深度学习论文复现:MTCNN算法分析笔记
MTCNN算法分析笔记
- 1. 项目来源
-
- (1)论文题目
- (2)实现目标
- (3)相关资源
- 2. 代码运行
-
- i)图像标注
- ii)生成PNet训练数据
- iii)训练PNet
- iv)生成RNet训练数据
- v)训练RNet
- vi)生成ONet训练数据
- vii)训练ONet
- 3. 算法与代码分析
1. 项目来源
(1)论文题目
本次复现的论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks ,原作者是使用Matlab进行算法实现的。
(2)实现目标
本次的任务是基于该论文的Pytorch实现,使用百度Paddle Paddle框架对其进行复现。这篇博客则是以论文的Pytorch复现为基础,对MTCNN论文与算法进行学习与分析。
(3)相关资源
按要求下载以下资源:
-
参考Github前辈的复现代码,自己做了一点点修改
百度网盘:https://pan.baidu.com/s/14otWIZM8ix-dNoBkCYGoiA
提取码:xwet -
WIDER FACE数据集中的wider_face_split.zip与WIDER_train.zip压缩包,解压后存放路径分别为:
MTCNN_TUTORIAL-MASTER/data_set/wider_face_split/
MTCNN_TUTORIAL-MASTER/data_set/WIDER_train/ -
登录FDDB官网下载数据集,包括原图Original images与标注文件Face annotations,存放路径分别为:
MTCNN_TUTORIAL-MASTER/data_set/train/
MTCNN_TUTORIAL-MASTER/data_set/FDDB-folds/
2. 代码运行
由于本论文每个阶段的训练与测试过程都是按照PNet-RNet-ONet的顺序级联进行的,前一阶段的训练结果为后一阶段的网络输入,故而训练与测试均需要分多个阶段进行,下面将逐个对各阶段进行简要分析。
i)图像标注
在MTCNN_TUTORIAL-MASTER/data_preprocessing/文件夹下新建文件夹anno_store,并执行如下指令
python data_preprocessing/transform.py
将在该路径下生成文件anno_train.txt,以将预先下载的wider_face_split/wider_face_train.mat标记文件转换为txt格式。
转换后的wider_face_train.txt文件中记录有数据集中原图像地址,以及作为ground truth的人脸框坐标。
ii)生成PNet训练数据
输入PNet的训练数据,按图像交并比IOU的值,分为三部分:0-0.3划分为negative,0.4-0.65划分为part,0.65-1划分为positive。
执行如下指令
python data_preprocessing/gen_Pnet_train_data.py
该文件负责从原图中crop出图像并按照IOU值进行分类,将三种标签的数据分别存入data_set/train/12/negative/,data_set/train/12/part/,data_set/train/12/positive/
--------------------------------------一条分割线-------------------------------------------
再执行下述指令
python data_preprocessing/assemble_Pnet_imglist.py
组装PNet的数据集注释文件并完成shuffle,将其打乱,自此完成PNet训练数据的准备
iii)训练PNet
执行下述语句
python train/Train_Pnet.py
训练过程中,PNet网络的train模式与val模式交替进行。
值得一提的是,首次训练之前,需要创建验证集对应的文件夹data_set/val/12/,文件夹中将生成pos_12_val.txt,part_12_val.txt,neg_12_val.txt三个标注文件。
iv)生成RNet训练数据
创建data_set/train/24/文件夹,执行如下命令
python data_preprocessing/gen_Rnet_train_data.py
python data_preprocessing/assemble_Rnet_imglist.py
功能大致与第二步中PNet数据准备的功能相同,data_set/train/24/文件夹中将生成pos_24_val.txt,part_24_val.txt,neg_24_val.txt三个标注文件
v)训练RNet
执行下述语句,功能大致与第三步中PNet网络训练相同
python train/Train_Pnet.py
vi)生成ONet训练数据
创建data_set/train/48/文件夹,执行下列语句
python data_preprocessing/gen_Onet_train_data.py
功能与第二步中PNet数据准备功能相同,文件夹中将生成pos_48.txt, part_48.txt, neg_48.txt三个标注文件
由于第三阶段ONet,即Output Net需要输出脸部 landmark坐标,故而在数据准备阶段需要额外生成data_preprocessing/anno_store/landmark_48.txt文件,记录面部标志点信息,执行下述语句
python data_preprocessing/gen_landmark_48.py
为完成ONet训练数据的预处理与shuffle,执行下述语句
python data_preprocessing/assemble_Onet_imglist.py
vii)训练ONet
执行下述语句,功能大致与第三步中PNet网络训练相同
python train/Train_Onet.py
自此,训练、验证阶段完成
下面展示一下我们的训练过程与测试结果~
训练过程之模型导入

训练过程

测试过程:

测试效果:





加载了训练好的模型,我们又训练了几轮,效果还挺好的,是吧~
3. 算法与代码分析
对照代码通读论文,对模型与算法进行一系列分析。
-
整体来看,整个训练过程其实是三个网络按照P-R-O的顺序迭代进行的,包括训练与验证,都是级联进行的。同时,网络在整体上保持着数据准备(随机crop出训练用图像边框,并按其IOU值分为positive、part、negative三类)、数据扰乱、网络训练的顺序进行的,PRO三个网络首尾相接。
-
网络在训练过程中,每一个stage分别对人脸二分类,边界框回归、人脸关键点三个任务进行loss值的运算。至于loss函数的选取,人脸二分类问题使用交叉熵损失函数,其余问题则应用均方误差MSE。
值得一提的是,由于PNet与RNet中feature map尺寸较小,对于landmark的识别较为困难,故而我们只在最后的ONet中引入人脸关键点检测的任务,故而也只有在ONet的训练过程中对人脸标志点landmark进行均方误差的计算。
下面的这张图或许具有一定的误导性,让你以为在PNet与RNet中同样进行landmark任务的训练,但其实作者在代码中已经给出了明确的答案。
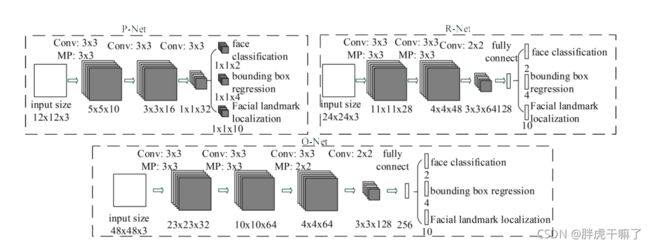
-
依靠上图,我们对网络架构进行解释:为了提升网络的性能,作者应用3x3滤波器代替5x5卷积核,激活函数方面则使用PReLu,大概是下图这个形状的。
至于PRO网络的具体形状,输入数据分别为12x12x3,24x24x3,48x48x3,后续经过一系列的卷积、池化、卷积、池化,完成主干网络的训练。将之感网络训练的结果分别输入到两个(ONet是三个)分支中,使用不同卷积核对其进行训练,分别对应face classification,bounding box regression,facial landmark localization三个任务。
值得一提的是,在ONet中,由于相较P、R网络更为复杂,故而多设置了一道卷积层,期望通过网络深度的增加换取更优的性能。

-
关于数据准备阶段,随机crop出样本框的技巧,即得到neg、part、pos三类样本的方法。以data_preprocessing/gen_Pnet_train_data.py为例,直接上代码,分一大一小两个for循环完成。
下面是一个小的for循环,只负责取35个负样本(其实第二个for循环中也取得了一些负样本)
neg_num = 0
while neg_num < 35:
# 随机crop出一些不同大小的正方形框框(边长最小是12),35个负样本中允许较大的negative出现
# width与height为image的宽和高
size = np.random.randint(12, min(width, height) / 2)
nx = np.random.randint(0, width - size)
ny = np.random.randint(0, height - size)
crop_box = np.array([nx, ny, nx + size, ny + size])
Iou =IoU(crop_box, boxes)
cropped_im = img[ny: ny + size, nx: nx + size, :]
#放缩到固定大小,方便第一阶段PNet运算
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
if np.max(Iou) < 0.3:
# Iou with all gts must below 0.3
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
f2.write(save_file + ' 0\n')
cv2.imwrite(save_file, resized_im)
n_idx += 1
neg_num += 1#每张图片找出35个negative样本为止
此部分代码的目的是为了在较大的范围内进行随机crop,取得35个negative样本。样本框为边长大于12的正方形,框的取值范围是分布在整张图片上的。
下面是一个大的for循环,positive,part,negative三种样本都有涉及
# 在ground true的坐标内
for box in boxes:
# box (x_left, y_top, w, h)
x1, y1, x2, y2 = box
w = x2 - x1 + 1
h = y2 - y1 + 1
# ignore small faces
# in case the ground truth boxes of small faces are not accurate
if max(w, h) < 40 or x1 < 0 or y1 < 0 or w < 0 or h < 0:
continue
# generate negative examples that have overlap with gt,生成和ground true有重合的负样本
for i in range(5):
size = np.random.randint(12, min(width, height) / 2)
# delta_x and delta_y are offsets of (x1, y1)
delta_x = np.random.randint(max(-size, -x1), w)
delta_y = np.random.randint(max(-size, -y1), h)
nx1 = max(0, x1 + delta_x)
ny1 = max(0, y1 + delta_y)
if nx1 + size > width or ny1 + size > height:
continue
crop_box = np.array([nx1, ny1, nx1 + size, ny1 + size])
Iou = IoU(crop_box, boxes)
cropped_im = img[ny1: ny1 + size, nx1: nx1 + size, :]
# 放缩为固定大小
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
if np.max(Iou) < 0.3:
# Iou with all gts must below 0.3
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
f2.write(save_file + ' 0\n')
cv2.imwrite(save_file, resized_im)
n_idx += 1
# generate positive examples and part faces,在ground truth 的基础上,生成正样本和part样本
for i in range(20):
size = np.random.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
# delta here is the offset of box center
delta_x = np.random.randint(-w * 0.2, w * 0.2)
delta_y = np.random.randint(-h * 0.2, h * 0.2)
nx1 = max(x1 + w / 2 + delta_x - size / 2, 0)
ny1 = max(y1 + h / 2 + delta_y - size / 2, 0)
nx2 = nx1 + size
ny2 = ny1 + size
if nx2 > width or ny2 > height:
continue #随机失败,跳过
crop_box = np.array([nx1, ny1, nx2, ny2])
# 归一化
offset_x1 = (x1 - nx1) / float(size)
offset_y1 = (y1 - ny1) / float(size)
offset_x2 = (x2 - nx2) / float(size)
offset_y2 = (y2 - ny2) / float(size)
cropped_im = img[int(ny1): int(ny2), int(nx1): int(nx2), :]
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
box_ = box.reshape(1, -1)
if IoU(crop_box, box_) >= 0.65:#正样本
save_file = os.path.join(pos_save_dir, "%s.jpg" % p_idx)
f1.write(save_file + ' 1 %.2f %.2f %.2f %.2f\n' % (offset_x1, offset_y1, offset_x2, offset_y2))
cv2.imwrite(save_file, resized_im)
p_idx += 1
elif IoU(crop_box, box_) >= 0.4 and d_idx < 1.2*p_idx + 1:#part样本,期望part图像的数目多于正样本的1.2倍
save_file = os.path.join(part_save_dir, "%s.jpg" % d_idx)
f3.write(save_file + ' -1 %.2f %.2f %.2f %.2f\n' % (offset_x1, offset_y1, offset_x2, offset_y2))
cv2.imwrite(save_file, resized_im)
d_idx += 1
代码很长,不逐行解释了,整体上是一个for循环套着两个for。关于小的for循环,前一个for,是在五次迭代中尽量取得一些negative样本,而后一个for循环,是在20次迭代中争取得到一些part和positive样本。
关于整体的这个大的for循环,其实可以发现是对于box的遍历,即对每个ground truth进行遍历。目的是什么呢?结合三种样本的crop过程,其实可以发现,这种crop是围绕在正确人脸框的周围进行随机取值,其实这已经是一种伪随机了。
比较重要但很容易忽视的一点是,代码中出现的宽w与高h,与之前的width、height代表的全图像尺寸不同,w与h是ground truth人脸框的大小,其实这样的取值才能保证crop出的三种样本均位于正确答案周围。
关于这种伪随机操作的意义,对于part与正样本来说,在正确答案周围的随机取值,得到指定数目样本的效率自然是大于在全图随机画框的方法;对于negative样本来说呢,在正确答案周围crop得到的负样本,或许更加具有迷惑性,是一种天然的“难样本”,这与后续代码中“难样本挖掘”的理念不谋而合。
至于循环数分别为5和20的原因,大概是为了使得各类样本的比例大致满足negatives:positives:part(:landmark)= 3:1:1(:2)了吧
- 其实还有一点质疑:为什么人脸框一定要选择一个正方形呢?毕竟胖成圆形的肉肉脸应该还是少数吧,或许可以在后续代码改进的过程中尝试维持宽度不变,而长度乘一个大于1的系数,假如说人脸的长宽比大致是1.5:1,这样可能更为合理,毕竟人脸框形状的选取也会影响IOU的计算,正方形的边框势必导致IOU的计算值较小,或许这一点会影响到模型的灵敏度,这个因素我们会在后面的模型复现中尝试改进。
其实我还没有很大量的看过数据集中的图像哈哈哈,不过我猜测作者可能有过我这种想法,但是数据集中人脸经常会出现不同的倾斜角度,这样的话,正方形的包容性显然比长方形更大了,如果是这样的话,作者大大应该在第五层~~至于具体如何选择,不同的数据集应该有不同的偏向性,还是要后续通过总结数据集特征和实验来证明。总的来说,这个因素我们会在后面的模型复现中尝试改进! - 关于难样本挖掘的实现,作者是通过ohem思想改写损失函数,在loss函数运算的过程中,只在反向传播与梯度下降的过程中应用loss值在前70%的样本,也就是我们所说的难样本,还挺机智的是吧~
- 我发现论文中提到的nms,即非极大值抑制,只在网络的实例测试代码中有看到,而在训练过程中没有能够看到它的应用。这一点我暂时还没能搞明白,可能会和队友、老师讨论一下。