「计算机组成原理」计算机系统概述
文章目录
- 一、计算机发展历程
-
- 1.1 什么是计算机系统
- 1.2 硬件的发展
-
- 1.2.1 硬件发展
- 1.2.2 摩尔定律
- 1.3 软件的发展
- 1.4 目前的发展趋势
- 二、计算机系统的多级层次结构
-
- 2.1 编程语言的三个等级
- 2.2 计算机系统层次结构
- 三、计算机硬件的基本组成
-
- 3.1 冯诺依曼结构
- 3.2 现代计算机结构
- 四、计算机各硬件的工作原理
-
- 4.1 主存
- 4.2 运算器
- 4.3 控制器
- 4.4 工作过程
- 五、计算机性能指标
-
- 5.1 存储器的容量
- 5.2 CPU
- 5.3 系统整体性能指标
- 5.4 区分常用单位
- 5.5 小结
一、计算机发展历程
1.1 什么是计算机系统
计算机系统=硬件+软件,软件又分为系统软件和应用软件。
系统软件如操作系统、数据库管理系统DBMS、标准程序库、网络软件、语言处理程序、服务程序等。
应用软件就是我们平常经常使用的如微信、IDEA等。
1.2 硬件的发展
1.2.1 硬件发展
硬件的发展大体可以划分为4个时代,分别是电子管时代、晶体管时代、中小规模集成电路时代和大规模超大规模集成电路时代。划分不同时代的主要依据是所使用的逻辑元件的不同。
- 电子管时代1946~1957
电子管时代使用的逻辑元件是电子管,此时的计算机不仅体积超大,而且耗电量巨大。 - 晶体管时代1958~1964
晶体管时代使用的逻辑元件是晶体管,此时的计算机体积和功耗都降低了。 - 中小规模集成电路时代1964~1971
中小规模集成电路时代使用的逻辑元件是中小规模集成电路,该逻辑元件将大量的晶体管集成在了基片上。 - 大规模超大规模集成电路时代1972~至今
大规模超大规模集成电路时代使用的逻辑元件是大规模和超大规模集成电路,如苹果的A16芯片采用4nm工艺,集成了近160亿晶体管。
一个小故事:
1947年,贝尔实验室发明了晶体管(C语言和UNIX也诞生于贝尔实验室),核心人物是William Shockley(威廉·肖克利),他也被称为晶体管之父。1955年他离开了贝尔实验室,在硅谷创建了肖克利实验室股份有限公司。但是他个人对于管理公司的方式与公司内部不和,因此公司内部的8名主要人员于1957年离开了公司创办了仙童半导体公司,这8个人也被肖克利叫做八叛徒(traitorous eight)。1959年仙童半导体公司发明了第一块集成电路。1968年,摩尔等人离开仙童创立了Intel。1969年,仙童销售部负责人桑德斯离开仙童创立了AMD。
1.2.2 摩尔定律
摩尔定律的大致内容是:集成电路上可以容纳的晶体管数目在大约每经过18个月到24个月便会增加一倍。换言之,处理器的性能大约每两年翻一倍,同时价格下降为之前的一半。
1.3 软件的发展
为了完整性加的部分,该系列不讨论过多软件部分。
1.4 目前的发展趋势
计算机目前的发展趋势两极分化:
- 微型计算机向更微型化、网络化、高性能、多用途方向发展。
- 巨型机向更巨型化、超高速、并行处理、智能化方向发展。如我国的神威·太湖之光,感兴趣的可以参考超级计算机榜单。
二、计算机系统的多级层次结构
2.1 编程语言的三个等级
计算机系统的层次划分有很多角度,作为一个程序猿来说,我平常最关心的事情之一就是编程语言。编程语言可以分为三个级别:机器语言、汇编语言和高级语言。
- 机器语言就是0101的二进制代码,也就是所谓的计算机唯一认识的语言(其实计算机不认识01,但是它能识别高低电平)。机器语言是也最底层、最接近硬件的语言
- 汇编语言和机器语言是一一对应的,只不过它更容易被程序猿理解,相当于一个助记符。
- 高级语言就是现在大多数开发人员经常使用的如C/C++等。
补充:
编译型语言:编译型语言需要经过编译程序编译成汇编语言,再通过汇编程序汇编成机器语言,然后计算机就可以执行了。编译型语言会被一次全部翻译成机器语言。
解释性语言:解释型语言会直接被解释程序翻译成机器语言。与编译型语言不同的是,解释型语言是解释一句运行一句。
举个不是特别恰当的例子:编译程序与解释程序的区别类似于翻译软件和同声传译。翻译软件会将一个文本一次性全部翻译完,而同声传译则需要发言者说一句,工作人员翻译一句。
编译、汇编、解释程序可以统称为翻译程序。
2.2 计算机系统层次结构
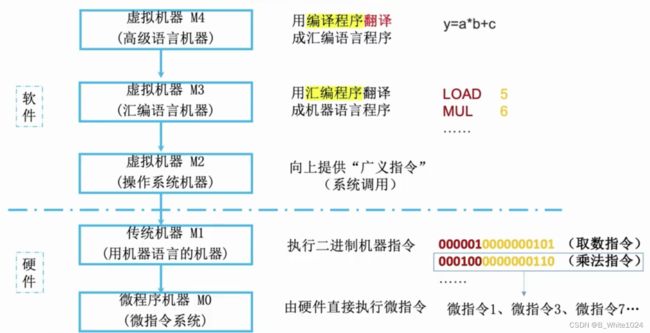
根据使用的编程语言不同,可以将计算机系统分为5个层次,自下至上依次是微程序机器M0(微指令机器)–>传统机器M1(用机器语言的机器)–>虚拟机器M2(操作系统机器)–>虚拟机器M3(汇编语言机器)–>虚拟机器M4(高级语言机器)。下层是上层的基础,上层是下层的扩展。
传统机器M1就是可以执行二进制代码指令的机器,但是一条指令又可以分为多个微指令,这些微指令在M0上由硬件直接执行。汇编语言不能由机器直接执行,需要汇编程序翻译成机器语言,因此将M3称为虚拟机器。同样的,高级语言也需要由编译器翻译成汇编语言,所以M4也是虚拟机器。而高级语言和汇编语言程序难免会用到操作系统的服务如系统调用(又称与广义指令),因此他们与M1之间还需要操作系统机器M2。其中M2至M4属于软件,M0和M1属于硬件,是计算机组成原理要探讨的重点。
三、计算机硬件的基本组成
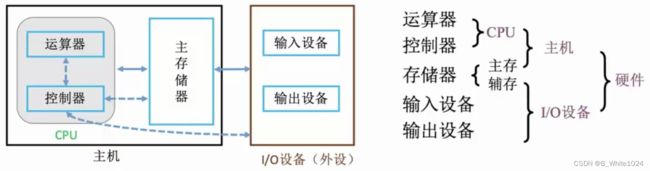
计算机硬件由输入设备、输出设备、运算器、控制器、主存储器5大部分组成。输入输出设备就是IO设备,像键盘和显示器,一个将信息转换成计算机认识的形式,一个将结果转换成人认识的形式。主存储器用来存放数据和程序。运算器用来进行算数和逻辑运算。控制器指挥各部件使程序运行。
3.1 冯诺依曼结构
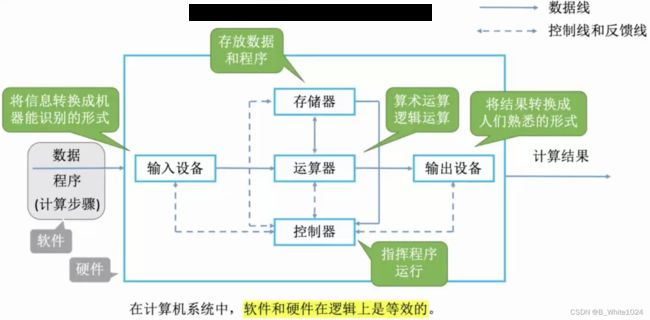
冯诺依曼机器有以下特点:
- 计算机由5大部件组成
- 指令和数据以同等地位存放在存储器,可按地址寻址
- 指令和数据用二进制表示
- 指令由操作码和地址码组成
- 存储程序
- 以运算器为中心
冯诺依曼首次提出了“存储程序”的概念:将指令以二进制代码的形式实现输入到计算机的主存储器,然后按其首地址执行第一条指令,接着就按照程序规定的顺序执行其他指令,直至程序结束。
而以运算器为中心并不合适,运算器的主要功能是运算,而冯诺依曼结构的计算机不论是从输入设备输入数据到存储器,还是输出设备从存储器拿走数据都需要运算器的中转,这就使得该结构的计算机效率较低。
软件和硬件在逻辑上是等效的是指同样的事情,只使用软件或者只使用硬件都可以完成,只不过是用软件成本低但效率也低,而使用硬件效率高但成本也高。
3.2 现代计算机结构
为了解决冯诺依曼机器的缺点,现在计算机以存储器为中心,而且大多将运算器和控制器集成为CPU。
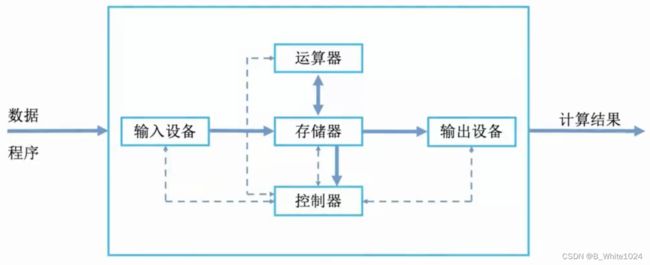
下边的示意图会更清晰的表明现代计算机的结构:
四、计算机各硬件的工作原理
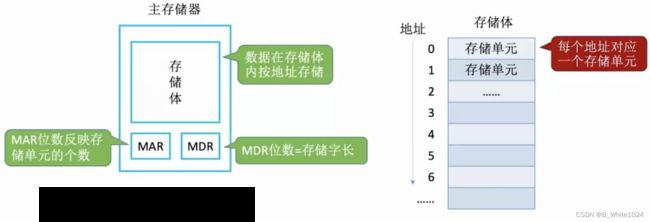
4.1 主存
主存由存储体、地址寄存器MAR、数据寄存器MDR组成(现在的计算机通常把MAR和MDR集成在CPU中,但其逻辑上仍属于主存)。存储体内存储了数据。MAR在读写时分别存储了要从哪里读和要写到哪里去。MDR在读写是存储了要读出或写入的数据。
存储单元:存储体由存储单元组成,每个地址对应一个存储单元。
存储字(word):存储单元中二进制代码的组合。
存储字长:存储单元中二进制代码的位数,一般是8bit的整数倍。
存储元:存储二进制的电子元件,每个存储元可存1bit.
MAR的位数反映了存储单元的个数,如5位的MAR最多可表示 2 5 = 32 2^5=32 25=32个存储单元。MDR的位数反映了存储字长,如32位的MDR表示存储字长为32bit,此时一个字就是32bit.此时该存储体的存储容量就是 2 5 × 32 = 1024 b i t = 128 B 2^5 \times 32 = 1024bit = 128B 25×32=1024bit=128B。注意:字word是和存储体相关的概念,而字节Byte是一个单位,二者没什么必然联系。
4.2 运算器
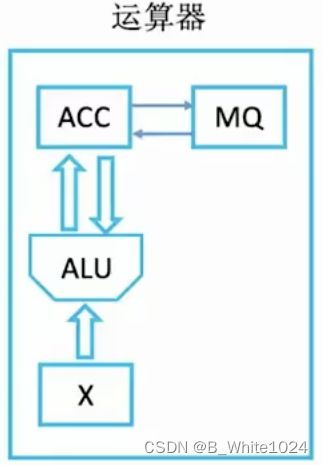
运算器由累加寄存器ACC、乘上寄存器MQ、操作数寄存器X、算术逻辑单元ALU组成。其核心是ALU,用来实现算术运算和逻辑运算。其于的寄存器主要用于存储操作数或者运行结果:

记忆tips:把两个操作数一个叫做被操作数,一个叫做操作数。
关于被操作数和操作数:除了乘法的被操作数存在X中,其于所有被操作数均存放于ACC中。除了乘法的操作数存放于MQ中,其于所有操作数均存放于X中。
关于MQ结果:加减法的结果存放于ACC中,乘除法的结果存放于ACC和MQ中。
4.3 控制器
控制器由控制单元CU、指令寄存器IR、程序计数器PC组成。CU负责分析指令,给各个部件发出控制信号。IR存放当前执行的指令,PC存放下一条指令的地址,可以自动+1.
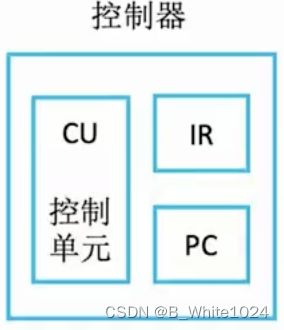
完成一条指令可以划分为3个阶段:取指令、分析指令和执行指令。首先根据PC中的地址将指令取出放到IR中。IR将该指令的地址码部分送往MAR来指名要操作的数据所处的位置,同时将该指令的操作码部分送往CU,由CU分析该指令并控制各部件执行该指令。
4.4 工作过程
int a=2,b=3,c=1,y=0;
void main(){
y=a*b+c;
}
以上述代码为例,该代码经过汇编后变成如下的机器指令存储于主存中:
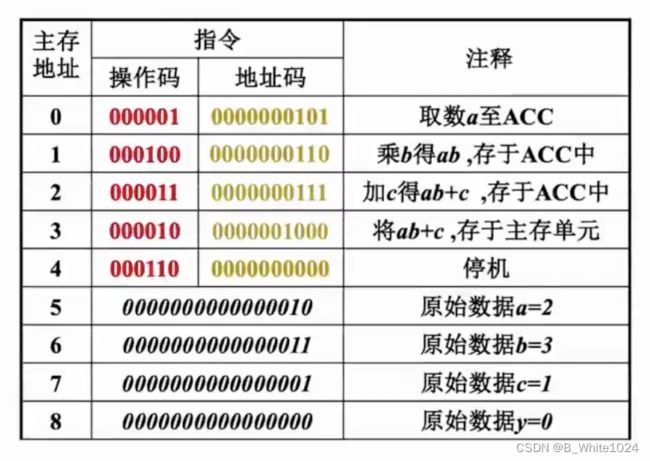
以执行主存地址为1的指令为例:由于在此之前已经执行过地址为0的指令,PC的值已经自动+1,因此此时各寄存器的情况为:(PC)=1,(ACC)=2.在此基础上执行指令1的步骤如下:
取指令,该阶段执行结束后PC会自动+1
#1:(PC) —> MAR,将PC中的数据送往MAR,导致(MAR)=1
#2/3:M(MAR) —> MDR,将MAR中的数据送往MDR,导致(MDR)=0001000000000110
#4:(MDR) —> IR,将MDR中的数据送往IR,导致(IR)=0001000000000110
分析指令
#5:OP(IR) —> CU,将指令的操作码部分送往CU,CU分析后得知这是一条乘法指令
执行指令
#6:Ad(IR) —> MAR,将指令的地址码部分送往MAR,导致(MAR)=6
#7/8:M(MAR) —> MDR,将地址为6的数据送往MDR,导致(MDR)=0000000000000011=3
#9:MDR —> MQ,将MDR中的数据送往MQ,导致(MQ)=0000000000000011=3
#10:(ACC) —> X,将ACC中的数据送往X,导致(X)=2
#11:(MQ)*(X) —> ACC,由ALU实现乘法运算,导致(ACC)=6。若结果太大,则需要MQ辅助存储低位。
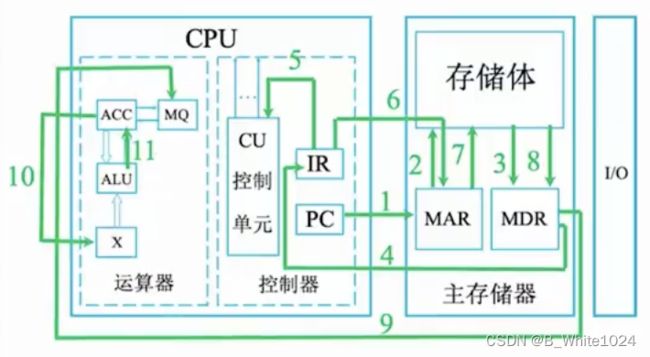
至此指令2执行完毕,#1~#4为取指令,#5为分析指令,#6~#11为执行指令。其中所有指令的#1~#5即取指令和分析指令阶段都相同。
通过该过程可以看出,无论是指令还是数据都需要从MDR中送到不同的寄存器。若此次操作取出的是指令,则需要MDR送往IR;若此次操作取出的是数据,则需要根据不同的操作送往不同的寄存器。CPU区分此次取出的是指令还是数据是根据指令周期的不同阶段,若此时处于取指阶段,那么取出的就是指令;若此时处于执行阶段,取出的就是数据。
五、计算机性能指标
5.1 存储器的容量
存储器的容量由存储单元的个数以及每个存储单元的存储字长共同决定。存储单元的个数由MAR的位数决定,存储字长由MDR的位数决定。如32位的MAR最多可表示 2 32 2^{32} 232个存储单元,8位的MDR表示存储字长为8bit,该存储体的存储容量就是 2 32 × 8 b i t = 4 G B 2^{32} \times 8 bit = 4GB 232×8bit=4GB。
5.2 CPU
- 时钟周期
时钟周期通常是节拍脉冲,它是最CPU中最小的时间单位,也就是说每个操作至少需要一个时钟周期。单位是微秒、纳秒。

- 主频(时钟频率)
主频指的是CPU一秒钟有多少个时钟周期,它等于 1 时钟周期 \frac{1}{时钟周期} 时钟周期1,单位是Hz。 - CPI
CPI(Clock cycle Per Instruction)指执行一条指令需要多少个时钟周期。对于同一个CPU,由于不同指令的所需要做的微操作不同,因此它们的CPI不同;对于不同的CPU执行相同的指令,由于系统架构不同,它们的CPI也会不相同;对于同一个CPU多次执行同一个指令,也可能会因为系统状态的不同而导致其CPI不同。计算CPI时通常取平均值。
这样计算 平均执行一条指令的耗时 = 平均 C P I × 时钟周期 平均执行一条指令的耗时 = 平均CPI \times 时钟周期 平均执行一条指令的耗时=平均CPI×时钟周期. - CPU执行时间
CPU执行时间指的是整个程序的耗时,它等于 指令条数 × 平均 C P I × 时钟周期 指令条数 \times 平均CPI \times 时钟周期 指令条数×平均CPI×时钟周期。 - IPS
IPS(Instructions Per Second)表示CPU一秒钟能执行多少条指令,它等于 主频 平均 C P I \frac{主频}{平均CPI} 平均CPI主频。 - FLOPS
FLOPS(Floating-point Operations Per Second)表示CPU每秒能进行多少次浮点数运算。类似的还有KFLOPS、MFLOPS、GFLOPS、TFLOPS、PFLOPS、EFLOPS、ZFLOPS,后者一次是前者的 1 0 3 10^3 103倍。
5.3 系统整体性能指标
- 数据通路带宽
表示数据总线一次所能并行传送信息的位数(各硬件部件通过数据总线传输数据)。 - 吞吐量
表示单位时间内系统能处理请求的数量,它主要取决于主存的存取周期。 - 响应时间
表示用户向计算机发起了一个请求开始,到系统对该请求作出响应为止所需要的时间。它通常包括CPU时间和等待时间(磁盘访问、存储器访问、I/O操作、操作系统开销等)。 - 基准程序
向鲁大师这样的跑分软件,不要过分相信。
5.4 区分常用单位
描述大小时: K = 2 10 、 M = 2 20 、 G = 2 30 、 T = 2 40 K=2^{10} 、M=2^{20} 、G=2^{30} 、T=2^{40} K=210、M=220、G=230、T=240
描述速率时: K = 1 0 3 、 M = 1 0 6 、 G = 1 0 9 、 T = 2 12 K=10^{3} 、M=10^{6} 、G=10^{9} 、T=2^{12} K=103、M=106、G=109、T=212
5.5 小结
主频高的CPU不一定比主频低的CPU运行速度更快,因为他们的CPI可能不同。
相同CPI的两个CPU,若A比B的主频高,A也不一定比B快,这是因为二者架构可能不同,同一条指令所需要的微操作可能不同。
基准程序执行越快不能说明机器越好,这是因为基准程序中的语句存在频度差异,其结果不能完全说明问题。