hive整理-按照题目顺序--一
目录
-
- 1:写个sql,一个表,分区是date,一个键是id,想知道第一天和第二天到这个地方相同的人/第一天的总人数、行转列、列转行、留存率、求成绩行列转换、
- 2. hive的理解,数据分层中的应用 --》数据库\数据仓库区别
-
- 2.1 数据库\数据仓库区别
- 2.2 数据仓库建模的意义,为什么要对数据仓库分层?
- 2.3 数仓分层
- 3. hive底层原理,sql执行过程
-
- 3.1 hive执行顺序
- 3.2.1 Hive执行流程
- 3.2.1 Hive工作原理
- 5.是否所有的map进行之后才能进行reduce(阿里也问过同样的问题)
- 6.Hive优化?SQL优化,参数优化
-
- 01.请慎重使用COUNT(DISTINCT col)
- 02.小文件会造成资源的过度占用以及影响查询效率
- 03.请慎重使用SELECT *
- 04.不要在表关联后面加WHERE条件
- 05.处理掉字段中带有空值的数据
- 06.设置并行执行任务数
- 07.设置合理的Reducer个数
- 08.JVM重用
- 09.为什么任务执行的时候只有一个reduce?
- 10.选择使用Tez引擎
- 11.选择使用本地模式
- 12.选择使用严格模式
- 8.说一下hive中sort by、order by、cluster by、distribute by各代表的意思
- 9.hive有哪些方式保存元数据,各有哪些特点?‘
- 10.Hive 中的存储格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
- 11.Hive join过程中大表小表的放置顺序
- 12.hive的两张表关联,使用mapreduce怎么实现?
- 13.hive与spark的区别
- 14.(1 )两条语句的执行结果是否一样?为什么?
1:写个sql,一个表,分区是date,一个键是id,想知道第一天和第二天到这个地方相同的人/第一天的总人数、行转列、列转行、留存率、求成绩行列转换、
2. hive的理解,数据分层中的应用 --》数据库\数据仓库区别
2.1 数据库\数据仓库区别
2.2 数据仓库建模的意义,为什么要对数据仓库分层?
- 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
- 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对
https://blog.csdn.net/qq_39093097/article/details/100126722
版本二:
只有数据模型将数据有序的组织和存储起来之后,大数据才能得到高性能、低成本、高效率、高质量的使用。
1、清晰数据结构:
每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
2、数据血缘追踪:
简单来讲可以这样理解,我们最终给业务诚信的是一能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
3、减少重复开发:
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低存储和计算成本。
4、用空间换时间,把复杂问题简单化。
讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
5、屏蔽原始数据的异常。屏蔽业务的影响,不必改一次业务就需要重新接入数据。
在业务或系统发生变化时,可以保持稳定或很容易扩展,提高数据稳定性和连续性。
扩展内容见:https://blog.csdn.net/qq_22473611/article/details/103278799
2.3 数仓分层
DW :data warehouse 翻译成数据仓库
DW数据分层,由下到上为 DWD,DWB,DWS
DWD:data warehouse detail 细节数据层,有的也称为 ODS层,是业务层与数据仓库的隔离层
DWB:data warehouse base 基础数据层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
DWS:data warehouse service 服务数据层,基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表。
ODS:操作数据存储ODS(Operational Data Store)是数据仓库体系结构中的一个可选部分,ODS具备数据仓库的部分特征和OLTP系统的部分特征,它是**“面向主题的、集成的、当前或接近当前的、不断变化的”数据。**
3. hive底层原理,sql执行过程
3.1 hive执行顺序
hive语句和mysql都可以通过 explain+代码 查看执行计划,这样就可以查看执行顺序
**SQL语句书写顺序:**
select … from … where … group by … having … order by …
**SQL语句执行顺序:**
from … where … group by … having … select … order by …
from … on … join … where … group by … having … select … distinct … order by … limit
**hive语句执行顺序:**
from … where … select … group by … having … order by …
3.2.1 Hive执行流程
hiveSQL转换成MapReduce的执行计划包括如下几个步骤(6个): HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)->优化后的操作树->mapreduce任务树->优化后的mapreduce任务树
1.Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
2.遍历AST Tree, 抽象出查询的基本组成单元QueryBlock。
3.遍历QueryBlock,翻译为执行操作树OperatorTree
4.逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
5.遍历OperatorTree,翻译为MapReduce任务
6.物理层优化器进行MapReduce任务的变换,生成最终的执行计划
详细讲解
如果Join的两张表一张表是临时表,就会生成一个ConditionalTask,在运行期间判断是否使用MapJoin
CommonJoinResolver优化器
CommonJoinResolver优化器就是将CommonJoin转化为MapJoin,转化过程如下:
1.深度优先遍历Task Tree
2.找到JoinOperator,判断左右表数据量大小
3.对与小表 + 大表 => MapJoinTask,对于小/大表 + 中间表 => ConditionalTask
3.2.1 Hive工作原理
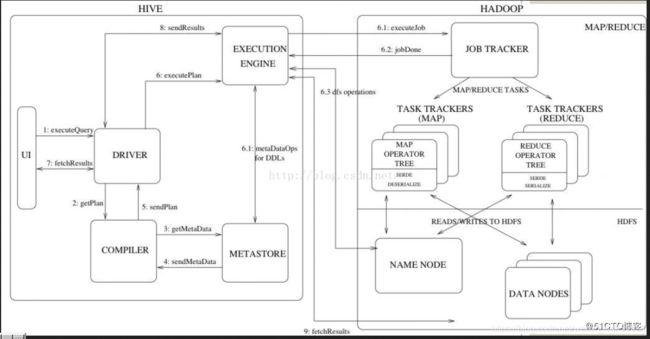 流程大致步骤为:
流程大致步骤为:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划(执行操作树OperatorTree),重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。 - 获取执行的结果。
- 取得并返回执行结果。
转载自添加链接描述
hive的架构设计可学习添加链接描述
5.是否所有的map进行之后才能进行reduce(阿里也问过同样的问题)
- 在同一个job中,reduce会等它所有分配的map执行完后才开始执行,map的输出是reduce的输入,但是reduce可以在map执行占比到某个阀值时就可以开始拷数据了,但真正的执行也得等拉取到所有依赖的map结果后才开始执行。
- 不同的job中,互不影响都是可以并行的。
- Spark通过RDD解决的非常好。
6.Hive优化?SQL优化,参数优化
参考:干货:Hive调优及优化的12种方式(推荐收藏)
https://mp.weixin.qq.com/s?__biz=Mzg3NjIyNjQwMg==&mid=2247484741&idx=1&sn=f9fbdb4f7f18727b0c195a248d1a0bad&chksm=cf343748f843be5e9af681322b309e6a86ffced76b7c0a0c3b32a4b31cf1e0b0a22417d32523&scene=21#wechat_redirect
(mapjoin、列裁剪、分区、分桶、Map数、Reduce数、常用参数等)
答:
针对于Hive内部调优的一些方式(原因和解决方案可查看上面参考文章)
01.请慎重使用COUNT(DISTINCT col) :改成使用Group By 或者 ROW_NUMBER() OVER(PARTITION BY col)方式
02.小文件会造成资源的过度占用以及影响查询效率 :
03.请慎重使用SELECT * :只查所需数据
04.不要在表关联后面加WHERE条件 :谓词下推
05.处理掉字段中带有空值的数据
06.设置并行执行任务数
07.设置合理的Reducer个数
08.JVM重用
09.为什么任务执行的时候只有一个reduce?
10.选使用Tez引擎
11.选择使用本地模式
12.选择使用严格模式
01.请慎重使用COUNT(DISTINCT col)
原因:
distinct会将b列所有的数据保存到内存中,形成一个类似hash的结构,速度是十分的快;但是在大数据背景下,因为b列所有的值都会形成以key值,极有可能发生OOM
解决方案:
所以,可以考虑使用Group By 或者 ROW_NUMBER() OVER(PARTITION BY col)方式代替COUNT(DISTINCT col)
02.小文件会造成资源的过度占用以及影响查询效率
原因:
1)小文件在HDFS中存储本身就会占用过多的内存空间,那么对于MR查询过程中过多的小文件又会造成启动过多的Mapper Task, 每个Mapper都是一个后台线程,会占用JVM的空间
2)在Hive中,动态分区会造成在插入数据过程中,生成过多零碎的小文件(请回忆昨天讲的动态分区的逻辑)
3)不合理的Reducer Task数量的设置也会造成小文件的生成,因为最终Reducer是将数据落地到HDFS中的
4)Hive中分桶表的设置
解决方案:
1)在数据源头HDFS中控制小文件产生的个数,比如
采用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件(常见于在流计算的时候采用Sequencefile格式进行存储)
2)减少reduce的数量(可以使用参数进行控制)
3)慎重使用动态分区,最好在分区中指定分区字段的val值
4)最好数据的校验工作,比如通过脚本方式检测hive表的文件数量,并进行文件合并
5)合并多个文件数据到一个文件中,重新构建表
03.请慎重使用SELECT *
原因:
在大数据量多字段的数据表中,如果使用 SELECT * 方式去查询数据,会造成很多无效数据的处理,会占用程序资源,造成资源的浪费
解决方案:
在查询数据表时,指定所需的待查字段名,而非使用 * 号
04.不要在表关联后面加WHERE条件
原因:
比如以下语句:
SELECT * FROM stu as t
LEFT JOIN course as t1
ON t.id=t2.stu_id
WHERE t.age=18;
请思考上面语句是否具有优化的空间?如何优化?
解决方案:
采用谓词下推的技术,提早进行过滤有可能减少必须在数据库分区之间传递的数据量
谓词下推的解释:
所谓谓词下推就是通过嵌套的方式,将底层查询语句尽量推到数据底层去过滤,这样在上层应用中就可以使用更少的数据量来查询,这种SQL技巧被称为谓词下推(Predicate pushdown)
那么上面语句就可以采用这种方式来处理:
SELECT * FROM (SELECT * FROM stu WHERE age=18) as t LEFT JOIN course AS t1 on t.id=t1.stu_id
05.处理掉字段中带有空值的数据
原因:
一个表内有许多空值时会导致MapReduce过程中,空成为一个key值,对应的会有大量的value值, 而一个key的value会一起到达reduce造成内存不足
解决方式:
1、在查询的时候,过滤掉所有为NULL的数据,比如:
create table res_tbl as
select n.* from
(select * from res where id is not null ) n
left join org_tbl o on n.id = o.id;
2、查询出空值并给其赋上随机数,避免了key值为空(数据倾斜中常用的一种技巧)
create table res_tbl as
select n.* from res n
full join org_tbl o on
case when n.id is null then concat('hive', rand()) else n.id end = o.id;
# coalecse 函数也可以
06.设置并行执行任务数
通过设置参数 hive.exec.parallel 值为 true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果 job 中并行阶段增多,那么集群利用率就会增加。
//打开任务并行执行
set hive.exec.parallel=true;
//同一个 sql 允许最大并行度,默认为 8
set hive.exec.parallel.thread.number=16;
07.设置合理的Reducer个数
原因:
过多的启动和初始化 reduce 也会消耗时间和资源
有多少个Reduer就会有多少个文件产生,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题
解决方案:
Reducer设置的原则:
# 每个Reduce处理的数据默认是256MB
hive.exec.reducers.bytes.per.reducer=256000000
# 每个任务最大的reduce数,默认为1009
hive.exec.reducers.max=1009
# 计算reduce数的公式
N=min(每个任务最大的reduce数,总输入数据量/reduce处理数据量大小)
# 设置Reducer的数量
set mapreduce.job.reduces=n
08.JVM重用
JVM重用是Hadoop中调优参数的内容,该方式对Hive的性能也有很大的帮助,特别对于很难避免小文件的场景或者Task特别多的场景,这类场景大数据书执行时间都很短
Hadood的默认配置通常是使用派生JVM来执行map和reduce任务的,会造成JVM的启动过程比较大的开销,尤其是在执行Job包含有成百上千个task任务的情况。
# JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在hadoop的mapred-site.xml文件中进行设置
<property><name>mapred.job.reuse.jvm.num.tasks</name><value>10</value></property>
09.为什么任务执行的时候只有一个reduce?
原因:
使用了Order by (Order By是会进行全局排序)
直接COUNT(1),没有加GROUP BY,比如:
有笛卡尔积操作
SELECT COUNT(1) FROM tbl WHERE pt=’201909’
解决方案:
避免使用全局排序,可以使用sort by进行局部排序
使用GROUP BY进行统计,不会进行全局排序,比如:
SELECT pt,COUNT(1) FROM tbl WHERE pt=’201909’group by pt;
10.选择使用Tez引擎
Tez: 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
# 设置
hive.execution.engine = tez;
通过上述设置,执行的每个HIVE查询都将利用Tez
当然,也可以选择使用spark作为计算引擎
11.选择使用本地模式
有时候Hive处理的数据量非常小,那么在这种情况下,为查询出发执行任务的时间消耗可能会比实际job的执行时间要长,对于大多数这种情况,hive可以通过本地模式在单节点上处理所有任务,对于小数据量任务可以大大的缩短时间
可以通过
hive.exec.mode.local.auto=true
12.选择使用严格模式
Hive提供了一种严格模式,可以防止用户执行那些可能产生意想不到的不好的影响查询
比如:
对于分区表,除非WHERE语句中含有分区字段过滤条件来限制数据范围,否则不允许执行,也就是说不允许扫描所有分区
使用ORDER BY 语句进行查询是,必须使用LIMIT语句,因为ORDER BY 为了执行排序过程会将所有结果数据分发到同一个reduce中进行处理,强制要求用户添加LIMIT可以防止reducer额外的执行很长时间
# 严格模式的配置:
hive.mapred.mode=strict
8.说一下hive中sort by、order by、cluster by、distribute by各代表的意思
1. order by
对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序),只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
这里跟传统的sql还有一点区别:如果指定了hive.mapred.mode=strict(默认值是nonstrict),这时就必须指定limit来限制输出条数,原因是:所有的数据都会在同一个reducer端进行,数据量大的情况下可能不能出结果,那么在这样的严格模式下,必须指定输出的条数。
2. sort by
Hive中指定了sort by,那么在每个reducer端都会做排序,也就是说保证了局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是有序的,除非只有一个reducer)
好处是:执行了局部排序之后可以为接下去的全局排序提高不少的效率(其实就是做一次归并排序就可以做到全局排序了)。
3. distribute by和sort by一起使用
ditribute by是控制map的输出在reducer是如何划分的,按照指定的字段对数据进行划分输出到不同的reducer中。举个例子,我们有一张表,mid是指这个store所属的商户,money是这个商户的盈利,name是这个store的名字
store:
mid money name
AA 15.0 商店1
AA 20.0 商店2
BB 22.0 商店3
CC 44.0 商店4
执行hive语句:
select mid, money, name from store distribute by mid sort by mid asc, money asc
我们所有的mid相同的数据会被送到同一个reducer去处理,这就是因为指定了distribute by mid,这样的话就可以统计出每个商户中各个商店盈利的排序了(这个肯定是全局有序的,因为相同的商户会放到同一个reducer去处理)。这里需要注意的是distribute by必须要写在sort by之前。
4. cluster by
cluster by的功能就是distribute by和sort by相结合,如下2个语句是等价的:
select mid, money, name from store cluster by mid
select mid, money, name from store distribute by mid sort by mid
如果需要获得与3中语句一样的效果:
select mid, money, name from store cluster by mid sort by money
注意被cluster by指定的列只能是降序,不能指定asc和desc。
转载自
9.hive有哪些方式保存元数据,各有哪些特点?‘
- 内存数据库derby,安装小,但是数据存在内存,不稳定
- mysql数据库,数据存储模式可以自己设置,持久化好,查看方便。
- Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。mysql
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。
10.Hive 中的存储格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
- TextFile:默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
- SequenceFile:SequenceFile是Hadoop API提供的一种二进制文件支持,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。优势是文件和hadoop api中的MapFile是相互兼容的。
- RCfile: 存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
- ORCfile:存储方式:数据按行分块 每块按照列存储。压缩快 快速列存取。效率比rcfile高,是rcfile的改良版本。
- Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
11.Hive join过程中大表小表的放置顺序
在编写带有join操作的代码语句时,应该将条目少的表/子查询放在join操作符的左边。因为在reduce阶段,位于join操作符左边的表的内容会被加载进内存,载入条目较少的表可以有效减少oom(out of memory)即内存溢出。所以对于同一个key来说,对应的value值小的放前,大的放后。------小表放前(小表join大表)
12.hive的两张表关联,使用mapreduce怎么实现?
1)如果其中有一张表为小表,直接使用map端join的方式(map端加载小表)进行聚合。
2)如果两张都是大表,那么采用联合key,联合key的第一个组成部分是join on中的公共字段,第二部分是一个flag,0代表表A,1代表表B,由此让Reduce区分客户信息和订单信息;在Mapper中同时处理两张表的信息,将join on公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce中,然后在Reduce中实现聚合。
转载自:添加链接描述
13.hive与spark的区别
14.(1 )两条语句的执行结果是否一样?为什么?
(2 )假设,数据量很大的情况下,您会选择哪种语句执行?也可以自行开发
--sql 语句 1
select
t1.id,t1.xxx,t2.xxx
from t1 left join t2
on t1.id = t2.id and t1.id < 10
--sql 语句 2
select
t1.id,t1.xxx,t2.xxx
from t1 left join t2
on t1.id = t2.id
where t1.id < 10
答:1)由于left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left 或right表中的记录,full则具有left 和right的特性的并集。
sql 语句 1 中 采用的是left join,所以 on 里的 t1.id <10 对左表 t1 不起作用,结果还是会返回t1 表的所有数据
sql 2 则是先 通过 on 上的条件,将两表关联,在最终关联好的表上,在进行过滤,所以只会返回t1.id < 10 的所有数据
2) 当数据量很大的情况下,基于上述情况我会选择 sql 2 ,但是性能不高,可以采用以下查询(子查询)
select
tmp_t1.id,tmp_t1.xxx,t2.xxx
from
(
select * from t1 where t1.id < 10
) tmp_t1 left join t2
on tmp_t1.id = t2.id