Transformer & BERT 详解第1篇(共4篇)
本系列文章围绕以下几个主题来详细解读Transformer和BERT的原理和发展
- Transformer 模型详解
- Transformer在CV,NLP,推荐系统的发展与应用
- BERT模型详解
- BERT最新发展与应用
更多内容请关注公众号:AliceWanderAI
本篇文章:Transformer模型详解
- 整体结构
- Encoder
- Decoder
- Positional Encoding
- Self Attention
- Add & Norm
1. 整体结构
Transformer主要由两大部分组成:Encoder & Decoder.
Encoder-Decoder模型可以基于CNN/RNN来构建。而Transformer是完全采用Self Attention机制来构建Encoder-Decoder模型结构的。
如下图所示。左边是Encoder的结构,它将输入Inputs 映射成隐藏层的输出,隐藏层的输出作为Decoder的输入的一部分,再解码成为自然语言序列。
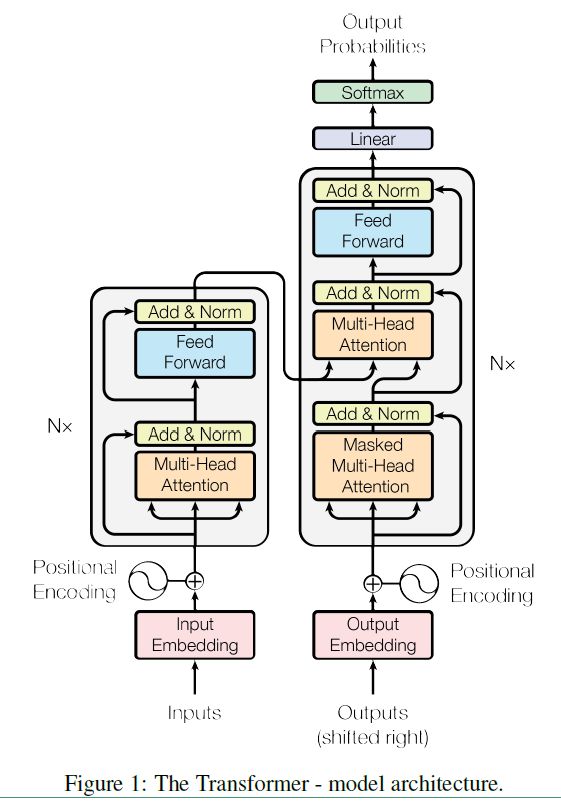
2. Encoder
由Figure1 可以看出,Encoder的构件包括:
- Input Embedding
- Positional Encoding
- Multi-Head Attention
- Add & Norm
- Feed Forward
一个一个来解析这些构件的作用。
Input Embedding
这一层的作用是 embedding 层是要将各个词转换成固定维度的向量,然后输入到下一层中。在BERT中,每个词会被转换成768维的向量表示。
Positional Encoding
Transformer 模型没有循环神经网络的迭代操作,无法编码输入的序列的顺序性。所以我们必须提供每个字的位置信息给 Transformer,这样它才能识别出语言中的顺序关系。
Multi-Head Attention
Multi-Head Attention是基于Self Attention的。那么为什么要用self-Attention呢?它有什么优点:
1) 可以并行化处理,在计算self-Attention是不依赖于其他结果的。
2)计算复杂度低。
3)self-Attention可以很好的捕获全局信息,无论词的位置在哪,词之间的距离都是1,因为计算词之间的关系时是不依赖于其他词的。在大量的文献中表明,self-Attention的长距离信息捕捉能力和RNN相当,远远超过CNN(CNN主要是捕捉局部信息,当然可以通过增加深度来增大感受野,但实验表明即使感受野能涵盖整个句子,也无法较好的捕捉长距离的信息)。
Add & Norm
Add类似于ResNet的残差模块,即,将输入x与输出f(x)直接相加,再传入下一层。这样可以加深网络深度,加快收敛。
Norm也就是Layer Normalization 。其作用是把神经网络中隐藏层归一为标准正态分布,也就是 i.i.d 独立同分布,以起到加快训练速度,加速收敛的作用。LN 是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
Feed Forward
这是由Full connected 网络构成。
3. Decoder
Decoder和Encoder的组成部件大致相似,只是结构设计有区别。Decoder的构件有:
- Output Embedding
- Positional Encoding
- Masked Multi-Head Attention
- Multi-Head Attention
- Add & Norm
- Feed Forward
- Linear
- Softmax
这里只简单介绍不同构件的作用。
Output Embedding
与Input embedding类似,不过它是将decoder的输出进行和encoder 中embedding类似的操作, 然后送入decoder的下一层。
Linear
线性映射
Softmax
通过计算输出矩阵权重来预测输出的token。
4. Positional Encoding
Positional Encoding,维度和embedding的维度一样。这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下

其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
PE向量和input embedding向量直接相加,送入下一层网络模块,也就是self attention 模块。
5. Self Attention
Self Attention的结构如下。
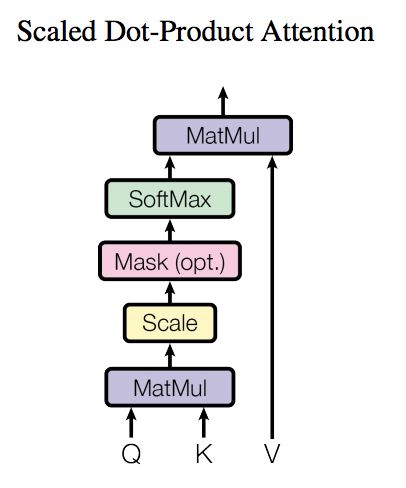
对于self-attention来讲,Q(Query), K(Key), V(Value)三个矩阵均来自同一输入,首先我们要计算Q与K之间的点乘,然后为了防止其结果过大,会除以一个尺度标度根号dk。再利用Softmax操作将其结果归一化为概率分布,然后再乘以矩阵V就得到权重求和的表示。该操作可以表示为

如果将输入的所有向量合并为矩阵形式,则所有query, key, value向量也可以合并为矩阵形式表示如下。 ,
, ,
,  是我们模型训练过程学习到的合适的参数。
是我们模型训练过程学习到的合适的参数。
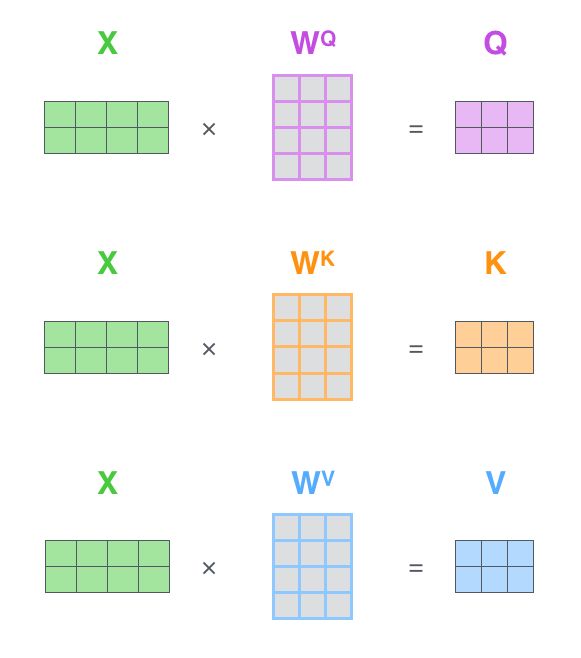
而multihead就是我们可以有不同的Q,K,V表示,最后再将其结果结合起来,如下图所示:

这就是基本的Multihead Attention单元,对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出.
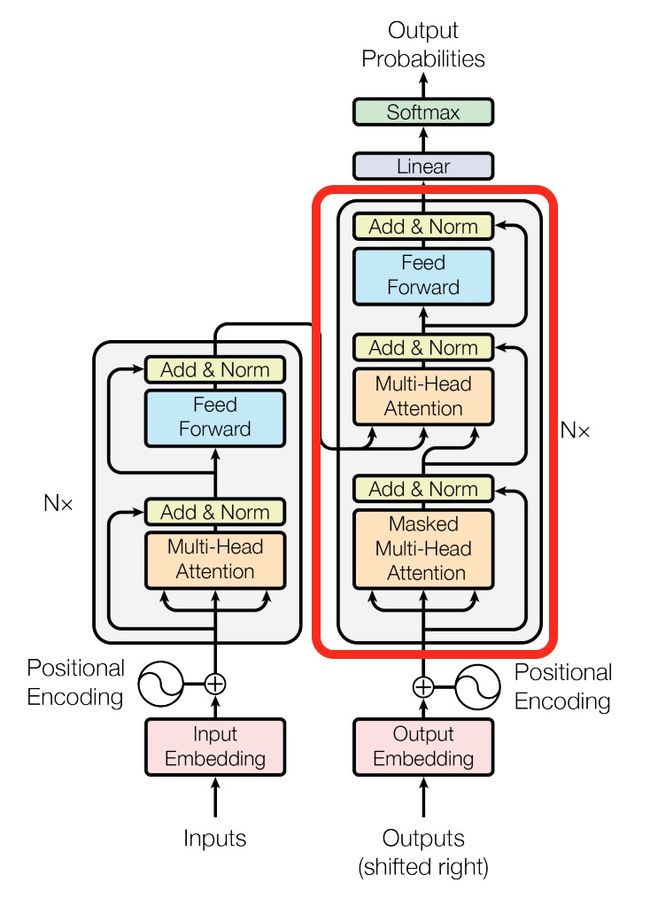
第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
而第二级decoder也被称作encoder-decoder attention layer,即它的query来自于之前一级的decoder层的输出,但其key和value来自于encoder的输出,这使得decoder的每一个位置都可以attend到输入序列的每一个位置。
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
6. Add & Norm
Add是指残差结构,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。

Norm是指层归一化,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
它们的作用是加深网络结构,加速收敛。
参考资料:
- https://zhuanlan.zhihu.com/p/47282410
- Attention Is All You Need
- Attention is all you need模型笔记