grep的用法
命令介绍
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
关于egrep:在此命令后跟的模板可以进行正则表达式的匹配
egrep = grep -E:扩展的正则表达式 (除了< , > , \b 使用其他正则都可以去掉\)
命令参数
常用参数已加粗
- -A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。
- -C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -c:统计匹配的行数
- -e :实现多个选项间的逻辑or 关系
- -E:扩展的正则表达式
- -f FILE:从FILE获取PATTERN匹配
- -F :相当于fgrep
- -i --ignore-case #忽略字符大小写的差别。
- -n:显示匹配的行号
- -o:仅显示匹配到的字符串
- -q: 静默模式,不输出任何信息
- -s:不显示错误信息。
- -v:显示不被pattern 匹配到的行,相当于[^] 反向匹配
- -w :匹配 整个单词
应用示例
实例1—参数使用
#1.查看源文本
[root@blackstone test]# cat grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
asczxcasBCXSDASCZADAD
SADASCZXCASD
#2.过滤包含字符b的行以及下两行
[root@blackstone test]# grep -A2 b grep_basic
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
asczxcasBCXSDASCZADAD
#3.过滤包含字符b的行以及前1行
[root@blackstone test]# grep -B1 b grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
#4.过滤包含b的行以及其上下两行
[root@blackstone test]# grep -C1 b grep_basic
aaaaaaaa
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
#5.统计匹配的行数
[root@blackstone test]# grep -c aaa grep_basic
2
#6.使用e添加或或关系匹配的条目,即就是同时对AAA或者bbb进行筛选
[root@blackstone test]# grep -e AAA -e bbb grep_basic
bbbbbbbbbbbbbb
AAAAAAAaaaaaa
#7.筛选的同时显示行号并忽略大小写
[root@blackstone test]# grep -in b grep_basic
2:bbbbbbbbbbbbbb
4:asczxcasBCXSDASCZADAD
#8.筛选过程仅显示匹配到的部分
[root@blackstone test]# grep -o ADA grep_basic
ADA
ADA
#9.无输出筛选---主要用于shell编程中对返回值的判断确认信息的存在性
[root@blackstone test]# grep -q aa grep_basic
#10.进行取反显示,即就是匹配到的行不显示
[root@blackstone test]# grep -v aa grep_basic
bbbbbbbbbbbbbb
asczxcasBCXSDASCZADAD
SADASCZXCASD
#11.严格匹配字符,要求行内字符必须和模式完全一致
[root@blackstone test]# grep -w aa grep_basic
[root@blackstone test]# grep -w aaa grep_basic
[root@blackstone test]# grep -w aaaaaaaa grep_basic
aaaaaaaa
#12.使用文件进行匹配---通过以下的操作我们可以得知,文件内容匹配是默认的匹配方式
[root@blackstone test]# cat a.txt
aaaaaaaa
[root@blackstone test]# grep -f a.txt grep_basic
aaaaaaaa
[root@blackstone test]# vim a.txt
[root@blackstone test]# grep -f a.txt grep_basic
aaaaaaaa
AAAAAAAaaaaaa
实例2—正则使用
正则表达式在字符匹配中当然是不可或缺的存在,其实正则的概念很好理解,通过一系列符号去抓取一类文本的核心特征,从而对某一类文本进行特殊的操作。那么任意一个字符串其实都是可以通过正则进行表示的,单一字符+字符的出现次数就可以表示这个字符串的特征了。
1.元字符匹配
(1)格式
- . 匹配任意单个字符,不能匹配空行
- [] 匹配指定范围内的任意单个字符
- [^] 取反
- [:alnum:] 或 [0-9a-zA-Z]
- [:alpha:] 或 [a-zA-Z]
- [:upper:] 或 [A-Z]
- [:lower:] 或 [a-z]
- [:blank:] 空白字符(空格和制表符)
- [:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
- [:cntrl:] 不可打印的控制字符(退格、删除、警铃…)
- [:digit:] 十进制数字 或[0-9]
- [:xdigit:]十六进制数字
- [:graph:] 可打印的非空白字符
- [:print:] 可打印字符
- [:punct:] 标点符号
(2)应用示例
#查看源字符文件
[root@blackstone test]# cat grep_regular
abxc
123456
//a
[]
,.;'[]
#1.使用.匹配字符,由于.匹配任意字符,故可以到文本中的文字均被标红
[root@blackstone test]# grep . grep_regular
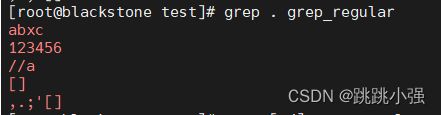
#2.打印出除了abc以外的所有字符
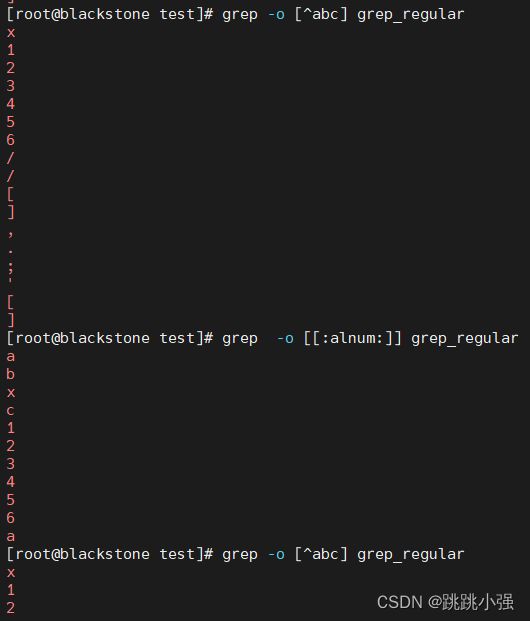
[root@blackstone test]# grep -o [^abc] grep_regular
#3.过滤显示文本中所有的[0-9a-zA-Z]范围的字符
[root@blackstone test]# grep -o [[:alnum:]] grep_regular
#4.过滤显示出文本中所有的标点符号
[root@blackstone test]# grep -o [[:punct:]] grep_regular
2.字符出现次数
(1)格式
- ***** 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
- .* 任意前面长度的任意字符,不包括0次
- ? 匹配其前面的字符0 或 1次
- + 匹配其前面的字符至少1次
- {n} 匹配前面的字符n次
- {m,n} 匹配前面的字符至少m 次,至多n次
- {,n} 匹配前面的字符至多n次
- {n,} 匹配前面的字符至少n次
(2)示例
#查看原文本
[root@blackstone test]# cat grep_01
ggle
gogle
google
gooooooooooooooooooooooooooogle
gagle
#1.过滤字符中的o出现次数为0次或多次
[root@blackstone test]# grep "g[o]*gle" grep_01
ggle
gogle
google
gooooooooooooooooooooooooooogle
#2.过滤字符o的次数大于等于1
[root@blackstone test]# grep "g[o].*gle" grep_01
gogle
google
gooooooooooooooooooooooooooogle
#3.问号匹配0/1次前置字符,这里由于在grep中执行故需要加\进行转义
[root@blackstone test]# grep "g[o]\?gle" grep_01
ggle
gogle
#4.使用+匹配前置字符大于等于1次,同样使用\进行转义
[root@blackstone test]# grep "g[o]\+gle" grep_01
gogle
google
gooooooooooooooooooooooooooogle
#5.匹配次数区间为[1,2]其中{}符号添加\进行转义
[root@blackstone test]# grep "g[o]\{1,2\}gle" grep_01
gogle
google
#6.使用-E或者egrep直接支持正则进行匹配
[root@blackstone test]# grep -E "g[o]{10,}gle" grep_01
gooooooooooooooooooooooooooogle
[root@blackstone test]# egrep "g[o]{10,}gle" grep_01
gooooooooooooooooooooooooooogle
[root@blackstone test]# egrep "g[o]{,10}gle" grep_01
ggle
gogle
google
3.位置界定符号
(1)格式
- ^ 行首锚定,用于模式的最左侧
- $ 行尾锚定,用于模式的最右侧
^PATTERN$用于模式匹配整行^$空行^[[:space:]].*$空白行- < 或 \b 词首锚定,用于单词模式的左侧
- > 或 \b 词尾锚定;用于单词模式的右侧
(2)演示
[root@blackstone test]# cat grep_02
aaa
bbbbbb
aczxcsdasdasfascac
#1.匹配以a开头的行
[root@blackstone test]# grep ^a grep_02
aaa
aczxcsdasdasfascac
#2.匹配以b结尾的行
[root@blackstone test]# grep b$ grep_02
bbbbbb
#3.匹配以a开头以c结尾的行
[root@blackstone test]# grep "^\$" grep_02
aczxcsdasdasfascac
#4.匹配空行
[root@blackstone test]# grep ^$ grep_02
空行1
空行2
空行3
关于空白行的匹配:在文档内部一致敲空格代替输入
[root@blackstone test]# grep ^[[:space:]].*$ grep_02

4.分组与向后引用
(1)格式
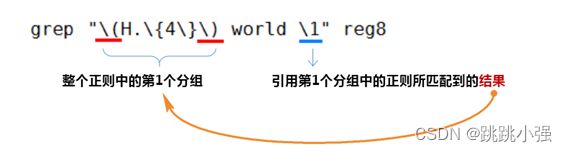
分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理。分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, …
向后引用: 引用前面的分组括号中的模式所匹配字符,而非模式本身
- \1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
- \2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
- & 表示前面的分组中所有字符
工作流程:前面匹配的内容可以通过进行一个()进行整合,定义为\数字在之后的正则中可以进行引用,以简化正则的重复书写
(2)简单应用示例
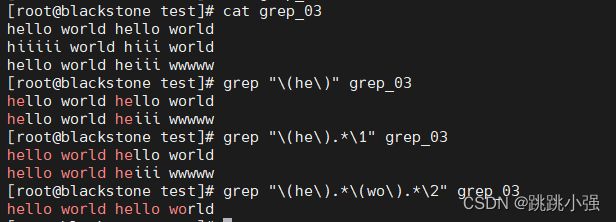
[root@blackstone test]# cat grep_03
hello world hello world
hiiiii world hiii world
hello world heiii wwwww
#1.匹配含有he的行
[root@blackstone test]# grep "\(he\)" grep_03
#2.对he结果进行分组,在后续的匹配中进行引用,形成包夹型的匹配字符
[root@blackstone test]# grep "\(he\).*\1" grep_03
#3.设置多个分组并向后引用第二组进行字符匹配
[root@blackstone test]# grep "\(he\).*\(wo\).*\2" grep_03
建议:个人觉得这个分组引用一定程度上可以减小正则的书写长度,但是还有有些过于费解,掌握前三个就可以了。