飞桨+昆仑芯的大模型推理优化与应用实践
近日,2023全球人工智能开发者先锋大会(GAIDC 2023)于上海成功举办。大会以“向光而行的AI开发者”为主题,汇聚了当前科技和产业革命中的开发者先锋力量。
作为落户于上海市临港新片区的AI芯片企业,昆仑芯科技是“芯无限,闯未来——AI芯片开发者论坛”、“智领未来:大模型技术与应用论坛”的主要协办单位之一,并深度参与上述两个论坛的主题演讲,及互动体验展区,全面展现公司的综合实力优势。
“智领未来:大模型技术与应用”论坛上,昆仑芯科技互联网行业研发总监王志鹏介绍了飞桨+昆仑芯对大模型推理的优化加速技术,并分享了在百度搜索、百度商业、文心一格等大规模业务场景中的应用实践经验。该分享围绕稠密大模型和稀疏大模型展开,大模型对应的模型体积和计算量,给实际产业应用的推理部署带来严峻挑战,昆仑芯基于飞桨框架,针对不同类型的大模型开展了深度优化,并实现了大规模应用落地。
 昆仑芯科技互联网行业研发总监 王志鹏
昆仑芯科技互联网行业研发总监 王志鹏
本篇以下内容整理于昆仑芯科技互联网行业研发总监王志鹏题为《昆仑芯大模型推理优化与应用实践》演讲实录。(篇末附现场直播回放)
首先为大家简单介绍昆仑芯科技这家公司。公司前身是百度智能芯片及架构部,2021年4月完成独立融资。团队在国内最早布局AI加速领域,深耕10余年。我们在硬件架构方面有多年积累,核心团队于2017年推出了自研的通用AI计算处理器核心架构昆仑芯XPU,目前公司已经实现两代产品的成功量产及规模落地。
公司取得的较突出成果其中之一就是:在互联网公司的多个核心业务场景,我们的客户把昆仑芯AI加速卡真正用了起来,而且性能等各方面都取得了很好的效果,帮用户实现了降本增效。
我们的互联网研发团队,在支持昆仑芯两代产品上万片规模部署中,完成了从系统到框架、到算子的端到端研发落地工作,今天的分享也会围绕这点来展开。

我们站在商业化落地的角度去看,现在行业里真正意义上大规模应用的大模型到底是什么?
从产业落地的角度来看,市场上真正在大规模应用的两类大模型:
第一类是稠密大模型,以Transformer结构为主,包含Encoder和Decoder。Encoder占比大的是很多NLP的判别类任务;而Decoder,比如最近出圈的ChatGPT则是以Decoder为主。
第二类是稀疏大模型,模型规模可高达TB量级,广泛应用在各大互联网公司的广告、推荐系统中,算力消耗非常大。
后面会围绕这两类展开来讲。
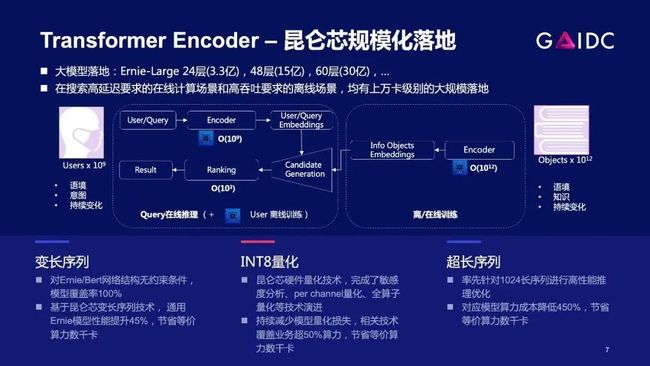
首先来看稠密大模型的推理,它的核心是Transformer。结合我们的真实业务来讲,过去三年昆仑芯在百度搜索业务持续上量。这里可以通过两个数字看一看:
- 部署了数万张昆仑芯AI加速卡
- 在推理领域部署的比例远超50%
可以说,在搜索业务场景,客户把后背交给了我们。

Encoder优化:变长序列和INT8量化

什么是变长序列?比如说大家在百度搜关键词,对于同一批请求,大部分query只有16字节,但某个query达到了128字节,这会导致输入矩阵规模达到128,这就是上面提到的padding rate,补了很多0,而这部分0我们是不希望占用计算资源的。
在推理引擎层面,我们把补0的位置记下来,在算子开发层面,对补0的这部分数据,不送入SRAM,只送入有效数据,这个技术叫做“密排”。
在硬件底层,矩阵乘计算单元需要具备支持任意规模矩阵乘,直接计算的能力,不需要向上取整后再计算。
举个例子:“密排”后矩阵乘输入规模是37,而如果硬件不支持任意规模,需要向上取整到64,那64-37这部分,会带来额外的DMA开销和额外的无效计算。
这些无效计算,能否完全不做呢?
可以看到,任何优化都是软硬协同的。硬件层面,昆仑芯可以做到任意规模,无需取整,再结合我们软件层面的优化支持,最终可实现无效计算的100%消除。
实测数据上,在搜索真实业务模型上,打开变长性能可以提升60%-70%,这个数字在行业内是非常有竞争力的。

接下来我们看INT8量化。它的目标也是为了提升性能,用8位计算,能有效减少计算量。跟变长序列不同的是:变长序列优化是精度无损的,而INT8量化,是精度有损的。
这里面最大的挑战是:如何在控制精度损失的情况下(保证业务可接受),还能完成INT8量化能大规模上线,并取得性能收益。
我们联合PaddleSlim团队完成INT8量化相关基建,其中关键一项是:OP敏感度分析工具。
解释一下:对于一个模型来讲,有74个OP,可能其中某一个OP替换为INT8后精度掉的特别多。OP敏感度分析工具可以在模型中快速找到使精度下降最快的OP,并将其还原成FP16,从而达到大幅降低精度损失的效果。
换言之,不是所有的OP全部要求用INT8精度,而是保证90%-95%的OP是INT8精度。这样,一方面精度达到可上线的要求,另外一方面INT8的收益也还能保留90%以上。

Decoding优化技术
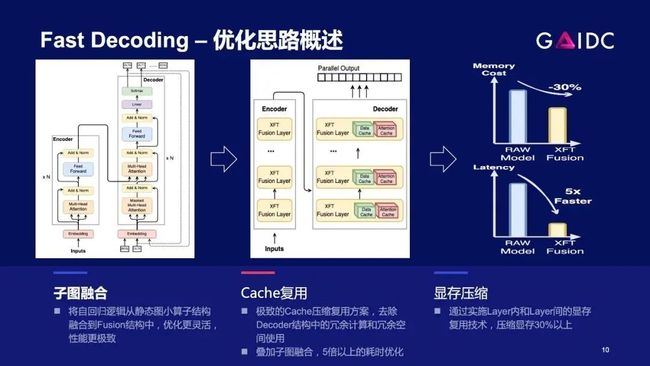
接下来我们一起看下Decoding部分的优化。这个需求来自百度内部真实场景,一个是翻译,一个是对话(Plato-X),这两类模型参数量已经达到10亿+规模。
Decoding与Encoder不同的是它有自回归循环结构,因此在解码过程中会产生大量重复计算。针对这种情况,我们通过下面提到的多种方案,相比于优化前的基线版本,实现了5倍以上的性能提升。
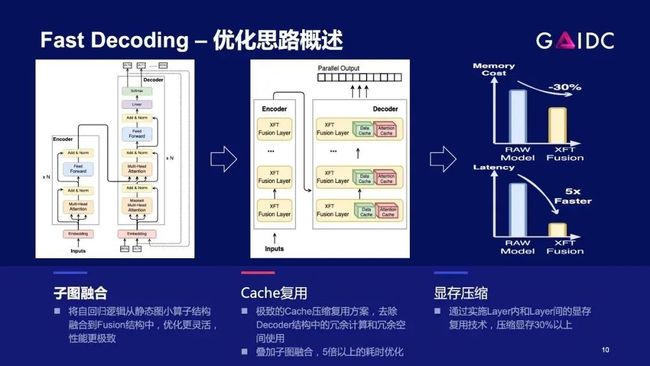
展开讲下优化细节:
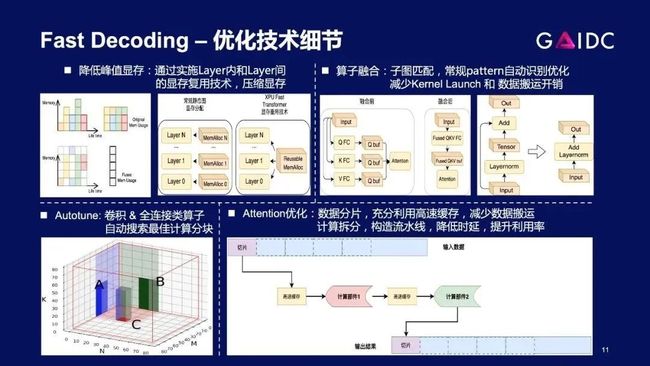
第一类,通用的AI硬件都会有的图优化和显存优化
第二类,算子层面优化,例如自动的Autotune,手动的跟硬件特性相关的优化
第三类,自回归结构带来的重复计算,靠空间换时间,利用K/V_cache,用少量的显存额外开销,换来性能的显著提升
值得一提的是,优化技巧与业务有很强的关联。
例如翻译,有两类场景:
- 在线场景
对时延要求非常高,因此使得很多优化手段受限;
- 离线场景
时延要求相对宽松,因此可以利用硬件多stream技术把硬件利用率打满。比如从60%提高到90%,这样虽然时延有所增加,但吞吐极大提升,可以帮用户节省更多成本。
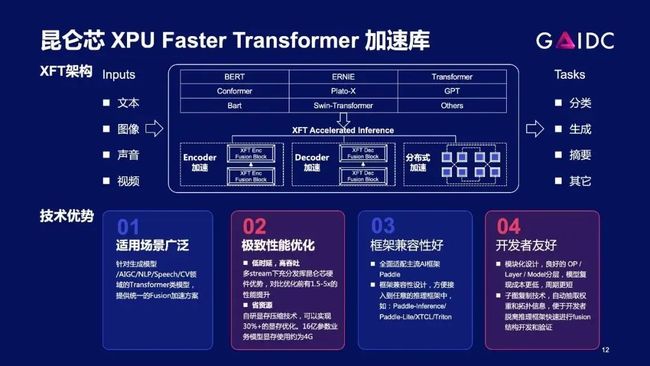
以上Encoder和Decoding所有的优化技术,都已经沉淀为了重要的基建,支撑大模型推理的快速推进。我们把Transformer相关的优化技术沉淀出来,并跟飞桨PaddlePaddle做全面整合,融入飞桨PaddlePaddle生态。
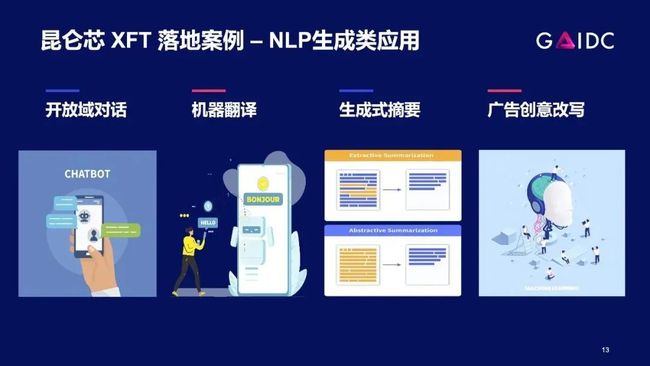
这是我们落地的生成类应用,有些数据可以share给大家。
今天大家都在谈千亿模型应用,但实际落地的过程中,很多业务在往大模型演进的过程中是有中间态的。比如说,PLATO应用最广泛的版本,主要是6亿和16亿参数量。对于很多垂类场景,这些规模的模型已经能很好的完成当前任务。
从产业趋势来看,百亿模型推理未来大概率也是重点落地方向,因为其在推理成本和推理时延方面相比千亿模型极具优势,我们也在重点跟进。
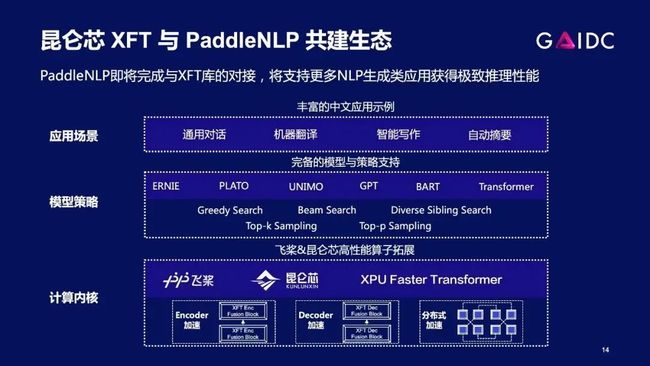
专业的事儿,让专业的人去做。昆仑芯专注打磨作为一家芯片公司的核心产品力——围绕模型,把性能做好。
上层应用解决方案则是飞桨PaddlePaddle框架及PaddleNLP所擅长的,我们通过与飞桨的共同协作,可以让更多用户、以更高效便捷的方式,来快速体验昆仑芯产品。

扩散模型上的落地进展
接下来分享下昆仑芯在扩散模型上的落地进展。
2022年Q4,昆仑芯和文心一格团队、飞桨PaddlePaddle团队,三方发起了端到端联合优化项目,我们快速分析性能瓶颈——Unet是最大的性能开销,而超长序列Attention算子则是性能开销top1。我们在2-3周内快速完成端到端优化,最终的优化效果是实现了2秒出图。
这也从侧面体现了昆仑芯硬件在AI多场景具备很强的通用性。

文心一格上已经部署昆仑芯AI加速卡R200,以上是基于昆仑芯AI加速卡出图的真实效果。
未来,生成类应用场景对算力需求会越来越大。面对强大的竞争对手,如何在国内AI芯片公司中出圈?作为AI芯片公司,能更早深入理解新的AI场景,并设计出有竞争力的软硬件产品,是持续保持竞争力的关键。

从训练到推理的落地之路
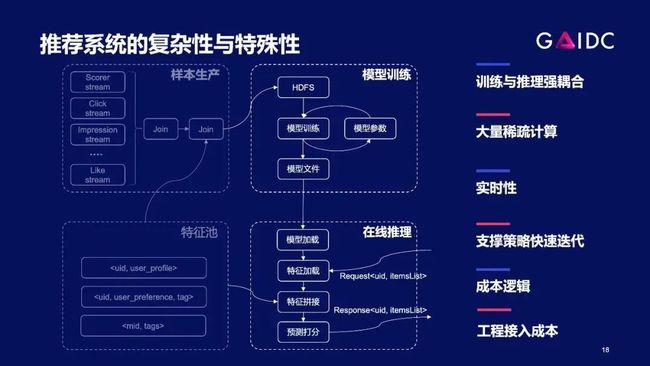
稀疏大模型与稠密大模型不同的点是:稠密模型优化好后,算好成本,客户就认为搞定了,但对稀疏模型来讲并不是这样。由于之前缺乏这方面的认识,我们也遇到了一些挫折——优化好了dense模型,以为用户就会买单,而客户教育我们说:在整个推荐推理过程中,dense模型开销只占全流程的20%,仅仅把dense部分优化好,是不够的。
我们也意识到:真正要切入推荐场景,就要跳出模型优化的单一思路,站在推荐系统全局,看到训练和推理的强耦合性,重新找准痛点切入。
接下来给各位分享我们走通的这条从训练到推理的落地道路。
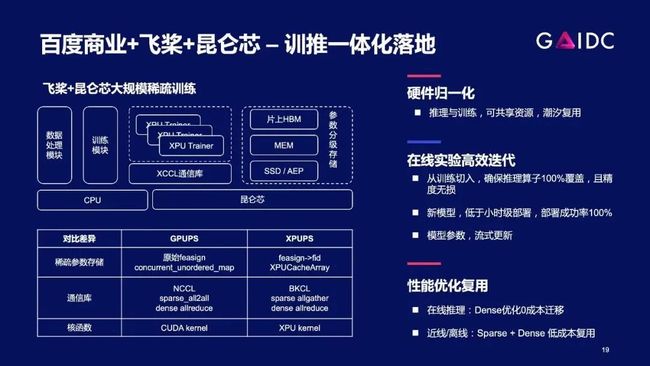
一年半以前,百度商业团队、飞桨PaddlePaddle参数服务器架构团队以及昆仑芯团队,启动了联合研发项目。
第一期,我们用昆仑芯AI加速卡R200推理卡,实现广告系统的稀疏模型的训练。事实证明,此类模型本身对算力和通信带宽需求比较小,在R200上能充分发挥硬件利用率。
我们也在外部客户中验证了这个逻辑:对于很多真实训练场景,并不是算力、带宽越大越好。
在百GB级别的稀疏大模型上,百度内部已经开始规模上线。
同时,基于昆仑芯AI加速器组R480-X8硬件,我们已经完成了TB级别稀疏大模型的性能优化,并取得了业内很有竞争力的性能数据,接下来会持续扩大落地规模。
抛开训练,单看推荐系统大模型的推理过程,相比稠密模型复杂很多——包含特征抽取、模型参数检索等等,链条非常长;计算过程复杂,在CPU和GPU上均有部分计算负载。
因此,对新硬件公司来说,该场景很难切入,找准切入点就非常重要。我们选择了从稠密模型切入,在多个客户的推荐场景中完成了规模化落地,技术细节这里不做展开。
大规模落地验证和深刻的场景理解是昆仑芯的核心优势。我们可以更快找到客户的痛点,并在项目执行中高效落地。

结语
大规模落地验证和深刻的场景理解是昆仑芯的核心优势。我们可以更快找到客户的痛点,并在项目执行中高效落地。
今天的主题涵盖内容比较多,没有把每块都展开细讲,未来我们持续把团队更多更详细的技术进展和大家进行分享,谢谢。