[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第1张图片](http://img.e-com-net.com/image/info8/04541a53fc324999bda51f9317480062.jpg)
文章目录
- Overview
-
- What problem is addressed in the paper?
- Is it a new problem? If so, why does it matter? If not, why does it still matter?
- What is the key to the solution?
- What can we learn from ablation studies?
- Potential fundamental flaws; how this work can be improved?
- 3 Overview
-
-
- NeRF-Art Pipeline
- 3.1 Preliminary on NeRF Scene Representation
-
- 4 TEXT-GUIDED NERF STYLIZATION
-
- 4.1 Trajectory Control w/ Directional CLIP Loss
-
- **absolute directional CLIP loss**
- **relative directional CLIP loss**
- 4.2 Strength Control w/ Glocal Contrastive Learning
-
- contrastive learning strategy
- **final globallocal contrastive loss**
- 4.3 Artifact Suppression w/ Weight Regularization
-
- the weight regularization loss
- 4.4 Training
- 5 EXPERIMENTS
-
- 5.3 Text Evaluation
- 5.4 Comparisons
- 5.6 Ablation Study
-
- Why global-local contrastive learning?
- Why weight regularization?
- 5.7 Generalization Evaluation
- 5.8 Geometry Evaluation
- 6 CONCLUSION
-
- limitations
- 其他信息:
Overview
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第2张图片](http://img.e-com-net.com/image/info8/838f74c1da874f59a3adeeaa695fa6fb.jpg)
What problem is addressed in the paper?
Text-Driven Neural Radiance Fields Stylization.
In this paper, we present NeRF-Art, a text-guided NeRF stylization approach that manipulates the style of a pre-trained NeRF model with a simple text prompt.
Is it a new problem? If so, why does it matter? If not, why does it still matter?
No. Stylizing NeRF, however, remains challenging, especially on simulating a text-guided style with both the appearance and the geometry altered simultaneously (对NeRF进行风格化仍然具有挑战性,特别是在模拟一个同时改变外观和几何的文本引导样式时)
Unlike previous approaches that either lack sufficient geometry deformations and texture details or require meshes to guide the stylization, our method can shift a 3D scene to the target style characterized by desired geometry and appearance variations without any mesh guidance (不同于以前的方法,要么缺乏足够的几何变形和纹理细节,要么需要网格来引导风格化,我们的方法可以将3D场景转移到目标风格,其特征是所需的几何和外观变化,而无需任何网格引导)
What is the key to the solution?
- This is achieved by introducing a novel global-local contrastive learning strategy, combined with the directional constraint to simultaneously control both the trajectory and the strength of the target style. (这是通过引入一种新的全局-局部对比学习策略(global-local contrastive learning strategy),结合方向约束,同时控制目标风格的轨迹和强度来实现的。)
- Moreover, we adopt a weight regularization method to effectively suppress cloudy artifacts and geometry noises which arise easily when the density field is transformed during geometry stylization. (权值正则化方法有效地抑制了几何风格化过程中密度场变换时容易产生的浑浊伪影和几何噪声)
What can we learn from ablation studies?
- By combining both global and local contrastive loss with the directional CLIP, our method successfully achieves uniform stylization with both correct stylization direction and sufficient magnitude.
- The weight regularization loss can suppress cloudy artifacts and geometric noises by encouraging a more concentrated density distribution for stylization.
Potential fundamental flaws; how this work can be improved?
Some text prompts are linguistically ambiguous, like “Digital painting”, which describes a wide range of styles.
3 Overview
NeRF-Art Pipeline
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第3张图片](http://img.e-com-net.com/image/info8/6e32bc1d2a4f47bd9c395f27aecd1c6e.jpg)
方法分为两个阶段:
- reconstruction stages
首先根据目标场景的多视图输入 使用重构损失 L r e c L_{rec} Lrec预训练 NeRF model F r e c F_{rec} Frec - stylization stages
风格化 F r e c − > F s t y F_{rec} -> F_{sty} Frec−>Fsty. 用文本提示 t t g t t_{tgt} ttgt ,结合相对方向损失 L d i r r L_{dir}^r Ldirr 和global-local 对比损失 L c o n g + l L_{con}^{g+l} Lcong+l, 还有权重正则化损失 L r e g L_{reg} Lreg 和感知损失 L p e r L_{per} Lper
3.1 Preliminary on NeRF Scene Representation
Color:

重构损失 L r e c L_{rec} Lrec:
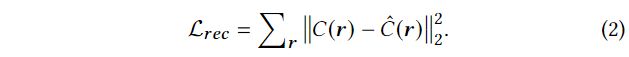
4 TEXT-GUIDED NERF STYLIZATION
风格化的目的是,在保留 F r e c F_{rec} Frec内容的同时,使用文本提示 t t g t t_{tgt} ttgt的风格控制。
挑战:
- preserves the original content from being washed away by the new style,
- reaches the target style with proper strength that satisfies the semantics of the input text prompt,
- maintains cross-view consistency and avoids artifacts in the final NeRF model.
4.1 Trajectory Control w/ Directional CLIP Loss
CLIP有两个encoder:
- images encoder ε ^ i ( ⋅ ) \hat{\varepsilon}_i(\cdot) ε^i(⋅)
- text encoder ε ^ t ( ⋅ ) \hat{\varepsilon}_t(\cdot) ε^t(⋅)
absolute directional CLIP loss
that measures the cosine similarity (⟨·, ·⟩) between the stylized NeRF rendering and the target text prompt (Figure 3(a)) :
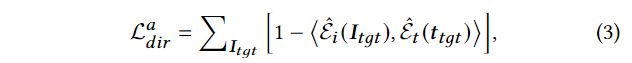
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第4张图片](http://img.e-com-net.com/image/info8/8925486e4f064466bbfa688c6cf6ec30.jpg)
该损失的缺点:
容易使生成器模式崩溃并损害风格化的生成多样性
relative directional CLIP loss
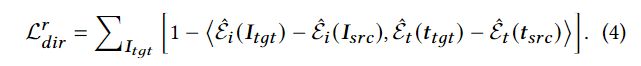
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第5张图片](http://img.e-com-net.com/image/info8/6c8aefb770e84e4b823f54918f956678.jpg)
它可以执行相对的风格化轨迹。然而,在改变预训练的NeRF模型时,它很难保持足够的风格化强度。
4.2 Strength Control w/ Glocal Contrastive Learning
contrastive learning strategy

其中,{ v , v + , v − v,v^+,v- v,v+,v−} 分别是查询样本,正样本,负样本。
全局loss: 将完整的视角图像 I t g t I_{tgt} Itgt作为查询锚点。
![]()
全局对比损失在整个NeRF场景上仍然难以实现充分均匀的风格化,导致某些部分风格化过度,而其他区域风格化不足。
为了实现更充分和平衡的风格化,我们提出了一种互补的局部对比损失:使用随机局部patches P t g t P_{tgt} Ptgt
![]()
final globallocal contrastive loss
![]()
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第6张图片](http://img.e-com-net.com/image/info8/6ab5a7124ef143419aa793dec68f8beb.jpg)
4.3 Artifact Suppression w/ Weight Regularization
我们的方法不仅要改变颜色,还要改变预训练NeRF的密度,以实现外观和几何的联合风格化。然而,允许训练过程来改变密度可能会导致在相机附近产生像云一样的半透明伪影和几何噪声,即使预训练的NeRF是完全干净的。
为了缓解这个问题,
我们采用权重正则化损失来抑制几何噪声,并鼓励更集中的密度分布,更好地类似于现实场景。
the weight regularization loss
![]()
4.4 Training
总体损失:
![]()
感知损失:

5 EXPERIMENTS
5.3 Text Evaluation
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第7张图片](http://img.e-com-net.com/image/info8/c1170f6f2d9545a5bedc8b6166ba776a.jpg)
5.4 Comparisons
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第8张图片](http://img.e-com-net.com/image/info8/c60a59d4a1014cc3a42d478af6d52ea1.jpg)
StyleGAN- nada对真实人脸的友好度较低,因为输入图像必须倒转到StyleGAN潜空间才能进行风格化,这将不可避免地导致一些细节丢失和身份变化。与之不同的是,NeRF-Art不受任何预训练网络的潜在空间的限制,也不需要反转步骤。
文森特·梵高 , “野兽派”
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第9张图片](http://img.e-com-net.com/image/info8/80e23a90454044cc955047706498f513.jpg)
CLIP-NeRF风格化的NeRF使用绝对方向损失,我们只在鼻子和头发上看到了足够的“野兽派”风格的风格化,但男人的脸颊还没有完全风格化。 相比之下,我们设计了一个全局-局部对比学习策略,以确保理想的风格强度。
CLIP-NeRF没有使用权值正则化,其结果可能会出现严重的几何噪声。相比之下,我们的权重正则化通过鼓励更集中的密度分布来抑制几何噪声。
“托尔金精灵”, 野兽派”,蝙蝠侠、 绿巨人
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第10张图片](http://img.e-com-net.com/image/info8/032d16a6d57a4372a3a18124f8be6f2d.jpg)
DreamField也采用绝对方向损失对NeRF进行风格化,不能保证风格化足够均匀。DreamField采用随机背景增强CLIP在前景上的注意力,这需要视图一致的蒙版,而我们的不需要。
我们的方法在详细的布料褶皱、面部属性和细粒度几何变形(如肌肉形状和天线)方面始终优于DreamField。
我们的NeRF-Art通过提出一种对比学习技术来实现充分和均匀的风格化,并设计权重正则化来去除浑浊的伪影和几何噪声,从而优于这些方法。
爱德华•蒙克
皮克斯,伏地魔、 钢铁侠、超人
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第11张图片](http://img.e-com-net.com/image/info8/a6651799ebbe40acb87ca89234705b54.jpg)
受限于网格表示的表达能力,Text2Mesh大多数运行失败,呈现不稳定的风格化结果,导致边缘或表面出现不规则的变形和压痕。
AvatarCLIP采用随机背景增强来引导CLIP聚焦于前景,并防止浮动的工件生成。然而,这个过程需要视图一致的面具,而我们的不需要。
AvatarCLIP仍然不能产生令人满意的纹理和几何细节。相比之下,我们的胡子更细,衣服上的皱纹更细,面部特征也更清晰。
在没有任何网格引导的情况下,使用所提出的对比学习策略,nerf - art实现了更好的风格化
5.6 Ablation Study
Why global-local contrastive learning?
如果没有全局-局部的对比损失,结果会出现风格化不足或不均匀的问题。目标提示分别是“异鬼”和“托尔金精灵”。![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第12张图片](http://img.e-com-net.com/image/info8/37135b6dc7ef456ea741584938447b7a.jpg)
在图9的第三列中的“托尔金精灵”示例中,面部风格化不足,眼睛风格化过度。
通过将全局和局部对比损失与定向CLIP相结合,我们的方法成功地实现了均匀的风格化,风格化方向正确,大小足够
Why weight regularization?
改变NeRF的几何形状可能会导致模糊的伪影。在图11中,我们证明了权重正则化损失可以通过鼓励更集中的密度分布进行程式化来抑制模糊伪影和几何噪声。
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第13张图片](http://img.e-com-net.com/image/info8/6671bc084ab24ddea2721746f450268d.jpg)
在没有权值正则化损失的情况下,观察到角附近的模糊伪影或几何噪声。
5.7 Generalization Evaluation
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第14张图片](http://img.e-com-net.com/image/info8/984510e39f99431896bdddff061f2225.jpg)
5.8 Geometry Evaluation
为了评估几何图形在风格化过程中是否被正确调制,我们在图10中显示了几何图形评估结果。
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第15张图片](http://img.e-com-net.com/image/info8/aac230c61d3947bcb921845d24a65108.jpg)
例如,“伏地魔”画平了女孩的鼻子,“托尔金精灵”画尖了女孩的耳朵,“皮克斯”画圆了女孩的下巴。此外,我们在VolSDF和NeuS上都发现了相同的观察结果。总之,我们得出结论,我们的方法可以正确地调制NeRF的几何形状,以匹配所需的风格。
6 CONCLUSION
在本文中,我们提出了基于CLIP的文本引导的NeRF风格化方法NeRF- art。不同于现有的方法,在风格化过程中需要网格引导或在风格化中捕获不足的几何变形和纹理细节,我们的方法同时调节其几何和外观以匹配所需的风格,并仅通过文本引导显示几何变形和纹理细节的视觉愉悦结果。为了实现这一目标,我们引入了精心设计的方向约束组合来控制风格轨迹,并引入了新颖的全局-局部对比损失来加强适当的风格强度。此外,我们提出了一种权值正则化策略,以消除几何变形中的模糊伪影和几何噪声。在真实人脸和一般场景上的大量实验表明,该方法在风格化质量和视图一致性方面都是有效和鲁棒的。
limitations
一些文本提示在语言上存在歧义,如“数字绘画”,它描述了广泛的风格,包括油画、铅笔素描、3D渲染图像、卡通素描等。这种模糊性可能会混淆CLIP,使最终结果出乎意料,如图13所示。
![[论文解析] NeRF-Art: Text-Driven Neural Radiance Fields Stylization_第16张图片](http://img.e-com-net.com/image/info8/8ef508f3306b450ea85e4d0a519c2d6d.jpg)
如果我们将单词“Mouth”和“Batman”组合在一起作为提示,结果意外地在嘴巴上放了一个蝙蝠形状,这可能不是用户想要的。这些都是值得我们在未来探索的有趣问题。
其他信息:
Project page: https://cassiepython.github.io/nerfart/
text-guidence stylization:
- StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
it is an image-based method and will lead to inconsistencies when applied to stylizing multiple views. - AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
- Text2Mesh: Text-Driven Neural Stylization for Meshes
uses CLIP to guide the stylization of a given 3D mesh by learning a displacement map for geometry deformation and vertex colors for texture stylization - HairCLIP: Design Your Hair by Text and Reference Image
(这些方法仅限于网格输入。相比之下,我们的方法能够在没有任何网格输入的情况下对3D场景进行风格化,具有更好的视觉质量和视图一致性。)