【AI Studio】飞桨图像分类零基础训练营 - 03 - 卷积神经网络基础
前言:第三天,老师结合ppt文图详细讲解了线性和卷积网络的构建,由简单到复杂的讲解卷积网络的发展。最后结合几个项目加深理解。愈发感觉老师讲的好了。第二天的课听完后还感觉自己什么都懂了,结果轮到自己动手搭建模型时发现自己的无知,所以今天要把各个知识点详尽列举。
目录
- 【AI Studio】飞桨图像分类零基础训练营 - 03 - 卷积神经网络基础
-
- 深度全连接神经网络模型
-
- 一、建立模型
-
- 1.神经元
- 2.激活函数
- 3.前馈神经网络 / 前向传播过程
- 4.输出层
- 二、损失函数
- 三、参数训练
- 四、模型实战(上)
-
- 1.线性回归
- 2.SoftMAx分类器
- 3.多层感知机模型
- 4.卷积网络LeNet-5
- 卷积神经网络
-
- 一、建立模型
-
- 1.局部连接(卷积conv)
- 2.权重共享
- 3.下采样(池化pooling)
- 4.经典卷积神经网络结构
- 5.卷积核运算
- 6.多通道、多卷积
- 7.Pooling层
- 二、损失函数
- 三、参数学习
- 四、模型实战(下)
-
- 1.卷积网络模型AlexNet
-
- 建模流程
- 代码实现
- 2.卷积卷积网络GoogLeNet
-
- 建模流程
- 代码实现
- 3.残差神经网络ResNet
-
- 建模流程
- 代码实现
- 4.MobileNet V1模型
-
- ①逐通道卷积
- ②逐点卷积
- ③代码实现
- 竞赛实战——蝴蝶识别与分类
-
- 1. 创建项目和挂载数据
- 2.初探蝴蝶数据集
- 3.准备数据
- 4.建立模型
- 5.应用高阶API训练模型
- 6. 应用已经训练好的模型进行预测
———————————————
【AI Studio】飞桨图像分类零基础训练营 - 03 - 卷积神经网络基础
课程文档PPT
https://aistudio.baidu.com/aistudio/education/preview/1106964
深度全连接神经网络模型
一、建立模型
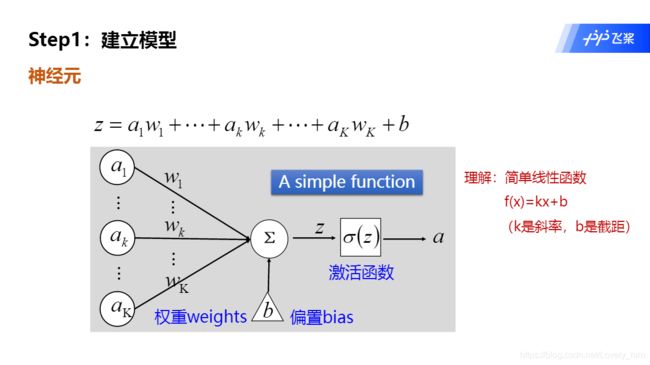
1.神经元
- 单个神经元,由
权重w,偏置b,激活函数σ,还有输入x,输出y组成。 - 然后多个叠加组成一竖(层),就算简单的单层线性网络。
- 目前记住!神经元 = 线性函数 + 激活函数。也就是说,线性函数后一定要接激活函数。
注意:paddle1版本,relu激活函数是合并在线性层里面一起写的,不需要独立出来加。但在paddle2.0版本中,线性层和激活函数层是分开的,你用完线性层,激活函数必须加后面。
2.激活函数
- 图中的
将“线性函数”转变为“非线性函数”,个人的理解/换个说话,意思就是:如果没有激活函数纯神经元组成的线性网络,无论多少层都可以拍扁为一层。意思就是达不到多层的目的。 这一点还是蛮好理解的,因为一个神经元就是线性函数,如果全都用这种线性函数组成,那整个模型就能通过化简运算变为单层,达不到多层的效果。 - 下图举出常用的激活函数,记住公式表达,和计算

3.前馈神经网络 / 前向传播过程
- 下图是一个多层网络的例子,如果没有算过的可以带入数值感受一下,多层线性网络的计算过程。箭头线上的是w,三角形内的是b,粉红圈代表输入。绿圈代表神经元,圈内图标代表激活函数是TanH,矩形内的数字是得数。

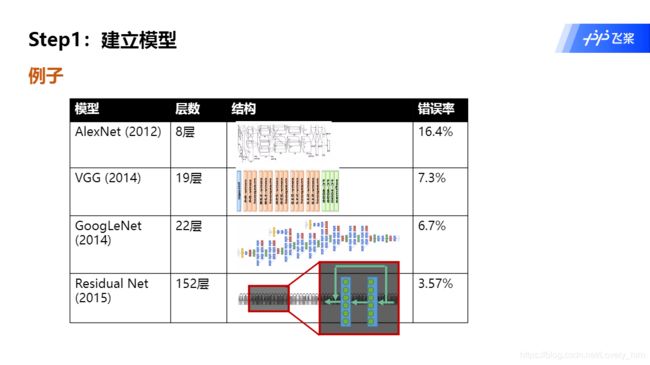
题外话:一览经典模型的结构图,看多后养成概念:模型其实就是就是一堆层的操作的叠加。背后的功能也都是抽象性的。而且现在的层数也是越来越多了。有了概念后,看入门不会那么懵逼。
4.输出层
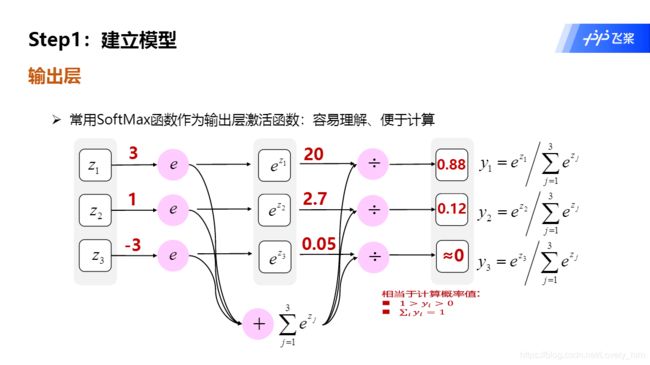
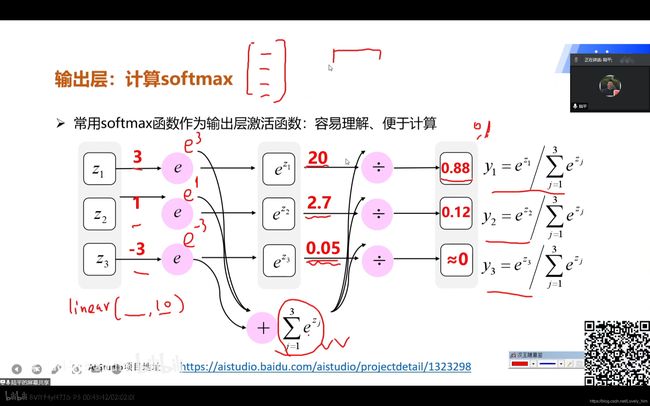
- 第1点中提到,线性函数后要接激活函数,那输出层的激活函数怎么选择,就是一个主要操作了。在图像分类中
SoftMax激活函数常被用到,经过运算后输出值范围为(0,1),相当于概率值。用于分类很合适,在第二课中也有项目例子,可以查看。 - 值得注意的是,在Paddle中,单独实现
SoftMax激活函数的方法是paddle.nn.functional.softmax,而还有一个paddle.nn.CrossEntropyLoss()方法是交叉熵损失函数和SoftMax激活函数组合而成的SoftMax分类器。 - 所以如果这2个方法同时使用的话,就相当于对输出层使用了2次
SoftMax激活函数……这就有点奇怪了,因为用分类器,我开预测值范围并不是(0,1)。这是一个疑惑的问题,日后如果明白了回来补上。 - 助教告诉我原因了,预测的时候不会进过损失函数的,所以预测的时候要加
SoftMax激活函数,才能使预测值像概率。但另一个问题是我现在哈不知道训练时不加,预测时加这种分开的操作……
二、损失函数
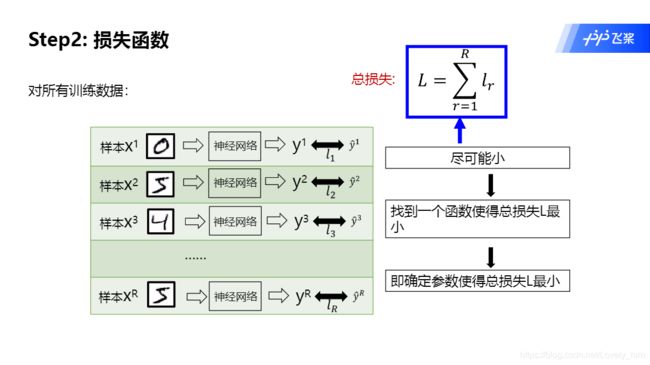
在老师的定义归类中,模型只有前面那堆神经元组成正向传播过程。而后续的反向传播过程是另外单独的。这样归类也很合理,因为模型在用的时候也只有前向传播的过程,而反向传播的过程是在优化模型和设计模型中起作用。
输入x经过神经网络得到输出y',然后与真实值y经过损失函数,得到损失值l,全部加和得到总损失L。- 训练模型的目标就是
输出y'接近真实值y,即损失值l尽可能小。 - 而损失函数也有很多可以选择,常用的就是交叉熵损失函数(第二课笔记有讲解)、平方损失函数。
三、参数训练
- 损失函数的图像可以简单表示为如下,横坐标就是
神经网络参数。通过改变网络参数,损失值会不断改变。而我们每次改变的步长与学习率n有关,而移动的方向,就与由损失值计算的梯度有关。 - 训练的过程,因为损失函数的图像是无法预知的,那我们设定的
初始值和步长就很重要,决定了训练的速度。 - 而训练的结果,因为图像无法预知,所以其实找到的往往是
局部最小值,而不是全局最小值。而且,因为步长而错过最小值也有可能。 - 所以神经网络,把模型搭起来还不够,还要会调参。
调参数,又是另一门学问了,第四课笔记再详解。涉及:
超参数,等概念。还有调参参考的指标。

四、模型实战(上)
【学习目录】基于PaddlePaddle2.0-构建机器学习、深度学习模型
https://aistudio.baidu.com/aistudio/projectdetail/1354419
这一部分的4个模型是昨天讲的,这里再快速过一遍。其中模型构建如代码所示,除了线性回归,其余代码都使用了
paddle.nn.CrossEntropyLoss()。即在模型的最后输出层都有一个SoftMax激活函数。
- Paddle飞桨搭建网络模型方法可分为两类,一种是用类打包,先定义层再叠加搭建(下面的模型3、4就是这种方法)。另一种就是一步到位使用方法直接打包各层(下面的模型2就是这种方法)。
- 入门建议使用前者,思路清晰代码好看。熟练后可以使用后者。如果模型的大的话,往往会两者组合使用,后者嵌套在前者里面。
1.线性回归
基于PaddlePaddle2.0-构建线性回归模型
https://aistudio.baidu.com/aistudio/projectdetail/1322247
# 构建模型。
model=paddle.nn.Linear(in_features=2, out_features=1)

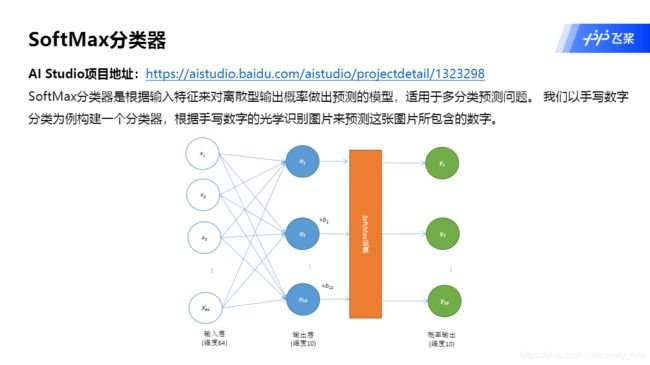
2.SoftMAx分类器
基于PaddlePaddle2.0-构建SoftMax分类器
https://aistudio.baidu.com/aistudio/projectdetail/1323298
# 构建模型。
linear=paddle.nn.Sequential(
paddle.nn.Flatten(),#将[1,28,28]形状的图片数据改变形状为[1,784]
paddle.nn.Linear(784,10)
)
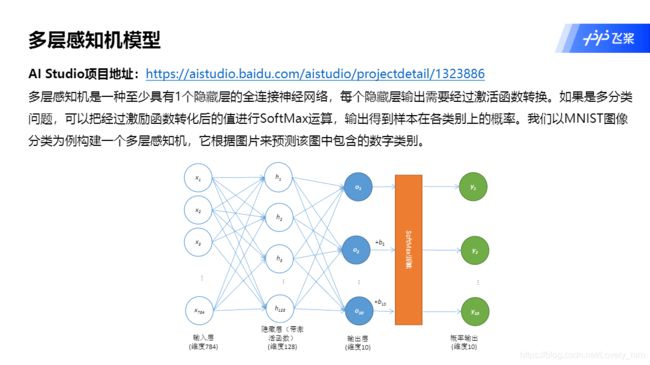
3.多层感知机模型
基于PaddlePaddle2.0-构建多层感知机模型
https://aistudio.baidu.com/aistudio/projectdetail/1323886
# 构建模型。
def forward(self, x):
x=self.flatten(x)
x=self.hidden(x) #经过隐藏层
x=F.relu(x) #经过激活层
x=self.output(x)
return x
4.卷积网络LeNet-5
基于PaddlePaddle2.0-构建卷积网络模型LeNet-5
https://aistudio.baidu.com/aistudio/projectdetail/1329509
# 构建模型,正向传播过程
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
out = self.fc3(x)
return out

卷积神经网络
深度全连接神经网络模型的缺点
- ①,模型结构不够灵活:只能增加神经元个数和网络层数,不多样。
- ②,模型参数太多:全连接网络中,一个神经元都对前一层每个神经元数有单独的参数。如果层数一多且神经元个数一多,参数就成次方增长。
一、建立模型
1.局部连接(卷积conv)
- 对于图像来说,一般像素都很高,如果是全连接,就需要把每个像素点都作为输入传入。那参数就过多了。而局部连接就可以大大减少参数量。
- 而局部连接的可行是出于:图像识别中讲究的是特征识别。会把图像的各个特征提取识别。(个人理解)

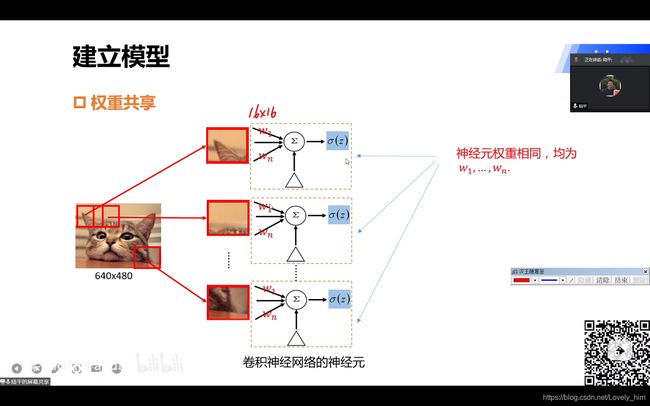
2.权重共享
- 卷积操作是一个卷积核滑动计算下一幅图像的输出,这样一层中的参数就只有卷积核内的几个参数了,对比全连接网络来说参数大大减少。
- 如果我们把每个滑动的区域都单一个神经元,该区域的局部图像做输入,卷积操作后做输出。然后所有神经元排列一起当做一层,就可以把卷积理解为所有神经元的参数都相等,共享一份参数。
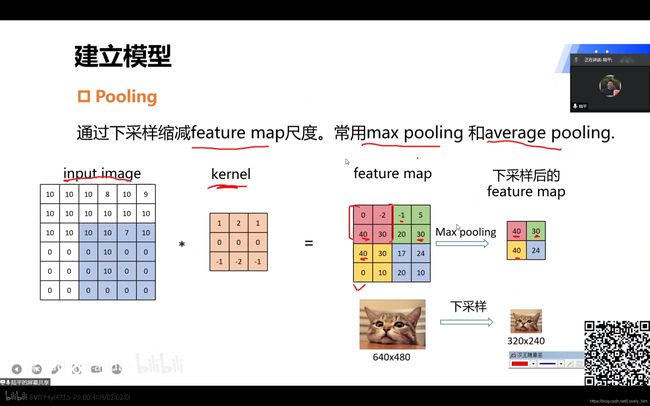
3.下采样(池化pooling)
- 下采样说通俗点,直接效果就是把图像缩小了。在代码中实现时,对应的网络层称为
池化层。 - 其作用含义是“ 缩小后的图像中,一个像素点的信息融合了,缩小前几个像素点的信息 ” —— 即扩大感受野。(个人理解)

4.经典卷积神经网络结构
- 卷积网络的特点(个人认为),
卷积conv+池化pooling叠加,然后输出层为全连接+Soft-max输出预测概率。 - 中间部分可以类比全连接网络的
神经元+激活函数,结合记忆。 (记住那些专业术语的单词,不然听不懂老师讲课)

5.卷积核运算
- 卷积核内的运算就是一一对应乘积然后加和,手算验证一下即可。人算很麻烦,在代码实现时会利用python的广播机制,使用矩阵操作进行计算(线性代数学的不好可能会晕)。
矩阵加法运算
https://aistudio.baidu.com/aistudio/projectdetail/1616566
- 飞桨框架替我们解决了计算问题,我们只需要考虑输入图像大小和输出图像大小即可。而输出图像的大小与输入图像的大小和卷积核有关,具体计算参考一下公式。

卷积层 - 扩展理解
- 如果把输入输出图像拍扁,然后把卷积核用神经元“全连接”的形式展现,会得到下图。
- 神经元是局部连接的,且权重共享。可以结合理解卷积和神经元。
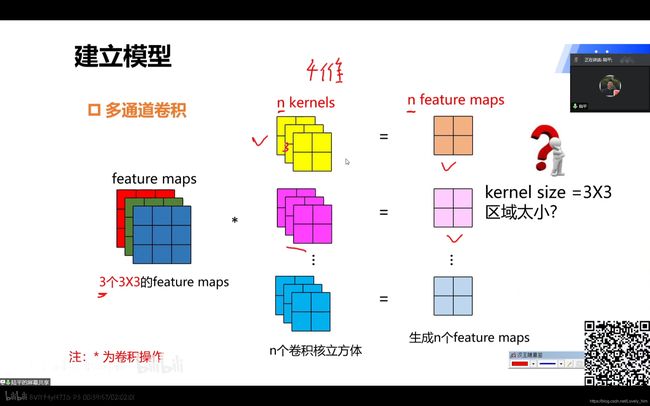
6.多通道、多卷积
- 单个卷积只能提取单
特征feature,所以一幅图像会采用多个卷积核kernel提取特征。同时会输出多个特征图feature maps,一个卷积核对应一个。 - 另外,如果上一个卷积层有多个卷积核得到多个
特征图feature maps,那这一层的一个卷积核kernel就会自动广播(此时卷积核通常表示为一个立方体)然后和多个特征图feature maps运算得到一个特征图feature map。(下图就是这个操作!!!)

- 然后,如果这一层多个不同的
卷积核kernels,就会又生成多个特征图feature maps到下一层,继续套娃。(下图就是这个操作!!!)
7.Pooling层
- 老师说,把
Pooling层理解为下采样也是可以的。(言外之意是不是指并不完全相等?先留个坑,自己知道并警惕一下。) Pooling层运算也有很多种,常用的有取最大值max pooling和取平均值average pooling。其作用就是增大感受野。- (如果上采样就是放大图片,用的就是
插值方法)
二、损失函数
- 因为
Softamx分类器是全连接层+Softmax激活函数+交叉熵损失函数的组合,所以飞桨2.0把后两者组合在一起使用。通过方法paddle.nn.CrossEntropyLoss()调用。
小知识:交叉熵瞬损失函数的公式,的后半段
ln(y)是指信息量,在第二课中有详细介绍,不记得的可返回查看。
三、参数学习
- 训练模型的过程:损失函数和参数学习,这两过程和全连接神经网络差不多。结合记忆,简单过一下。

四、模型实战(下)
- 本节课的重头戏,集合代码讲。2节课的项目都集合在一下连接中,自取。
【学习目录】基于PaddlePaddle2.0-构建机器学习、深度学习模型
https://aistudio.baidu.com/aistudio/projectdetail/1354419
1.卷积网络模型AlexNet
基于PaddlePaddle2.0-构建卷积网络模型AlexNet
https://aistudio.baidu.com/aistudio/projectdetail/1332790
建模流程
- AlexNet模型由Alex Krizhevsky、Ilya Sutskever和Geoffrey E. Hinton开发,是2012年ImageNet挑战赛冠军模型。相比于LeNet模型,AlexNet的神经网络层数更多,其中包含ReLU激活层,并且在全连接层引入Dropout机制防止过拟合。下面详细解析AlexNet模型。

- 原模型是双路线的,因为作者是采用双GPU。这里只是实现大概流程,只采用一半,即单路线。足矣应付简单的学习任务。
- 根据老师的描述,相比于LeNet模型,AlexNet的神经网络层数更多,其中包含ReLU激活层,并且在全连接层引入Dropout机制防止过拟合。 我的理解就是一个升级版,更多层更多卷积。
代码实现
#构建模型
class AlexNetModel(paddle.nn.Layer):
def __init__(self):
super(AlexNetModel, self).__init__()
self.conv_pool1 = paddle.nn.Sequential( #输入大小m*3*227*227
paddle.nn.Conv2D(3,96,11,4,0), #L1, 输出大小m*96*55*55
paddle.nn.ReLU(), #L2, 输出大小m*55*55*96
paddle.nn.MaxPool2D(kernel_size=3, stride=2)) #L3, 输出大小m*96*27*27
self.conv_pool2 = paddle.nn.Sequential(
paddle.nn.Conv2D(96, 256, 5, 1, 2), #L4, 输出大小m*256*27*27
paddle.nn.ReLU(), #L5, 输出大小m*256*27*27
paddle.nn.MaxPool2D(3, 2)) #L6, 输出大小m*256*13*13
self.conv_pool3 = paddle.nn.Sequential(
paddle.nn.Conv2D(256, 384, 3, 1, 1),#L7, 输出大小m*384*13*13
paddle.nn.ReLU()) #L8, 输出m*384*13*13
self.conv_pool4 = paddle.nn.Sequential(
paddle.nn.Conv2D(384, 384, 3, 1, 1),#L9, 输出大小m*384*13*13
paddle.nn.ReLU()) #L10, 输出大小m*384*13*13
self.conv_pool5 = paddle.nn.Sequential(
paddle.nn.Conv2D(384, 256, 3, 1, 1),#L11, 输出大小m*256*13*13
paddle.nn.ReLU(), #L12, 输出大小m*256*13*13
paddle.nn.MaxPool2D(3, 2)) #L13, 输出大小m*256*6*6
self.full_conn = paddle.nn.Sequential(
paddle.nn.Linear(256*6*6, 4096), #L14, 输出大小m*4096
paddle.nn.ReLU(), #L15, 输出大小m*4096
paddle.nn.Dropout(0.5), #L16, 输出大小m*4096
paddle.nn.Linear(4096, 4096), #L17, 输出大小m*4096
paddle.nn.ReLU(), #L18, 输出大小m*4096
paddle.nn.Dropout(0.5), #L19, 输出大小m*4096
paddle.nn.Linear(4096, 10)) #L20, 输出大小m*10
self.flatten=paddle.nn.Flatten()
def forward(self, x): #前向传播
x = self.conv_pool1(x)
x = self.conv_pool2(x)
x = self.conv_pool3(x)
x = self.conv_pool4(x)
x = self.conv_pool5(x)
x = self.flatten(x)
x = self.full_conn(x)
return x
- 以上是模型搭建过程,值得注意,模型搭建是采用了两种推荐方法(前文提到的),即使用
paddle.nn.Sequential打包,也使用forward排布。这也算一种技巧,很好利用,当层数太多时,这样确实不错。
import paddle
import paddle.nn.functional as F
import numpy as np
from paddle.vision.transforms import Compose, Resize, Transpose, Normalize
#准备数据
t = Compose([Resize(size=227),Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'),Transpose()]) #数据转换
cifar10_train = paddle.vision.datasets.cifar.Cifar10(mode='train', transform=t, backend='cv2')
cifar10_test = paddle.vision.datasets.cifar.Cifar10(mode="test", transform=t, backend='cv2')
epoch_num = 20
batch_size = 256
learning_rate = 0.0001
val_acc_history = []
val_loss_history = []
def train(model):
#启动训练模式
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters())
train_loader = paddle.io.DataLoader(cifar10_train, shuffle=True, batch_size=batch_size)
valid_loader = paddle.io.DataLoader(cifar10_test, batch_size=batch_size)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data = paddle.cast(data[0], 'float32')
y_data = paddle.cast(data[1], 'int64')
y_data = paddle.reshape(y_data, (-1, 1))
y_predict = model(x_data)
loss = F.cross_entropy(y_predict, y_data)
loss.backward()
opt.step()
opt.clear_grad()
print("训练轮次: {}; 损失: {}".format(epoch, loss.numpy()))
#每训练完1个epoch, 用测试数据集来验证一下模型
#切换到训练模式
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data = paddle.cast(data[0], 'float32')
y_data = paddle.cast(data[1], 'int64')
y_data = paddle.reshape(y_data, (-1, 1))
y_predict = model(x_data)
loss = F.cross_entropy(y_predict, y_data)
acc = paddle.metric.accuracy(y_predict, y_data)
accuracies.append(np.mean(acc.numpy()))
losses.append(np.mean(loss.numpy()))
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("评估准确度为:{};损失为:{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
#重新又启动训练模式
model.train()
model = AlexNetModel()
train(model)
- 在高阶应用中,会把训练和评估部分都打包在一个函数内调用。学习一下。之后几个模型就不全列代码了。
2.卷积卷积网络GoogLeNet
基于PaddlePaddle2.0-构建卷积网络GoogLeNet
https://aistudio.baidu.com/aistudio/projectdetail/1340883
建模流程
(1)GoogLeNet模型串联结构:
GoogLeNet模型结构由多个模块串联而成。其中Inception层内部为并联结构。
(2)GoogLeNet模型Inception内部结构:GoogLeNet模型的每个Inception模块包括4条并联路径。


- 这一个模型引入了一个新操作,除了叠加式的串联网络,还可以并行式的并联网络。之后学习其他的模型时,会学到越来越多奇奇怪怪的路径。背后都有一个抽象含义,而这条路径的可行和其含义的正确,就源于发明者花大量时间去训练得出的经验结论。
- 该模型的并联操作是拼接操作,相当于把4条路径的图像全部组合在一起,也不运算。形象表示就相当于把第二维的特征图数量相加,组成一个立方体。(第一维是通道数,第二维是特征图数,第三四维才是图像长宽)
- 另一个新操作就是大小为1的卷积核,这里老师(的理解)解释,它的作用是做个加权操作。因为卷积大小1就相当于全部数都乘于一个数再输出大小一样的图像。
代码实现
- 并联操作如下,注意
forward中还有套娃使用的方法,学习一下。 - 注意最好返回的不算x,而是利用
paddle.concat返回。这个做法是因为等一会这个模型还要再套娃一次……
#构建模型
class Inception(paddle.nn.Layer):
def __init__(self, in_channels, c1, c2, c3, c4):
super(Inception, self).__init__()
#路线1,卷积核1x1
self.route1x1_1 = paddle.nn.Conv2D(in_channels, c1, kernel_size=1)
#路线2,卷积层1x1、卷积层3x3
self.route1x1_2 = paddle.nn.Conv2D(in_channels, c2[0], kernel_size=1)
self.route3x3_2 = paddle.nn.Conv2D(c2[0], c2[1], kernel_size=3, padding=1)
#路线3,卷积层1x1、卷积层5x5
self.route1x1_3 = paddle.nn.Conv2D(in_channels, c3[0], kernel_size=1)
self.route5x5_3 = paddle.nn.Conv2D(c3[0], c3[1], kernel_size=5, padding=2)
#路线4,池化层3x3、卷积层1x1
self.route3x3_4 = paddle.nn.MaxPool2D(kernel_size=3, stride=1, padding=1)
self.route1x1_4 = paddle.nn.Conv2D(in_channels, c4, kernel_size=1)
def forward(self, x):
route1 = F.relu(self.route1x1_1(x))
route2 = F.relu(self.route3x3_2(F.relu(self.route1x1_2(x))))
route3 = F.relu(self.route5x5_3(F.relu(self.route1x1_3(x))))
route4 = F.relu(self.route1x1_4(self.route3x3_4(x)))
out = [route1, route2, route3, route4]
return paddle.concat(out, axis=1) #在通道维度(axis=1)上进行连接
- 下面是实现串联结构的部分,居然把上面定义的模型嵌套在下面了,原来还能这么用。学习一下。(无限套娃)
class GoogLeNet(paddle.nn.Layer):
def __init__(self, in_channel, num_classes):
super(GoogLeNet, self).__init__()
self.b1 = paddle.nn.Sequential(
BasicConv2d(in_channel, out_channels=64, kernel=7, stride=2, padding=3),
paddle.nn.MaxPool2D(3, 2))
self.b2 = paddle.nn.Sequential(
BasicConv2d(64, 64, kernel=1),
BasicConv2d(64, 192, kernel=3, padding=1),
paddle.nn.MaxPool2D(3, 2))
self.b3 = paddle.nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
paddle.nn.MaxPool2D(3, 2))
self.b4 = paddle.nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
paddle.nn.MaxPool2D(3, 2))
self.b5 = paddle.nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (182, 384), (48, 128), 128),
paddle.nn.AvgPool2D(2))
self.flatten=paddle.nn.Flatten()
self.b6 = paddle.nn.Linear(1024, num_classes)
def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.flatten(x)
x = self.b6(x)
return x
- 之后的训练过程打包函数就是复用上一个例子的,差不多一样,不再陈列。
3.残差神经网络ResNet
基于PaddlePaddle2.0-构建残差神经网络模型
https://aistudio.baidu.com/aistudio/projectdetail/1342659
建模流程
残差网络(ResNet)模型是由何凯明开发,它是2015年ImageNet ILSVRC-2015分类挑战赛的冠军模型。ResNet模型引入残差模块,它能够有效地消除由于模型层数增加而导致的梯度弥散或梯度爆炸问题。下面详细解析ResNet模型原理。

- 该模型又引入了一种新概念,它的路径更加曲折了……我不过多讲理解了,因为我也没理解,先拿来用。用多用熟后再解析。
代码实现
- 以下是核心模块:残差部分的代码实现
#构建模型
class Residual(paddle.nn.Layer):
def __init__(self, in_channel, out_channel, use_conv1x1=False, stride=1):
super(Residual, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channel, out_channel, kernel_size=3, padding=1, stride=stride)
self.conv2 = paddle.nn.Conv2D(out_channel, out_channel, kernel_size=3, padding=1)
if use_conv1x1: #使用1x1卷积核
self.conv3 = paddle.nn.Conv2D(in_channel, out_channel, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.batchNorm1 = paddle.nn.BatchNorm2D(out_channel)
self.batchNorm2 = paddle.nn.BatchNorm2D(out_channel)
def forward(self, x):
y = F.relu(self.batchNorm1(self.conv1(x)))
y = self.batchNorm2(self.conv2(y))
if self.conv3:
x = self.conv3(x)
out = F.relu(y+x) #核心代码
return out
- 然后以下是另外两部分的代码,其他代码(模型训练和数据处理)部分省略。
def ResNetBlock(in_channel, out_channel, num_layers, is_first=False):
if is_first:
assert in_channel == out_channel
block_list = []
for i in range(num_layers):
if i == 0 and not is_first:
block_list.append(Residual(in_channel, out_channel, use_conv1x1=True, stride=2))
else:
block_list.append(Residual(out_channel, out_channel))
resNetBlock = paddle.nn.Sequential(*block_list) #用*号可以把list列表展开为元素
return resNetBlock
class ResNetModel(paddle.nn.Layer):
def __init__(self):
super(ResNetModel, self).__init__()
self.b1 = paddle.nn.Sequential(
paddle.nn.Conv2D(3, 64, kernel_size=7, stride=2, padding=3),
paddle.nn.BatchNorm2D(64),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(kernel_size=3, stride=2, padding=1))
self.b2 = ResNetBlock(64, 64, 2, is_first=True)
self.b3 = ResNetBlock(64, 128, 2)
self.b4 = ResNetBlock(128, 256, 2)
self.b5 = ResNetBlock(256, 512, 2)
self.AvgPool = paddle.nn.AvgPool2D(2)
self.flatten = paddle.nn.Flatten()
self.Linear = paddle.nn.Linear(512, 10)
def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.AvgPool(x)
x = self.flatten(x)
x = self.Linear(x)
return x
4.MobileNet V1模型
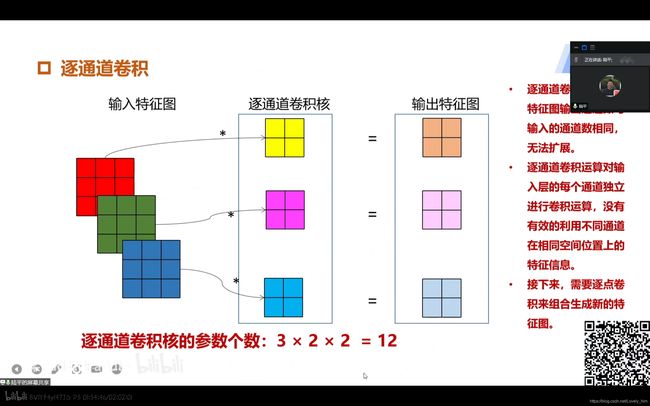
我已经不会分目录级别了……这一课好多内容- 深度可分离卷积结构:通过化简后可知特点,当通道数很大时,参数会比较少。其优点就是可以搭载在嵌入式中运行,比如树莓派之类的。
①逐通道卷积
- 和标准卷积不一样,计算方法如下图。相当于增加了卷积次数,不再把上一层的多通道特征图合在一起卷积了,而是都单独卷积。不改变输出通道数量。
②逐点卷积
- 和标准卷积类似,也类似
ResNet中的1x1卷积类似。逐通道卷积不改变通道数,所以要通过逐点卷积修改通道数。(好像通道数变得更加多了) 讲解内容都在ppt的文字中,我怕曲解意思就不多描述了。我自己也不算很理解。- 这里的卷积运算会将上一步的特征图在深度方向上进行加权组合,生成新的特征图。
③代码实现
- 在飞桨中,可以利用
paddle.nn.Conv2d方法实现,具体看飞桨文档吧。改一下参数就可以了。
竞赛实战——蝴蝶识别与分类
基于PaddlePaddle2.0的蝴蝶图像识别分类——利用预训练残差网络ResNet101模型
https://aistudio.baidu.com/aistudio/projectdetail/1417071

1. 创建项目和挂载数据
- 在AI Studio中创建项目时可以选择网站上已公布上传的数据集加载。不懂操作的查查图文教程。
AIStudio 各类操作详解
https://blog.csdn.net/weixin_41450123/category_10707833.html
2.初探蝴蝶数据集
- 首先解压数据,因为数据集下载后是压缩包的形式,在
notebook上和本地(因操作系统不同)操作不太一样。各自相应百度即可。 - 一般数据集的文件格式为如下(略),每个子文件夹都是一个类别(也就是标签),其中的图片就是数据。
- 然后训练集和验证集在一起,需要自己手动划分,测试集单独,且不知道标签,作为衡量的指标。
3.准备数据
- 一般下载下来的数据集不能直接丢到框架里训练,要先处理成框架能用的数据。
数据准备过程包括以下两个重点步骤:
- 一、是建立样本数据读取路径与样本标签之间的关系。
- 二、是构造读取器与数据预处理。可以写个自定义数据读取器,它继承于PaddlePaddle2.0的
dataset类,在__getitem__方法中把自定义的预处理方法加载进去。
- 第一步,建立读取路径和样本标签的关系,在Python基础课中已经讲过了。就是打开
.txt文件读取字符串,然后拼接。
# 代码略,有点乱,具体去项目里看吧。
- 第二步,转换数据,在那之前先定义一个处理数据的函数。用于数据增强。
#自定义的数据预处理函数,输入原始图像,输出处理后的图像,可以借用paddle.vision.transforms的数据处理功能
def preprocess(img):
# 一个可调用的Compose对象,它将依次调用每个给定的 transforms。
transform = Compose([
# 数据增强
# tf.RandomHorizontalFlip(), # 基于概率来执行图片的水平翻转。
tf.RandomVerticalFlip(), # 基于概率来执行图片的垂直翻转。
#tf.ColorJitter(0.1,0.1,0.1,0.1),#随机调整图像的亮度,对比度,饱和度和色调。
# 将输入数据调整为指定大小。
Resize(size=(224, 224)), #把数据长宽像素调成224*224
# 图像归一化处理,支持两种方式: 1. 用统一的均值和标准差值对图像的每个通道进行归一化处理;
# 2. 对每个通道指定不同的均值和标准差值进行归一化处理。 255/2 = 127.5
Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'), #标准化
# 将输入的图像数据更改为目标格式。例如,大多数数据预处理是使用HWC格式的图片,而神经网络可能使用CHW模式输入张量。 输出的图片是numpy.ndarray的实例。
Transpose(), #原始数据形状维度是HWC格式,经过Transpose,转换为CHW格式
])
# 把图像传进入然后经过上面的处理顺序再返回。
img = transform(img).astype("float32")
return img
- 然后在定义转换数据的类,要用到Paddle中的
Dataset类,使用方法有点像搭建模式时继承paddle.nn.Layer一样。类比记忆。
#自定义数据读取器
# 重点,Dataset类是paddle用力打包数据的
# 这个类的继承和建立模型的paddle.nn.Layer 的使用方法大同小异,也是有几个必须要写的函数,一个是__getitem__,一个是__len__
class Reader(Dataset):
def __init__(self, data, is_val=False): # is_val 参数是用来划分训练集和验证集的。前80%还是后20%。
super().__init__()
#在初始化阶段,把数据集划分训练集和测试集。由于在读取前样本已经被打乱顺序,取20%的样本作为测试集,80%的样本作为训练集。
self.samples = data[-int(len(data)*0.2):] if is_val else data[:-int(len(data)*0.2)]
print(data[0])
# is_val 作用在于是从前面取还是从后面取,都已经打乱了,应该都没关系了吧。
def __getitem__(self, idx):
#处理图像
img_path = self.samples[idx][0] #得到某样本的路径
# 使用PIL模块读取图片,而不是cv2
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
# 之后自己写 数据增强。
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
#处理标签
label = self.samples[idx][1] #得到某样本的标签
label = np.array([label], dtype="int64") #把标签数据类型转成int64
return img, label
def __len__(self):
#返回每个Epoch中图片数量
return len(self.samples)
- 上面的类是针对训练集和验证集的,因为它们都有标签。而没有标签的预测集还要另外写一个类读取。
- 而且测试集不需要训练,也就不需要做数据处理直接读取就可以了。
# 读取数据
class InferDataset(Dataset):
def __init__(self, img_path=None):
"""
数据读取Reader(推理)
:param img_path: 推理单张图片
"""
super().__init__()
if img_path:
self.img_paths = [img_path]
else:
raise Exception("请指定需要预测对应图片路径")
def __getitem__(self, index):
# 获取图像路径
img_path = self.img_paths[index]
# 使用Pillow来读取图像数据并转成Numpy格式
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
return img
def __len__(self):
return len(self.img_paths)
- 最后,调用类方法,对所有数据进行打包。
4.建立模型
- 老师建议,入门跑深度学习,最好先用历史上已有的,比较成功的模型来用。自己调调参数,感受一下先。
1.为了提升探索速度,建议首先选用比较成熟的基础模型,看看基础模型所能够达到的准确度。之后再试试模型融合,准确度是否有提升。最后可以试试自己独创模型。
2.为简便,这里直接采用101层的残差网络ResNet,并且采用预训练模式。为什么要采用预训练模型呢?因为通常模型参数采用随机初始化,而预训练模型参数初始值是一个比较确定的值。这个参数初始值是经历了大量任务训练而得来的,比如用CIFAR图像识别任务来训练模型,得到的参数。虽然蝴蝶识别任务和CIFAR图像识别任务是不同的,但可能存在某些机器视觉上的共性。用预训练模型可能能够较快地得到比较好的准确度。
3.在PaddlePaddle2.0中,使用预训练模型只需要设定模型参数pretained=True。值得注意的是,预训练模型得出的结果类别是1000维度,要用个线性变换,把类别转化为20维度。
#定义模型
class MyNet(paddle.nn.Layer):
def __init__(self):
super(MyNet,self).__init__()
self.resnet=paddle.vision.models.resnet50(pretrained=True)
# Dropout是一种正则化手段,该算子根据给定的丢弃概率 p ,在训练过程中随机将一些神经元输出设置为0,通过阻止神经元节点间的相关性来减少过拟合
self.dropout=paddle.nn.Dropout(p=0.4)
self.fc = paddle.nn.Linear(1000, 20)
#网络的前向计算过程
def forward(self,x):
x=self.resnet(x)
x=self.dropout(x)
x=self.fc(x)
return x
5.应用高阶API训练模型
一、定义输入数据形状大小和数据类型。
二、实例化模型。如果要用高阶API,需要用Paddle.Model()对模型进行封装,如model = paddle.Model(model,inputs=input_define,labels=label_define)。
三、定义优化器。这个使用Adam优化器,学习率设置为0.0001,优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。
四、准备模型。这里用到高阶API,model.prepare()。
五、训练模型。这里用到高阶API,model.fit()。参数意义详见下述代码注释。
高阶API用起来更方便,建议直接上手,趁早习惯。飞桨好多文档的例子都是旧版或是低阶的,感觉好难查例程。Adam优化器的学习率影响确实很重要,不能高,不然会震荡,也不能低,不然就停滞不前,很容易卡在小坑里。
#定义输入
input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img")
label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64", name="label")
#实例化网络对象并定义优化器等训练逻辑
model = MyNet()
model = paddle.Model(model,inputs=input_define,labels=label_define) #用Paddle.Model()对模型进行封装
optimizer = paddle.optimizer.Adam(learning_rate=0.00002, parameters=model.parameters())
#上述优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。
model.prepare(optimizer=optimizer, #指定优化器
loss=paddle.nn.CrossEntropyLoss(), #指定损失函数
metrics=paddle.metric.Accuracy()) #指定评估方法
model.fit(train_data=train_dataset, #训练数据集
eval_data=eval_dataset, #测试数据集
batch_size=64, #一个批次的样本数量
epochs=50, #迭代轮次
save_dir="/home/aistudio/lup", #把模型参数、优化器参数保存至自定义的文件夹
save_freq=10, #设定每隔多少个epoch保存模型参数及优化器参数
log_freq=100 #打印日志的频率
)
6. 应用已经训练好的模型进行预测
如果是要参加建模比赛,通常赛事组织方会提供待预测的数据集,我们需要利用自己构建的模型,来对待预测数据集合中的数据标签进行预测。也就是说,我们其实并不知道到其真实标签是什么,只有比赛的组织方知道真实标签,我们的模型预测结果越接近真实结果,那么分数也就越高。
预测流程分为以下几个步骤:
一、构建数据读取器。因为预测数据集没有标签,该读取器写法和训练数据读取器不一样,建议重新写一个类,继承于Dataset基类。(这一步我归类到处理训练集验证集时一起做了)
二、实例化模型。如果要用高阶API,需要用Paddle.Model()对模型进行封装,如paddle.Model(MyNet(),inputs=input_define),由于是预测模型,所以仅设定输入数据格式就好了。
三、读取刚刚训练好的参数。这个保存在/home/aistudio/work目录之下,如果指定的是final则是最后一轮训练后的结果。可以指定其他轮次的结果,比如model.load(’/home/aistudio/work/30’),这里用到了高阶API,model.load()
四、准备模型。这里用到高阶API,model.prepare()。
五、读取待预测集合中的数据,利用已经训练好的模型进行预测。
六、结果保存。
#实例化推理模型
model = paddle.Model(MyNet(),inputs=input_define)
#读取刚刚训练好的参数
model.load('/home/aistudio/lup/final')
#准备模型
model.prepare()
#利用训练好的模型进行预测
results=[]
# 这是一张一张图片丢进去预测。
for infer_path in infer_list: # infer_list 是每个图像的读取路径
infer_data = InferDataset(infer_path)
result = model.predict(test_data=infer_data)[0] #关键代码,实现预测功能
result = paddle.to_tensor(result)
result = np.argmax(result.numpy()) #获得最大值所在的序号
results.append("{}".format(label_dict2[result])) #查找该序号所对应的标签名字
# 最后把结果保存起来,然后就可以提交了。
with open("work/result.txt", "w") as f:
for r in results:
f.write("{}\n".format(r))
老师说这个模型的测试集准确率会在85%左右,我怎么改(也没改多少)都没稳定超过这个数,一直在这个数之间反复横跳。- 善用建立模型和数据增强,不然训练时间翻几倍。一等就是一小时或几小时。算力卡完全不够用。