深度学习 - 模型的优化和过拟合问题
优化函数、学习速率与反向传播算法
学习速率(learning_rate)
梯度就是表明损失函数相对参数的变化率,对梯度进行缩放的参数被称为学习速率(learning rate);
学习速率是一种超参数或对模型的一种手工可配置的设置,需要为它指定正确的值。
如果学习速率太小,则找到损失函数极小值点时可能需要许多轮迭代;如果太大,则算法可能会“跳过”极小值点并且因周期性的“跳跃”而永远无法找到极小值点。
在具体实践中,可通过查看损失函数值随时间的变化曲线,来判断学习速率的选取是合适的。
- 合适的学习速率,损失函数随时间下降,直到一个底部;
- 不合适的学习速率,损失函数可能会发生震荡。
不同的学习率会有会对模型有影响
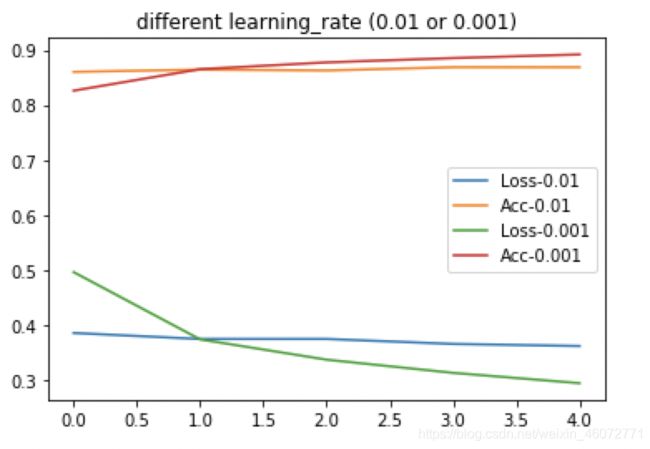
学习速率选取原则
在调整学习速率时,既需要使其足够小,保证不至于发生超调, 也要保证它足够大,以使损失函数能够尽快下降,从而可通过较少次数的迭代更快地完成学习。
反向传播算法
反向传播算法是一种高效计算数据流图中梯度的技术每一层的导数都是后一层的导数与前一层输出之积,这正是链式法则的奇妙之处,误差反向传播算法利用的正是这一特点。前馈时,从输入开始,逐一计算每个隐含层的输出,直到输出层。然后开始计算导数,并从输出层经各隐含层逐一反向传播。为了减少计算量,还需对所有已完成计算的元素进行复用。
这便是反向传播算法名称的由来。
优化器(optimizer)的选择与调用
优化器(optimizer)的原理与选择:常见优化器总结
优化器 (optimizer) 是编译模型的所需的两个参数之一。有两种方法将优化器传入model.compile():
- 通过名称来调用优化器,只能使用优化器的默认参数
optimizer='adam'; - 也可以传入实例化的优化器对象,可以进行调参数(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01))。
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
上下方法是等价的,效果相同
model.compile(optimizer='adam,
loss='sparse_categorical_crossentropy',
metrics=['acc'])
网络优化与超参数选择
网络容量(可以认为与网络中的可训练参数成正比网络容量)
- 网络中的神经单元数越多,层数越多,神经网络的拟合能力越强。
但是训练速度、难度越大,越容易产生过拟合。
如何选择超参数?
- 所谓超参数,也就是搭建神经网络中,需要我们自己如选择(不是通过梯度下降算法去优化)的那些参数。
- 比如,中间层的神经元个数、学习速率
那么如何提高网络的拟合能力,一种显然的想法是增大网络容量:
- 增加层
- 增加隐藏神经元个数那么如何提高网络的拟合能力
这两种方法哪种更好呢?
- 单纯的增加神经元个数对于网络性能的提高并不明显,增加层会大大提高网络的拟合能力;
- 这也是为什么现在深度学习的层越来越深的原因那么如何提高网络的拟合能力。
注意:单层的神经元个数,不能太小,太小的话,会造成信息瓶颈,使得模型欠拟合。
参数选择原则
理想的模型是刚好在欠拟合和过拟合的界线上,也就是正好拟合数据。
首先开发一个过拟合的模型:
- 添加更多的层。
- 让每一层变得更大。
- 训练更多的轮次参数选择原则
然后,抑制过拟合:
- 增加Dropout层
- 正则化
- 图像增强参数选择原则
再次,调节超参数:学习速率,隐藏层单元数,训练轮次
❗️总的原则是:保证神经网络容量足够拟合数据
一、增大网络容量,直到过拟合
二、采取措施抑制过拟合
三、继续增大网络容量,直到过拟合
超参数的选择是一个经验与不断测试的结果。
经典机器学习的方法,如特征工程、增加训练数据也要做交叉验证。
关于过拟合
根据图像观察是否产生过拟合⚠️
根据下边两张对loss和acc的对比图像可以看出:
在epoch = 1左右的时候两张图像均产生了交点,且在交点之后数值的大小均产生了变化
- 训练集测得loss < 测试集测得val_loss (loss越小越好)
- 训练集测得acc > 测试集测得val_acc (acc越大越好)
模型对训练集的性能优于模型对测试集的性能;
则说明,从此交点之后,发生了过拟合的现象。

抑制过拟合
增加Dropout层解决过拟合问题
为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝.
理想的模型是刚好在欠拟合和过拟合的界线上,也就是正好拟合数据。
# 不会单独出现,会跟在其他用于拟合的隐藏层后(例如:全连接层)
model.add(tf.keras.layers.Dropout(0.5)) # 删除50%的数据
举个例子
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5)) # 删除50%的数据
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5)) # 删除50%的数据
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5)) # 删除50%的数据
model.add(tf.keras.layers.Dense(10, activation='softmax'))
由下面两张图可以看出没有再发生过拟合(但正确率有所减小,可能是Dropout层太多了)
plt.plot(model_fit.epoch, model_fit.history['acc'])
plt.plot(model_fit.epoch, model_fit.history['val_acc'])
plt.legend(('acc', 'val_acc'))
plt.show()
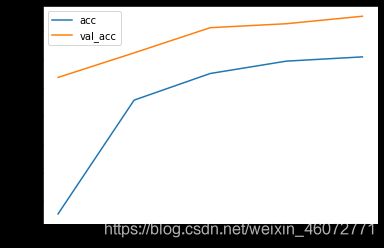
减小网络容量也可以抑制过拟合
# 可以看出此模型相比上边的减少了2个隐藏层,并且同时减小了隐藏层的输出维度(由128减至32)
model3 = tf.keras.Sequential()
model3.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model3.add(tf.keras.layers.Dense(24, activation='relu'))
model3.add(tf.keras.layers.Dense(10, activation='softmax'))
model3.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
model3_fit = model3.fit(train_image, train_label,
epochs=5,
validation_data=(test_image, test_label))