深度学习之图像
搜/广/推/NLP/CV/数据挖掘怎么选?
CV:CV是计算机视觉,作为算法岗火爆先锋部队,在五年前吃到了一大波红利。算法岗的落地场景我认为在搜索、广告、推荐、自然语言处理、计算机视觉、数据挖掘这六大算法岗中最多的。比如所有人都知道的人脸识别就是其中最大的应用场景,并且已经完全落地了,应用在无人售货机支付、APP登陆、支付宝微信银行等实名验证、交通违法自动识别、罪犯跟踪、门禁等等等等,商汤几乎就是靠着一手人脸识别的产品养活了整个公司。除此之外,CV还有无人驾驶、智能家居、监控、视频内容理解等等场景。但是应用场景多+第一批深度学习红利,带来的结果就是“卷”,七八年前,大量的计算机从业者转行深度学习、人工智能,所以导致人才溢出,供大于求。现在的情况就是,「没有顶会、比赛或者非名校根本进不了大厂」。这并不是一个危言耸听的事实,但是大家也不必过于焦虑,从我身边的例子来看,顶会or比赛or名校,有其一,在基础水平扎实的情况下,就能进大厂,具体怎么准备才能进,我之后会说。但也正是由于CV大大超过其他算法岗的落地场景,在算法岗普遍卷的今天,我反而推荐「以SSP为目标的,还有2年及以上多学校时间」的同学们去学习CV,因为现在“卷”不代表以后也“卷”。因为CV前几年卷,所以这几年大家大有着一起涌入搜广推的趋势,CV反而没想象中的卷。我身边就有不少非科班的同学去了大厂的CV岗(PS:他们有实习、名校、竞赛的背景其一)。当然,如果你马上就要准备春招了,手头只有CV的相关项目(相信大部分同学都是这个状态),那在学校还可以的情况下,冲一冲CV岗的实习也不是不可以,春招可比秋招简单多了,一段CV项目+不错的学校或者不错的比赛,足以进入任何一家大厂了,当然要是目标核心部门那要求还要更高一点。「总结:我认为CV的未来是光明的,人才需求是最多的,核心依据是它海量的应用场景,以及人才的流向分布,所以,如果你是刚进实验室的小白,想学CV又不敢学,大胆的去学,竞争比你想象的小;如果你是没有论文,但是名校毕业或手握项目和竞赛,面临春招不知道要不要找CV岗的应届生,大胆去找,竞争比你想象的小。」
NLP:NLP是以上6个算法岗中最有挑战性的岗位,因为在CV中,视频可以分割为一帧一帧的图像,图像又可以分割为一个一个的像素点,像素点又是有限的,这很适合计算机去解析。但是文字不一样,且不说全世界有上百种文字,每种文字又有亿万种变换,更别说中文这种博大精深的语言了。就目前来看,NLP成功落地的场景也只有机器翻译了(搜索我们在下文再提),所谓的对话、问答等还远远没有达到实际应用的地步,跟CV的落地比起来差远了。所以说实话,「短期内我看不到NLP的前景,大多都是实验室的玩具,发paper的工具罢了」。而在企业中,NLP也没有太多的应用场景,大部分都是解析文本来给下游任务做特征的。从我的经历来看,比如爱奇艺这类视频APP做NLP的有一部分是解析弹幕、评论等给用户画像做特征;腾讯广告中的NLP有一部分就是解析文本,给广告的推荐做特征、给用户打标签等等;百度小度中的NLP是跟语音、搜索挂钩的;京东的NLP有一部分是做推荐理由的。所以,纯的NLP岗位是真的不多,但做研究另当别论,如果你是博士励志进入大厂的研究所,那么NLP绝对是一篇蓝海,还有很多方向值得去探索。但是如果你是去业务部门干活的,那NLP的坑位确实不多。「总结:我认为NLP是有极大挑战的,适合做研究的,因为很多问题都没解决;不适合做业务的,因为坑位少」
数据挖掘:与NLP关联比较大的岗位是数据挖掘,但是很多公司其实不区分数据挖掘和NLP。在腾讯,知识图谱就归于数据挖掘方向。数据挖掘是最原始的算法岗,其初始的含义是从数据中挖掘信息的岗位。由于深度学习的崛起,数据挖掘慢慢的就被数据分析、NLP等等岗位所替代。所以其实这个岗位大家不用单独的去关注和学习,数据挖掘算法和机器学习算法大部分是重合的,只有小部分是数据挖掘所独有的,比如Apriori等等。同理,在公司中,数据挖掘也更多的是和业务绑定的岗位,不用特意去准备或者投递。如果某个公司真的有数据挖掘、机器学习、推荐算法,三个不同的岗位,建议仔细看招聘JD,当然JD主要看什么呢?看部门,和负责的产品,这才是真实的,其他的都是假的。「总结:不用单独考虑这个岗位」
搜索:搜索算法也是和NLP密切相关的一个算法岗位,很多我认识的做NLP的同学都转向搜索算法了。现在搜索算法的需求很大,任何APP都有搜索的需求,但同样也很卷。大家想想,每个APP搜索的入口也就一两个吧,也就一两个团队在做,跟你竞争的都是NLP的大佬,什么研究对话的、研究问答的、研究翻译的,论文一套一套的,怎么打得过他们?「总结:如果你是NLP出身,又担心NLP坑位不好找的,就去做搜索」
推荐:推荐算法前几年是最容易就业的,因为推荐是直接跟钱挂钩的,最接近公司营收的环节,岗位相对比较多。更重要的是在CV之后,深度学习的一波红利也被推荐吃到了,大量的业务靠着深度学习的推荐指标起飞了一把,比如抖音和淘宝。但是推荐现在也面临一些问题,「一是政策,这个大家可以自行去了解一下;二是大公司的推荐很多都做到头了,很难有新的东西出来,指标很难提升,工程师的压力都很大;三是推荐这个岗位是和互联网的发展直接挂钩的,在增量时代推荐的人才当然是越多越好,但现在已经是存量了,互联网的发展慢慢陷入了瓶颈,推荐的日子也不好过」。我对推荐的未来持悲观态度,如果你是正在寻找方向的学生,那我是不推荐这个领域的,因为等你找工作了必然是2年之后的事情了,那时候互联网是什么情况真的不好说。对于今年春招的同学来说,你还是可以来吃一波最后的红利的,推荐,无论如何,在两年内,都会是最好找工作的算法岗之一,另一个是广告。另外,推荐门槛也低,基本有一段大厂实习+不差的学校就能通吃所有公司了(非核心部门)。「总结:如果你不着急就业,别学推荐,因为推荐发展一般;如果你急着找工作,那仍然可以来尝试一下」
广告:每每当人们提到推荐的时候,必然绕不开广告,这两者的技术栈很像很像很像。相信也有很多同学在犹豫投推荐好呢还是投广告好。在我当初纠结的时候,有一个前辈曾经告诉我,应届生首选广告,因为广告目标简单,无非点击和转化,比较纯粹,不像推荐要优化点击次日留存下拉概率浏览深度停留时长等等一系列指标。也正是如此,在广告中模型做的更深入,不用去考虑其他有的没的的东西,但也正是如此,广告的模型更卷,挠破头改模型,做无可做。前辈说的话,我不置可否,但是毋庸置疑的是,广告的场景比推荐更广,因为互联网公司就是靠广告赚钱的,每个公司都有广告团队,而且还不小,而且还很核心。可以说,你能进大厂广告部门,基本跳槽不愁了。但是有利就有弊,靠近盈利中心,就意味着压力大,能提指标固然能步步高升,不能提指标,那就很痛苦了。「总结:广告坑位多,部门核心,优先级高于推荐,但是卷、累、压力大」
说了那么多,最后做个总结吧,「看好CV的业务发展,看好NLP的研究发展;至于搜广推,如果你还不知道怎么选,那么建议看公司选职位,比如百度一定是搜索>广告和推荐,腾讯一定是广告>搜索和推荐,小红书一定是推荐>广告和搜索」,当然再细一点也可以看部门,这里就不再多做举例。
图像识别CNN
0.各种卷积操作
参考:https://blog.csdn.net/weixin_43624538/article/details/96917113
1.Alexnet
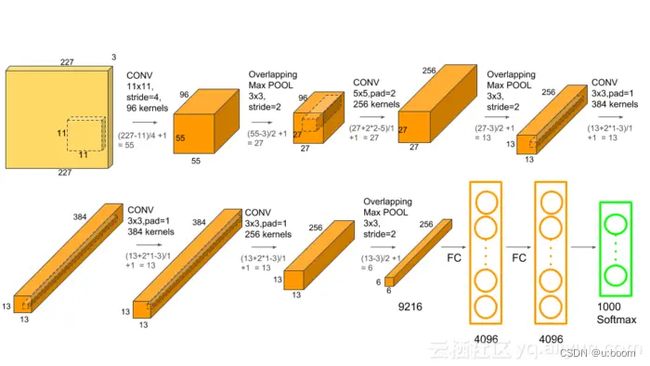
1.1 论文:ImageNet Classification with Deep Convolutional Neural Networks
1.2 过程
输入Input的图像规格: 224X224X3(RGB图像),实际上会经过预处理变为:227X227X3
96个大小规格为11X11X3的卷积核(步长为4),进行特征提取,卷积后的数据经过Relu激励变为:55X55X96 [(227-11)/4+1=55]
降采样pool1的核:3X3 步长:2,通过最大池化进行降采样之后的数据为27X27X96
256个5X5大小的卷积核(步长1)对27X27X96个特征图,进行进一步提取特征,然后进行relu操作,27X27X256
降采样pool2的核:3X3 步长:2,pool2(池化层)降采样之后的数据为13X13X256
384个卷积核(3X3,步长为1),没有降采样,13X13X384
256个卷积核(3X3,步长为1),没有降采样,13X13X256
降采样操作pool3的卷积核:3X3 步长:2,pool3(池化层)降采样之后的数据为6X6X256
两层全联接,并进行dropout,4096X1
最后输出层全联接,1000X1
1.3 经验
Alexnet中采用的是最大池化,是为了避免平均池化的模糊化效果,从而保留最显著的特征
AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性,减少了信息的丢失。
https://www.cnblogs.com/wangguchangqing/p/10333370.html
https://www.jianshu.com/p/00a53eb5f4b3
https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
2.VGG
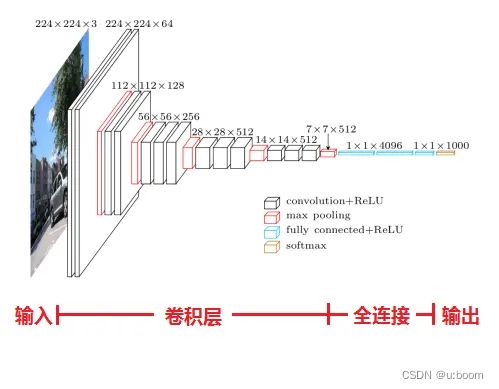
2.0 论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深层卷积网络的大规模图像识别)
2.1 加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
输入224x224x3的图片,预处理(preprocession)时计算出三个通道的平均值,在每个像素上减去平均值(处理后迭代更少,更快收敛)。
经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
作2x2的max pooling池化,尺寸变为56x56x128
经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
作2x2的max pooling池化,尺寸变为28x28x256
经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
作2x2的max pooling池化,尺寸变为14x14x512
经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
作2x2的max pooling池化,尺寸变为7x7x512
与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
通过softmax输出1000个预测结果
2.2 经验
1、LRN层无性能增益(A-LRN)
2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)
3、多个小卷积核比单个大卷积核性能好(B)
最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
2.3 VGG与Alexnet相比,具有如下改进几点:
去掉了LRN层,作者发现深度网络中LRN的作用并不明显,干脆取消了
采用更小的卷积核-3x3,Alexnet中使用了更大的卷积核,比如有7x7的,因此VGG相对于Alexnet而言,参数量更少
池化核变小,VGG中的池化核是2x2,stride为2,Alexnet池化核是3x3,步长为2
2.4 问题
虽然 VGGNet 减少了卷积层参数,但实际上其参数空间比 AlexNet 大,其中绝大多数的参数都是来自于第一个全连接层,耗费更多计算资源
3.Resnet
3.1 论文:Deep Residual Learning for Imafge Recognition
3.2 模型

其中实线箭头的处理——即本文核心:残差块:
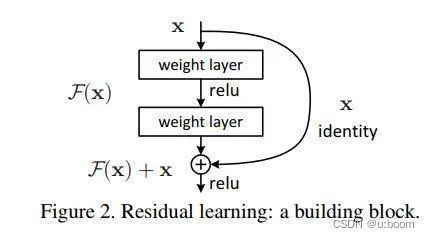
思想:确保输出的结果至少不会比输入更差。
3.3 衍生网络:Inception-Resnet,ResNeXt
图像识别的常用处理方法
1.特征图是否要尽可能保留RGB通道信息
2.通过权值共享来节约空间和提高效率(理解如何做到的)
3.合适的激励函数(如RELU,softmax),来确保特征图的值范围在合理范围之内。越深的网络反向梯度越难传导。
4.LRN处理
5.池化
6.dropout随机从丢掉一些节点信息。经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。
7.数据增强:先resize,然后random_crop,flip操作(裁剪,镜像,标准化)
8.正则项
9.交叉熵,欧式距离,最小化方法?
10.学习率、batch_size、step定义与选择、动态调整
11.动量以加快学习速度,tf.train.momentumOptimizer
- fine-tune 训练
深度学习的图像网络处理思路
增加图像分类的精度很重要的一个方面就是增加网络学习特征的质量。
1.增加深度——1000层残差网络
2.增加宽度——Wide Residual Networks
增大宽度可以增加各种深度的残差模型的性能
只要参数的数量可以接受,宽度和深度的增加就可以使性能提升。
在相同的参数数量下,更深的模型并不比更宽的模型有更好的性能。
目标检测
1.传统方法
Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化。
1.DPM:DPM的本质就是弹簧形变模型,参考:https://blog.csdn.net/ttransposition/article/details/12966521
2.提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案
0.生成候选区域的方法:
objectness
selective search
category-independen object proposals
constrained parametric min-cuts(CPMC)
multi-scale combinatorial grouping
Ciresan
1.R-CNN(Selective Search + CNN + SVM)参考https://blog.csdn.net/briblue/article/details/82012575
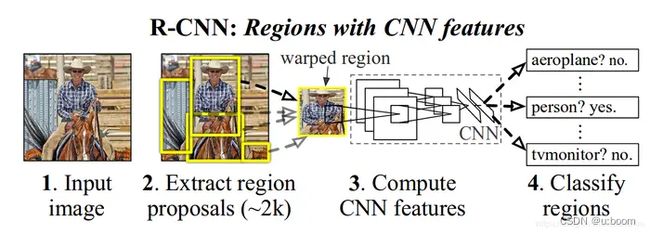
算法思路
给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
对于每个区域利用 CNN 抽取一个固定长度的特征向量。
再对每个区域利用 SVM 进行目标分类。
测试:计算 IoU 指标,采取非极大性抑制,以最高分的区域为基础,剔除掉那些重叠位置的区域。
2.Fast R-CNN(Selective Search + CNN + ROI)https://www.jianshu.com/p/26ca6f6bd1a1
https://www.jianshu.com/p/fbbb21e1e390
相比R-CNN最大的区别,在于RoI池化层和全连接层中目标分类与检测框回归微调的统一。
在推荐区域之前,先对图像执行特征提取工作,通过这种办法,后面只用对整个图像使用一个 CNN(之前的 R-CNN 网络需要在 2000 个重叠的区域上分别运行 2000 个 CNN)。
将支持向量机替换成了一个 softmax 层,这种变化并没有创建新的模型,而是将神经网络进行了扩展以用于预测工作。
3.Faster R-CNN(RPN + CNN + ROI)
用一个快速神经网络代替了之前慢速的选择搜索算法(selective search algorithm)。具体而言,它引入了一个 region proposal 网络(RPN)。
在最后卷积得到的特征图上,使用一个 3x3 的窗口在特征图上滑动,然后将其映射到一个更低的维度上(如 256 维),
在每个滑动窗口的位置上,RPN 都可以基于 k 个固定比例的 anchor box(默认的边界框)生成多个可能的区域。
每个 region proposal 都由两部分组成:a)该区域的 objectness 分数。b)4 个表征该区域边界框的坐标。
4.Mask rcnn
何恺明基于以往的Faster Rcnn架构提出的新的卷积网络.
掩码
https://blog.csdn.net/weixin_43624538/article/details/88734864
5.R-FCN(RPN+)论文https://www.jianshu.com/p/e90692259530
通过最大化共享计算来提升速度。
位置敏感ROI池化层——图像分类:要求图像具有平移不变性(translation invariance)目标检测:要求图像具有位置敏感性(translation variance)
https://blog.csdn.net/qq_30622831/article/details/81455550
6.SPPNet(ROI Pooling)Spatial Pyramid Pooling(空间金字塔池化)
论文:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition
7.MobileNet
3.基于深度学习的回归方法
1.YOLO
不再需要中间的region proposal找目标,直接回归便完成了位置和类别的判定。
没有了Region Proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
https://www.jianshu.com/p/13ec2aa50c12
2.SSD(Single-Shot Detector)
SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制
3.DenseBox
4.cornerNet
基于关键点的实时且精度高的目标检测算法
参考:https://my.oschina.net/u/876354/blog/1634322
https://www.jiqizhixin.com/articles/2017-09-18-7
https://cloud.tencent.com/developer/news/281788