【转载】Faster R-CNN 理解与改进方法
这里写自定义目录标题
-
- 新的改变
- 功能快捷键
- 合理的创建标题,有助于目录的生成
- 如何改变文本的样式
- 插入链接与图片
- 如何插入一段漂亮的代码片
- 生成一个适合你的列表
- 创建一个表格
-
- 设定内容居中、居左、居右
- SmartyPants
- 创建一个自定义列表
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
-
- 导出
- 导入
Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是Object Detection领域的主流框架之一,虽然推出了后续 R-FCN,Mask R-CNN 等改进框架,但基本结构变化不大。同时不乏有SSD,YOLO等骨骼清奇的新作,但精度上依然以Faster R-CNN为最好。对于一般的通用检测问题(例如行人检测,车辆检测,文字检测),只需在ImageNet pre-train model上进行若干次 fine-tune,就能得到非常好的效果。相比于刷pascal voc,Imagenet,coco 等benchmarks,大多数人感兴趣的可能是如何应用到自己的检测目标上。
PS: 一作任少卿大神人挺帅的,回答问题还很耐心。
Faster R-CNN 主要由三个部分组成:(1)基础特征提取网络(2)RPN (Region Proposal Network) (3)Fast-RCNN 。其中RPN和Fast-RCNN共享特征提取卷积层,思路上依旧延续提取proposal + 分类的思想。后人在此框架上,推出了一些更新,也主要是针对以上三点。
1. 更好的特征网络
(1)ResNet,PVANet
ResNet CVPR2016 oral
paper : https://arxiv.org/abs/1512.03385 code :https://github.com/KaimingHe/deep-residual-networks
ResNet 依然是现在最好的基础网络,ResNeXT可能性能上比他好一点,但不是很主流,通过将Faster-RCNN中的VGG16替换成ResNet可以提高performance,不仅是detection,在segmentation,video analysis,recognition等其他领域,使用更深的ResNet都可以得到稳定的提升。
PASCAL VOC 2007 上,通过将VGG-16替换成ResNet-101,mAP从73.2%提高到76.4%, PASACAL 2012 上从70.4%提高到73.8%
值得注意的是,ResNet版本的Faster-RCNN连接方法和Baseline 版本不太一致,具体见任少卿在PAMI 2015中提到 https://arxiv.org/abs/1504.06066。以ResNet-101为例,参考下图方式,其中res5c,atrous + fc4096 + fc4096 + fcn+1 的方式是和baseline版本一致的方式,而res4b22+res5a+res5b+rec5c+fcn+1 是最终采取的方式。这种连接方式使得ResNet-faster-rcnn成为全卷积结构,大大减少模型大小,同时在性能上有一定提升。

在速度方面,ResNet比VGG16更慢,同时需要训练的次数也更多,个人实验结果vgg16 baseline版本训练一轮耗时1.5s,ResNet版本一轮耗时2.0s,同时内存占用量也远远大于VGG16,大概四五倍,没有12G的GPU就不要想用了。
PVANet NIPS2016 workshop
paper:https://arxiv.org/abs/1608.08021 code:https://github.com/sanghoon/pva-faster-rcnn
PVANet是几个韩国人鼓捣出来的一个更深但快速的基础网络,在VOC2012上效果达到82.5%,接近Faster R-CNN + ResNet-101 +++ 和 R-FCN的结果,但是速度上快非常多。实际验证结果,训练和测试速度都比baseline版本快一倍左右。不过,这个网络非常难训练,收敛困难,loss会比较大,选用的训练方法是plateau,在一些比较困难的任务上,大概得好几倍的迭代次数才能达到和VGG16性能相当程度。另外,82.5%这个性能也并非全部得益于PVANet,文章中把anchor数量增加到40多个,还做了一些小改动。个人认为,PVANet的速度广受认可,但性能顶多和VGG16相当,不如ResNet。
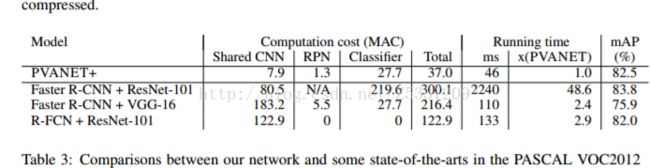
(2) Hierarchy Feature
代表作有HyperNet,同样的思想在SSD和FCN中也有用到,将多层次的卷积网络feature map接在一起
HpyerNet
paper : https://arxiv.org/pdf/1604.00600.pdf code:
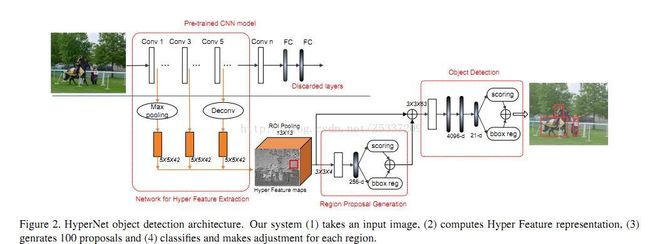
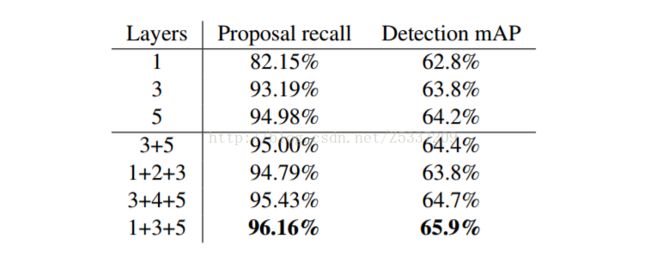
以VGG-16为例,将conv1,conv3,conv5三层接在一起,形成一个Hyper Feature,以Hpyer Feature maps 代替原有的conv5_3,用于RPN和Fast-RCNN。该文章问题出发点针对小目标和定位精度,由于CNN的本身特点,随着层数加深,特征变得越来越抽象和语义,但分辨率却随之下降。Conv5_3 每一个像素点对应的stride = 16 pixel,如果能在conv3_3上做预测,一个像素点对应的stride = 4 pixel,相当于可以获得更好的精度,而conv5_3代表的语义信息对分类有帮助,结合下来,相当于一个定位精度和分类精度的折中。下图是以AlexNet为例,不同层接法在Pascal VOC 2007上的结果,可以看到,1+3+5会取得不错的效果。
2. 更精准更精细的RPN
(1)FPN
(2)more anchors
3. ROI分类方法
(1)PS-ROI-POOLING
R-FCN:
(2)ROI-Align & multi-task benefits
Mask R-CNN :
(3)multi-layer roi-pooling
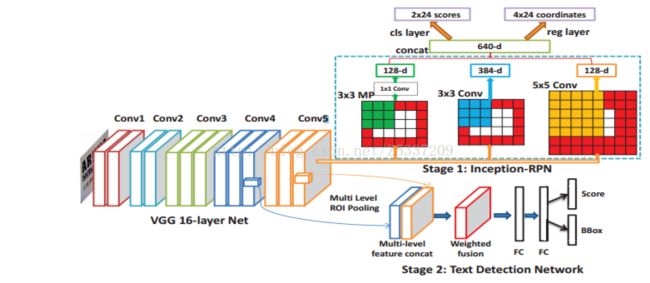
DeepText:
Paper : https://arxiv.org/abs/1605.07314
一篇将Faster RCNN应用在文字检测的文章,里面的contribution比较琐碎,但有一点小改进经验证过相当有效,就是roi分别在conv4,conv5上做roi-pooling,合并后再进行分类。这样基本不增加计算量,又能利用更高分辨率的conv4。
4. sample and post-process
(1)Hard example mining
OHEM
Paper: Code:
(2)GAN
A-Fast-RCNN
Paper CVPR 2017 : https://arxiv.org/abs/1704.03414
这篇文章比较新颖,蹭上了GAN的热点,利用GAN在线产生一些遮挡形变的positive sample。与Fast-RCNN比较,在VOC2007上,mAP增加了2.3%,VOC2012上增加了2.6%。
(3)soft-NMS
Soft-NMS (Improving Object Detection With One Line of Code)
Paper: https://arxiv.org/pdf/1704.04503.pdf code:https://github.com/bharatsingh430/soft-nms
该篇文章主要focus在后处理NMS上,不得不承认,对于很多问题,后处理的方法会对结果产生几个点的影响。虽然我自己试验过,在我的任务上,Soft-NMS得到的结果和NMS完全一致,该后处理方式可能不具备推广性,但是好在尝试起来非常容易,代价也很小,只需要替换一个函数就可以,所以大家不妨可以试验一下。
# 欢迎使用Markdown编辑器你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件或者.html文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
mermaid语法说明 ↩︎
注脚的解释 ↩︎