深度学习训练营之识别宝可梦人物和角色
深度学习训练营之识别宝可梦人物和角色
- 原文链接
- 环境介绍
- 前置工作
-
- 设置GPU
- 数据加载
- 数据查看
- 数据预处理
-
- 加载数据
- 可视化数据
- 检查数据
- 配置数据集
-
- `prefetch()`功能详细介绍:
- 调用官方的网络的模型
- 模型训练
-
- 官方模型调用
- 设置动态学习率
- 模型训练
- 模型评估
- 结果分析
- 参考链接
原文链接
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:365天深度学习训练营-第P1周:实现mnist手写数字识别
- 原作者:K同学啊|接辅导、项目定制
环境介绍
- 语言环境:Python3.9.13
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2
前置工作
设置GPU
如果
# K同学啊深度学习练习
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)
数据加载
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = pd.read_csv('SH600519.csv') # 读取股票文件
调整数据集所在的位置
在这里插入图片描述
将运行的代码和需要运行的数据集放在同一个文件夹,方便数据的导入

data_dir = "016_Pokemon"
data_dir = pathlib.Path(data_dir)
数据查看
数据集一共分为10个角色,每个角色都会有单独的自带的文件夹保存图片
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
图片总数为: 219
数据预处理
加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
这三行代码主要是先对图片进行预处理,设定图片的高度和宽度还有batch_size的大小
batch_size = 8
img_height = 224
img_width = 224
这三行代码划分数据集,train_ds,val_ds
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)

通过class_names输出数据集的标签,标签按照字母顺序对应于目录名称
class_names = train_ds.class_names
print(class_names)
![]()
可视化数据
plt.figure(figsize=(20, 10)) # 图形的宽为10高为5
plt.suptitle("数据展示")
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
ax.patch.set_facecolor('yellow')
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break

Image_batch是形状的张量(8,224,224,3)。这是一批形状224x224x3的8张图片(最后一维指的是彩色通道RGB)。Label_batch是形状(8,)的张量,这些标签对应32张图片
配置数据集
- shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
- prefetch():预取数据,加速运行
prefetch()功能详细介绍:
CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态
使用该函数的作用就在于尽可能的提高CPU等的使用性能,提高模型训练时候的速度

使用该函数可以减少空闲时间

cache():将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
调用官方的网络的模型
在训练模型当中,选取不同的训练方法都会有不同的训练结果,但是要进行模型的比较的时候,难道要一个一个的训练,一个一个模型进行构建吗?这样实在是太费时间了,看到K同学所分享的内容,我看到了,
我们可以使用官方所给出的方法对模型进行直接的调用.
这样的一个神器就叫做 tf.keras.applications
简单的讲 tf.keras.applications 就是它把我们常用的一些模型,比如VGG-16等进行了封装,我假设想调用某一个模型时(例如:VGG-16),直接调用函数接口就OK了,无需再自己进行构建,当然在这里还是希望我们可以取了解一些模型具体的代码书写过程,这样对我们后期学期有很大的帮助(这话是将给我自己听的)
tf.keras.applications 目前支持的模型及该模型的性能参数如下(知道有这些内容就好):

TOP-5准确率可以简单的理解为在正确的标签(分类)在这5个类别里之中的概率
这是官网当中模型的相关介绍
常用的三个参数解释如下:
- include_top:是否包括网络顶部的 3 个全连接层。
- weights:默认不加载权重文件,"imagenet"加载官方权重文件,或者输入自己的权重文件路径。
- classes:分类图像的类别数
这三个参数可以根据需要进行修改
常见的其他接口有
- tf.keras.applications.xception.Xception()
- tf.keras.applications.vgg16.VGG16()
- tf.keras.applications.vgg19.VGG19()
- tf.keras.applications.resnet50.ResNet50()
- tf.keras.applications.inception_v3.InceptionV3()
- tf.keras.applications.inception_resnet_v2.InceptionResNetV2()
- tf.keras.applications.mobilenet.MobileNet()
- tf.keras.applications.mobilenet_v2.MobileNetV2()
- tf.keras.applications.densenet.DenseNet121()
- tf.keras.applications.densenet.DenseNet169()
- tf.keras.applications.densenet.DenseNet201()
- tf.keras.applications.nasnet.NASNetMobile()
- tf.keras.applications.nasnet.NASNetLarge()
这方面的内容还挺有意思,直接通过调用就可以进行训练
模型训练
官方模型调用
K同学啊在调用的过程当中使用的Densenet121的方法,我这里尝试使用其他接口,使用tf.keras.applications.nasnet.NASNetMobile()进行模型的预测,其他内容不变
model = tf.keras.applications.nasnet.NASNetMobile(weights='imagenet')
model.summary()

设置动态学习率
设置动态学习率也就相对于是说每一次模型优化之后,我都会调整我的学习率,这样的好处就在于,使得学习率的调整更加合理,及可以避免学习率过大而导致的结果不收敛,以及避免学习率过小时进入局部最优解,常见的就有RMSProp
这里使用的是指数衰减学习率导入到优化器当中
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=5, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
模型训练
model.compile(optimizer=optimizer,
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
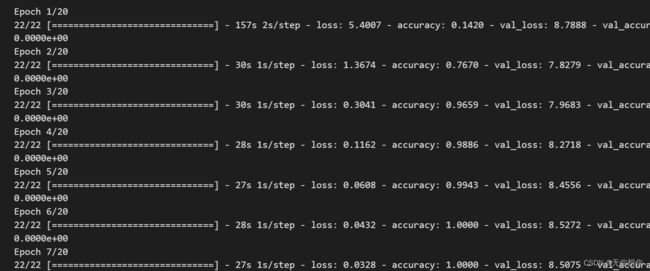
模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
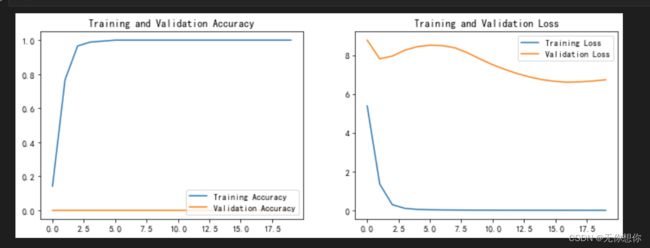
结果分析
不难看出,这里的运行出来的结果很不理想,说明该方法其实并不适合对于宝可梦角色的预测当中,可能的原因在于模型动态学习率的方法并不适合,毕竟是指数倍的计算,计算量比较大,nasnet本身是一个通过堆叠 网络单元的形式将其迁移到任意分类任务,乃至任意类型的任务中,还有就是nasnet本身更加适合用于强化学习?这方面不是很了解,可以后续进行学习
参考链接
tf.keras.applications API地址