2020数模国赛c题论文latex
一个新手小组的论文,记录第一篇





















\documentclass{ctexart}
% \documentclass[12pt, a4paper]{article}
\usepackage{url}
\usepackage{appendix}
\renewcommand\appendix{\par
\setcounter{section}{0}
\setcounter{subsection}{0}
\gdef\thesection{附录 \Alph{section}}}
%\usepackage{listings}%插入代码
\usepackage{listings}
\usepackage{xcolor}
\lstset{
language=Matlab, %代码语言使用的是matlab
frame=shadowbox, %把代码用带有阴影的框圈起来
rulesepcolor=\color{red!20!green!20!blue!20},%代码块边框为淡青色
keywordstyle=\color{blue!90}\bfseries, %代码关键字的颜色为蓝色,粗体
commentstyle=\color{red!10!green!70}\textit, % 设置代码注释的颜色
showstringspaces=false,%不显示代码字符串中间的空格标记
numbers=left, % 显示行号
numberstyle=\tiny, % 行号字体
stringstyle=\ttfamily, % 代码字符串的特殊格式
breaklines=true, %对过长的代码自动换行
extendedchars=false, %解决代码跨页时,章节标题,页眉等汉字不显示的问题
% escapebegin=\begin{CJK*},escapeend=\end{CJK*}, % 代码中出现中文必须加上,否则报错
texcl=true}
\usepackage{xcolor}
\usepackage{graphicx}%插入表格
\usepackage{booktabs} %绘制表格
\usepackage{caption} %标题
\usepackage{geometry}
\usepackage{array}
\usepackage{amsmath}
\usepackage{subfigure} %插入图片
\usepackage{longtable}
\usepackage{abstract}%摘要
\pagestyle{plain} %页眉消失
\usepackage{setspace}
\usepackage{multirow}%表格
\usepackage{diagbox}
\usepackage{enumerate}%序号
\usepackage{float}%固定图片或表格的位置
\usepackage{gensymb}
\usepackage{microtype}
\geometry{a4paper,left=2.0cm,right=2.0cm,top=2.0cm,bottom=2.0cm}%页边距
\lstset{
numbers=left, %设置行号位置
numberstyle=\tiny, %设置行号大小
keywordstyle=\color{blue}, %设置关键字颜色
commentstyle=\color[cmyk]{1,0,1,0}, %设置注释颜色
escapeinside=``, %逃逸字符(1左面的键),用于显示中文
breaklines, %自动折行
extendedchars=false, %解决代码跨页时,章节标题,页眉等汉字不显示的问题
xleftmargin=1em,xrightmargin=1em, aboveskip=1em, %设置边距
tabsize=4, %设置tab空格数
showspaces=false %不显示空格
}
\title{银行对中小微企业的信贷决策模型}
%\RequirePackage[normalem]{ulem} %DIF PREAMBLE
\begin{document}
%\tableofcontents
\maketitle
\renewcommand{\abstractname}{\Large 摘要\\}
\begin{abstract}
\normalsize
本文在题目规定的为银行解决制定关于中小微企业的信贷策略的大思路下, 大致经历了处理中小微企业的发票信息, 对企业的信贷风险进行量化, 给出相应的信贷策略, 并探究突发因素与不同企业的影响, 增添指标给出调整策略。\par
在模型建立方面, 对于问题一, 本组建立了基本信誉判定模型、基于熵权法的信贷风险安全指数评价模型、基于遗传算法的最优信贷策略决策模型; 对于问题二, 本组建立了基于随机森林分配的信誉等级评价模型; 对于问题三, 本组建立了突发因素影响指数评价模型。\par
关于问题一,基本信誉判定模型,将信誉等级作为唯一指标,判定是否放贷,确定放贷的企业才会进入接下来的流程;信贷风险安全指数评价模型,我们规定了9个指标并用python进行求解,运用 MATLAB 软件编写熵权法程序, 计算出附件 1 中确定放贷的所有企业的信贷风险安全指数; 最优信贷策略决策模型, 首先拟合出目标函数所需的函数关系,然后采用遗传算法, 在较短的时间内, 计算对附件 1 中企业的信贷策略。本组以银行年度贷款总额为 1 亿元为例, 求解银行对每家企业的贷款额度和利率,并得到银行年度最大利润约为 $290.99$ 万元。\par
关于问题二,信誉等级评价模型, 我们运用了随机森林的方法, 以附件 1 中企业信息为训练和测试样本, 得到了较为可靠的预测模型, 然后对附件 2 中 302 家无信贷记录企业的信誉评级进行了预测。随后, 本组分别依据问题一中的评价和决策模型, 计算附件 2 中企业的信贷风险安全指数和具体信贷策略, 得到银行年度最大利润为 $260.83$ 万元。\par
关于问题三,突发因素影响指标评价模型, 我们首先规定了企业及突发事件的类别及关系,然后利用熵权topsis方法计算出相关指标,并巧妙的转化为了可以作为企业评价指标的评分,作为问题一中建立的信贷风险安全指数评价模型中的第10个指标,对附件 2 中的 302 家企业按照已建立的模型进行计算,得到调整后的企业信贷安全指数和信贷策略, 可知银行年度最大利润为 $320.98$ 万元。\par
最后, 我们分析了模型的优缺点, 提出了未来的改进方向。\par
本组模型的主要创新点有: 首先判定是否放贷,为接下来的运算减少数据;引入系列原创指标和函数, 包括基本信誉、突发因素影响指标和违约率函数等; 采用随机森林方法, 兼顾效率与准确性; 创新性地建立了企业特征和突发事件的分类描述体系, 为信贷策略调整提供基础。\par
~\\~\\
\textbf{关键字:信贷策略基本信誉\, 熵权法\, 信贷风险安全指数\, 随机森林\, 突发因素影响指数}
\end{abstract}
\newpage
\section{问题重述}
\subsection{问题背景}
中小微企业是是产业升级的新生力量和吸纳就业的重要的载体,对我国的经济发展具有重要的作用。而我国的经济发展正处在一个非常重要的转型阶段,国家越来越重视经济的高质量发展,适当的放缓了经济的发展速度。在宏观经济发展增速放缓的大背景下,中小微企业实力本身是较为薄弱的,资金对于中小微企业的发展也是较为重要的。\par
近年来,国家政策引导信贷供给侧加强对中小微企业的信贷投放。越来越多的中小微企业选择通过银行信贷的方式获得资金。中小微企业,顾名思义,规模较小,一般缺少抵押资产,对银行来说,如何建立对中小微企业进行风险评估的科学模型,合理分配好资金投放,科学制定给中小微企业的信贷策略,是一个不可避免的重要问题。因此,本问题在该背景下具有重要意义。
\subsection{问题要求}
现某银行已确定的贷款策略区间为:贷款额度为10-100万元;年利率为4\%-15\%;贷款期限为1年。并有3个附件提供相关数据,分别为:附件一123家有信贷记录的企业的相关数据;附件二302家无信贷相关记录的企业的相关数据;附件三银行贷款年利率与客户流失率关系的2019年统计数据。\par
基于上述背景和已知信息,我们需要建立数学模型以解决下列问题:\par
\begin{enumerate}[(1)]
\item 从123家有信贷记录企业的信誉数据与发票数据中汲取有效信息,分析其对于信贷风险的作用机理并量化,在银行的贷款总额度固定的基础上,确立对各企业的信贷策略。
\item 在(1)的模型的基础上,对302家无信贷记录企业的数据信息,量化各企业的信贷风险,并在银行的贷款总额度为1亿的基础上,确立对各企业的信贷策略。
\item 突发影响因素会对企业产生较大的影响,且对不同类型的企业会产生不同的影响(例如疫情的到来使线下服务业遭受重创,而使物流业获得较大的发展),针对附件二的302家企业,综合分析信贷风险和不同的突发影响因素对不同行业产生的影响,在银行的贷款总额度为1亿的基础上,确立对各企业的信贷调整策略。
\end{enumerate}
\section{模型假设}
\begin{enumerate}
\item 假设企业的信贷风险仅由题目中所反映的企业实力、信誉以及供求关系的稳定性所决定, 不考虑经营者情况等其他主观因素。
\item 假设计算企业总收益时不用考虑企业的其他成本以及其他需要缴纳的税额。
\item 假设同一种类企业受相同突发因素的影响相同, 同一类别企业内部的差异性为0。
\end{enumerate}
\section{符号说明}
\begin{center}
\setlength{\tabcolsep}{9mm}{
\begin{tabular}{ccc}
\toprule %添加表格头部粗线。
\textbf{符号} & \textbf{意义} & \textbf{单位}\\
\midrule %添加表格中横线
$_{i}$ & 第i家企业 & $\backslash$
\\
$_{j}$ & 第j月 & $\backslash$
\\
R & 信誉评级 & $\backslash$
\\
$ ^{i}$ & 进项 &$\backslash$
\\
$ ^{o}$ & 销项 &$\backslash$
\\
V & 发票作废率 & \%
\\
N & 负数发票率 & \%
\\
T & 月平均交易额 & ¥
\\
P & 月利润总额 &¥
\\
V & 月增值税总额 &¥
\\
m & 进项有效发票的有效月份 &月
\\
n & 销项有效发票的有效月份 &月
\\
k & 有效发票的有效月份交集 &月
\\
$\bar P$ & 月平均利润总额 &¥
\\
$\bar P^{'}$ & 平均月利润增长率&\%
\\
$I$ & 信贷风险安全指数&$\backslash$
\\
$W$ & 银行年信贷利润总额&万元
\\
$lr$ & 客户流失率&\%
\\
$d$ & 违约率&\%
\\
$r$ & 银行贷款年利率&\%
\\
$a$ & 银行贷款额度&万元
\\
$S_{o}$ & 年度信贷总额&元
\\
\bottomrule %添加表格底部粗线
\end{tabular}}
\end{center}
\section{问题分析}
该题目是在银行的角度下解决中小微企业的信贷问题,基本思路为通过分析各企业的信贷风险来确定各企业的信贷策略,即是否放贷、贷款利率额度和期限,其中期限已确定为1年。而问题一是针对123家有信贷记录的企业,问题二是针对302家无信贷记录的企业,问题三多加考虑了突发情况对企业的影响对信贷策略进行调整。可以看出,这三个问题是层层递进,一脉相承的。
\subsection{问题一分析}
根据题目已知的银行的信贷决策机理,可以得到信贷策略是根据各个企业的信誉和实力制定的。我们组通过讨论得到,针对信贷策略中的是否放贷,我们选择只根据各企业的基本信誉判定(信誉评级不为D且不违约),每一个信誉良好的企业都应该拥有一个机会获得资金,谋求发展。\par
接下来我们将对确定放贷的企业,建立信贷风险安全指数评定模型,来为制定信贷策略提供数据支撑。通过讨论我们得出九个评价指标,分别是信誉评级、进项发票作废率、销项发票作废率、进项负数发票率、销项负数发票率、进项平均交易额、销项平均交易额、月平均利润、月平均利润增长率。通过熵权法利用这些指标可以求出各企业的信贷风险安全指数综合评价得分,再进行归一化和排序。\par
最后建立基于目标优化的企业的最优信贷策略决策模型。建立该模型首先需要拟合银行贷款年利率与各信誉等级客户的流失率之间的关系,再确定函数拟合出违约率与信贷风险安全指数之间的关系。接下来表示出银行的贷款年度总收益为目标函数,表示出已经确定的两个关系函数以及题目已知为约束条件,利用遗传算法算出最终各企业的信贷策略。\par
大致思路为:
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.46]{1.png}
\caption{问题一分析流程图}
\label{fig0}
\end{figure}
\subsection{问题二分析}
将问题二和问题一进行比较可以看出,问题二与问题一都是为了得到企业的信贷策略。我们可以在第一问已经建立起的基于熵权法的信贷风险安全评价模型和基于遗传算法的银行最优信贷策略模型的基础上,对问题二进行求解。\par
通过比较也可以知道,问题二相较于问题一,所给数据中缺少企业的信贷等级这一指标,所以我们可以先建立其信贷等级评价模型,进而利用问题一中的模型对最优信贷策略进行规划决策。下面只对新出现的模型进行主要介绍,与问题一的重复步骤将不再赘述。\par
在建立信贷等级评价模型时,我们小组决定选用随机森林的机器学习方法,以附件一中的数据为样本,进行训练和测试,再应用于附件二,得到问题二中的目标企业的信贷评级。
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.6]{11.png}
\caption{问题二分析流程图}
\label{fig0}
\end{figure}
\subsection{问题三分析}
问题三是在问题一、二的基础上, 考虑突发因素对于企业经营状况以及盈利情况的影响。\par
我们首先需要对突发事件的类别、企业的类型进行定义和分类,因为突发事件对企业生产经营和经济效益所带来的影响大小不同。它取决于突发事件类别的不同、企业的行业类型以及类别的不同。\par
然后将突发事件与行业的分类联系起来, 并对影响程度做出具体的评价。\par
之后即可利用突发事件对企业影响产生的评价分数作为第十个指标,加入信贷风险安全指数评价模型中,之后与问题一的流程一致。
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.6]{23.png}
\caption{问题三分析流程图}
\label{fig0}
\end{figure}
\section{模型建立与求解}
\subsection{问题一模型的建立与求解}
\subsubsection{基本信誉判定}
根据题目:银行原则上对于信誉评级为D的企业不予放贷,所以我们规定基本信誉评判规则如下:信誉等级为D或违约的为“差”,否则为“好”。通过excel即可筛选出基本信誉为“差”的,进行不放贷策略;筛选出基本信誉为好的,进行放贷策略,并进入以下步骤制定更加详细的信贷策略。\par 共筛选出110家企业选择放贷,以下展示出部分筛选结果:
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.65]{3.png}
\caption{基本信誉判定为“好”即可以放贷的部分企业}
\label{fig0}
\end{figure}
\subsubsection{信贷风险安全指数评定指标体系}
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.57]{2.png}
\caption{信贷风险安全指数评定指标体系}
\label{fig0}
\end{figure}
\textbf{a.信誉评级 R}\par
信誉评级是由银行人工根据企业内部现状进行评定的,一定程度地反映了企业的信誉。由附件1可以直接得到目标企业的信誉评级,将各等级进行赋分量化:\par
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|c|c|}
\hline
A&B&C\\
5&3&1
\\
\hline
\end{tabular}
\end{table}
\textbf{b.进项发票作废率 $V^i$}\par
进项发票作废率即企业进货时开具的作废发票占总开具发票的比例。在一定程度上反映了该企业的上游产业链的稳定性以及该企业的信誉。利用python计算,对附件1数据处理,先对进项发票数量求和算出总数,再筛选出进项作废发票求和得数量,对两者进行除法运算。\par
\begin{center}
$ V^i_{i}$ = $ \frac{\mbox{进项作废发票数}}{\mbox{进项发票总数}}\times100\%$\\
\end{center}\par
其中, $V^i_{i}$即企业i在已知数据中得到的进货时开具的作废发票比例占总开具发票的比例。\par
\textbf{c.销项发票作废率 $V^o$}\par
销项发票作废率即企业售货时开具的作废发票占总开具发票的比例。在一定程度上反映了该企业的下游产业链的稳定性以及该企业的信誉。利用python计算,对附件1数据处理,先对销项发票数量求和算出总数,再筛选出销项作废发票求和得数量,对两者进行除法运算。\par
\begin{center}
$ V^o_{i}$ = $ \frac{\mbox{销项作废发票数}}{\mbox{销项发票总数}}\times100\%$\\
\end{center}\par
其中, $V^o_{i}$即企业i在已知数据中得到的售货时开具的作废发票比例占总开具发票的比例。\par
\textbf{d.进项负数发票率 $N^i$}\par
进项负数发票率即企业进货时开具的负数发票占有效发票的比例。在一定程度上反映了该企业的上游产业链的产品质量稳定性以及该企业的信誉。利用python计算,对附件1数据处理,先对进项有效发票数量求和算出总数,再筛选出进项负数发票求和得数量,对两者进行除法运算。\par
\begin{center}
$ N^i_{i}$ = $ \frac{\mbox{进项负数发票数}}{\mbox{进项有效发票数}}\times100\%$\\
\end{center}\par
其中, $ N^i_{i}$即企业i在已知数据中得到的进货时开具的负数发票比例占总开具发票的比例。\par
\textbf{e.销项负数发票率 $N^o$}\par
销项负数发票率即企业售货时开具的负数发票占有效发票的比例。在一定程度上反映了该企业的产品质量及其稳定性以及该企业的下游产业链的信誉情况。利用python计算,对附件1数据处理,先对销项有效发票数量求和算出总数,再筛选出销项负数发票求和得数量,对两者进行除法运算。\par
\begin{center}
$ N^o_{i}$ = $ \frac{\mbox{销项负数发票数}}{\mbox{销项有效发票数}}\times100\%$\\
\end{center}\par
其中, $ N^o_{i}$即企业i在已知数据中得到的售货时开具的负数发票比例占总开具发票的比例。\par
\textbf{f.进项月平均交易额 $T^i$}\par
进项月平均交易额即企业平均每月的进货额。在一定程度上反映了该企业的规模大小以及其上游产业链的规模大小和稳定性。利用python计算,对附件1数据处理,先对进项有效发票中的金额求和算出总额,再计算出进项有效发票的周期总月数,对两者进行除法运算。\par
\begin{center}
$T^i_{i}$ = $ \frac{\mbox{进项有效发票总金额}}{\mbox{进项有效发票总周期}}$\\
\end{center}\par
其中, $ T^i_{i}$即企业i在其进项有效发票的有效周期中可以得到的平均每月的进货额。\par
\textbf{g.销项月平均交易额 $T^o$}\par
销项月平均交易额即企业平均每月的售货额。在一定程度上反映了该企业规模及其产品的质量、受欢迎度等以及该企业的下游产业链的规模大小和稳定性。利用python计算,对附件1数据处理,对销项有效发票中的金额求和算出总额,再计算出销项有效发票的周期总月数,对两者进行除法运算。\par
\begin{center}
$ T^o_{i}$ = $ \frac{\mbox{销项有效发票总金额}}{\mbox{销项有效发票总周期}}$\\
\end{center}\par
其中, $ T^o_{i}$即企业i在其销项有效发票的有效周期中可以得到的平均每月的售货额。\par
\textbf{h.月平均利润总额 $\bar P$}\par
月平均利润总额即企业平均每月获得的利润总额。在一定程度上反映了该企业的获利能力(一家上市公司能否较快发展的关键也是公司股价的唯一动力)及该企业的规模大小。利用python计算,首先计算出每月的增值税总额,并利用各月的销项有效发票总额与进项有效发票总额,三者作差求得。\par
\begin{center}
k=$m\cap n$\\
$j\in k$\\
$V_{ij}$ =月销项有效发票税额-月进项有效发票税额\\
$P_{ij}$ =月销项有效发票金额-月进项有效发票金额-$V_{ij}$\\
$\bar P_{i}=\frac {P_{ij}}{k}$
\end{center}\par
其中, $V_{ij}$即企业i在j月的增值税总额;$P_{ij}$即企业i在j月的利润总额;m即企业i在其进项有效发票的有效月份;n即企业i在其销项有效发票的有效月份;k取m和n的交集;j属于k集。\par
\textbf{i.平均月利润增长率 $\bar P^{'}$}\par
平均月利润增长率即企业月利润增长额与上月利润总额的比率的平均值,反映企业营业利润的增减变动情况。在一定程度上反映了该企业的盈利能力和企业前景。利用python计算,先将企业在有效发票销项和进项的最小周期中的数据提取出来,然后根据公式计算。\par
\begin{center}
k=$m\cap n$\\
$j\in k$\\
$\bar P^{'}_{i}$ = $ {\frac{1}{k}}\times{\sum_{j=1}^{k}{{\frac{P_{ij+1}-P_{ij}}{P_{ij}}}\times 100\%}}$\\
\end{center}\par
其中, $ \bar P^{'}_{i}$即企业i在有效发票销项和进项的最小周期中可以得到的企业月利润增长额与上月利润总额的比率的平均值;k取m和n的交集;j属于k集;$P_{ij}$即企业i在j月的利润总额。\par
\subsubsection{信贷风险安全指数I评定模型}
通过上面的计算我们得到了各企业的各指标值,为建立信贷风险安全指数评定模型打下了基础。\par
接下来通过小组讨论,我们选择用熵权法计算各企业的信贷风险安全指数。熵值法是根据各项指标指标值的变异程度来确定指标权数的,这是一种客观赋权法,避免了人为因素带来的偏差。\par
~\par
在采用熵权法之前,对指标数值标准化。利用极差变换法将所有负向指标转化为正向指标。及进项发票作废率、销项发票作废率、进项负数发票率、销项负数发票率。经过讨论,利用python,采用"1-'所得相应数值'"的方法。由此所有的指标均正向表示,进入熵权法流程:\par
熵权法的评价步骤\par
设有 $n$ 个评价对象, $m$ 个评价指标变量,第 $i$ 个评价对象关于第 $j$ 个指标变量的取值 为 $a_{i j}(i=1,2, \cdots, n ; j=1,2, \cdots, m)$, 构造数据矩阵 $\boldsymbol{A}=\left(a_{i j}\right)_{n \times m}$ 。\par
基于樀权法的评价方法步骤如下:\\
(1) 利用原始数据矩阵 $\boldsymbol{A}=\left(a_{i j}\right)_{n \times m}$ 计算 $p_{i j}(i=1,2, \cdots, n, j=1,2, \cdots, m)$, 即第 $i$ 个评 价对象关于第 $j$ 个指标值的比重:
$$
p_{i j}=\frac{a_{i j}}{\sum_{i=1}^{n} a_{i j}}, i=1,2, \cdots, n, j=1,2, \cdots, m .
$$
(2) 计算第 $j$ 项指标的熵值:
$$
e_{j}=-\frac{1}{\ln n} \sum_{i=1}^{n} p_{i j} \ln p_{i j}, j=1,2, \cdots, m .
$$
(3) 计算第 $j$ 项指标的变异系数: $g_{j}=1-e_{j}, j=1,2, \cdots, m$.
对于第 $j$ 项指标, $e_{j}$ 越大, 指标值的变异程度就越小。
(4) 计算第 $j$ 项指标的权重:
$$
w_{j}=\frac{g_{j}}{\sum_{i=1}^{m} g_{j}}, j=1,2, \cdots, m .
$$
(5) 计算第 $i$ 个评价对象的综合评价值:
$$
s_{i}=\sum_{j=1}^{m} w_{j} p_{i j} .
$$
~\\~\\
\setlength{\tabcolsep}{9mm}{
\begin{tabular}{l}
\toprule %添加表格头部粗线。
\textbf{解题步骤} \\
\midrule %添加表格中横线
Step1 将数据导入Matlab, 对指标进行标准化处理\\
Step2 计算标准化后指标的熵值\\
Step3 计算各指标的差异系数\\
Step4 计算各指标的权重\\
Step5 分别用权重乘以归一化后的数据得到综合评价得分即信贷风险安全指数\\
\bottomrule %添加表格底部粗线
\end{tabular}}
~\\~\\~\\按照得到的信贷安全指数对企业进行排序,部分结果如下:\\
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.5]{4.png}
\caption{信贷安全指数部分排名}
\label{fig0}
\end{figure}
\subsubsection{最优信贷策略决策模型}
\textbf{a.目标函数总信贷利润W的确立}\par
以银行的总贷款利润W作为目标函数用来对银行向企业的贷款额 $\mathrm{a}$ 与贷款利率 $\mathrm{r}$ 进行决策。银行的起始总贷款利润为可以按期还款的企业所带来的利润减去不能按期还款的企业所带来的亏损;除此之外还要考虑客户流失率对于潜在客户流失所带来的利润值的流失。银行的总利润W表示如下:
$$
W=\left\{
\begin{aligned}
\sum_{i}^{x}[a \cdot r \cdot(1-\bar d_{A})-a \cdot \bar d_{A}] \cdot\left(1-lr_{A}\right)]\\
\sum_{i}^{y}[a \cdot r \cdot(1-\bar d_{B})-a \cdot \bar d_{B}] \cdot\left(1-lr_{B}\right)]\\
\sum_{i}^{z}[a \cdot r \cdot(1-\bar d_{C})-a \cdot \bar d_{C}] \cdot\left(1-lr_{C}\right)]\\
\end{aligned}
\right.
$$
上式中$a$代表贷款额, $r$ 代表贷款利率; $d$代表违约概率, $lr$表示相应的客户流失率; $x$ 、 $y$、 $z$ 分别表示在确定放贷的信誉等级A、B、C中的企业数量。其中:
$$
\left\{\begin{array}{c}
lr=lr(r)\\
d=d(I) \\
\end{array}\right.
$$
受到时间和能力的限制,我们将问题作了简化处理,取$d$的在各信誉等级的平均值,即$\bar d_{A}$、$\bar d_{B}$、$\bar d_{C}$,大大简化了式子的运算过程。
\textbf{b.拟合客户流失率lr与银行贷款年利率r函数}\par
根据附件3,在excel中拟合客户流失率与银行贷款年利率散点图。\par
首先对银行贷款年利率与A型客户流失率进行拟合。在作图过程中,我们发现无法使用指数和乘幂函数等模型,最终我们选择用对数、一次和二次模型来测试:\par
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.9]{5.png}
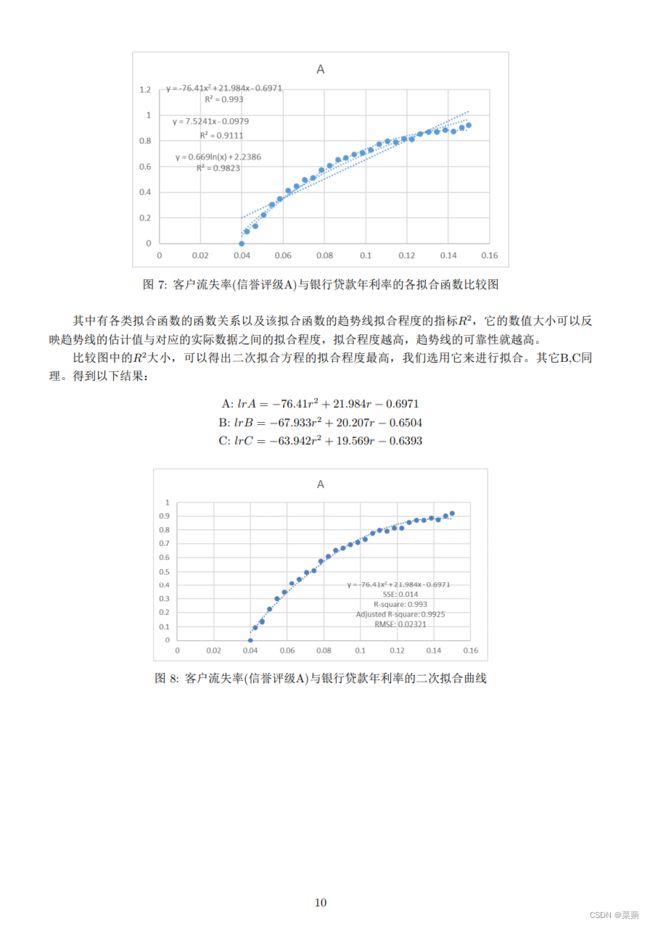
\caption{客户流失率(信誉评级A)与银行贷款年利率的各拟合函数比较图}
\label{fig0}
\end{figure}
其中有各类拟合函数的函数关系以及该拟合函数的趋势线拟合程度的指标$R^2$,它的数值大小可以反映趋势线的估计值与对应的实际数据之间的拟合程度,拟合程度越高,趋势线的可靠性就越高。\par
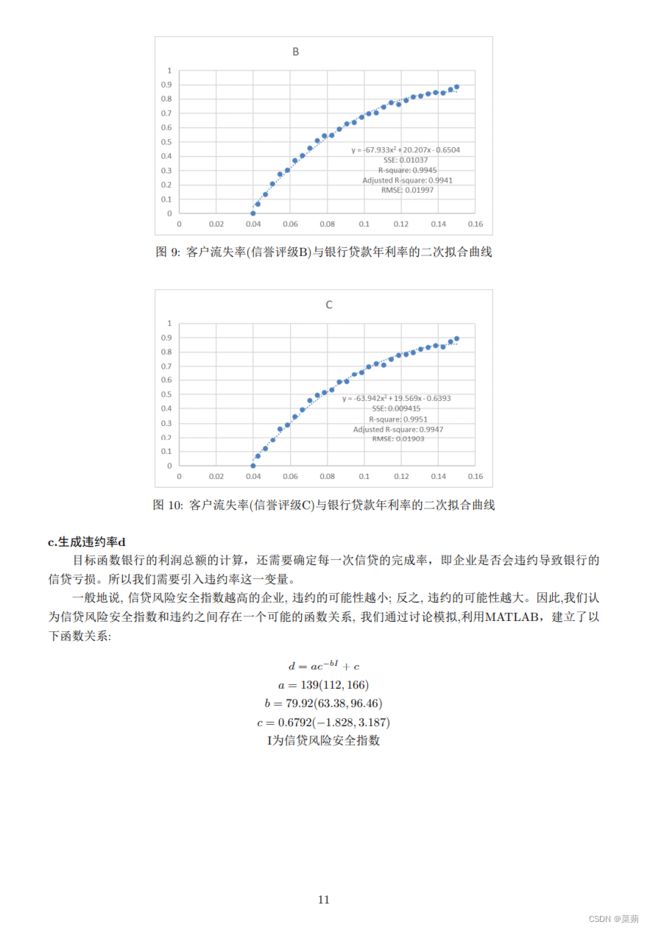
比较图中的$R^2$大小,可以得出二次拟合方程的拟合程度最高,我们选用它来进行拟合。其它B,C同理。得到以下结果:
\begin{center}
A: $lrA=-76.41 r^{2}+21.984 r-0.6971$\\
B: $lrB=-67.933 r^{2}+20.207 r-0.6504$\\
C: $lrC=-63.942 r^{2}+19.569 r-0.6393$\\
\end{center}
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.8]{6.png}
\caption{客户流失率(信誉评级A)与银行贷款年利率的二次拟合曲线}
\label{fig0}
\end{figure}
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.8]{7.png}
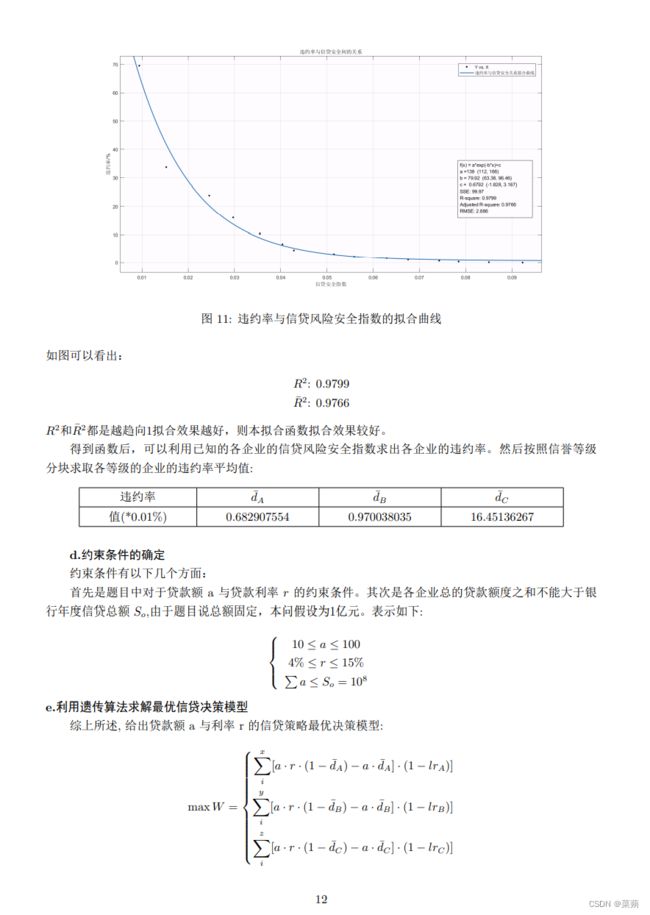
\caption{客户流失率(信誉评级B)与银行贷款年利率的二次拟合曲线}
\label{fig0}
\end{figure}
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.8]{8.png}
\caption{客户流失率(信誉评级C)与银行贷款年利率的二次拟合曲线}
\label{fig0}
\end{figure}
\textbf{c.生成违约率d}\par
目标函数银行的利润总额的计算,还需要确定每一次信贷的完成率,即企业是否会违约导致银行的信贷亏损。所以我们需要引入违约率这一变量。\par
一般地说, 信贷风险安全指数越高的企业, 违约的可能性越小; 反之, 违约的可能性越大。因此,我们认为信贷风险安全指数和违约之间存在一个可能的函数关系, 我们通过讨论模拟,利用MATLAB, 建立了以下函数关系:\par
\begin{center}
$d={ae}^{ -bI}+c$\\
$a=139(112,166)$\\
$b=79.92(63.38,96.46)$\\
$c=0.6792(-1.828,3.187)$\\
I为信贷风险安全指数\\
\end{center}
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.33]{9.png}
\caption{违约率与信贷风险安全指数的拟合曲线}
\label{fig0}
\end{figure}
如图可以看出:
\begin{center}
$R^{2}$: $0.9799$\\
$\bar R^{2}$: $0.9766$\\
\end{center}
$R^{2}$和$\bar R^{2}$都是越趋向1拟合效果越好,则本拟合函数拟合效果较好。\par
得到函数后,可以利用已知的各企业的信贷风险安全指数求出各企业的违约率。然后按照信誉等级分块求取各等级的企业的违约率平均值:\par
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|c|c|c|}
\hline
违约率&$\bar d_{A}$&$\bar d_{B}$&$\bar d_{C}$\\
\hline
值(*0.01\%)&0.682907554&0.970038035&16.45136267\\
\hline
\end{tabular}
\end{table}
\textbf{d.约束条件的确定}\par
约束条件有以下几个方面:\par
首先是题目中对于贷款额 a 与贷款利率 $r$ 的约束条件。 其次是各企业总的贷款额度之和不能大于银行年度信贷总额 $S_{o}$,由于题目说总额固定,本问假设为1亿元。 表示如下:\par
$$
\left\{\begin{array}{c}
10 \leq a \leq 100 \\
4 \% \leq r \leq 15 \% \\
\sum a \leq S_{o}=10^8
\end{array}\right.
$$
\textbf{e.利用遗传算法求解最优信贷决策模型}\par
综上所述, 给出贷款额 $\mathrm{a}$ 与利率 $\mathrm{r}$ 的信贷策略最优决策模型:\par
$$
\max W=\left\{
\begin{aligned}
\sum_{i}^{x}[a \cdot r \cdot(1-\bar d_{A})-a \cdot \bar d_{A}] \cdot\left(1-lr_{A}\right)]\\
\sum_{i}^{y}[a \cdot r \cdot(1-\bar d_{B})-a \cdot \bar d_{B}] \cdot\left(1-lr_{B}\right)]\\
\sum_{i}^{z}[a \cdot r \cdot(1-\bar d_{C})-a \cdot \bar d_{C}] \cdot\left(1-lr_{C}\right)]\\
\end{aligned}
\right.
$$\\
$$
st\left\{\begin{array}{c}
lr=lr(r) \\
\mathrm{d}=\mathrm{d}(\mathrm{I}) \\
10 \leq a \leq 100 \\
4 \% \leq r \leq 15 \% \\
\sum a \leq S_{o}=10^8
\end{array}\right.
$$
模型描述: $\mathrm{W}$ 为目标变量, $\mathrm{a}$ 与 $\mathrm{r}$ 为决策变量。
$\mathrm{W}$ 为总贷款利润; $\mathrm{d}$ 为违约概率, $lr$ 为客户流失率, $a$ 为贷款额度,$r$ 为贷款利率; $S_{o}$ 为银行年度信贷总额; $I$ 为信贷风险安全指数。\par
通过讨论分析,我们选择用遗传算法来计算本模型的最优解。\par
遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。具有具有很好的收敛性,在计算精度要求时,计算时间少,鲁棒性高等优点。它的具体流程如图:\\\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.6]{10.png}
\caption{遗传算法流程图}
\label{fig0}
\end{figure}
利用MATLAB计算,本问设信贷总额为1亿,具体代码及所选企业见附录。以下展示具体结果:\\
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|c|c|c|}
\hline
&利率&贷款金额(万元)& 总利润(万元)\\
\hline
A&0.058313 &94.4353345&\\
\hline
B&0.089032 &63.22714601&\\
\hline
C&0.081339&15.03350202& \\
\hline
W& & &290.9941538\\
\hline
\end{tabular}
\end{table}
综上所述,在选择供贷的企业中,信誉等级为A的企业,信贷方案为贷款利率0.058313,贷款金额为94.4353345万元;信誉等级为B的企业,信贷方案为贷款利率0.089032,贷款金额为63.22714601万元;信誉等级为C的企业,信贷方案为贷款利率0.081339,贷款金额为15.03350202万元;预估银行将获得的最大利润为290.9941538万元。
\subsection{问题二模型的建立与求解}
\subsubsection{基于随机森林分配的信誉评级评价模型}
首先对附件2中的企业的信誉等级进行评价,建立基于随机森林分配的信誉评级评价模型。\par
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。它具有很多优点,例如它可以处理大量的输入变数、学习过程是很快速的。这些优点正是我们所需要的。\par
随机森林的具体步骤为:
\begin{enumerate}[1)]
\item 从样本集中有放回随机采样选出n个样本;
\item 从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树;
\item 重复以上两步m次,即生成m棵决策树,形成随机森林;
\item 对于新数据,经过每棵树决策,最后投票确认分到哪一类。
\end{enumerate}
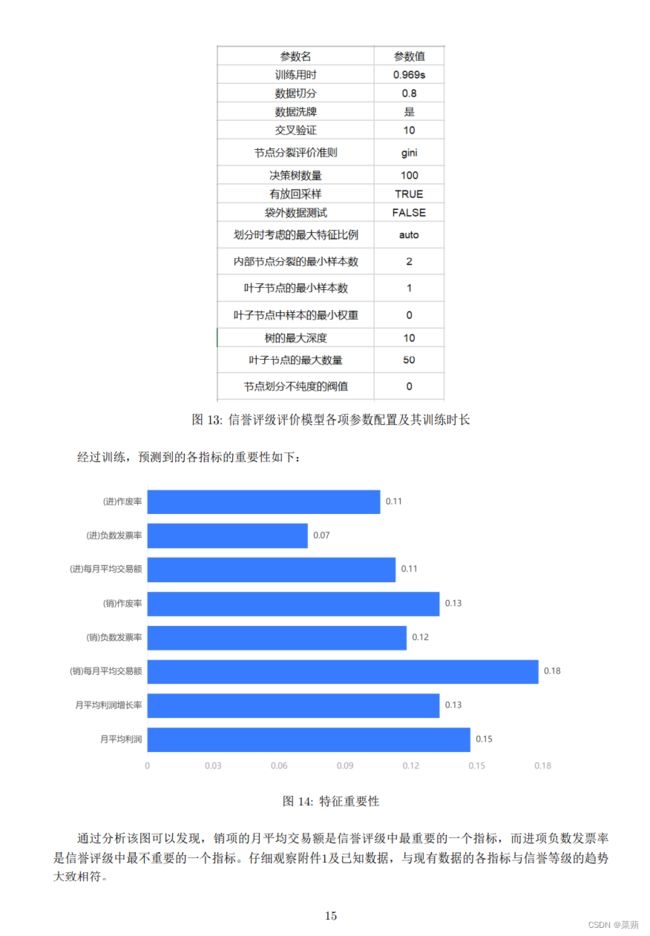
其中样本集为附件1中的企业数据及问题一求得的九项指标,我们将附件1的80\%的数据用作训练,20\%的数据用作测试。以下为模型参数配置及训练时长:\par
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=1.1]{12.png}
\caption{信誉评级评价模型各项参数配置及其训练时长}
\label{fig0}
\end{figure}
经过训练,预测到的各指标的重要性如下:\par
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.3]{13.png}
\caption{特征重要性}
\label{fig0}
\end{figure}
通过分析该图可以发现,销项的月平均交易额是信誉评级中最重要的一个指标,而进项负数发票率是信誉评级中最不重要的一个指标。仔细观察附件1及已知数据,与现有数据的各指标与信誉等级的趋势大致相符。\par
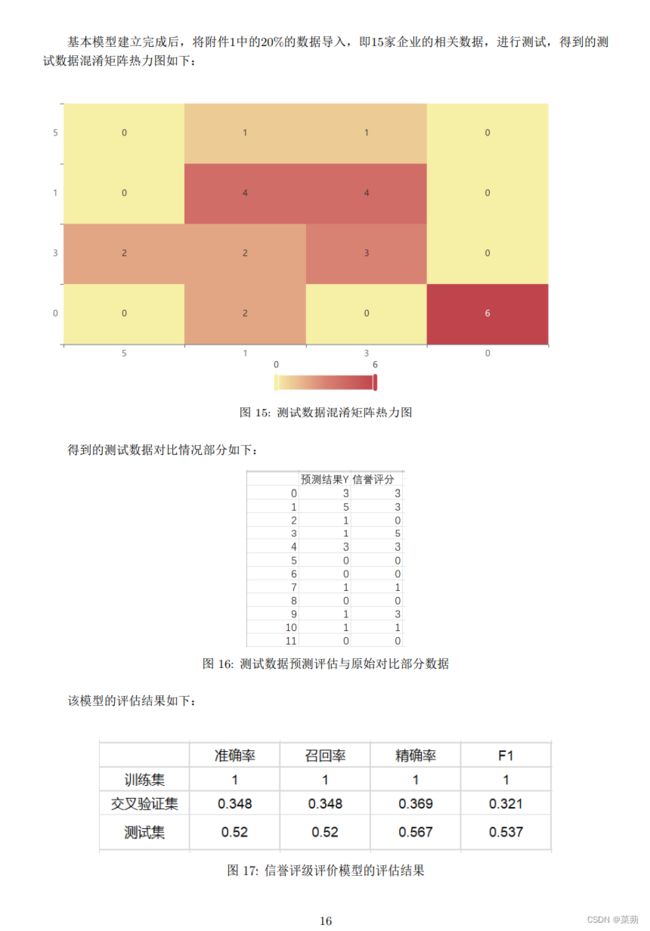
基本模型建立完成后,将附件1中的20\%的数据导入,即15家企业的相关数据,进行测试,得到的测试数据混淆矩阵热力图如下:
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.3]{14.png}
\caption{测试数据混淆矩阵热力图}
\label{fig0}
\end{figure}
得到的测试数据对比情况部分如下:
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.8]{16.png}
\caption{测试数据预测评估与原始对比部分数据}
\label{fig0}
\end{figure}
该模型的评估结果如下:\\
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=1.4]{15.png}
\caption{信誉评级评价模型的评估结果}
\label{fig0}
\end{figure}
上表中展示了训练集和测试集的分类评价指标,通过量化指标来衡量决策树对训练、测试数据的分类效果。\\
\begin{itemize}
\item 准确率: 预测正确样本占㣦样本的比例,准确率越大越好。
\item 召回率: 实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
\item 精确率: 预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
\item F1: 精确率和召回率的调和平均,精确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是精确率高、召回率就低,或者召回率低、但精确率高。
\end{itemize}\par
由图可知,测试集的各项指标满足>0.5的评价标准。选择该模型进行对附件2的302家企业进行信誉评估:\\
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=1]{18.png}
\caption{信誉评级评价模型的部分运算结果}
\label{fig0}
\end{figure}
其中评分为5的等级为A;评分为3的等级为B;评分为1的等级为C;由于D等级选择不放贷,不进入下面流程,所以已将等级为D的企业剔除。
\subsubsection{信贷风险安全指数I评定模型}
信贷风险安全指数评定指标体系的建立与问题一相同,不再赘述。同样利用python,计算出附件2中选择放贷的企业的各项指标,然后利用熵权法计算出信贷风险安全指数部分结果如下:\\
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.5]{19.png}
\caption{信贷风险安全指数的部分运算结果}
\label{fig0}
\end{figure}
\subsubsection{最优信贷策略决策模型}
按照问题一的运算步骤,将问题二所需数据代入,相关原理问题一已给出,不再赘述。得到结果如下:\\
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|c|c|c|}
\hline
&利率&贷款金额(万元)& 总利润(万元)\\
\hline
A&0.043484 &14.82425775&\\
\hline
B&0.048947 &72.33184177&\\
\hline
C& 0.148732&13.01169546& \\
\hline
W& & &260.8300117\\
\hline
\end{tabular}
\end{table}
综上所述,在选择供贷的企业中,信誉等级为A的企业,信贷方案为贷款利率0.043484,贷款金额为14.82425775万元;信誉等级为B的企业,信贷方案为贷款利率0.048947,贷款金额为72.33184177万元;信誉等级为C的企业,信贷方案为贷款利率 0.148732,贷款金额为13.01169546万元;预估银行将获得的最大利润为260.8300117万元。
\subsection{问题三模型的建立与求解}
\subsubsection{突发因素影响指数评价模型}
\textbf{a. 企业及突发事件的类别及关系的建立}\par
经过查找与讨论,我们将企业类别划分为建筑业、
制造业、
一般服务业、
高新技术产业、
文化产业这五大类,将突发事件的类别划分为自然灾害、事故灾难、公共卫生事件、社会安全事件这四类。
将影响指数规定为ABCD四种。具体划分关系如下:\par
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.7]{20.png}
\caption{类别及等级规定}
\label{fig0}
\end{figure}
根据规定,利用熵权TOPSIS即可求出每种行业在四种突发情况下的影响,可以获得对每种行业的突发因素影响指数:\par
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=1]{21.png}
\caption{不同突发事件对不同行业的影响指数}
\label{fig0}
\end{figure}
\subsubsection{最优信贷策略决策模型}
根据excel将企业划分类别后,将得到得指数值赋值到对应企业中,再按照信贷风险安全指数评定模型计算各企业得指标及权重及最后最终得分:\\
\begin{figure}[H] %插入图片
\centering
\includegraphics[scale=0.5]{22.png}
\caption{加入突发因素指标值后得附件2企业部分排名}
\label{fig0}
\end{figure}
再次利用遗传算法按照问题一的模型进行计算得到:
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|c|c|c|}
\hline
&利率&贷款金额(万元)& 总利润(万元)\\
\hline
A&0.062367 &56.0369379&\\
\hline
B&0.072954 &49.19543569&\\
\hline
C&0.136409&12.79127106& \\
\hline
W& & &320.983375\\
\hline
\end{tabular}
\end{table}
综上所述,调整后的方案为:在选择供贷的企业中,信誉等级为A的企业,信贷方案为贷款利率0.062367,贷款金额为56.0369379万元;信誉等级为B的企业,信贷方案为贷款利率0.072954,贷款金额为49.19543569万元;信誉等级为C的企业,信贷方案为贷款利率0.081339,贷款金额为12.79127106万元;预估银行将获得的最大利润为320.983375万元。\\
\section{模型评价与改进}
\subsection{模型优点}
\begin{enumerate}[(1)]
\item 与常规思路不同的是,我们首先将是否放贷这一策略单独考虑,从123家缩减到了110家,为之后的计算步骤缩减了计算量。
\item 利用随机森林方法对信誉等级进行评价,利用该方法的优势,提高了建模速度以及建模准确性。
\item 问题三中,巧妙的将突发事件影响指数转化为了可以对企业进行评价的指标,可以直接进入已建立的模型进行计算,简化了步骤。
\end{enumerate}
\subsection{模型缺点}
\begin{enumerate}[(1)]
\item 在计算发票作废率、负向发票率的时候,未考虑不同企业的不同周期带来的影响。如果有更充分的时间,还应为此建模拟合不同周期对发票率的影响程度。
\item 在建立信贷决策模型的时候,为了便于计算和节省时间,我们将违约率做了按照信誉等级求取平均值的处理,算出的结果不够准确。如果有更充分的时间并且提高我们的能力,还应寻找更加精确的方法来求取更加准确和个性化的信贷方案。
\item 在建立突发事件影响指数评价模型的时候,我们对突发事件的影响只规定了影响程度大小,没有规定影响类别,只考虑了负向影响,便展开了计算。如果有充裕的时间,我们将仔细考虑不同事件对不同企业的影响。
\end{enumerate}
%\section{参考文献}
\begin{thebibliography}{9} %参考文献
\bibitem{bib:one}司守奎,孙玺菁.数学建模算法与应用[M].北京:国防工业出版社,2016.
\bibitem{bib:one}李占山,杨云凯,张家晨.基于熵权法的过滤式特征选择算法[J].东北大学学报(自然科学版),2022,43(07):921-929.
\bibitem{bib:one}小小小鱼生活.百度知道[EB/OL].(2020-02-05).\url{https://zhidao.baidu.com/question/442487033.html}[2022-08-14]
\bibitem{bib:one}夜风博客.随机森林(原理/样例实现/参数调优)[EB/OL].(2022-08-11).\url{https://www.homedt.net/226166.html}[2022-08-14]
\bibitem{bib:one}吴昕玥. X银行中小企业信贷违约率研究[D].电子科技大学,2020.DOI:10.27005/d.cnki.gdzku.2020.000567.
\end{thebibliography}
%附录
%\begin{appendices}
% \section{文件列表}
% \section{补充表格、图片和公式推导}
% \section{代码}
%\end{appendices}
%附录
\begin{appendix}
\section{支撑材料清单}
\begin{table}[H]%最基本的表格
\centering
\begin{tabular}{|c|l|}
\hline
图片&1-23.png\\
\hline
表格&\begin{tabular}[c]{@{}l@{}}
问题一信贷风险安全指数结果.xlsx\\
问题一银行贷款年利率与客户流失率关系的统计数据及曲线关系.xlsx\\
问题一违约率与信贷风险安全指数.xlsx\\
问题二随机森林训练测试数据.xlsx\\
问题三企业分类结果.xlsx\\
问题三调整后信贷风险安全指数结果.xlsx
\end{tabular}\\
\hline
文件夹&\begin{tabular}[c]{@{}l@{}}
问题二随机森林评价信誉等级模型相关结果\\
问题三对数据进行分配相关代码
\end{tabular}\\
\hline
python&\begin{tabular}[c]{@{}l@{}}
求解后两项指标.py\\
求解前6项指标.py\\
熵权.py
\end{tabular}\\
\hline
\end{tabular}
\end{table}
\section{部分代码}
\begin{lstlisting}[language=python]
#[language=python]
#熵权法
import copy
import numpy as np
import pandas as pd
from scipy.stats import rankdata
data = pd.read_excel('E:\\secret garden\\数模\\暑期培训\\2020\\C\\结果.xlsx')
# 获取指标数字(正向化后的)
label_need = data.keys()[1:]
data1 = data[label_need].values
# 0.002~1区间归一化
[m, n] = data1.shape
data2 = copy.deepcopy(data1)
ymin = 0.002
ymax = 1
for j in range(0, n):
d_max = max(data1[:, j])
d_min = min(data1[:, j])
data2[:, j]= (ymax - ymin) * (data1[:, j] - d_min) / (d_max - d_min) + ymin
# print(data2)
# 计算信息熵
p = copy.deepcopy(data2)
for j in range(0,n):
p[:, j]=data2[:, j]/sum(data2[:, j])
# print(p)
E = copy.deepcopy(data2[0,:])
for j in range(0, n):
E[j]=-1/np.log(m)*sum(p[:, j]*np.log(p[:,j ]))
# print(E)
# 计算权重
w = (1-E)/sum(1-E)
print(w)
# 计算得分
s = np.dot(data2,w)
Score = s/max(s)
for i in range(0, len(Score)):
print(f"第{i}个评价对象得分为:{Score[i]}")
#求解指标的部分代码
import pprint
import openpyxl
import pandas as pd
wb = openpyxl.load_workbook('E:\\secret garden\\数模\\暑期培训\\2020\\C\\问题2\\进项.xlsx')
print("载入成功")
sheet = wb['进项发票信息']
data = {}
month = 0
year = 0
for row in range(2, sheet.max_row + 1):
ser_num = sheet['A' + str(row)].value
inv_state = int(sheet['J' + str(row)].value)
money = float(sheet['G' + str(row)].value)
x_month = int(sheet['D' + str(row)].value)
x_year = int(sheet['C' + str(row)].value)
data.setdefault(ser_num, {'voided_inv': 0, 'neg_inv': 0, 'eff_inv': 0, 'sum_inv': 0, 'eff_mon': 0,
'month': 0})
data[ser_num]['sum_inv'] += 1
if x_month != month or x_year != year:
data[ser_num]['month'] += 1
month = x_month
year = x_year
if inv_state == 1:
data[ser_num]['eff_inv'] += 1
data[ser_num]['eff_mon'] += money
if money < 0:
data[ser_num]['neg_inv'] += 1
else:
data[ser_num]['voided_inv'] += 1
print('计算结束')
# resultFile = open('res.py', 'w')
# resultFile.write(pprint.pformat(data))
key = list(data.keys())
value = list(data.values())
# 利用pandas模块先建立DateFrame类型,然后将两个上面的list存进去
result_excel = pd.DataFrame()
result_excel["词向量"] = key
result_excel["voided_inv"] = value
# 写入excel
result_excel.to_excel("E:\\secret garden\\数模\\暑期培训\\2020\\C\\消项结果.xlsx")
\end{lstlisting}
\begin{lstlisting}[language=matlab]
%[language=matlab]
%遗传算法部分代码
clear
clc
%遗传算法参数
maxgen =100; %最大迭代次数
sizepop = 50; %种群大小
pcross = 1; %交叉率 随机数小于该阈值时会交叉
pmutation = 1; %变异率
%
lenchrom = [1,1,1,1,1,1]; %变量个数为2
bound = [0.04,0.15;0.04,0.15;0.04,0.15;10,100;10,100;10,100]; %变量范围
T = 10000;
individuals = struct('fitness',zeros(1,sizepop),'chrom',[]); %个体,包含适应度值用数组储存和基因1
avefitness = []; %每带平均适应度
bestfitness = []; %最优适应度
bestchrom = []; %最优适应度对应编码
%个体初始化(初始化种群)
for i = 1 : sizepop
individuals.chrom(i,:) = code(lenchrom,bound,T); %调用Code函数对基因编码赋初值
x = individuals.chrom(i,:) ; %将个体赋值为x
individuals.fitness(i) = fun(x).w; %带入适应度函数fun计算适应度,fun就是目标函数
end
[bestfitness,bestindex] = min(individuals.fitness); %最好适应度及其指数
bestchrom = individuals.chrom(bestindex,:);
avefitness = sum(individuals.fitness) / sizepop;
trace=[];%记录优化过程中最好值的变化情况
for i = 1 : maxgen
individuals = Select(individuals,sizepop); %选择操作后的个体
individuals.chrom = Cross(pcross, lenchrom, individuals.chrom,sizepop,bound,T); %交叉操作
individuals.chrom = Mutation(pmutation,lenchrom,individuals.chrom,sizepop,[i,maxgen],bound,T); %当前代数,最大代数
for j = 1:sizepop
x = individuals.chrom(j,:) ; %将个体赋值为x
individuals.fitness(j) = fun(x).w; %带入适应度函数fun计算适应度,fun就是目标函数
end
[n_bestfitness,n_bestindex] = min(individuals.fitness); %最好适应度及其指数
if bestfitness > n_bestfitness
bestfitness = n_bestfitness;
bestchrom = individuals.chrom(n_bestindex,:);
end
avefitness = sum(individuals.fitness) / sizepop;
trace = [trace; bestfitness];
end
% figure
% plot((1:maxgen)',trace(:,1),'r-',(1:maxgen)',trace(:,2),'b-');
% title(['函数值曲线''终止代数=' num2str(maxgen)], 'fortsize' ,12);
% xlabel('进化代数','fortsize',12);
% ylabel('函数值','fortsize',12);
% legend('各代平均值','各代最佳值','fortsize',12);
%
% disp('函数值变量');
% disp([bestfitness,x]);
function y = fun(x)
Ra = x(:,1);
Rb = x(:,2);
Rc = x(:,3);
Qa = x(:,4);
Qb = x(:,5);
Qc = x(:,6);
ha = 0.00682907554;
hb = 0.00970038035;
hc = 0.1645136267;
La = pol(-76.41,21.984,-0.6971,Ra);
Lb = pol(-67.933,20.207,-0.6504,Rb);
Lc = pol(-63.942,19.569,-0.6393,Rc);
Wa = (Qa.*Ra.*(1-ha) - Qa.*ha).*(1-La);
Wb = (Qb.*Rb.*(1-hb) - Qb.*hb).*(1-Lb);
Wc = (Qc.*Rc.*(1-hc) - Qc.*hc).*(1-Lc);
res = struct('w',[],'q',[]);
res.w = -(27*Wa + 37*Wb +32*Wc);
res.q = 27*Qa+37*Qb + 32*Qc;
y = res;
% y = -(27*Wa + 37*Wb +32*Wc);
function ret = Select(individuals,sizepop)
fitness = individuals.fitness;
fitness = min(-fitness); %目标函数转化为适应度函数的值
if fitness < 0
fitness = individuals.fitness + abs(fitness)*ones(1,sizepop);
end
sumfitness = sum(fitness);
sumf = fitness ./ sumfitness; %每个个体被选择的概率
index = []; %被选中个体列表
%保证种群大小不变,转50次转盘
for i = 1 : sizepop
%生成选择的随机数
pick = rand;
while rand == 0
pick = rand;
end
for j = 1 : sizepop
pick = pick - sumf(j);
if pick < 0
index = [index,j]; %代表个体被选中
break;
end
end
end
individuals.chrom = individuals.chrom(index,:);
individuals.fitness = individuals.fitness(:,index);
ret = individuals;
function flag = test(lenchrom,bound,code,T)
flag = 1;
[n,~] = size(code);
for i = 1 : n
if code(i) < bound(i,1) || code(i) > bound(i,2)
flag = 0;
end
end
if fun(code).q > T
flag = 0;
end
function ret = Cross(pcross, lenchrom,chrom,sizepop,bound,T)
for i = 1 :sizepop
pick = rand(1,2); %选择两个个体进行交叉
while prod(pick) == 0
pick = rand(1,2);
end
index = ceil(pick .* sizepop); %[0,1]*种群个数向上取整
%判断是否交叉
pick = rand;
while pick == 0
pick = rand;
end
if pick > pcross
continue;
end
%进行交叉
flag = 0;
while flag == 0
pick = rand; %生成随机数确定交叉位点
while pick == 0
pick = rand;
end
pos = ceil(pick .* sum(lenchrom));
pick = rand;
v1 = chrom(index(1),pos);
v2 = chrom(index(2),pos);
chrom(index(1),pos) = pick * v2 + (1 - pick) * v1;
chrom(index(2),pos) = pick * v1 + (1 - pick) * v2;
flag1 = test(lenchrom,bound,chrom(index(1),:),T);
flag2 = test(lenchrom,bound,chrom(index(2),:),T);
if flag1*flag2==0
flag = 0;
else
flag = 1;
end
end
end
ret = chrom;
function ret = code(lenchrom,bound,T)
pick = rand(1,length(lenchrom));
p = bound(:,1)' + (bound(:,2)-bound(:,1))' .* pick; %最小值+区间段*[0,1]随机数
while fun(p).q>T
p = bound(:,1)' + (bound(:,2)-bound(:,1))' .* pick;
end
ret = p;
\end{lstlisting}
\end{appendix}
\end{document}