生成、Chatbot),也在计算机视觉领域中得到应用(如ViT、图像分类),亦或是语音识别、股价预测。
下面附上视频的总结图:
1.2什么是Attention
什么是 Attention(注意力机制)?【知多少】_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1G64y1S7bc/?spm_id_from=333.337.search-card.all.click 上文提到了Attention注意力机制,那么在这部分内容中将会对Attention做一个更加详细的介绍,它于2014年被提出。关于“注意力”这个词首先想到的是我们人类在忙活、在完成某些任务时,都会把自己的注意力放在当前要做的事情上,也就是说即使一天当中我们需要完成很多事情,小到刷牙洗脸吃饭,大到学习工作敲代码,但是在面对不同的事情,我们只会专注于当下的任务。因此“注意力机制”这个名称非常形象地概括了该模型的特点和作用。
Attention也像是一个简化过程,它能从纷繁复杂的数据中找出当前输出最重要的部分。一个典型的Attention包括三个部分:Q(Query)、K(Key)、V(Value),Q表示输入的信息,Key和Value成组出现,通常是原有的源语言、原始文本等已有的信息。
那么Q、K、V这三个量是如何协同合作的呢?首先通过计算Q与K之间的相关性,得出不同的K对输出的重要程度,再与对应的V相乘求和,得到Q的输出(Attention Value)。以阅读理解为例,Q是问题,K与V是原始文本,计算相关性即找到文本中最需要注意的部分,利用V得到了答案。
Attention模型还延伸出了其他模型。如Self-Attention,Self-Attention只关注输入序列元素之间的关系,通过将输入序列直接转化为Q、K、V,内部进行Attention计算,能很好地捕捉文本的内在联系。另一种进化结构是MULTI-HEAD-Attention(多头注意力机制),是在自注意力机制的基础上使用多种变换生成的Q、K、V进行运算,再将它们对相关性的结论综合起来,进一步增强Self-Attention的效果。
Attenton在NLP中应用广泛,但其最初诞生于计算机视觉领域。
1.3什么是BERT
机器要想理解图像,则必须先将图像转换为RGB数值来表示,同理,机器想要理解语言,需要将语言转换由数字组成的向量。那么为什么是向量呢?词语的意义之间是有关联的,距离可以表示词与词之间的关系,比如苹果和梨都是水果,那么它们之间的距离就会比苹果和猫之间的距离来得近。问题又来了,这些向量该如何获得呢?机器学习的出现让我们不必一一为单词设计向量,只需要将数据交给模型,模型就会自动给出这些数据各自对应的向量(也即适合它们的位置),而BERT就是帮助我们找到向量(位置)的模型之一。(下面附上有关词向量的链接)
一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/164502624 BERT诞生于2018年,源于Transformer,实际上它是其中的Encoder。前面介绍Transformer的时候介绍过其Encoder能很好地理解单词的意义,既然如此人们就想将该部分单独抽离出来使用,没准能获取不错的效果。说干就干,嘿好家伙,没想到还真可以。
此外,人们还为BERT设计了独特的训练方式,其中之一是有遮挡的训练,在收集到的语料中,随机覆盖15%(这里我有一个疑问,为啥是15%?)的词汇,让BERT去猜被遮挡的词是什么,该方式可以让BERT更好的依据语境作出预测;或者输入成组的句子,让BERT去判断两个句子是否相连,该方式可以让BERT对上下文关系有更好的理解。在处理不同NLP任务时,需要将已经训练好的BERT依据任务目标增加不同功能的输出层联合训练,例如文本分类任务就增加了分类器,输入句子输出类别;阅读理解增加了一个全连接层,输入问题和文章,输出答案的位置;在联合训练过程中,BERT只需要进行微调即可。
BERT的可解释性好(我有一个疑问就是为啥说它好嘞?理由和依据是啥?),关于什么是可解释性,可看附上的文章。我的理解是当你拿到一个东西,你可以说出它的来龙去脉,当它在使用过程中如果异常了,你能很快根据对它的了解来判断并解决问题,那么这个东西就是可解释的;反之如果这个东西你是一知半解或者全然无知,它的工作结果只能靠猜,存在许多不确定性因素,那么这个东西就是不可解释的,这里的你指代是普遍的人,而不是个例。如果我的理解有不到位的地方还请多多指正!
万字长文概览深度学习的可解释性研究 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/110078466#:~:text=%E5%8F%AF%E8%A7%A3%E9%87%8A%E6%80%A7%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F%20%E5%B9%BF%E4%B9%89%E4%B8%8A%E7%9A%84%E5%8F%AF%E8%A7%A3%E9%87%8A%E6%80%A7%E6%8C%87,%E5%9C%A8%E6%88%91%E4%BB%AC%E9%9C%80%E8%A6%81%E4%BA%86%E8%A7%A3%E6%88%96%E8%A7%A3%E5%86%B3%E4%B8%80%E4%BB%B6%E4%BA%8B%E6%83%85%E7%9A%84%E6%97%B6%E5%80%99%EF%BC%8C%E6%88%91%E4%BB%AC%E5%8F%AF%E4%BB%A5%E8%8E%B7%E5%BE%97%E6%88%91%E4%BB%AC%E6%89%80%E9%9C%80%E8%A6%81%E7%9A%84%E8%B6%B3%E5%A4%9F%E7%9A%84%E5%8F%AF%E4%BB%A5%E7%90%86%E8%A7%A3%E7%9A%84%E4%BF%A1%E6%81%AF%20%E3%80%82%20%E6%AF%94%E5%A6%82%E6%88%91%E4%BB%AC%E5%9C%A8%E8%B0%83%E8%AF%95bug%E7%9A%84%E6%97%B6%E5%80%99%EF%BC%8C%E9%9C%80%E8%A6%81%E9%80%9A%E8%BF%87%E5%8F%98%E9%87%8F%E5%AE%A1%E6%9F%A5%E5%92%8C%E6%97%A5%E5%BF%97%E4%BF%A1%E6%81%AF%E5%AE%9A%E4%BD%8D%E5%88%B0%E9%97%AE%E9%A2%98%E5%87%BA%E5%9C%A8%E5%93%AA%E9%87%8C%E3%80%82

1.4什么是GPT
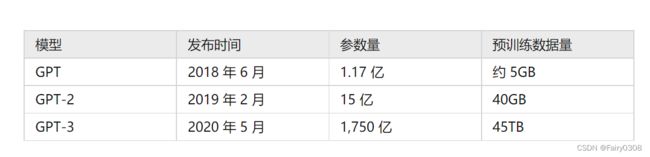
什么是 GPT?【知多少】_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Jv411a7RB/?spm_id_from=333.337.search-card.all.click&vd_source=23dd4249b2e4e05d2a24fb7ba074103b GPT结构同样源于Transformer,实际上它是其中的Decoder。GPT同样是一个需要面对不同任务进行微调的语言模型,不过由于刚面世的时候效果不如BERT,所以没有受到广泛关注。在提升了网络层数和训练数据量后推出了GPT-2,后来又将数据量拓展到45TB,最终获得拥有1750亿参数,大小超过700G的GPT-3。在使用GPT-3的时候,只要输入问题,它就能输出答案,不需要面对不同的问题再训练,也不需要调试就能使用,也即所谓的零样本学习。GPT-3更像一个接近于以一个包含知识,语境理解和语言组织能力的“数据库”。GPT-3作为一个商业项目没有开源,只能通过OpenAI官网申请使用API。
1.5什么是ViT
什么是 ViT(Vision Transformer)?【知多少】_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV18u411m7PY/?spm_id_from=333.337.search-card.all.click&vd_source=23dd4249b2e4e05d2a24fb7ba074103b 顾名思义,就是将Transformer应用在计算机视觉领域。由于Transformer的输入是词语句子即序列,而图像是一种二维数据,所以需要将二维的数据转换为一维的序列。图片是由像素组成的阵列,将其逐个拆开按顺序排列起来,理论可行,但现实是组成的序列数据量相较于语言序列来说过大,远超计算机处理长度。既然如此,可以将图像分割成小方块,每一个小方块就像单词,组合成的原始图像就像是句子,再将每一个小方块转换为向量输入到Transformer中,如此一来序列长度减短,数据的信息将会更丰富清晰,注意力也会更集中。
Transformer还可以改造成适合目标检测、语义分割的模型。
二、李宏毅(YouTobe)
2.1Self-Attention的演变
由于RNN不容易被平行化,CNN可以平行化,所以有人提出用CNN代替RNN,但是,CNN有一个缺点——需要堆叠多层CNN才能看到输入的全部序列,因为它的第一层的每个“三角形”只看过一小部分序列。最后人们提出用Sel-Attention Layer。
2.2视频链接及其他大牛对Transformer的理解
Transformer——李宏毅讲述https://www.youtube.com/watch?v=ugWDIIOHtPA&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=60Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/338817680(2条消息) 机器学习-31-Transformer详解以及我的三个疑惑和解答_迷雾总会解的博客-CSDN博客_transformer不收敛https://blog.csdn.net/qq_44766883/article/details/112008655
详解Transformer (Attention Is All You Need) - 知乎先导知识Attention残差网络Layer Normalization前言 注意力(Attention)机制[2]由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于… https://zhuanlan.zhihu.com/p/48508221
https://zhuanlan.zhihu.com/p/48508221
为什么残差连接的网络结构更容易学习? - 知乎这几天读了何凯明的残差网络,不得不佩服他对神经网络的深入理解,从他灵感的来源,让我感觉他就是个数学…https://www.zhihu.com/question/306135761/answer/2491142607
三、笔者理解
3.1整体架构

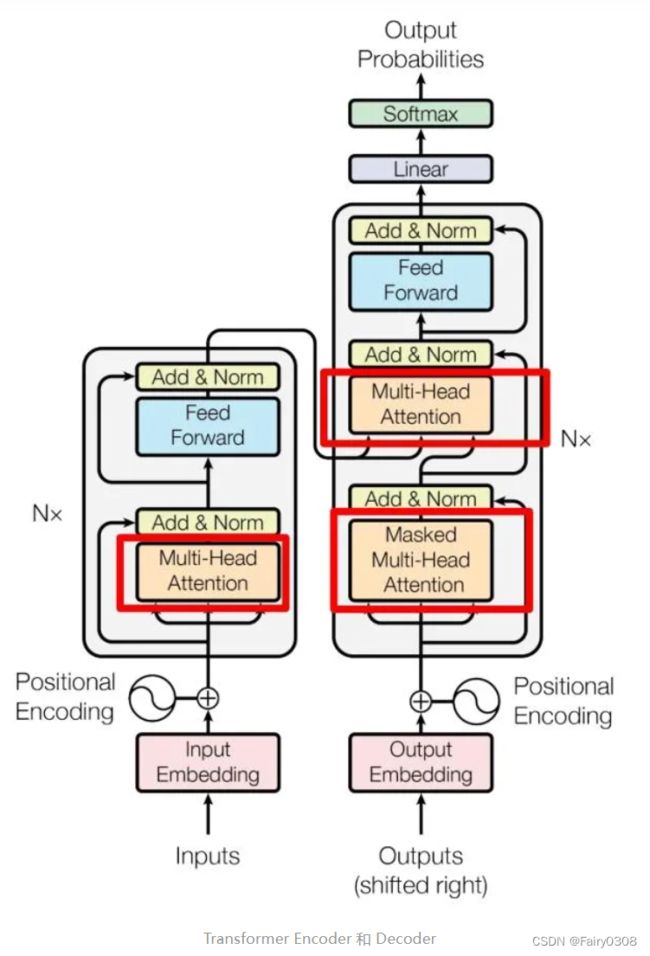
3.2Encoder
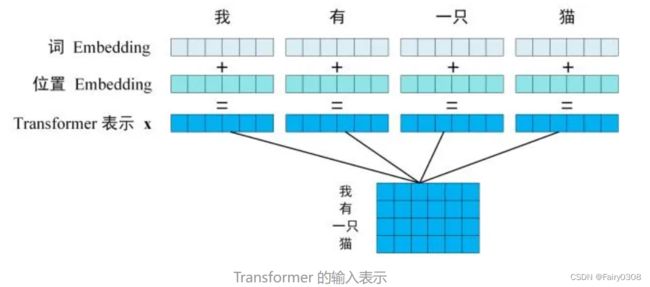
6个encoder block构成一个Encoder,Encoder的输入即第一个encoder block的输入,假设想要翻译的句子是“我有一只猫”,那么输入就是句子经过Embedding后得到每个字的表示向量组成的矩阵,但是之后每一个encoder block的输入都为前一个encoder block的输出。每一个encoder block由Multi-Head Attention、Feed Forward和Add&Norm组成,如下图所见,其中两个Add&Norm计算内容不同,但计算公式一样。
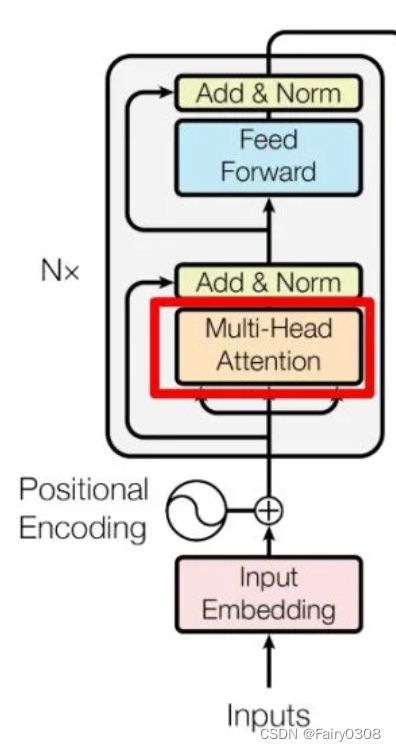
对于一个Multi-Head Attention,其实它是由多个Self-Attention组合而成,如下图所示,也就是说一个encoder block包含多个Self-Attention,但只包含一个Multi-Head Attention,而一个Encoder则包含6个Multi-Head Attention。

将得到的词表示向量矩阵输入Encoder 中,经过 6 个 encoder block后可以得到句子所有单词的编码信息矩阵,如下图所示。这个编码矩阵将作为Decoder的每个decoder block中的Multi-Head Attention的输入之一。3.1第二张图所示内容其实都只是其中一个encoder block和一个decoder block。
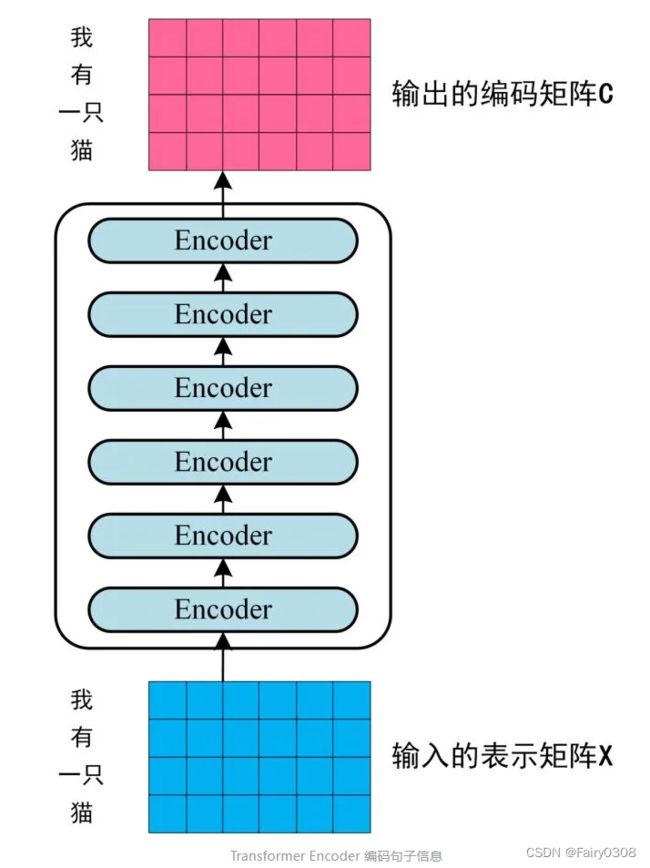
3.3Decoder
6个decoder block构成一个Decoder,Decoder的输入即第一个decoder block的Masked Multi-Head Attention输入,假设被翻译出的句子是“I have a cat”,那么输入就是句子经过Embedding后得到每个单词的表示向量组成的矩阵,但是之后每一个decoder block的输入都为前一个decoder block的输出。每一个encoder block由Masked Multi-Head Attention、Multi-Head Attention、Feed Forward和Add&Norm组成,如下图所见,其中两个Add&Norm计算内容不同,但计算公式一样。
由3.3的第一段描述和下图内容可知decoder block的Multi-Head Attention和Masked Multi-Head Attention的输入不同,Multi-Head Attention的输入由Encoder的输出和Masked Multi-Head Attention的输出组成。其中Encoder的输出用来计算Multi-Head Attention的K、V(可以看出每个decoder block的Multi-Head Attention的Q、K是一样的),Masked Multi-Head Attention的输出用来计算Multi-Head Attention的Q。
Masked Multi-Head Attention和Multi-Head Attention的区别就在于,Masked Multi-Head Attention在SoftMax的前一步多加了一步QK与Mask矩阵相乘的步骤。

一个decoder block包含一个Masked Multi-Head Attenton和一个Multi-Head Attention,那么Encoder则包含6个Masked Multi-Head Attenton和6个Multi-Head Attention。
3.4Transformer的训练
①训练时:第i个decoder的输入 = encoder输出 + ground truth embeding;
预测时:第i个decoder的输入 = encoder输出 + 第(i-1)个decoder输出
②训练时因为知道ground truth embeding,相当于知道正确答案,网络可以一次训练完成。
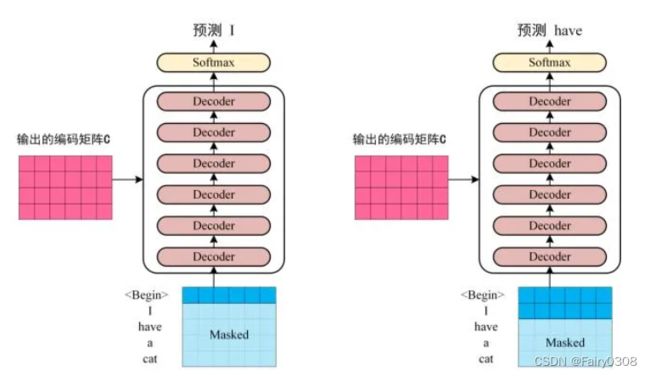
预测时,首先输入start,输出预测的第一个单词 然后start和新单词组成新的query,再输入decoder来预测下一个单词,循环往复直至end。从3.1的第一张图其实也可以看出Decoder是没有单词表示向量矩阵作为输入,只有Encoder的输出作为输入,因此这张图显示的其实是训练好后的模型,在训练过程中Decoder是具有单词向量矩阵作为输入的。
③训练Transformer的输出Z矩阵中,已经包含了对目标句子的每个单词的预测(每行对应一个单词)。也就是说明,Transformer的输入是一条句子一起输入,输出的也是整个句子(各个单词在一个输出矩阵中同时输出。简单一句话就是:输入或者输出的是一个矩阵(整个句子)。
有人提出疑问:输入一个句子之后开始预测,是不是encoder部分只执行一次,然后是decoder部分不停地重复执行,依次输出I, I hava,I have a,I have a cat(最终输出结果) ?
有人对这个疑问的回答:本质上是一个一个单词生成的,但是由于生成速度比较快,所以他看起来是一下子都输出的。但是实际上,输出的是有先后顺序的,(begin)输出后才有I,begin I都有输出后才有have。
④Wq,Wk,Wv这个三个矩阵一开始是直接随机初始化得到的,它在训练过程中就行更新,和其他参数一样根据梯度下降进行更新。
本文提出的算法对应的论文如下:
Attention is All You Need.(Transformer)
Recurrent Models of Visual Attention(最早提出用于图像分类的Attention)
Neural Machine Translation by Jointly Learning to Align and Translate(第一次提出将Attention用于NLP)
BERT
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(ViT)