【读点论文】EfficientFormer: Vision Transformers at MobileNet Speed,运用纯transformer架构对比卷积模型在终端上部署的推理速度
EfficientFormer: Vision Transformers at MobileNet Speed
Abstract
-
视觉transformer(ViT)在计算机视觉任务中取得了快速的进展,在各种基准上取得了有前景的结果。然而,由于大量的参数和模型设计(如注意力机制),基于维数的模型通常比轻量级卷积网络慢几倍。因此,为实时应用程序部署ViT特别具有挑战性,特别是在资源受限的硬件(如移动设备)上。
-
近年来,人们试图通过网络架构搜索或与MobileNet块混合设计来降低ViT的计算复杂度,但推理速度仍不能令人满意。这就引出了一个重要的问题:transformer的运行速度能和MobileNet一样快,同时获得高性能吗?为了回答这个问题,我们首先回顾了基于虚拟机的模型中使用的网络架构和操作符,并确定了低效的设计。然后我们引入一个尺寸一致的纯变压器(没有MobileNet块)作为设计范例。最后,我们执行延迟驱动的瘦身,以获得一系列最终模型,称为EfficientFormer。
-
大量的实验证明了该算法在移动设备上的性能和速度优势。我们最快的模型,EfficientFormer-L1,在ImageNet-1K上达到了79.2%的top-1准确率,在iPhone 12上只有1.6 ms的推断延迟(使用CoreML编译),其运行速度与MobileNetV2×1.4一样快(1.6 ms, 74.7%的top-1),而我们最大的模型,EfficientFormer-L7,获得了83.3%的准确率,只有7.0 ms的延迟。我们的工作证明,设计合理的transformer可以在保持高性能的同时,在移动设备上达到极低的延迟。
-
代码和模型可以在 snap-research/EfficientFormer: EfficientFormerV2 & EfficientFormer(NeurIPs 2022) (github.com)
-
论文地址:[2206.01191] EfficientFormer: Vision Transformers at MobileNet Speed (arxiv.org)
-
在实际应用中,一个可部署模型的实际推理速度是非常重要的,尤其是像 ViT 这类模型的部署是非常具有挑战的。该工作系统性地分析了 ViT 系列模型的架构和算子,基于分析结果提出了一系列提升推理速度的模型设计准则。最后,作者基于这些设计准则提出了推理速度与性能俱佳的 EfficientFormer 模型。
-
观察一:使用 large kernel 和 stride 的 patch embedding 层在移动设备上会是速度瓶颈。
- 作者发现相比于在 patch embedding layer 使用大卷积核 (k=16)DeiT-Small 或者 PoolFormer-S24,LeViT 中使用小 kernel size 构建的 patch embedding layer 具有更小的延迟。造成这一现象的主要原因是目前主流的端侧设备,无法很好地支持大卷积核的卷积操作。因此,使用多个 3x3 卷积堆叠来构建 patch embedding layer 会使得模型在端侧设备上具备更高的推理效率。
-
观察二:token mixer 中各个操作的特征维度的一致性是非常重要的。
- Reshape 操作过多会影响推理速度。对比 PoolFormer 和 LeViT,前者始终使用 4D tensor,后者在 4D tensor 和 3D tensor 之间来回切换,会带来额外的推理延迟。对比 LeViT 和 DeiT,后者计算量要比前者更大,但由于 DeiT 的 token mixer 中都是 3D tensor,相比 LeViT 并没有显著的速度下降,再一次证明了特征维度的一致性十分重要。因此,在模型中尽量保持维度的一致性,减少 reshape 操作。
-
观察三:CONV-BN 操作相比 LN(GN)-Linear 操作会具有更好的速度-精度平衡。
- MLP 是 Transformer 类模型的重要组成部分,通常其实现为 layer normalization(LN) + Linear 操作。在推理中, LN 或者 GN 需要计算当前数据的统计量,所以会占据带来的延迟。而使用卷积 (CONV)+batch normalization(BN) 的方式实现 MLP,虽然会带来轻微的精度损失,却比 LN-Linear 的延迟更低(推理时 BN 可以被融合进卷积操作中) 。因此,论文推荐使用 CONV-BN 操作来构建 MLP 层。
-
观察四:非线性激活函数的延迟跟硬件和编译器相关的。
- 论文发现在 iPhone 12 上,GeLU 并不会比 ReLU 有明显的推理延迟,但在其他设备上 GeLU 会比 ReLU 显著变慢。因此,非线性激活函数的选择需要根据硬件特点具体处理。
Introduction
-
transformer架构最初是为自然语言处理(NLP)任务设计的,它引入了Multi-Head Self Attention (MHSA)机制,允许网络对长期依赖进行建模,并且易于并行化。在此背景下,vits将注意力机制适应于2D图像,并提出了视觉转换器(Vision Transformer, ViT):将输入图像划分为不重叠的补丁,通过MHSA学习补丁间的表示,不存在归纳偏差。与卷积神经网络(cnn)相比,ViTs在计算机视觉任务上表现出了有希望的结果。在这一成功之后,一些努力通过改进训练策略,引入架构变化,重新设计注意力机制,以及提高各种视觉任务的性能,如分类,分割和检测[End-to-end object detection with transformers,Improved multiscale vision transformers for classification and detection],来探索ViT的潜力。
-
缺点是,transformer模型通常比竞争对手的cnn慢几倍[Towards efficient vision transformer inference: a first study of transformers on mobile devices,Mobilevit]。有许多因素限制了ViT的推断速度,包括大量的参数、相对于令牌长度的二次递增计算复杂度、不可折叠的归一化层以及缺乏编译器级别的优化(例如,CNN的Winograd)。高延迟使得变压器在资源受限的硬件上的实际应用不太可行,例如移动设备和可穿戴设备上的增强或虚拟现实应用。因此,轻量级cnn仍然是实时推理的默认选择。
-
为了缓解transformer的延迟瓶颈,人们提出了许多方法。例如,一些研究考虑用卷积层(CONV)改变线性层来设计新的架构或操作,将自注意与MobileNet块结合,或引入稀疏注意来降低计算成本,而另一些研究则利用网络搜索算法或修剪来提高效率。虽然现有的工作已经改善了计算性能的权衡,但与transformer模型的适用性有关的基本问题仍然没有得到回答:强大的视觉变压器能否以MobileNet的速度运行,并成为边缘应用程序的默认选项?这项工作通过以下贡献提供了对答案的研究:
-
首先,通过延迟分析(第3节)重新审视ViT及其变体的设计原则。在现有工作[Mobilevit]之后,使用iPhone 12作为测试平台,使用公开可用的CoreML作为编译器,因为移动设备被广泛使用,结果可以很容易地复制。
-
其次,基于我们的分析,识别了ViT中低效的设计和操作,并提出了一种新的视觉transformer尺寸一致设计范式
-
第三,从具有新设计范式的超级网络出发,提出了一个简单而有效的延迟驱动瘦身方法,以获得一个新的模型家族,即EfficientFormers。直接优化推理速度,而不是mac或参数数量。
-
-
我们最快的模型,EfficientFormer-L1,在ImageNet-1K分类任务上达到了79.2%的top-1精度,推理时间仅为1.6 ms(平均超过1000次运行),其运行速度与MobileNetV2×1.4一样快,top-1精度提高了4.5%。有希望的结果表明,延迟不再是广泛采用视觉transformer的障碍。我们最大的模型,EfficientFormer-L7,达到83.3%的精度,只有7.0 ms的延迟,远远超过ViT×MobileNet混合设计(MobileViT-XS, 74.8%, 7.2ms)。此外,通过使用EfficientFormer作为图像检测和分割基准测试的骨干,我们观察到卓越的性能。我们对上述问题提供了初步的答案,ViTs可以实现超快的推理速度,同时拥有强大的性能。希望我们的EfficientFormer可以作为一个强有力的基线,并激励后续工作在视觉变压器的边缘部署。
-

-
推理速度与准确性。所有模型都在ImageNet-1K上进行训练,并使用CoreMLTools在iPhone 12上进行测量以获得延迟。与cnn相比,EfficientFormer-L1的运行速度比EfficientNet-B0快40%,准确率提高2.1%。对于最新的MobileViT-XS, EfficientFormer-L7运行速度快0.2毫秒,准确率提高8.5%。
Related Work
-
变形金刚最初被提出来处理NLP任务中的长序列学习。Dosovitskiy等人和Carion等人分别将变压器架构用于分类和检测,并实现了与具有更强训练技术和更大规模数据集的CNN同行的竞争性能。DeiT在蒸馏的帮助下进一步改善了训练管道,消除了大规模预训练的需要。受到transformer模型的竞争性性能和全局接受域的启发,后续工作提出了改进架构,探索CONV网络和ViT之间的关系[Cmt,Coatnet, On the connection between local attention and dynamic depth-wise convolution],并使ViT适应不同的计算机视觉任务。其他研究工作探索了注意力机制的本质,并提出了令牌混合器的有见解的变体,例如局部注意力、空间MLP和池-混合器[Metaformer is actually what you need for vision]。
-
尽管在大多数视觉任务中都取得了成功,但当推理速度成为主要问题时,特别是在资源受限的边缘设备上,基于vitn的模型无法与经过充分研究的轻量级cnn竞争。为了加速ViT,采用了不同的方法引入了许多方法,例如提出新的架构或模块,重新思考自注意和稀疏注意机制,并利用cnn中广泛探索的搜索算法来寻找更小、更快的ViT。最近,LeViT提出了一种CONV -clothing设计来加速视觉转换器。然而,为了执行MHSA,四维特征需要频繁地重塑为平面补丁,这对于边缘资源的计算仍然是昂贵的(下图)。
-
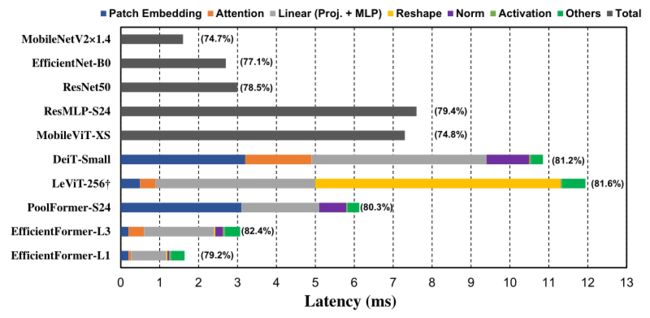
-
延迟分析。使用CoreML在iPhone 12上获得结果。报告了CNN (MobileNetV2×1.4, ResNet50和EfficientNet-B0),基于vit的模型(DeiT-Small, levitt -256, PoolFormer-S24和EfficientFormer)和各种运营商的设备上速度。模型和操作的延迟用不同的颜色表示。(⋅)是ImageNet-1K的前1的准确度。†LeViT使用了CoreML不支持的HardSwish,为了公平比较,我们将其替换为GeLU。
-
-
同样地,MobileViT引入了一种混合架构,结合了轻量级MobileNet块(具有点级和深度级CONV)和MHSA块;前者被放置在网络管道的早期阶段,以提取低级特征,而后者被放置在晚期,以享受全局接受域。一些著作[Mobile-former,NASVit]探索了类似的方法,作为减少计算的直接策略。
-
与现有工作不同,我们的目标是推动纯视觉变压器的延迟性能边界,而不是依赖于混合设计,并直接优化移动延迟。通过我们的详细分析,我们提出了一个新的设计范式,它可以通过架构搜索进一步提升。
视觉transformer的设备上延迟分析
-
现有的大多数方法通过计算复杂度(mac)或从服务器GPU获得的吞吐量(图像/秒)来优化transformer的推理速度。然而这些指标并不能反映真实的设备延迟。为了清楚地了解哪些操作和设计选择减缓了边缘设备上vit的推断,对许多模型和操作进行了全面的延迟分析,如上图所示,从中绘制了以下观察结果。
-
Observation 1:内核和步幅较大的补丁嵌入是移动设备运行速度的瓶颈。
-
Patch嵌入通常采用不重叠的卷积层实现,该卷积层具有较大的内核大小和步幅。一个普遍的观点是变压器网络中贴片嵌入层的计算成本是不显著的或可以忽略的。但是,在上图中对比了DeiT-S和PoolFormer-S24的大内核和大stride的补丁嵌入模型和没有大内核和大stride的模型,即levitt -256和EfficientFormer,可以看出,补丁嵌入在移动设备上反而是一个速度瓶颈。
-
大多数编译器都不支持大内核卷积,并且不能通过Winograd等现有算法进行加速。或者,非重叠的贴片嵌入可以被具有快速下采样的卷积干取代,该卷积干由几个硬件高效的3 × 3卷积组成(下图)。
-
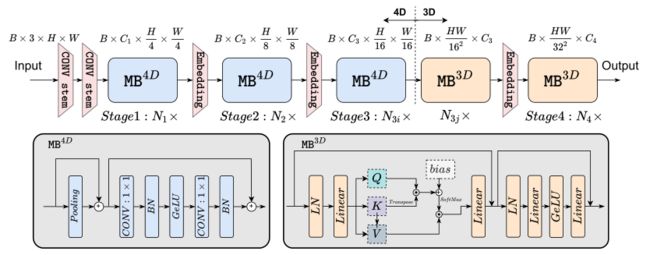
-
概述EfficientFormer。网络从一个卷积干开始作为补丁嵌入,然后是MetaBlock (MB)。MB4D和MB3D包含不同的令牌混合器配置,即本地池化或全局多头自注意,以尺寸一致的方式排列。
-
-
Observation 2:一致性特征维度对于令牌混合器的选择很重要。MHSA不一定是速度瓶颈。
-
最近的工作将基于vi的模型扩展到由MLP块和未指定的令牌混合器组成的MetaFormer架构。在构建基于虚拟机的模型时,选择令牌混合器是必不可少的设计选择。选项有很多——具有全局接受域的传统MHSA混合器,更复杂的转移窗口注意,或者像池化这样的非参数操作符。
-
我们将比较范围缩小到两个令牌混合器,池化和MHSA,我们选择前者是因为它的简单性和效率,而后者是为了更好的性能。更复杂的令牌混合器,如移位窗口,目前不被大多数公共移动编译器支持,我们将它们排除在我们的范围之外。此外,我们没有使用深度卷积来代替池化,因为我们专注于在没有轻量级卷积的帮助下构建体系结构。
-
为了理解两个令牌混合器的延迟,我们执行以下两个比较:
-
首先,通过比较PoolFormer-s24和levite -256,我们观察到重塑操作是levite -256的瓶颈。levitt -256的大部分是在4D张量上使用CONV实现的,由于注意力必须在贴片的3D张量上执行,因此在将特征转发到MHSA时需要频繁的重塑操作(丢弃注意力头的额外维度)。另一方面,当网络主要由基于CONV的实现组成时,池化自然适合4D张量,例如,作为MLP实现的CONV 1 × 1和用于下采样的CONV干。因此,PoolFormer显示出更快的推断速度。
-
其次,通过对比DeiT-Small和levite -256,发现在特征维度一致且不需要重塑的情况下,MHSA不会给手机带来明显的开销。虽然计算量更大,但具有一致3D特征的DeiT-Small可以达到与新的ViT变体(即levite -256)相当的速度。
-
-
在这项工作中,我们提出了一个具有4D特征实现和3D MHSA的维数一致网络,但消除了低效的频繁重塑操作。
-
-
Observation 3:convn - bn比LN (GN)-Linear更有利于延迟,精度的缺点通常是可以接受的。
-
选择MLP实现是另一个重要的设计选择。通常选择两种方案之一:层归一化(LN)与三维线性投影(proj.)和CONV 1 × 1与批量归一化(BN .)。CONV -BN更有利于延迟,因为BN可以折叠到前面的卷积中以加速推理,而动态归一化,如LN和GN,仍然在推理阶段收集运行统计信息,因此有助于延迟。DeiT-Small和PoolFormer-S24以及之前的工作分析,LN引入的时延占全网时延的10% ~ 20%左右。
-
基于我们的消融研究在附录表。与GN相比,CONV -BN仅略微降低了性能,并实现了与信道LN相当的结果。在这项工作中,我们尽可能多地应用CONV BN(在所有潜在的4D特征中)用于延迟增益,性能下降可以忽略不计,同时使用LN用于3D特征,这与ViT中的原始MHSA设计一致,并产生更好的精度。
-
-
Observation 4:非线性的延迟取决于硬件和编译器。
- 最后,我们研究了非线性,包括GeLU, ReLU和HardSwish。之前的工作[Towards efficient vision transformer inference: a first study of transformers on mobile devices]表明,GeLU在硬件上效率不高,并降低了推断速度。然而,我们观察到GeLU在iPhone 12中得到了很好的支持,几乎没有比它的对手ReLU慢。相反,在我们的实验中,HardSwish非常慢,编译器可能不支持(HardSwish的levitt -256延迟为44.5 ms,而GeLU为11.9 ms)。我们得出的结论是,在给定特定硬件和编译器的情况下,非线性应该根据具体情况来确定。我们相信大多数激活在未来都将得到支持。在这项工作中,使用了GeLU激活。
-
作者将上述观察转化为模型设计的指导思想,构建了如上图所示的模型结构。
-
-
在 EfficientFormer 中,使用了 3x3 卷积来构建 patch embedding layer。
-
为了保持每个 block 内的特征维度的一致性,同时有效地利用 attention 机制来提升模型性能,论文先用基于 4D Tensor 的卷积操作(标记为 MB^4D)构建了前 3 个 stage,再使用基于 3D Tensor 的注意力机制模块(标记为 MB^3D)完善和构建了后 2 个 stage。
-
在 MB^4D 中,作者使用了 Pooling 操作来作为 token mixer,同时使用了 CONV-BN 来构建 MLP。
-
在 MB^3D 中,作者使用了 MHSA(multi-head self-attention)作为 token mixer,使用 LN-Linear 的方式构建 MLP。
-
激活函数统一使用了 GeLU 形式。
-
-
Design of EfficientFormer
-
基于延迟分析,本文提出了EfficientFormer的设计,网络由补丁嵌入(PatchEmbed)和元变块堆栈组成,用MB表示:
- γ = ∏ i m M B i ( P a t c h E m b e d ( X 0 B , 3 , H , W ) ) , ( 1 ) \gamma=\prod_{i}^{m}MB_i(PatchEmbed({X_0^{B,3,H,W}})),(1) γ=i∏mMBi(PatchEmbed(X0B,3,H,W)),(1)
- 其中X0为批大小为B,空间大小为[H, W]的输入图像,Y为期望输出,m为总块数(深度)。MB由未指定的令牌混合器(TokenMixer)和一个MLP块组成,可以表示为:
- X i + 1 = M B ( X i ) = M L P ( T o k e n M i x e r ( X i ) ) , ( 2 ) \mathcal{X_{i+1}}=MB(\mathcal{X_i})=MLP(TokenMixer(\mathcal{X_i})),(2) Xi+1=MB(Xi)=MLP(TokenMixer(Xi)),(2)
- 其中,Xi|i>0是转发到第i MB的中间特征。我们进一步将阶段(或S)定义为处理具有相同空间大小的特征的几个MetaBlock的堆栈,如图中的N1×,表示S1具有N1个MetaBlock。网络包括4个阶段。在每个Stage中,对嵌入维数和下采样令牌长度进行嵌入操作,如上图所示。使用上述架构,EfficientFormer是一个完全基于transformer的模型,没有集成MobileNet结构。接下来,我们深入研究网络设计的细节,特别是体系结构细节和搜索算法。
-
Dimension-Consistent Design
-
根据上文中的观察,我们提出了一种维一致的设计,将网络分为一个4D分区,其中算子以convc -net风格实现(MB4D),以及一个3D分区,其中线性投影和关注在3D张量上执行,以享受MHSA的全局建模能力而不牺牲效率(MB3D),如图3所示。具体来说,网络从4D分区开始,最后阶段应用3D分区。注意,上图只是一个实例,4D和3D分区的实际长度是后面通过architecture search指定的。
-
首先,对输入图像进行2个3 × 3卷积的CONV干处理,步长为2,作为补丁嵌入,
-
X 1 B , C j ∣ j = 1 , H / 4 , W / 4 = P a a t c h E m b e d ( X 0 B , 3 , H , W ) , ( 3 ) \mathcal{X}_1^{B,C_{j|j=1},H/4,W/4 }=PaatchEmbed(\mathcal{X}_0^{B,3,H,W}),(3) X1B,Cj∣j=1,H/4,W/4=PaatchEmbed(X0B,3,H,W),(3)
-
其中Cj为第j级的通道号(宽度)。然后网络从MB4D开始,使用简单的Pool混合器提取低级特征,
-
I i = P o o l ( X i B , C , H 2 j + 1 , W 2 j + 1 ) + X i B , C , H 2 j + 1 , W 2 j + 1 , ( 4 ) X i B , C , H 2 j + 1 , W 2 j + 1 = C o n v B ( C o n v B , G ( I i ) ) + I i , ( 5 ) \mathcal{I}_i=Pool(\mathcal{X}_i^{B,C,\frac{H}{2^{j+1}},\frac{W}{2^{j+1}}})+\mathcal{X}_i^{B,C,\frac{H}{2^{j+1}},\frac{W}{2^{j+1}}},(4)\\ \mathcal{X}_i^{B,C,\frac{H}{2^{j+1}},\frac{W}{2^{j+1}}}=Conv_B(Conv_{B,G}(\mathcal{I_i}))+\mathcal{I_i},(5) Ii=Pool(XiB,C,2j+1H,2j+1W)+XiB,C,2j+1H,2j+1W,(4)XiB,C,2j+1H,2j+1W=ConvB(ConvB,G(Ii))+Ii,(5)
-
其中ConvB,G表示卷积后是否分别有BN和GeLU。注意这里我们没有像[PoolFormer]中那样在池搅拌器之前使用组或层归一化(LN),因为4D分区是基于CONV -BN的设计,因此在每个池搅拌器前面都存在一个BN。
-
在处理完所有的MB4D块后,我们进行一次重塑,变换特征大小,进入3D分区。MB3D采用传统的ViT结构,如图3所示。公式:
-
I i = L i n e a r ( M H S A ( L i n e a r ( L N ( X i B , H W 4 j + 1 , C j ) ) ) ) + X i B , H W 4 j + 1 , C j , ( 6 ) X i B , H W 4 j + 1 , C j = L i n e a r ( L i n e a r G ( L N ( I i ) ) ) + I i , ( 7 ) \mathcal{I_i}=Linear(MHSA(Linear(LN(\mathcal{X}_i^{B,\frac{HW}{4^{j+1}},C_j}))))+\mathcal{X}_i^{B,\frac{HW}{4^{j+1}},C_j},(6)\\ \mathcal{X}_i^{B,\frac{HW}{4^{j+1}},C_j}=Linear(Linear_G(LN(\mathcal{I_i})))+\mathcal{I_i},(7) Ii=Linear(MHSA(Linear(LN(XiB,4j+1HW,Cj))))+XiB,4j+1HW,Cj,(6)XiB,4j+1HW,Cj=Linear(LinearG(LN(Ii)))+Ii,(7)
-
其中LinearG表示Linear,后面跟着GeLU,和
-
M H S A ( Q , K , V ) = s o f t m a x ( Q ⋅ K T / C j + b ) ⋅ V , ( 8 ) MHSA(Q,K,V)=softmax(Q·K^T/\sqrt{C_j}+b)·V,(8) MHSA(Q,K,V)=softmax(Q⋅KT/Cj+b)⋅V,(8)
-
其中Q、K、V表示线性投影学习到的查询、键和值,b表示注意偏差参数化为位置编码。
-
-
Latency Driven Slimming
-
超级网络的设计。基于尺寸一致的设计,我们构建了一个超级网络,用于搜索网络架构的高效模型,如图所示(为搜索到的最终网络示例)。为了表示这样一个超网络,我们定义了MetaPath (MP),它是可能块的集合:
-
M P i , j = 1 , 2 ∈ { M B i 4 D , I i } M P i , j = 3 , 4 ∈ { M B i 4 D , M B i 3 D , I i } ( 7 ) MP_{i,j=1,2}\in\{MB_i^{4D},I_i\}\\ MP_{i,j=3,4}\in\{MB_i^{4D},MB_i^{3D},I_i\}(7) MPi,j=1,2∈{MBi4D,Ii}MPi,j=3,4∈{MBi4D,MBi3D,Ii}(7)
-
其中I表示身份路径,j表示第j个阶段,I表示第I个块。超网络可以用MP代替图3中的MB来说明。如Eqn. 7所示,在超网的S1和S2中,每个区块可以从MB4D或I中选择,而在S3和S4中,每个区块可以从MB3D、MB4D或I中选择。我们只在后两个阶段启用MB3D,原因有二。首先,由于MHSA的计算量相对于令牌长度呈二次增长,在早期阶段对其进行集成将大大增加计算成本。其次,将全局MHSA应用到最后一个阶段与直觉一致,即网络的早期阶段捕获低级特征,而后期层学习长期依赖关系。
-
搜索空间。本文的搜索空间包括Cj(每个Stage的宽度),Nj(每个Stage的块数,即深度),最后N个块来应用MB3D。
-
搜索算法。以往的硬件感知网络搜索方法一般依赖于在搜索空间中对每个候选节点进行硬件部署来获取时延,耗时较长。在这项工作中,我们提出了一个简单、快速而有效的基于梯度的搜索算法,以获得一个只需要训练一次超级网络的候选网络。该算法有三个主要步骤。
-
首先,我们用Gumbel Softmax sampling训练超网络,得到每个MP内块的重要性分数,可以表示为
-
X i + 1 = , ( 8 ) \mathcal{X}_{i+1}=,(8) Xi+1=,(8)
-
其中α评估MP中每个块的重要性,因为它代表了选择一个块的概率,例如,为第i个块选择MB4D或MB3D。 η \eta η∼U(0,1)保证探测,τ为温度,n表示MP中的块类型,即S1和S2为n∈{4D, I}, S3和S4为n∈{4D, 3D, I}。利用Eqn. 8,可以很容易地求出网络权值和α的导数。训练遵循标准配方(见第5.1节),以获得训练的权重和结构参数α。
-
其次,我们通过收集不同宽度的MB4D和MB3D的设备上延迟(16的倍数)来构建一个延迟查找表。
-
最后,我们通过查找表评估从第一步获得的超网络执行网络瘦身。注意,典型的基于梯度的搜索算法只是选择α最大的块,它不适合我们的范围,因为它不能搜索宽度Cj。事实上,构造一个多宽度的超网络是消耗内存的,甚至不现实,因为在我们的设计中每个MP都有几个分支。我们不再直接在复杂搜索空间上进行搜索,而是在单宽度超网络上进行逐步瘦身,如下所示。
-
-
我们首先定义MPi的重要性分数分别为S1,2和S3,4的α4D i αIi和α3D i +α4D i αIi。类似地,每个阶段的重要性得分可以通过将该阶段内所有MP的得分相加得到。根据重要性分数,我们定义动作空间,其中包括三个选项:1)为最不重要的MP选择I, 2)删除第一个MB3D, 3)减少最不重要阶段的宽度(乘以16)。然后,我们通过查找表计算每个动作的结果延迟,并评估每个动作的准确率下降。最后,我们根据每个延迟精度下降(−% ms)选择操作。此过程将迭代执行,直到达到目标延迟。
-
实验与讨论
-
我们通过PyTorch 1.11和Timm库实现了EfficientFormer,这是近年来的常见实践。我们的模型是在NVIDIA A100和V100 gpu集群上训练的。iPhone 12 (A14仿生芯片)上的推理速度是用iOS版本15来衡量的,平均运行超过1000次,使用所有可用的计算资源(NPU),或仅CPU。CoreMLTools用于部署运行时模型。此外,我们还提供了Nvidia A100 GPU的延迟分析,批处理大小为64,以利用硬件屋顶线。经过训练的PyTorch模型以ONNX格式部署,并使用TensorRT进行编译。报告不包括预处理的GPU运行时。我们在附录6中提供了详细的网络结构和更多的消融研究。
-
Image Classification
-
所有的EfficientFormer模型都在ImageNet-1K数据集上从头开始训练,以执行图像分类任务。我们使用标准图像大小(224 × 224)进行训练和测试。我们遵循DeiT的训练配方,但主要报告300个训练周期的结果,以便与其他基于vit的模型进行比较。我们使用AdamW优化器,5个周期的热身训练和余弦退火学习率计划。初始学习率设置为10−3 ×(批大小/1024),最小学习率设置为10−5。蒸馏教师模型为RegNetY -16GF,在ImageNet上预训练,top-1准确率为82.9%。结果如表和图所示。
-
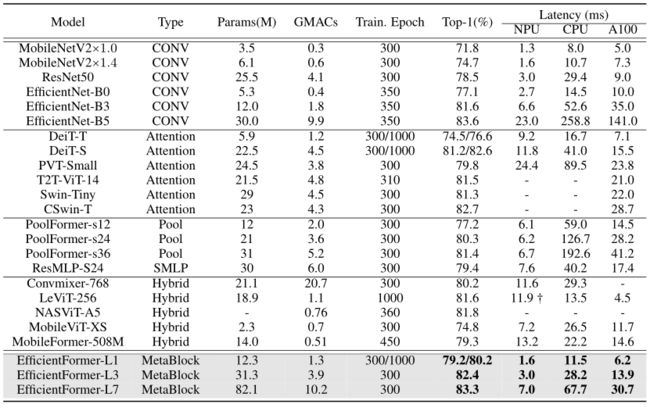
-
ImgeNet-1K比较结果。延迟结果分别在iPhone Neural Engine (NPU)、iPhone CPU和Nvidia A100 GPU上进行测试。注意,对于移动速度,我们报告每帧的延迟,而在A100 GPU上,我们报告每批大小64的延迟,以达到最大的资源利用率。Hybrid是指MobileNet块和ViT块的混合。(-)指未透露或不支持的模型。†使用GeLU激活测量的延迟进行公平的比较,原始的levitt -256模型与HardSwish激活运行在44.5 ms。不同的训练种子导致EfficientFormer的准确度波动小于±0.2%,延迟基准的误差小于±0.1 ms。
-
-
与cnn的比较。与广泛使用的基于cnn的模型相比,EfficientFormer在准确性和延迟之间实现了更好的平衡。在iPhone Neural Engine上,EfficientFormerL1以MobileNetV2×1.4的速度运行,同时实现4.5%的top-1精度。此外,EfficientFormer-L3的运行速度与EfficientNet-B0相似,而top-1精度相对高5.3%。对于性能较高的模型(> 83% top-1), EfficientFormer-L7的运行速度比EfficientNet-B5快3倍以上,显示了我们模型的性能优势。此外,在桌面GPU (A100)上,EfficientFormer-L1的运行速度比EfficientNet-B0快38%,而top-1精度提高2.1%。EfficientFormer-L7比EfficientNet-B5快4.6倍。这些结果使我们能够回答前面提出的核心问题;ViT不需要牺牲延迟来获得良好的性能,而且精确的ViT仍然可以像轻量级cnn一样具有超快的推理速度。
-
与vit的比较。传统的vit在延迟方面仍然不如cnn。例如,DeiT-Tiny的精度与EfficientNet-B0相似,但运行速度慢3.4倍。但是,EfficientFormer与其他转换器模型一样,运行时间更快。与DeiT-Small相比,EfficientFormerL3的准确率更高(82.4% vs 81.2%),速度快4倍。值得注意的是,尽管最近的变压器变体PoolFormer自然具有一致的4D架构,并且与典型的vit相比运行得更快,但缺少全局MHSA极大地限制了性能上限。与PoolFormer-S36相比,EfficientFormer-L3的top-1精度提高了1%,在Nvidia A100 GPU上快了3倍,在iPhone NPU上快了2.2倍,在iPhone CPU上快了6.8倍。
-
与混合设计的比较。现有的混合设计,例如levitt -256和MobileViT,仍然与vit的延迟瓶颈作斗争,并且很难超越轻量级cnn。例如,levite -256的运行速度比DeiT-Small慢,而top-1精度低1%。对于包含MHSA和MobileNet块的混合模型MobileViT,观察到它明显比CNN同类模型(例如MobileNetV2和EfficientNet-B0)慢,而精度也不令人满意(比EfficientNet-B0低2.3%)。因此,简单地用MobileNet块交换MHSA很难推动帕累托曲线前进。相比之下,作为纯基于变压器的模型,EfficientFormer可以在保持高性能的同时实现超快的推理速度。EfficientFormer-L1的top-1精度比MobileViT-XS高4.4%,并且在不同的硬件和编译器上运行得更快(在Nvidia A100 GPU计算上快1.9倍,在iPhone CPU上快2.3倍,在iPhone NPU上快4.5倍)。在相似的推理时间,在ImageNet上,EfficientFormer-L7的top-1准确率比MobileViT-XS高出8.5%,显示了我们设计的优越性。
EfficientFormer as Backbone
-
目标检测与实例分割。我们遵循Mask-RCNN的实现,集成了EfficientFormer作为骨干,并验证了性能。我们在COCO2017上进行实验,其中分别包含118K和5K图像的训练集和验证集。使用ImageNet-1K预训练的权重初始化EfficientFormer骨干。与之前的工作[PoolFormer]类似,使用初始学习率为2 × 10−4的AdamW优化器,训练模型12个epoch。我们将输入大小设置为1333 × 800。
-
检测和实例分割结果如下表所示。EfficientFormers的性能始终优于CNN (ResNet)和transformer (PoolFormer)主干。在计算成本相似的情况下,EfficientFormer- l3比ResNet50骨骨干高出3.4 box AP和3.7 mask AP,比PoolFormer-S24骨骨干高出1.3 box AP和1.1 mask AP,证明了EfficientFormer在视觉任务中泛化能力较强。
-
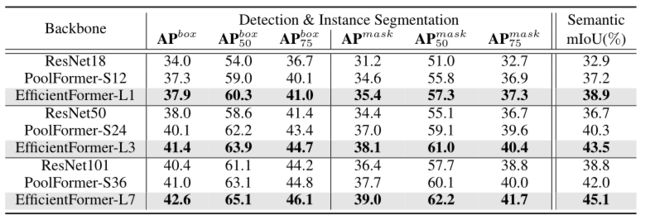
-
以EfficientFormer为骨干的比较结果。目标检测和实例分割的结果来自COCO 2017。语义分割结果由ADE20K得到。
-
-
语义分割。进一步验证了EfficientFormer在语义分割任务上的性能。我们使用具有挑战性的场景解析数据集ADE20K,其中包含20K个训练图像和2K个验证图像,涵盖150个类别。与现有的工作[poolformer]类似,我们构建了EfficientFormer作为骨干,并将Semantic FPN[82]作为分割解码器,以进行公平的比较。在ImageNet-1K上使用预训练的权重初始化骨干,并在8个gpu上训练模型40K次迭代,总批大小为32个。我们遵循分割中的常用做法,使用AdamW优化器,从初始学习率2 × 10−4开始,应用幂为0.9的多学习率调度。我们调整输入图像的大小并裁剪为512 × 512用于训练,短的一侧为512用于测试(在验证集上)。
-
如上表所示。在类似的计算预算下,EfficientFormer始终优于基于CNN和transformer的主干。例如,EfficientFormer-L3的性能比PoolFormer-S24高出3.2 mIoU。我们表明,在全局关注下,EfficientFormer学习了更好的长期依赖关系,这在高分辨率的密集预测任务中是有益的。
Discussion
-
与MetaFormer的关系。EfficientFormer的设计部分是受到MetaFormer概念的启发。与PoolFormer相比,EfficientFormer解决了维度不匹配问题,这是低效边缘推断的根本原因,因此能够在不牺牲速度的情况下利用全局MHSA。因此,与PoolFormer相比,EfficientFormer表现出了优越的精度性能。尽管PoolFormer完全是4D设计,但它采用了低效的补丁嵌入和分组归一化,导致延迟增加。相反,我们重新设计的4D分区的EfficientFormer是更加硬件友好的,并在多个任务中表现出更好的性能。
-
局限性。(i)虽然大多数设计是通用的,例如尺寸一致设计和带有convn - bn融合的4D块,但在其他平台上,EfficientFormer的实际速度可能不同。例如,如果GeLU没有得到很好的支持,而HardSwish在特定的硬件和编译器上得到了有效的实现,则可能需要相应地修改操作符。(ii)提出的延迟驱动瘦身简单快速。但是,如果不考虑搜索成本并执行基于枚举的暴力搜索,则可能获得更好的结果。
Conclusion
- 在这项工作中,我们展示了Vision Transformer可以在移动设备上以MobileNet速度运行。从全面的延迟分析开始,我们在一系列基于vitc的架构中识别出低效的操作符,从而得出重要的观察结果,指导我们的新设计范例。提出的EfficientFormer符合尺寸一致的设计,平滑地利用硬件友好的4D MetaBlocks和强大的3D MHSA块。我们进一步提出了一种基于设计空间的快速延迟驱动瘦身方法来获得优化的配置。在图像分类、目标检测和分割任务上的大量实验表明,EfficientFormer模型优于现有的变压器模型,同时比大多数竞争对手的cnn更快。ViT架构的延迟驱动分析和实验结果验证了我们的说法:强大的视觉变压器可以在边缘上实现超快的推理速度。未来的研究将进一步探索EfficientFormer在几种资源受限设备上的潜力。
Ablation Analysis
-
我们的主要结论和速度分析可以在延迟分析图中找到。在这里,我们包括更多针对不同设计选择的消融研究,如下表所示,以EfficientFormer-L3为例。在iPhone 12上使用CoreML测量延迟,从ImageNet-1K数据集获得top-1的精度。
-

-
对EfficientFormer-L3设计选择的烧蚀分析。V1-5是指具有不同操作符选择的变体。
-
Patch Embedding.
- 与非重叠大核补丁嵌入(上表中的V5)相比,提出的EfficientFormer中的卷积干(上表中的V1)大大降低了48%的推理延迟,准确率提高了0.7%。我们证明了卷积干不仅有利于模型的收敛性和准确性,而且大大提高了移动设备上的推理速度,因此可以作为非重叠补丁嵌入实现的一个很好的替代方案。
-
MHSA和延迟驱动搜索。
- 如果没有提出的3D MHSA和延迟驱动搜索,EfficientFormer降级为带有池混合器的纯4D设计,这类似于PoolFormer(补丁嵌入和归一化是不同的)。通过对比上表中的EfficientFormer和V1,我们可以观察到3D MHSA和延迟驱动搜索的集成极大地提高了2.1%的top-1精度,而对推断速度的影响最小(0.5 ms)。结果证明,具有全局感受野的MHSA对模型性能有重要贡献。因此,尽管可以享受更快的推断速度,但简单地删除MHSA会极大地限制性能上限。在EfficientFormer中,我们以维度一致的方式平滑地集成MHSA,获得更好的性能,同时实现超快的推理速度。
-
规范化。
- 除了在EfficientFormer的4D分区中的convn - bn结构,还探索了在之前的工作[metaformer]中使用的4D分区中的组归一化(GN)和通道层归一化(LN)。通过比较V1和V2,可以观察到,GN (V2-GN)只能略微提高精度(0.3% top-1),但由于在推理阶段不能折叠,会产生延迟开销。类似地,应用LN (V2-LN)比BN具有更高的延迟,而性能改进可以忽略不计。因此,我们在effentformer的整个4D分区中应用了convn - bn结构。
-
激活函数。
- 除了本研究中使用的GeLU(V1),还探索了ReLU和HardSwish(V3和V4)。大家普遍认为ReLU是最简单最快的激活函数,而GeLU和HardSwish的性能更好。我们观察到,在使用CoreMLTools的iPhone 12上,ReLU几乎不能提供任何超过GeLU的加速,而HardSwish明显比ReLU和GeLU慢。我们得出的结论是,激活函数可以根据具体的硬件和编译器具体情况来选择。在这项工作中,我们使用GeLU提供了比ReLU更好的性能,同时执行速度更快。为了公平比较,我们根据iPhone 12和CoreMLTools的支持修改了其他作品中的低效算子,例如将HardSwish改为GeLU来报告LeViT延迟。
-
尺寸一致性设计。
-
在Nvidia A100 GPU上进行了延迟分析,以表明所提出的尺寸一致(D-C)设计除了对iPhone有益之外也是有益的。将批处理大小为64的PyTorch模型部署为ONNX格式,并使用TensorRT编译和基准测试延迟。我们在下表中报告了平均超过1000次运行的延迟结果。对于非dc - c设计,我们将提出的Meta3D块还原为4D实现,其中线性投影和mlp都是用CONV1×1-BN实现的,而不是3D-Linear层,为了执行多头自注意,重塑操作变得必要。通过这种配置,注意力块可以与Meta4D块一起任意放置,而无需遵循尺寸一致的设计,同时引入了频繁的重塑。我们对以下两个模型进行比较,计算复杂度完全相同的dc版本和非dc版本:
-
EfficientFormer-L7,有8个注意力块。DummyNet,一个手工制作的假人模型,共有16个注意力块。
-

-
尺寸一致性(D-C)设计与非D-C注意块放置的分析。延迟(ms)是在Nvidia A100 GPU上使用TensorRT测量的。
-
从上表可以看出,无论是对EfficientFormer-L7还是对DummyNet,所提出的尺寸一致设计都比非尺寸一致设计的推理速度更快。
-
-
延迟驱动瘦身。
-
除了硬件高效的架构设计外,为模型找到合适的深度和宽度配置以实现令人满意的性能仍然至关重要。为了理解延迟驱动瘦身的好处,我们从搜索空间中随机抽取了具有相同计算量的网络样本,即1.3 gmac,与我们的搜索模型EfficientFormer-L1相同。样本网络记为Random 1 ~ Random 5,分别比effentformer - l1更深更窄,或更浅更宽。我们使用与effentformer - l1相同的训练配方在ImageNet-1K上训练样本模型。这些模型的比较如下表所示。可以看到,我们搜索的EfficientFormer-L1在ImageNet-1K上比随机采样的网络具有更好的延迟或更高的top-1精度,证明了我们提出的延迟驱动瘦身的优势。
-
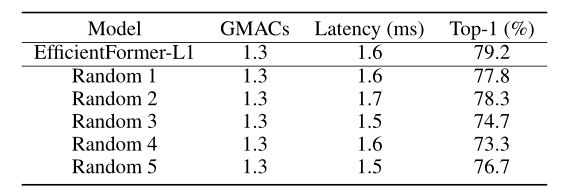
-
延迟驱动的瘦身分析。所有随机网络都使用与ImageNet-1K上的EfficientFormer-L1相同的训练策略进行训练。时延是在iPhone 12 NPU上使用CoreMLTools得到的。
-
Architecture of EfficientFormers
-
下表给出了efficiency - former - l1、efficiency - former - l3和efficiency - former - l7的详细网络架构。我们报告每个阶段的分辨率和块数。此外,EfficientFormer的宽度被指定为嵌入尺寸(Embed。昏暗的)。对于MHSA块,提供了Query和Key的维度,并且我们为所有的EfficientFormer变体使用了8个头。MLP扩展比设置为默认值,就像大多数ViT艺术一样。
-
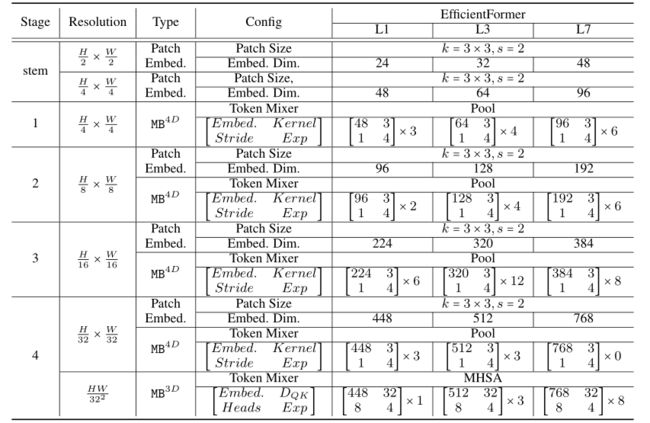
-
EfficientFormer的体系结构细节。Exp为MLP块的膨胀比。DQK是查询和键的维度。
硬件利用率分析
-
EfficientFormer通过更好的架构设计改进了延迟与精度之间的权衡,从而实现了更高的硬件利用率。为了了解硬件利用率,我们使用TFLOPS(每秒Tera FLOPs)作为评估指标,该指标由模型计算成本(FLOPs)除以执行时间计算得出。具有更高吞吐量(TFLOPS)的模型可以更好地利用硬件的计算能力。
-
为了与不同计算复杂度下的基线模型进行比较,对EfficientFormer-L1的深度和宽度进行线性缩放,得到一系列模型(EfficientFormer-LS-1 ~ EfficientFormer-LS-14),参数个数为1.1M ~ 31.3M, MACs为0.09G ~ 3.9G,并在iPhone 12 NPU上对时延和利用率进行基准测试。
-
如下图所示,超微型模型仍然以大约1ms的速度运行,如EfficientFormer-LS-{1,2,3},其吞吐量较低,硬件没有得到充分利用。数据处理和传输成为瓶颈。因此,在牺牲精度的情况下,让模型变得超级小是不太有价值的。相比之下,我们的1.3GMACs模型,EfficientFormer-L1处于最佳点,在保持高精度的同时享受快速推断速度(1.6ms)。
-

-
iPhone 12 NPU硬件利用率分析。
-
此外,我们可以观察到,在不同的计算复杂度水平上,EfficientFormer变体在硬件利用率方面优于cnn和vit。例如,在4-GMACs级别上,EfficientFormer-LS-14的TFLOPS比DeiT-S高3.3倍,比PoolFormer高2.2倍,实现了与ResNet50相当的吞吐量。在轻量级领域,EfficientFormerLS-4的TFLOPS比EfficientNet-B0高2.2倍。我们证明,通过提出的硬件友好型设计,EfficientFormer自然具有更好的硬件利用率。