【DeepSeek】复现DeepSeek R1?快来看这个Open R1项目实践指南~
Open R1 项目基于 DeepSeek-R1 的技术报告和方法论,公开并复现 R1 的训练管线,并且希望所有开发者都能在这个基础上搭建自己的研究或应用。
笔者研读了大量资料,对 Open R1 的愿景、原理及在实践层面的具体操作,产生了许多想法。因此,这篇博客会从最初的概念入手,带领大家了解 Open R1 的原理与技术细节,并侧重讲解其中最为关键的强化学习训练方法之一 —— GRPO(群组相对策略优化, Group Relative Policy Optimization)。
第一章:Open R1 项目的由来与核心思想
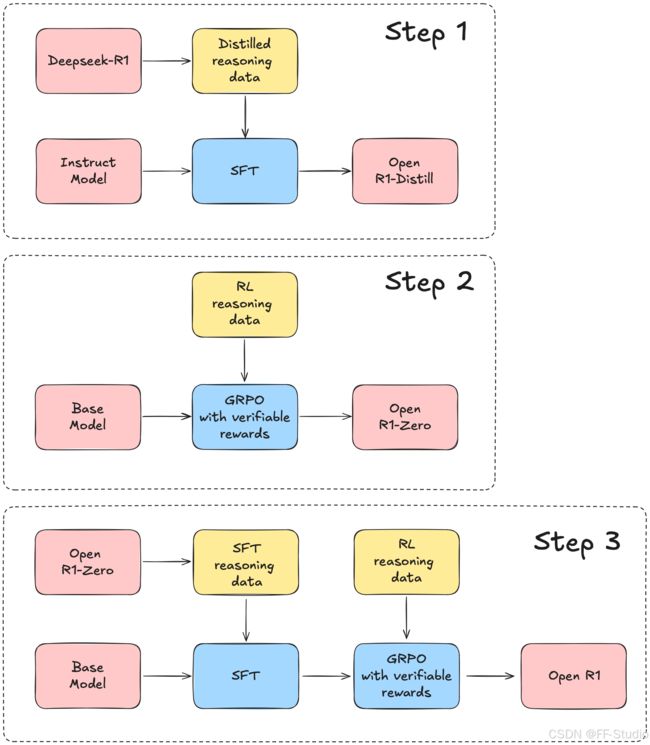
从 Open R1 项目主页(https://github.com/huggingface/open-r1)的介绍可以了解到,该项目想要做到的是“基于 DeepSeek-R1 的技术报告,构建一个完全可复现、可开源、可二次开发的 R1 训练管线”,以此实现与官方 R1 模型不相上下的性能。笔者在阅读官方资料时,发现其思路大致包括以下几个主要阶段:
-
数据蒸馏 (Distillation)
他们会先从 DeepSeek-R1 本体或 R1-Zero 之类的高性能模型中,通过一定的 prompts (提示),生成适合下游训练的数据,使得“较小规模”的模型也能部分吸收 R1 的推理和知识能力。这种做法类似于经典的知识蒸馏 (Knowledge Distillation) 或 Instruct 数据蒸馏,只不过这一次是面向 LLM 之间的蒸馏。
这个阶段产生了R1-Distill小模型。 -
强化学习策略优化
这个阶段很可能是最关键也最复杂的部分,DeepSeek 本身采用了大量 RL、CoT (Chain of Thought) 数据来强化数学推理与复杂多步推理能力。Open R1 的目标就是复现当初官方做法,整合相似或同源数据,并以 GRPO 等方法做纯强化学习训练(即无需再做额外 SFT,人类反馈或奖励模型会引导更新)。 -
多阶段训练
在深度对齐的背景下,一般不会只做单一轮次的训练,而是会分多个阶段。例如:- 阶段 A:先做冷启动的 SFT,保证模型具备初步的思考和多轮对话能力。
- 阶段 B:利用高质量大规模的数据及奖励模型进行强化学习,提升模型的推理和对人类指令的理解能力。
- 阶段 C:将拒绝采样 (Rejection Sampling) 等再结合监督微调 (SFT),修正模型的表达风格,提升回答的连贯度、准确度和安全性等。
- 阶段 D:使用更加泛化的强化学习策略,在更广泛的场景下对齐人类偏好。
Open R1 在 GitHub 提供了多份脚本,包括一些 Makefile 中便于“make”一键调用的指令,大家可以根据需求直接 clone 项目后看他们的脚本实现。至于本篇文章,笔者想从核心训练思路与具体代码解析出发,让大家看到 Open R1 如何在实践层面实现 R1 的复制与扩展。
第二章:Open R1 环境搭建与项目结构概述
虽然我们重点要谈 GRPO 和相关训练,但在那之前,还是得对 Open R1 项目的基本结构和运行方式做一个大致了解。项目内多处文件都提示,若想顺利运行,需要提前满足一些环境依赖。
2.1 Python环境与依赖安装
官方推荐使用 Conda 或 venv 来创建独立的 Python 环境,这样能确保不会与系统其它库产生版本冲突。假设你选择 Conda(以下引用了项目 README 中的示例):
conda create -n openr1 python=3.11 && conda activate openr1
然后安装 vLLM(这是一个高效的推理引擎)以及特定版本的 PyTorch 等。需要注意的是,Open R1 明确要求 PyTorch 版本需要匹配 vLLM 的编译环境。例如示例命令:
pip install vllm==0.6.6.post1
# 如果你的GPU驱动是CUDA 12.1
pip install vllm==0.6.6.post1 --extra-index-url https://download.pytorch.org/whl/cu121
剩余依赖在 setup.py 中可以看到,也可以直接用
pip install -e ".[dev]"
来安装开发版本依赖。这包含了加速工具加 wandb、huggingface_hub、bitsandbytes、deepspeed 等等。安装完后记得登录你的 Hugging Face 账户和 wandb 账户。如果要上载或加载较大的模型文件,还要安装 git-lfs。
笔者提示:有时候 Accelerate、Deepspeed 等版本兼容性较为敏感,出现错误时应第一时间检查版本依赖。另外,项目内可能也提供一些用于 Slurm 分布式训练的脚本,需要注意硬件配置(如 GPU 数量、GPU 显存等)。
2.2 项目文件结构
在根目录下,你会看到一个 src/open_r1 目录,其中包含以下关键脚本:
sft.py:用来做 SFT (Supervised Fine-Tuning) 的脚本,输入可以是某个数据集名称或本地文件,以微调模型。grpo.py:GRPO 训练脚本的核心所在,用于纯强化学习或混合强化学习方式训练模型。evaluate.py:对模型在特定基准任务上做评测的脚本,比如在 MATH、一系列推理任务上进行测试,依赖lighteval等库。generate.py:从已有模型大批量地生成合成数据(Distilabel),用来进行半自动蒸馏或后续微调的用途。
另外还有一些辅助配置文件如 configs/zero2.yaml、configs/zero3.yaml 等,加速配置文件 accelerate_config.yaml,Makefile 等。这些都能让你快速上手多 GPU 甚至多节点的训练或推理命令。
在下文里,我们会多次引用 sft.py、grpo.py 以及 evaluate.py 等文件中的部分片段,然后给出中文注释,帮助理解其中的实现逻辑。
第三章:从简单到复杂,理解 SFT 与 GRPO 的衔接
在正式剖析 GRPO 的实现之前,笔者想先带各位浏览下 SFT(Supervised Fine-Tuning)在 Open R1 项目中的用法与代码结构。因为很多情况下,我们会先做一轮 SFT,把模型从一个基础点“拉到”初步可用的对话或推理水平,然后再进入 GRPO 强化学习阶段。
这样的一种训练管线往往能减少 RL 的收敛难度,也是 DeepSeek-R1 中多阶段训练的一个真实案例。
3.1 SFT 脚本 sft.py 解析
src/open_r1/sft.py 的逻辑核心是:
- 载入模型
- 载入数据集
- 用指定的超参数对数据集进行训练
- (可选)评估与推送到 Hugging Face Hub
让我们先把这段脚本做个简要梳理(以下部分代码来自原项目并加了中文注释),以便了解它是如何将数据与模型拼装起来做微调的。
# sft.py部分内容
from datasets import load_dataset
from transformers import AutoTokenizer
from trl import (
ModelConfig,
ScriptArguments,
SFTConfig,
SFTTrainer,
TrlParser,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
)
def main(script_args, training_args, model_args):
# 1. 配置量化选项
quantization_config = get_quantization_config(model_args)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=model_args.torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
training_args.model_init_kwargs = model_kwargs
# 2. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
trust_remote_code=model_args.trust_remote_code,
use_fast=True
)
tokenizer.pad_token = tokenizer.eos_token
# 3. 加载数据集
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
# 4. 初始化SFTTrainer
trainer = SFTTrainer(
model=model_args.model_name_or_path,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
processing_class=tokenizer,
peft_config=get_peft_config(model_args),
)
# 5. 正式训练
trainer.train()
# 6. 保存模型到本地output_dir,或推送到HF Hub
trainer.save_model(training_args.output_dir)
if training_args.push_to_hub:
trainer.push_to_hub(dataset_name=script_args.dataset_name)
if __name__ == "__main__":
parser = TrlParser((ScriptArguments, SFTConfig, ModelConfig))
script_args, training_args, model_args = parser.parse_args_and_config()
main(script_args, training_args, model_args)
从中我们可以见到几个关键信息:
SFTTrainer:这是来自trl库的一个 Trainer 子类,可以对语言模型做简单的监督微调。peft_config:可选,如果你想使用 PEFT (Parameter-Efficient Fine-Tuning) 技术,比如 LoRA、QP 量化等,就可以在此注入,从而降低大模型微调时的显存占用和算力需求。dataset[...]: SFT 只需要一个已经对齐好格式(比如对话格式或标准格式)的数据集即可,脚本会将其拆分成train、test、validation等部分。
如果你想运行 SFT,你可以用 Accelerate 命令或者直接 python 运行脚本。例如:
accelerate launch --config_file=configs/zero3.yaml src/open_r1/sft.py \
--model_name_or_path Qwen/Qwen2.5-1.5B-Instruct \
--dataset_name HuggingFaceH4/Bespoke-Stratos-17k \
--learning_rate 2.0e-5 \
--num_train_epochs 1 \
--packing \
--max_seq_length 4096 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--gradient_checkpointing \
--bf16 \
--logging_steps 5 \
--eval_strategy steps \
--eval_steps 100 \
--output_dir data/Qwen2.5-1.5B-Open-R1-Distill
上面示例就是把 Qwen/Qwen2.5-1.5B-Instruct 这个模型作为初始点,用 Bespoke-Stratos-17k 数据集进行一轮 SFT。注意 --packing 选项可以将不同样本拼接在同一序列里,这在大序列长模型训练中能提升 GPU 利用率。
当你完成这一阶段,得到的模型就可以算是一个“预热”过的模型,可能在上下文理解、多轮对话等方面会比原始基础模型更好,准备好下一步走向 GRPO 或其他强化学习方法。
第四章:进军强化学习之路——GRPO 原理和代码解读
这一章,笔者将把重点放在 Open R1 中非常核心、也极具代表性的强化学习脚本——grpo.py。在 DeepSeek-R1 以及不少研究中,GRPO(群组相对策略优化) 都被拿来与 PPO 做比较,并展现出内存占用更低、对大模型更友好的优点。让我们先从原理概念开始,再对项目中 grpo.py 里的代码细节做分析。
4.1 GRPO 原理的回顾
既然要讲解实现,先快速回顾下 GRPO 的动机和公式。GRPO 的全称 Group Relative Policy Optimization,它是类似于 PPO 的一种策略梯度方法,但不依赖一个庞大的价值网络来估计优势函数(advantage)。相反,它在同一个问题上生成多条候选输出,然后用奖励模型给这些候选打分,并对分数做组内归一化,形成相对的优势。这样就避免了构建和训练价值网络,从而大幅节省资源。
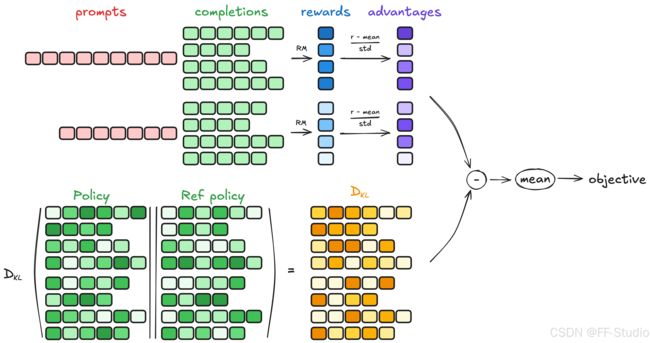
简化地说,如果 PPO 需要 Actor + Critic 两大块(且 Critic 不可或缺),GRPO 则只需要 Actor + 奖励模型,就能完成强化学习训练。具体的数学形式,在 GRPO 论文或一些参考博客中都有介绍,这里仅用一条公式简要概括其要点:
-
对同一批(batch)中的每个问题 q q q,采样 G G G 个输出 { o 1 , o 2 , … , o G } \{o_1, o_2, \ldots, o_G\} {o1,o2,…,oG}。
-
用奖励模型或规则得到分数 { r 1 , r 2 , … , r G } \{r_1, r_2, \ldots, r_G\} {r1,r2,…,rG}。
-
做分组内标准化:
r ~ i = r i − mean ( r ) std ( r ) \tilde{r}_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)} r~i=std(r)ri−mean(r) -
训练时将每个 r ~ i \tilde{r}_i r~i 视为该输出内所有 token 的优势估计,然后再与策略分布 π θ \pi_\theta πθ 的对数几率进行加权,形成一个类似 PPO ratio 的目标函数。
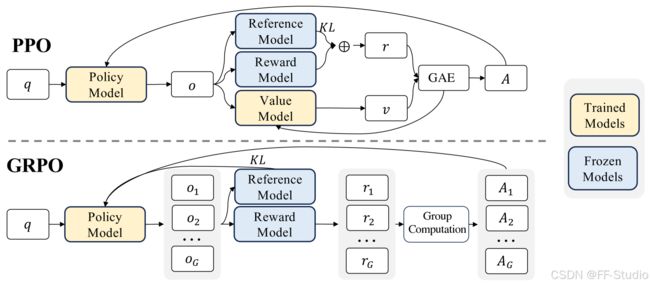
与 PPO 相比,GRPO 更适合应用在“多候选、多对比”的场景,并且节约了一大笔内存。
4.2 grpo.py 源码结构
Open R1 的 grpo.py 文件包含三大部分:
-
脚本参数定义(用
@dataclass或TrlParser进行解析):
这里会引入GRPOScriptArguments,GRPOConfig,ModelConfig等配置项,指定训练的超参数、模型路径、奖励函数等。 -
自定义的奖励函数(reward functions):
其中包括示例的准确度奖励accuracy_reward、格式奖励format_reward等。也提供了一个reward_funcs_registry来把字符串映射到对应函数。 -
训练主函数
main:
其中先加载数据集并做一些映射处理,然后实例化GRPOTrainer并进行train()。
让我们先看部分关键代码,做段落式的解析(结合原项目注释):
# grpo.py部分内容
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer, ModelConfig, ScriptArguments, TrlParser, get_peft_config
@dataclass
class GRPOScriptArguments(ScriptArguments):
"""
Script arguments for the GRPO training script.
Args:
reward_funcs (list[str]): List of reward functions. e.g. ['accuracy', 'format'].
"""
reward_funcs: list[str] = field(
default_factory=lambda: ["accuracy", "format"],
metadata={"help": "List of reward functions. Possible values: 'accuracy', 'format'"},
)
def accuracy_reward(completions, solution, **kwargs):
"""
一个示例奖励函数,检查生成内容与真值解(solution)是否匹配。
"""
contents = [completion[0]["content"] for completion in completions]
rewards = []
for content, sol in zip(contents, solution):
# 这里用 parse/verify 工具做latex解析对比
# 如果匹配就给1.0,不匹配就给0
# ...
reward = float(verify(answer_parsed, gold_parsed))
rewards.append(reward)
return rewards
def format_reward(completions, **kwargs):
"""
一个示例奖励函数,检查补全是否包含特定格式,比如 .*? .*? $"
completion_contents = [c[0]["content"] for c in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]
reward_funcs_registry = {
"accuracy": accuracy_reward,
"format": format_reward,
}
SYSTEM_PROMPT = (
"A conversation between User and Assistant. The user asks a question, ... <省略> ..."
)
def main(script_args, training_args, model_args):
# 1. 根据reward_funcs的字符串,从registry拿到函数列表
reward_funcs = [reward_funcs_registry[func] for func in script_args.reward_funcs]
# 2. 加载数据集
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
# 3. 对数据进行简单处理(比如把"problem"包装成对话格式)
# ...
dataset = dataset.map(make_conversation)
# 4. 初始化GRPOTrainer
trainer = GRPOTrainer(
model=model_args.model_name_or_path,
reward_funcs=reward_funcs,
args=training_args,
train_dataset=dataset[script_args.dataset_train_split],
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
peft_config=get_peft_config(model_args),
)
# 5. 训练
trainer.train()
# 6. 保存和推送
trainer.save_model(training_args.output_dir)
if training_args.push_to_hub:
trainer.push_to_hub(dataset_name=script_args.dataset_name)
if __name__ == "__main__":
parser = TrlParser((GRPOScriptArguments, GRPOConfig, ModelConfig))
script_args, training_args, model_args = parser.parse_args_and_config()
main(script_args, training_args, model_args)
4.2.1 自定义奖励函数
从以上可以看到,Open R1 给出了两个“示例奖励函数”——accuracy_reward 和 format_reward。
- accuracy_reward:对比回答与 gold solution 是否一致,用 parser 做一些 LaTeX 公式提取,然后判断是否相符。
- format_reward:纯粹检查字符串是否匹配某种模板,比如
... ...
在实际项目中,我们可能换成别的,比如针对对话安全性、对话流畅性或其他指标的打分模型,也可能是RM(Reward Model)。只要能返回[float, float, ...]形式就行。
4.2.2 GRPOTrainer
大多数“魔法”其实都在 trl 库提供的 GRPOTrainer 类中完成的。它负责在训练时执行下列逻辑:
- 对同一个“prompt”生成 G 条补全(G = group_size,一般由 config 中指定)
- 用用户传入的“奖励函数”进行打分
- 做组内归一化形成优势
- 根据策略梯度公式和 KL 正则等,更新策略
- 重复若干次迭代
在 Open R1 中就是:trainer = GRPOTrainer(...) 后 trainer.train() 就可以了。
由于 GRPOTrainer 内部的代码量也不小,这里就不展开全部,主要思路与 PPOTrainer 或 RLTrainer 类似,只是去除了对 Critic 的依赖,改成了 group relative 方式的 Advantage 计算。
第五章:运行 GRPO 的完整示例及代码注释
笔者从 Open R1 或类似项目脚本中整理了一个可行的“运行 GRPO”示例,展示如何在命令行上进行调用,以及如何在脚本中整合不同的配置项。假设我们已经完成了前述的 SFT 并有了一个初步可用的模型 my-sft-model,以及一个“有正确答案标注”的数据集 my-math-dataset:
运行指令(简化示例):
accelerate launch --config_file configs/zero3.yaml src/open_r1/grpo.py \
--output_dir my-output-dir \
--model_name_or_path my-sft-model \
--dataset_name my-math-dataset \
--reward_funcs accuracy format \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--logging_steps 10 \
--bf16
在这个命令里,几个关键点:
--model_name_or_path my-sft-model:即我们用于做 RL 训练的初始策略模型,可以是 Hugging Face Hub 上的一个 repo ID,也可以是本地路径。--reward_funcs accuracy format:表示我们希望在训练时,使用 registry 中的 accuracy_reward 和 format_reward 两个函数来生成奖励。最后的奖励会是这两个函数输出的加总或拼接后处理(参见GRPOTrainer的文档)。--per_device_train_batch_size 1:针对大模型,often 我们必须把 batch_size 调得很小,然后通过梯度累积来提高等效 batch size。--config_file configs/zero3.yaml:加速配置,会启用 DeepSpeed Zero-3、bfloat16 算法等,以在多 GPU 机器上进行分布式训练。
主要训练循环就发生在 trainer.train() 中。每当采样到一个 batch 的 prompts,GRPO 就会:
- 生成多条回答 (G 条,每条回答 length up to some max tokens)
- reward_funcs 进行打分
- 计算 group 内的 r ^ i \hat{r}_i r^i 并当作优势
- 做策略梯度更新
- 记录 KL、loss、reward 等指标
由于在大模型中进行 RL 会消耗巨量 GPU 时间,所以要选择合理的小组大小 G、合适的 max_token,并且调参过程也非常重要。例如 lr, weight decay, kl_coef, clip_range 等都是影响结果的重要因素。
第六章:如何结合示例代码进行灵活运用
有了对 SFT 与 GRPO 的理解后,笔者想结合实际代码片段,向大家演示一下如何在自己项目中复用或扩展这些脚本与方法。
6.1 批量生成数据:generate.py + Distilabel
在 Open R1 项目中,generate.py 脚本用来从一个预训练或微调模型里批量生成数据,常与 distilabel 工具配合使用。它可能有如下用途:
- 蒸馏:用大模型/教师模型生成的对话、解题记录,来训练小模型或下一阶段的 SFT。
- 评测:批量产出候选回答,用来做打分或对比。
- RL offline 数据:先生成大量回答,再结合人工标签或半自动标签器,对比好坏,为离线的 RL 或 RFT 做准备。
例如在 generate.py 中,你可以看到类似如下的代码(已加中文注释):
# generate.py
import argparse
from datasets import load_dataset
from distilabel.llms import OpenAILLM
from distilabel.pipeline import Pipeline
from distilabel.steps.tasks import TextGeneration
def build_distilabel_pipeline(
model: str,
base_url: str = "http://localhost:8000/v1",
prompt_column: Optional[str] = None,
temperature: Optional[float] = None,
# ... 省略若干
):
generation_kwargs = {"max_new_tokens": max_new_tokens}
if temperature is not None:
generation_kwargs["temperature"] = temperature
# ...
with Pipeline().ray() as pipeline:
TextGeneration(
llm=OpenAILLM(...), # 这里是对OpenAI API风格或本地vLLM接口的封装
# ...
num_generations=num_generations,
resources=StepResources(replicas=client_replicas),
)
return pipeline
if __name__ == "__main__":
parser = argparse.ArgumentParser(...)
# 解析传入的命令行参数:--hf-dataset, --model, --vllm-server-url 等
args = parser.parse_args()
dataset = load_dataset(args.hf_dataset, split=args.hf_dataset_split)
pipeline = build_distilabel_pipeline(
model=args.model,
base_url=args.vllm_server_url,
# ...
)
# 运行pipeline
distiset = pipeline.run(dataset=dataset)
# 可选:推送到HF Hub
if args.hf_output_dataset:
distiset.push_to_hub(args.hf_output_dataset, private=args.private)
通过上述脚本,你可以一次性针对某个数据集里的 N 条问题(例如 1 万道数学题)生成多条回答。然后对这些回答做存储或发布,从而完成蒸馏数据构建或评测数据收集。
由于 Distilabel 还支持对生成的过程附加一些解析或过滤逻辑,这就可以让你对不合格回答做自动截断,也可以对回答做一些包装,如
6.2 评测与对比:evaluate.py + lighteval
Open R1 也提供了一个 evaluate.py 脚本,用来在特定基准上评估模型的表现。例如 MATH-500, AIME24, 其他自定义评测集等。其内部使用 lighteval 工具,以在本地或多 GPU 下并行评测大量样本。原理上,这个脚本会加载模型,依次对评测数据集做推理,然后将输出结果与参考答案进行对比(常见是用提取 . . . \boxed{...} ... 中答案、用表达式或 LaTeX 做匹配),最后算出准确率等指标。
# evaluate.py
from lighteval.metrics.dynamic_metrics import (
ExprExtractionConfig,
LatexExtractionConfig,
multilingual_extractive_match_metric,
)
from lighteval.tasks.lighteval_task import LightevalTaskConfig
from lighteval.tasks.requests import Doc
# ...
def aime_prompt_fn(line, task_name: str = None):
return Doc(
task_name=task_name,
query=line["problem"],
choices=[line["answer"]],
gold_index=0,
)
aime24 = LightevalTaskConfig(
name="aime24",
# ...
metric=[expr_gold_metric],
version=1,
)
# main
if __name__ == "__main__":
# ...
# python evaluate.py --model deepseek-ai/R1-distill ...
关键是 lighteval 能够自动化地把输入数据(多道题)分发到多块 GPU 上进行推理,并行大大提升评测效率,然后把结果收集起来做准确率或 BLEU/ROUGE/F1 等指标计算。
在大型模型迭代中,快速自动评测也是非常重要的一环。你可以根据需要添加自己的自定义任务和对应的对比函数。
第七章:GRPO 与其他相关方法的对比与扩展
在了解了 Open R1 对 GRPO 的具体实现后,笔者想花点篇幅来谈谈 GRPO 与常见一些强化学习或对齐方法之间的异同,以及我们如何将其扩展到其他项目中。
7.1 PPO 与 GRPO 的区别
- 价值网络:PPO 通常要维护一个与 Actor 大小相仿的价值网络,以评估每个 token 或状态的价值;GRPO 则不需要,通过分组比较来获得优势函数。
- 内存需求:由于不需要价值网络,GRPO 大幅降低了内存消耗,对大模型尤其有利。
- 多候选生成:GRPO 需要在同一个 prompt 上一次性生成多条回答,然后做组内对比,这是其核心;PPO 则可以只用单条回答配合价值网络也能工作。
- 训练稳定性:两个算法都可以使用类似的 ratio clipping、KL 惩罚等技巧。
- 应用场景:如果你的场景天然会生成多条候选并进行比较(比如数学题答题),GRPO 会很自然且效率更高;如果你只关心对每次回答打个单点分数而不想做分组,也许 PPO 更直接。
7.2 DPO, RFT, RRHF 等其他对齐方法
除了 PPO、GRPO,近年也出现了更多对齐算法,如 DPO(Direct Preference Optimization)、RFT(Rejection Sampling Fine-tuning)、RRHF(Ranked Reward Fine-tuning)等等。简单对比:
- DPO:需要成对 (o+, o-) 的比较,通过直接优化 log ( π ( o + ∣ q ) ) − log ( π ( o − ∣ q ) ) \log(\pi(o^+|q)) - \log(\pi(o^-|q)) log(π(o+∣q))−log(π(o−∣q))。不需要大的RL循环,但需要大量成对偏好数据。
- RFT:从同一个 prompt 生成多个回答,过滤出最优回答做 supervision,每条都当作正样本;未被选中的扔掉。实现起来更简单,但对“次优回答”无法利用。
- RRHF:对一组回答按质量排序,然后给出 1、0、-1 等稀疏标签,加到损失里做差分。
- GRPO:可以视为针对“多候选+奖励函数”的RL方法,既不依赖价值网络,也能更灵活地利用多个回答间的相对得分。
实际上,各方法各有优缺点,没有一个是一刀切的完美解法。有些研究者也会把这些方法组合使用,比如先做 RFT 做一个 baseline,再用 PPO 或 GRPO 进一步 fine-tune 等。
7.3 在其他项目中的迁移
如果你不是在做 R1,而是在做自己的对话模型、代码生成模型或知识图谱问答模型,你同样可以把“GRPO”思路整合进去,只要能实现以下几点:
- 能为同一个输入 prompt 生成多条输出(batch 里的每个 prompt 可能生成 G 条输出)。
- 能对这些输出打分(可能是人工、自动奖励模型或规则)。
- 能将这些分数在组内做对比(例如减平均除标准差)。
- 把分组相对奖励当作优势函数,更新策略(可以用
trl库的GRPOTrainer,或自己实现也不难)。
这样,你就可以在不引入价值网络的情况下完成一个 RL 训练闭环。当然,大前提是你得有个行之有效的奖励函数。没有好用的奖励,强化学习就难以收敛或可能走向错误方向。
第八章:GRPO 训练中的注意事项与实践经验
笔者在查阅资料及与一些社区开发者交流时,收集了一些在使用 GRPO(以及类似方法)时可能需要关注的要点,整理如下,供读者参考:
-
Group Size (G)
过小的 G(如 G=2)可能导致组内对比信号太弱,难以稳定收敛;过大的 G(如 G=16 甚至 32)则会大幅增加推理生成开销。实践中常见在 4~8 之间先试验,根据具体任务难度做调整。 -
KL Coefficient 或 Clipping
为了让新策略不要背离原策略过远,需要一个 KL 正则项,或者用 ratio clipping。过高的 KL 惩罚会导致训练停滞,更新幅度微弱;过低则会冒险跑偏。要根据日志中的 KL 值进行监控,一般不会让 KL 在一个 batch 内飙升太猛。 -
max token 的设置
生成回答时要限制一定的 token 长度(比如 256 或 512),否则开销会爆炸式增长;同时,对于多步推理问题,也不能太短,否则回答不完整。 -
奖励函数的准确性与鲁棒性
如果奖励函数(或奖励模型)对小的字符串差异很敏感,会导致训练出现奇怪的偏差。有必要在上线前对奖励函数做充分测试和验证。 -
Mixed Precision / BF16 / FP16
在大模型训练中,使用混合精度可以大幅减少显存,但要注意某些操作可能不支持 bf16/fp16,需要相应地设置 ensure FP32 layers 等。 -
学习率及优化器
一般需要比预训练或 SFT 阶段略小的学习率,还要结合 warmup 步骤或者自适应调度器。若不仔细调参,容易出现发散或学习停滞的情况。 -
日志监控
要密切关注reward_mean、reward_std、kl、loss、completion_length等指标。若看到kl不断飙升或reward_mean升到很高再剧烈波动,可能就需要调参。
第九章:更进一步:大规模多阶段训练
回到 DeepSeek-R1 / Open R1 的宏观视角,GRPO 只是其中一个重要模块,要想真正复现他们的高性能大模型,往往要经历多轮多阶段训练,例如:
-
阶段1:SFT 冷启动
准备一批有推理痕迹或对话格式的数据,比如 1 万或 10 万条优质示例,让模型先学会基本的解题方法、对话风格。 -
阶段2:纯RL训练
在大规模数学、编程、推理数据上做 GRPO / PPO / DPO / RFT 等多候选强化学习,引导模型深度打磨推理能力。这一阶段的挑战在于需要训练时间长、硬件要求高,以及奖励模型评估是否准确。 -
阶段3:拒绝采样 + 监督微调
用拒绝采样保留优质回答,再进行一次 SFT,把模型回答风格拉回更贴近人类喜欢的形式,减少胡言乱语或过度啰嗦。 -
阶段4:通用场景RL
为了让模型能适应更广泛领域,需要更多不同任务的数据,可能包括自然对话、情感分析、编程调试、写作等等,再一次强化训练,对齐全方位的需求。
在这个过程中,每个阶段可能会轮番使用 SFT 或 GRPO,或搭配分布式训练、数据扩充,以及不时地更新奖励模型 RM 等复杂操作。Open R1 就希望把 DeepSeek-R1 在内部做的所有步骤公开化和可复现化,让全世界开发者都能把它当成一个范本或基线,进而改进属于自己的“R1”。
第十章:结语与展望
从原理到实践,从 SFT 到 GRPO,从 Open R1 的项目结构到更深层的多阶段训练思路,笔者在本文中做了非常系统、详尽的阐述。尤其是对 GRPO 训练方法的详细讲解,目的是让读者能够真正理解其相对于 PPO 的改进之处,以及如何在实际项目中落地实施。
Open R1 并非一蹴而就;它的野心是让任何人都能在高质量开源管线上进行大模型的二次开发,不再被大厂闭源系统所限制。如果大家在实践中遇到各种问题,如训练不收敛、奖励模型失效、部署卡住等,也不要气馁,因为大模型强化学习确实还处于一个相对前沿但不够成熟的阶段,需要大量的调试和迭代。
笔者相信,随着社区对 GRPO 等方法的不断使用与优化,我们将看到更加轻量高效的 RL 对齐方式,也会看到更多类似“Open R1”的大型开源再现项目。或许未来我们会在各种垂直领域(医疗、金融、编程等)见到带有强大推理能力和人类对齐特性的专用模型——而这些模型,很可能就依赖本文所提及的思路来实现训练:蒸馏、SFT、强化学习,再结合多候选相对比较等手段,最终迭代收敛。
最后,希望此文能够给大家提供一个较完整而连贯的思路,从理解理论到落地实践,从原理公式到具体代码。如果你也计划在自己的项目中试用 GRPO,不妨先参考 Open R1 提供的脚本和案例,尝试跑通小规模 Demo,随后再逐步拓展到大规模环境。让我们一起期待更多开源大模型项目在未来继续成长与革新吧!