卫生统计学 SAS代码复习
t检验
单样本t检验
DATA t1;
INPUT x@@;
CARDS;
20.99 20.41 20.10 20.00 20.91 22.60 20.99 20.41 20.00 23.00 22.00
;
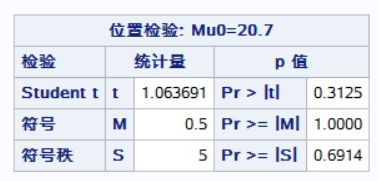
PROC UNIVARIATE mu0=20.70 NORMAL;
VAR x;
RUN;这段SAS代码的意义如下:
PROC UNIVARIATE:指定使用单变量分析过程。
mu0=20.70:指定假设总体均值为20.70。
NORMAL:指定数据符合正态分布。
VAR x:指定变量x为分析对象。
RUN:运行程序。综上,这段代码的意义是对变量x进行单变量分析,假设其均值为20.70,数据符合正态分布。
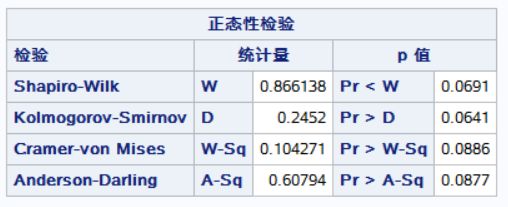
结果:首先进行统计描述,再正态性检验,最后求出置信区间与进行假设检验。

说明:
如果样本来自于正态分布的总体,那么样本数据也很可能符合正态分布。但是,由于样本容量较小或者存在离群值等情况,样本数据可能并不完全符合正态分布。因此,为了保证假设检验的准确性,需要对样本数据的正态性进行检验,例如使用Shapiro-Wilk检验、Kolmogorov-Smirnov检验等方法。如果样本数据不符合正态分布,可以考虑进行数据变换或者使用非参数检验方法。
Shapiro-Wilk检验是用于检验样本是否符合正态分布的一种方法,该检验是在原假设为样本来自于正态分布的情况下进行的,如果得出的p值小于预先设定的显著性水平(通常为0.05),则拒绝原假设,即认为样本不符合正态分布。原假设为“样本来自的总体与正态分布无显著性差异,即符合正态分布”。
配对t检验
DATA t2;
INPUT d@@;
CARDS;
3.48
7.41
7.48
9.42
8.25
3.35
6.95
7.41
6.35
7.41
8.58
;
PROC UNIVARIATE NORMAL;
VAR d;
RUN;
PROC MEANS MEAN STD T PRT CLM;
VAR d;
RUN;这段SAS代码的意义如下:
第一部分:
PROC UNIVARIATE NORMAL:指定使用单变量分析过程,并假设数据符合正态分布。
VAR d:指定变量d为分析对象。
RUN:运行程序。综上,这段代码的意义是对变量d进行单变量分析,假设其符合正态分布。
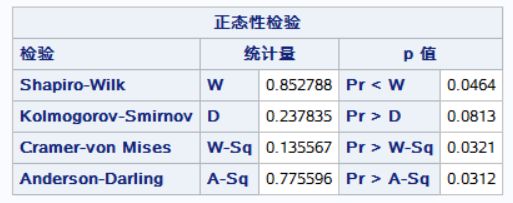
n<2000, use Shapiro-wilk. n>2000, use Kolmogo-Smirnov.
第二部分:
PROC MEANS:指定使用均值过程。
MEAN STD T PRT CLM:指定输出均值、标准差、t值、p值和置信区间。
VAR d:指定变量d为分析对象。
RUN:运行程序。综上,这段代码的意义是计算变量d的均值、标准差、t值、p值和置信区间。
结果

两个独立样本t检验
data t3;
input group wt@@;
cards;
1 134
1 146
1 104
1 119
1 124
1 161
1 107
1 83
1 113
1 129
1 97
1 123
2 70
2 118
2 101
2 85
2 107
2 132
2 94
;
/*调用univariate进行正态性检验*/
proc univariate normal;
var wt;
class group;
run;
/*调用ttest过程进行两独立样本的T检验*/
proc ttest;
class group;
var wt;
run;PROC TTEST:指定使用t检验过程。
CLASS group:指定变量group为分类变量。
VAR wt:指定变量wt为分析对象。
RUN:运行程序。综上,这段代码的意义是对变量wt进行t检验,并根据group变量进行分组比较。
结果

group1 正态性检验

group2 正态性检验

方差分析
完全随机设计资料的方差分析
DATA ANO1;
INPUT group col1;
CARDS;
1 6.82
1 5.73
1 7.19
1 7.93
1 7.62
1 7.77
1 7.9
1 7.89
2 5.66
2 4.82
2 5.53
2 4.98
2 4.4
2 4.18
2 4.07
2 4.11
3 2.13
3 2.71
3 2.5
3 2.67
3 3.6
3 3.36
3 2.33
3 2.85
;
/*正态性检验,会有三个组的结果,分析与t检验的差不多*/
PROC UNIVARIATE NORMAL;
CLASS group;
VAR col1;
RUN;
/*调用GLM过程进行方差分析*/
PROC GLM;
CLASS group;/*指定变量group为分类变量*/
MODEL col1=group;/*指定col1为因变量,group为自变量,构造统计模型*/
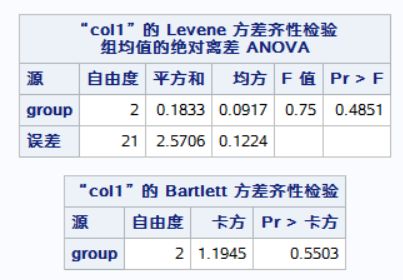
MEANS group/SNK BON LSD DUNNETT('1') HOVTEST=LEVENE(TYPE=ABS) HOVTEST=BARTLETT;
LSMEANS GROUP/CL PDIFF TDIFF STDERR ADJUST=DUNNETT;
RUN;MEANS group/:指定进行组间均值比较。

SNK:指定使用SNK方法进行多重比较。
BON:指定使用Bonferroni方法进行多重比较。
LSD:指定使用LSD方法进行多重比较。
DUNNETT('1'):指定使用Dunnett方法进行多重比较,并设定参照组为1。
HOVTEST=LEVENE(TYPE=ABS):指定使用Levene方法进行方差齐性检验,检验统计量为绝对值型。
HOVTEST=BARTLETT:指定使用Bartlett方法进行方差齐性检验。
LSMEANS GROUP/:指定对每个组进行均值比较。
CL:指定输出置信区间。
PDIFF:指定输出组间差异的p值。
TDIFF:指定输出组间差异的t值。
STDERR:指定输出标准误。
ADJUST=DUNNETT:指定对多重比较进行Dunnett校正。

随机区组设计资料的方差分析
DATA ANO2;
INPUT group block cure@@;
CARDS;
1 1 58.02 2 1 71.9 3 1 66.27
1 2 52.7 2 2 56.35 3 2 60.59
1 3 60.22 2 3 70.08 3 3 66.12
1 4 44.49 2 4 56.6 3 4 55.36
1 5 59.31 2 5 68.25 3 5 53.39
1 6 56.23 2 6 63.36 3 6 52.34
1 7 55.16 2 7 66.12 3 7 55.16
1 8 42.48 2 8 50.02 3 8 58.64
1 9 50.84 2 9 66.97 3 9 44.01
1 10 49.38 2 10 67.05 3 10 52.49
1 11 55.16 2 11 69.89 3 11 59.99
1 12 53.47 2 12 61.08 3 12 61.08
;
/*做正态性检验*/
PROC UNIVARIATE NORMAL;
CLASS group;
CLASS block;
VAR cure;
RUN;
/*调用GLM过程进行方差分析*/
PROC GLM;
CLASS group block;
MODEL cure = group block;/*构造模型,group是处理组,block是随机区组*/
RUN;结果:统计描述,正态性检验,方差齐性检验,最后假设检验。
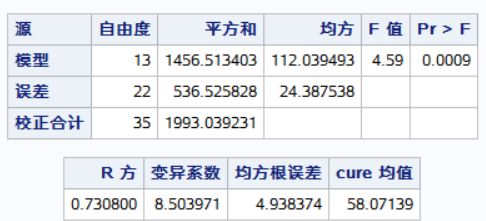
卡方检验
两个独立样本率的X²检验
DATA chi1;/*创建数据集*/
group=2;/*定义组数,行,如甲乙*/
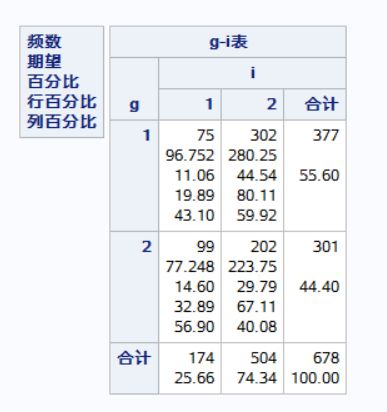
/*循环语句含义:第一行第一列75,第二列302;第二行第一列99,第二列202.*/
DO g=1 TO group;/*行*/
DO i=1 TO 2;/*列*/
INPUT f@@; /*@@表示读取数据不换行*/
OUTPUT;
END;
END;
CARDS;
75 302 99 202
;
PROC FREQ;
WEIGHT f;/*指定f为频数变量*/
TABLES g*i/ EXPECTED CHISQ;/*生成二维列联表,输出期望频数,进行卡方检验*/
RUN;结果:统计描述,卡方检验
列联表
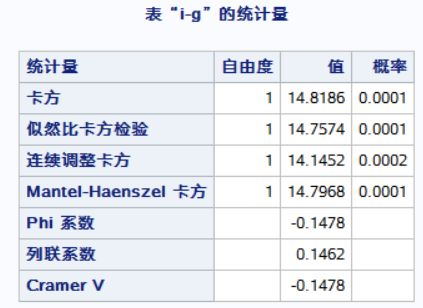
卡方检验
配对四格表的检验与关联性分析
DATA a;
INPUT r c f;/*row, column,frequency*/
CARDS;
1 1 80
1 2 15
2 1 30
2 2 10
;
PROC FREQ;
WEIGHT f;
TABLES r*c/AGREE;/*AGREE输出McNemar检验的结果(不需校正的情形,如资料需要校正,并不会给出校正后的卡方值及P值!)*/
/*TABLES r*c/AGREE CHISQ; /*CHISQ进行卡方检验的关联性分析*/
RUN;
/*用公式计算卡方值,并用函数得出相应P值*/
/*SAS中McNemar检验不考虑校正问题,当b+c<40时,需对校正。需要自己写公式计算。*/
DATA b;
INPUT a b c d;
IF b+c<40 THEN
chisq=(ABS(b-c)-1)**2/(b+c);
ELSE chisq=ABS(b-c)**2/(b+c);
p=1-PROBCHI(chisq,1);/*PROBCHI(chisq,df),自由度为df的卡方分布中,-∞到当前卡方值的左侧累积概率*/
CARDS;
80 15 30 10
;
PROC PRINT;
RUN;多个独立样本率的X²检验
DATA chi3;/*与上述的两个样本例子相同*/
group=3;
DO g=1 TO group;
DO i=1 TO 2;
INPUT f@@;
OUTPUT;
END;
END;
CARDS;
7 24 9 22 21 11
;
PROC FREQ;
WEIGHT f;
TABLES g*i/nocol nopercent EXPECTED CHISQ EXACT;/*不需要百分比,行百分比和列百分比*/
RUN;
秩和检验——非参数检验
单样本秩和检验——Wilcoxon符号秩和检验
(不在本次考试参考程序内,但有助于理解配对秩和检验)
data a10_1;/****p.211 例10-1,单样本秩和检验****************/
input x@@;
median=18.9;
d=x-median;/*与中位数的差值*/
cards;
0
0
0
0
0
12.4
34.1
69
98.4
129.5
156.1
163.5
170.9
177.6
172.4
180.3
189.2
192.2
196.8
205.3
;
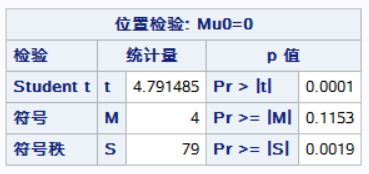
proc univariate;
var d;
run;
************************************************************************
注:结果中的Test for Location:Mu=0栏,t检验就是我们常见的t检验
************************************************************************;
配对设计数据的符号秩和检验
data a10_2;/****p.212 例10-2,配对秩和检验****************/
input x1 x2 @@;
d=x1-x2;
cards;
15 16
14 12
8 5
17 19
20 16
10 13
22 9
15 15
3 7
13 46
;
proc univariate;
var d;
run;
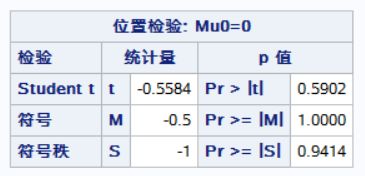
两组独立样本秩和检验
定量数据的比较
DATA non2;/*214页例题*/
INPUT group ca@@;
CARDS;
1 1843
1 383
1 406
1 334
1 443
1 676
1 771
1 358
1 607
1 484
2 842
2 336
2 742
2 1367
2 1623
2 597
2 1976
2 1818
2 643
2 4534
;
PROC UNIVARIATE NORMAL;/*正态性检验*/
CLASS group;
VAR ca;
RUN;
PROC NPAR1WAY WILCOXON;/*调用npar1way过程进行wilcoxon检验*/
EXACT WILCOXON;
CLASS group;/*定义group为分类变量*/
VAR ca;
RUN;
解释:group1,也就是男童组的秩和为77;group2,即女童组秩和为133;W的均数为105,标准差为13.23。

看Z=2.078,双侧P值为0.038,小于0.05,因此拒绝原假设,接受备择假设。
等级数据的比较
(本次考试不涉及,较复杂)
多组独立样本秩和检验——kruskal-Wallis检验
data non3;
input group tnf@@;
cards;
1 0.218
1 0.051
1 0.186
1 0.198
1 0.036
2 0.253
2 0.558
2 0.352
2 0.284
2 0.487
3 0.695
3 0.53
3 0.645
3 0.621
3 0.384
;
proc univariate normal;
class group;
var TNF;
run;
proc npar1way wilcoxon;
exact wilcoxon;
class group;
var tnf;
run;
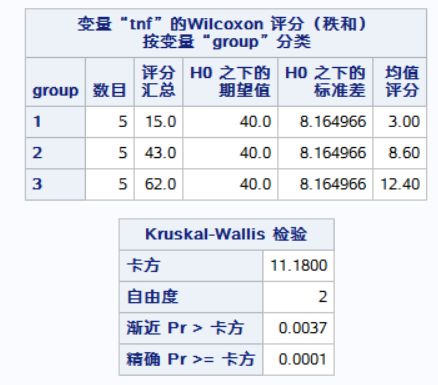
检验统计量H为11.18,P小于0.005.
直线与线性回归
pearson线性相关与回归分析
需服从正态分布
DATA corr_reg1;
INPUT x y;
CARDS;
6.8 21
10.3 12
1.7 42
11.0 8
8.8 13
5.8 28
2.5 41
3.3 35
4.3 31
9.0 16
3.2 38
12.7 6
8.2 18
7.0 24
5.1 30
4.1 34
;
RUN;
PROC UNIVARIATE NORMAL;/*正态性检验*/
VAR x y;
RUN;
PROC GPLOT;/*散点图*/
PLOT y*x;
RUN;
PROC CORR PEARSON NOSIMPLE;/*相关性分析,得出Pearson相关系数*/
VAR x y;
RUN;
PROC REG;/*线性回归分析*/
MODEL y=x/clb clm cli;/*建立回归模型,用于预测因变量y的值*/
PLOT y*x;/*用于绘制散点图和回归直线,其中y和x分别表示因变量和自变量。*/
RUN;PROC REG:线性回归分析这个过程用于进行线性回归分析,其中MODEL语句指定了因变量y和自变量x,CLB、CLM和CLI分别表示置信区间的下限、中间值和上限,用于计算置信区间。
解题步骤不能忘!
线性相关分析:
适用条件用散点图判断
求相关系数并进行总体相关系数的假设检验,如:
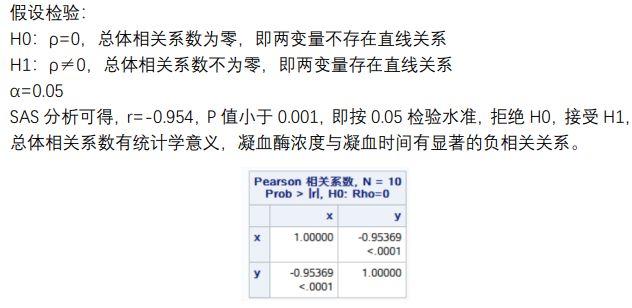
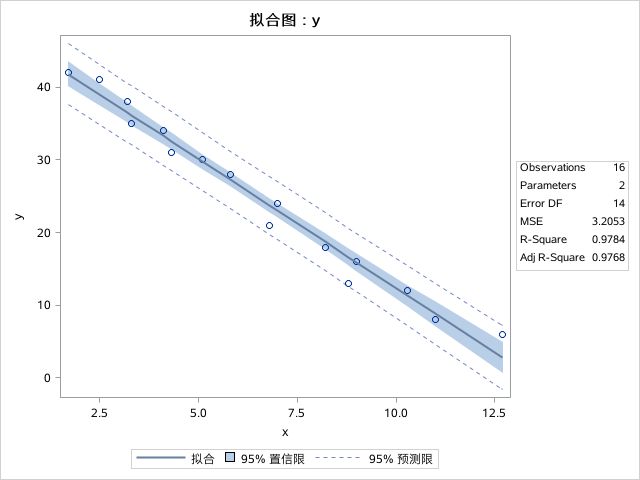
线性回归分析:
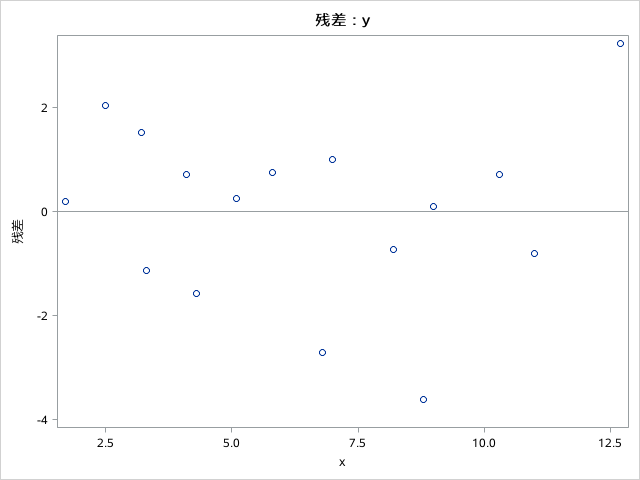
适用条件用LINE,做残差图判断方差齐性
求出回归方程,并假设检验
方差拟合效果,如:

R2=0.9095,因此线性回归可以解释凝血时间变异的 90.95%,方差拟合效果较好。相关系数有统计学意义,因此回归系数也有统计学意义。
sas结果:统计描述与正态性检验、散点图(如下)、pearson相关系数、回归系数的方差分析,回归方程的参数估计、方差拟合效果R²(见上图),回归直线的置信带、残差图、回归方程拟合直线等。


由此可知,相关系数为-0.98912

spearman线性相关分析(秩相关系数)
DATA corr_reg2;
INPUT x y;
CARDS;
1.0 40.5
2.0 37.7
2.5 39.0
3.5 20.0
3.5 22.0
4.0 37.4
4.4 31.5
4.5 15.6
4.6 21.0
7.7 6.3
8.0 7.1
8.0 9.0
8.3 4.0
8.5 4.0
8.5 5.4
8.8 4.7
24.5 0.0
;
RUN;
PROC CORR SPEARMAN NOSIMPLE;
VAR x y;
RUN;
自变量的筛选
DATA corr_reg3;
INPUT x1-x4 y;
CARDS;
24.22 10.0 5.75 13.6 29.36
24.22 3.0 9.32 6.2 14.31
19.03 15.0 2.50 11.1 26.08
23.39 3.0 5.66 9.7 19.62
19.49 4.0 2.83 7.3 42.82
24.38 6.0 6.86 7.3 22.76
19.03 2.9 3.22 7.7 31.00
21.11 9.0 4.90 6.0 17.28
23.32 5.0 3.54 6.7 30.25
24.34 2.0 4.51 7.2 24.28
23.82 8.0 8.47 9.1 18.94
22.86 20.0 9.92 8.1 16.08
24.49 12.0 6.01 7.0 29.50
23.37 6.0 4.31 6.3 25.64
20.81 7.0 3.46 7.1 32.26
24.14 5.0 10.21 7.4 16.01
26.45 4.0 19.31 5.1 19.03
25.22 2.3 8.65 7.6 17.46
27.22 3.0 8.54 8.6 20.36
25.93 6.0 7.21 8.9 15.92
26.99 12.0 8.75 7.0 15.34
25.71 7.0 13.07 13.5 8.05
28.41 4.0 8.90 13.5 12.31
26.39 4.0 23.26 8.2 5.59
28.73 10.0 19.05 6.9 8.59
27.46 16.0 19.44 6.5 8.89
27.99 10.0 17.33 6.1 14.10
28.41 2.0 14.59 6.8 11.74
30.69 1.5 22.06 8.1 5.18
29.39 3.0 20.56 7.5 6.12
;
RUN;
PROC REG;
MODEL y=x1-x4 /STB;
MODEL y=x1-x4 /SELECTION=STEPWISE SLS=0.1 SLE=0.05 STB;
MODEL y=x1-x4 /SELECTION=FORWARD SLE=0.05;
MODEL y=x1-x4 /SELECTION=BACKWARD SLS=0.1;
MODEL y=x1-x4 /SELECTION=RSQUARE ADJRSQ CP;
RUN; 生存分析
KM法
kaplan-meier法,又称乘积极限法。非参数估计生存率的方法。
/*KM法*/
data a12_1;
input t d@@;/*t为生存时间,d是死亡例数*/
cards ;
2 1 5 1 8 1 9 1 9 0 10 1 13 1 13 1 15 0 18 1 20 1 23 0
;
proc lifetest method= pl/*KM也可以*/ data= a12_1;
time t * d(0) ;
run;结果:生存率及其标准误的计算、中位生存时间与生存曲线的计算、生存率的95%置信区间。(第八版P240-242)

生存为生存概率,生存标准误差即生存率标准误,剩余数目即期初人数。
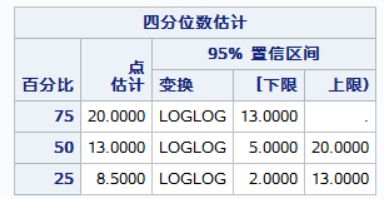
可得出中位生存时间,置信区间。

寿命表法
(不在考查范围)
proc lifetest method= life width= 2 data = a12_2;
time t * status (0);
freq number;/*频数*/
run;生存曲线比较——log-rank检验
对数秩检验(log-rank检验)
data a12_3;
input group t status ;
cards;
1 2 1
1 5 1
1 8 1
1 9 1
1 9 0
1 10 1
1 13 1
1 13 1
1 15 0
1 18 1
1 20 1
1 23 0
2 2 1
2 2 1
2 3 1
2 5 1
2 6 1
2 6 1
2 8 1
2 9 1
2 10 1
2 14 0
;
proc lifetest ;
time t * status(0);
strata group;
run;结果:
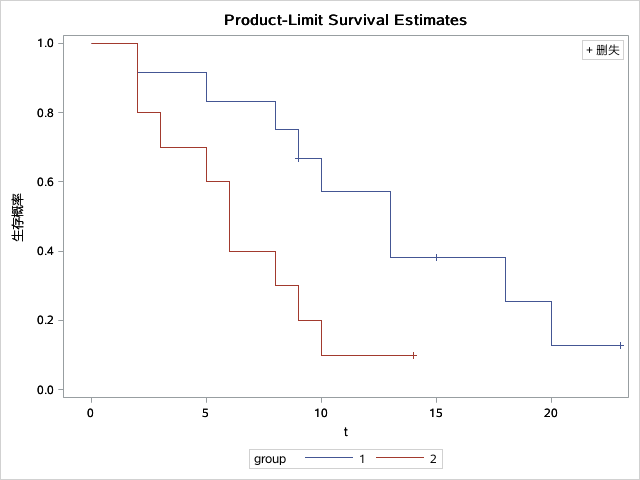
进行假设检验:

logistic 回归
多重回归分析包括(多重线性回归、logistic回归、cox回归)
第一步 导入外部文件
/****例13-2,logistic回归****************/
/*导入csv文件,以下两种方法,命名为a13_2或a13_22*/
data a13_2;
infile "C:\Users\Wei Shen\Desktop\实习15-Logistic回归\data13-2.csv" DLM=',' FIRSTOBS=2;
input no x1 x2 x3 x4 x5 x6 x7 x8 y;
run;
/*以下是另外一种方法,记得只用一个方法!*/
proc import out=a13_22 datafile="C:\Users\Wei Shen\Desktop\实习15-Logistic回归\data13-2.csv" dbms=csv replace;
getnames=yes;
run;第二步 确定自变量进入模型的形式并画图
/*确定自变量进入模型的形式,多分类变量需探索*/
proc logistic data=a13_2 descending plots(only)=(effect(link join=yes));/*desc,因变量的较大值与较小值比较,否则默认较小值与较大值比较。plots选项输出logitP与多分类自变量的关系*/
Class x2/param=reference ref=first;/*哑变量,或ref=last*/
model y=x2;
proc logistic data=a13_2 descending plots(only)=(effect(link join=yes));
Class x3/param=reference ref=first;/*哑变量*/
model y=x3;
proc logistic data=a13_2 descending plots(only)=(effect(link join=yes));
Class x5/param=reference ref=first;/*哑变量*/
model y=x5;
proc logistic data=a13_2 descending plots(only)=(effect(link join=yes));
model y=x5;
proc logistic data=a13_2 descending plots(only)=(effect(link join=yes));
Class x7/param=reference ref=first;/*哑变量*/
model y=x7;
run;
/*x2,x3,x7非线性,以哑变量进入方程,x5接近线性,但是根据OR值判断,最好还是以哑变量进入方程。但样本量比较小时,最好不要有太多哑变量*/
- plots(only)=(effect(link join=yes)):生成模型效应图和连结函数图,并且将它们合并在一起显示。其中,effect 表示模型效应图,link 表示连结函数图,join=yes 表示将两个图合并在一起显示。
- Class x3/param=reference ref=first;:x3 是分类变量,在此处被视为哑变量处理。param=reference 指定了参考类别参数估计方法(即以第一个水平作为基准),ref=first 则指定了第一个水平作为参考。
说明:
哑变量(Dummy Variable)是指将分类变量转换为数值型自变量的一种方法。在逻辑回归中,通常使用哑变量来处理分类自变量,因为逻辑回归模型只能接受数值型自变量作为输入。假设有一个分类自变量 x,它有 k 个水平(即 k 种取值),则可以通过创建 k-1 个二元哑变量来表示该分类自变量。具体地,对于每一个水平 i (i=1,2,...,k-1),都创建一个二元哑变量 D_i 和 D_(i+1),其中:
- 当 x=i 时,D_i=1、D_(i+1)=0;
- 当 x=(i+1) 时,D_i=0、D_(i+1)=1。
这样就可以用这些二元哑变量代替原始的分类自变量进行建模了。
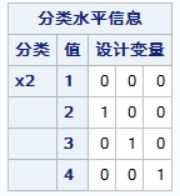
- model y=x3;:指定了逻辑回归模型,因变量为 y,自变量为 x3。只考虑分类变量 x3 对响应变量 y 的影响。
第三步 单因素或多因素回归分析
(跟上面的差不多,每个变量都一一进行回归分析,只是没画图)
单因素逻辑回归分析
需要的话进行单因素分析,不需要可以不用单因素分析。
/*单因素Logistic回归,等价于卡方检验*/
proc logistic data=a13_2 descending;
model y=x1;
proc logistic data=a13_2 descending;
Class x2/param=reference ref=first;/*哑变量*/
model y=x2;
proc logistic data=a13_2 descending;
Class x3/param=reference ref=first;/*哑变量*/
model y=x3;
proc logistic data=a13_2 descending;
model y=x4;
proc logistic data=a13_2 descending;
Class x5/param=reference ref=first;/*哑变量*/
model y=x5;
proc logistic data=a13_2 descending;
model y=x6;
proc logistic data=a13_2 descending;
Class x7/param=reference ref=first;/*哑变量*/
model y=x7;
proc logistic data=a13_2 descending;
model y=x8/stb;
run;多因素逻辑回归分析
可以都纳入模型,进行筛选。这里只纳入了3,4,5,6,8。
/*多因素回归分析,模型中纳入x3,x4,x5,x6,x8,其中x3和x5以哑变量形式进入*/
proc logistic data=a13_2 descending;/*plots(only)=all*/
Class x3 (param=reference ref=first);/*哑变量*/
Class x5 (param=reference ref=first);/*哑变量*/
model y=x3 x4 x5 x6 x8/stb aggregate scale=none;/*stb标准偏回归系数;aggregate和scale输出Pearson chi-square和Deviance值,用于拟合优度评价*/
/*模型拟合优度检验,H0:实际观察的频数分布与模型预测的频数分布相符合,模型拟合观察资料;H1:模型不拟合观察资料*/
/*Logistic回归模型的假设检验,H0:只含有截距项的模型成立;H1:含有截距和m个自变量的模型成立*/
/*Logistic回归系数的假设检验,H0:βj=0;H1:βj≠0*/
run;
/*Logistic逐步回归过程,最终x5,x8,x4,x6进入方程*/
proc logistic data=a13_2 descending;
model y=x1-x8/selection=stepwise sle=0.05 sls=0.1;
run;作业2代码:(即简易版逻辑回归)
data homework;
input dis sex his f;/*dis=1,病例;sex=1,男;his=1;有病史*/
cards;
1 1 1 30
1 1 0 138
1 0 1 20
1 0 0 90
0 1 1 15
0 1 0 153
0 0 1 11
0 0 0 99
;
proc logistic desc;
freq f;
model dis=sex his/selection=stepwise sle=0.05 sls=0.10 risklimits;
run;