消息队列之RabbitMQ
消息队列之RabbitMQ
目录
-
- 消息队列之RabbitMQ
-
- 什么叫消息队列
- 为什么使用消息队列
-
- 1. 解耦
- 2 异步
- 3、削峰/限流
- 三 使用消息队列带来的一些问题
- 消息队列技术选型
- RabbitMQ
-
- 介绍
- 消息模型
- RabbitMQ 基本概念
-
- 名词解释
- RabbitMQ 安装
什么叫消息队列
-
消息队列,一般我们会简称它为MQ(Message Queue)翻译过来就是消息队列
-
消息(Message)是指在应用间传送的数据,Queue队列是一种先进先出的数据结构。
-
消息队列可以看成一个存放数据的容器,我们将传输的数据存放在队列当中。
-
消息发布者只管把数据发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取数据而不管是谁发布的。
为什么使用消息队列
我们通过模拟一些场景来告诉大家,消息队列有什么好处
参考知乎java3y
1. 解耦
现在我有一个系统A,系统A里面有一个UserId的属性, 系统A的一个方法是发送消息。
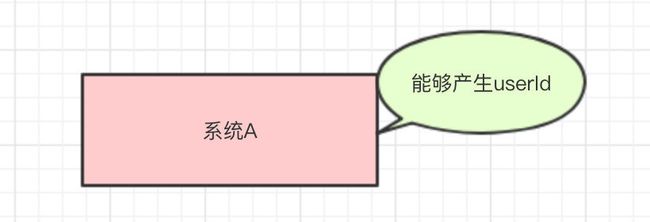
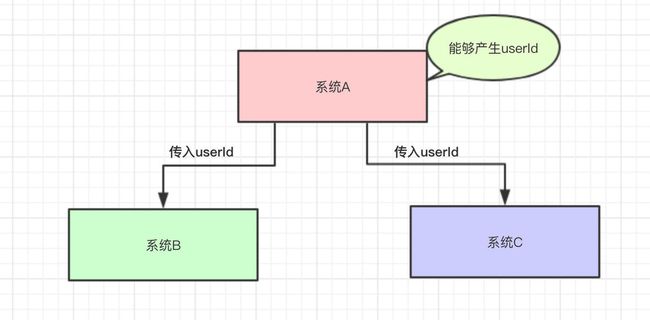
然后,系统A需要调用系统·B和系统C的接口去获取一些信息
然后,现在有系统B和系统C都需要这个findUser()去做相关的操作
写成伪代码可能是这样的:
public class SystemA {
// 系统B和系统C的依赖
SystemB systemB = new SystemB();
SystemC systemC = new SystemC();
// 系统A独有的数据userId
private String userId = "Java3y";
public void sendMessage() {
// 系统B和系统C都需要拿着系统A的userId去获取一些信息
systemB.getSomeInfo1(userId);
systemC.getSomeInfo2(userId);
}
}
ok,一切平安无事度过了几个天。
某一天,系统B的负责人告诉系统A的负责人,现在系统B的getSomeInfo1(String userId)这个接口不再使用了,让系统A别去调它了。
于是,系统A的负责人说"好的,那我就不调用你了。",于是就把调用系统B接口的代码给删掉了:
public void doSomething() {
// 系统A不再调用系统B的接口了
//systemB.getSomeInfo1(userId);
systemC.SystemCNeed2do(userId);
}
又过了几天,系统D的负责人接了个需求,也需要用到系统A的userId,于是就跑去跟系统A的负责人说:“老哥,我要用到你的userId,你调一下我的接口吧”
于是系统A说:“没问题的,这就搞”
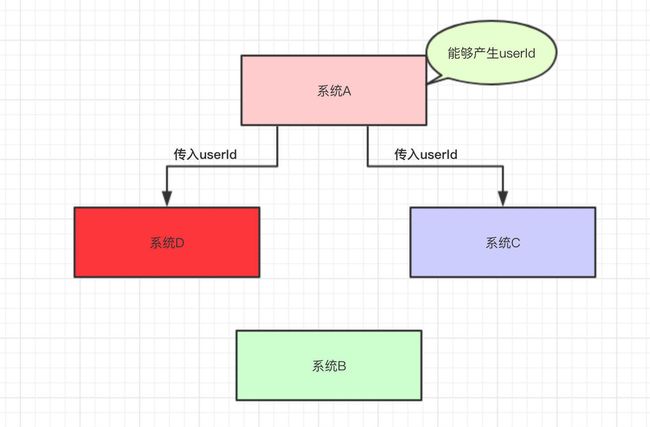
然后,系统A的代码如下:
public class SystemA {
// 已经不再需要系统B的依赖了
// SystemB systemB = new SystemB();
// 系统C和系统D的依赖
SystemC systemC = new SystemC();
SystemD systemD = new SystemD();
// 系统A独有的数据
private String userId = "Java3y";
public void doSomething() {
// 已经不再需要系统B的依赖了
//systemB.getSomeInfo1(userId);
// 系统C和系统D都需要拿着系统A的userId去操作其他的事
systemC.getSomeInfo2(userId);
systemD.getSomeInfo3(userId);
}
}
那这样下去每有一个人需用用A的userId, 我们就需要改一次系统A的代码,而且不仅如此,如果在调用系统C的时候,系统C挂了,系统A还得想办法处理。如果调用系统D时,由于网络延迟,请求超时了,那系统A是反馈fail还是重试?
然后有人跟系统A的负责人说将系统A的userId写到消息队列中,这样系统A就不用经常改动了。

系统A将userId写到消息队列中,系统C和系统D从消息队列中拿数据。这样有什么好处?
- 系统A只负责把数据写到队列中,谁想要或不想要这个数据(消息),系统A一点都不关心。
- 即便现在系统D不想要userId这个数据了,系统B又突然想要userId这个数据了,都跟系统A无关,系统A一点代码都不用改。
- 系统D拿userId不再经过系统A,而是从消息队列里边拿。系统D即便挂了或者请求超时,都跟系统A无关,只跟消息队列有关。
这样一来,系统A与系统B、C、D都解耦了。
2 异步
我们再来看看下面这种情况:系统A还是直接调用系统B、C、D
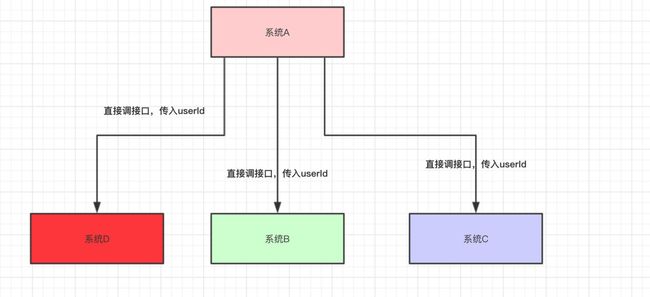
代码如下:
public class SystemA {
SystemB systemB = new SystemB();
SystemC systemC = new SystemC();
SystemD systemD = new SystemD();
// 系统A独有的数据
private String userId ;
public void doOrder() {
// 下订单
userId = this.order();
// 如果下单成功,则安排其他系统做一些事
systemB.SystemBNeed2do(userId);
systemC.SystemCNeed2do(userId);
systemD.SystemDNeed2do(userId);
}
}
假设系统A运算出userId具体的值需要50ms,调用系统B的接口需要300ms,调用系统C的接口需要300ms,调用系统D的接口需要300ms。那么这次请求就需要50+300+300+300=950ms
并且我们得知,系统A做的是主要的业务,而系统B、C、D是非主要的业务。比如系统A处理的是订单下单,而系统B是订单下单成功了,那发送一条短信告诉具体的用户此订单已成功,而系统C和系统D也是处理一些小事而已。
那么此时,为了提高用户体验和吞吐量,其实可以异步地调用系统B、C、D的接口。所以,我们可以弄成是这样的:
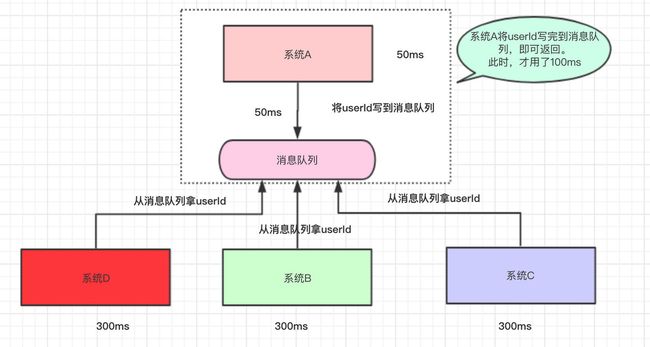
系统A执行完了以后,将userId写到消息队列中,然后就直接返回了(至于其他的操作,则异步处理)。
- 本来整个请求需要用950ms(同步)
- 现在将调用其他系统接口异步化,只需要100ms(异步)
3、削峰/限流
我们再来一个场景,现在我们每个月要搞一次大促,大促期间的并发可能会很高的,比如每秒3000个请求。假设我们现在有两台机器处理请求,并且每台机器只能每次处理1000个请求。

那多出来的1000个请求,可能就把我们整个系统给搞崩了…所以,有一种办法,我们可以写到消息队列中:

系统B和系统C根据自己的能够处理的请求数去消息队列中拿数据,这样即便有每秒有8000个请求,那只是把请求放在消息队列中,去拿消息队列的消息由系统自己去控制,这样就不会把整个系统给搞崩。
三 使用消息队列带来的一些问题
-
系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!

-
系统复杂性提高: 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!、
我们将数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了。如果没有做任何的措施,我们的数据就丢了。
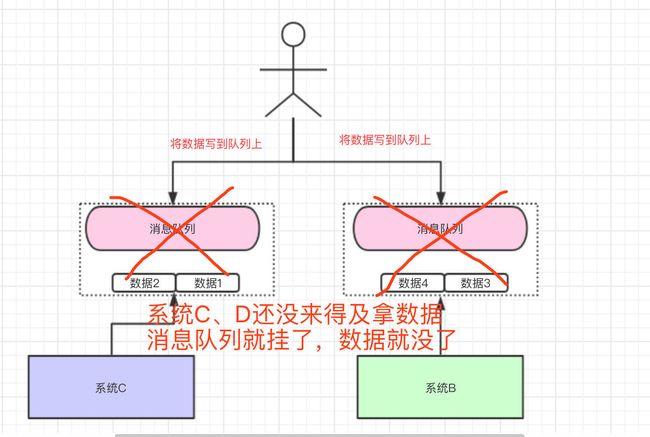
-
一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
除了这些,我们在使用的时候还得考虑各种的问题:
- 消息重复消费了怎么办啊?
- 我想保证消息是绝对有顺序的怎么做?
- ………
消息队列技术选型
我们自己来处理这些逻辑显得有些复杂,但我们可以选用市面上常见的几种MQ技术kafka、activeMq、rabbitMq、rocketMq
让我们先看下他们的优缺点
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 万级,吞吐量比RocketMQ和Kafka要低了一个数量级 | 10万级,RocketMQ也是可以支撑高吞吐的一种MQ | 10万级别,这是kafka最大的优点,就是吞吐量高。 |
| topic数量对吞吐量的影响 | topic数量对吞吐量的影响 | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | ||
| 时效性 | ms级 | 微秒级,这是rabbitmq的一大特点,延迟是最低的 | ms级 | 延迟在ms级以内 |
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 高,基于主架构实现高可用性 | 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,消息可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用,偶尔会有较低概率丢失消息 | erlang语言开发,性能极其好,延时很低;吞吐量到万级,MQ功能比较完备,而且开源提供的管理界面非常棒,用起来很好用,社区相对比较活跃,几乎每个月都发布几个版本分,在国内一些互联网公司近几年用rabbitmq也比较多一些,但是问题也是显而易见的,RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重。而且erlang开发,国内有几个公司有实力做erlang源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复bug。而且rabbitmq集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是erlang语言本身带来的问题。很难读源码,很难定制和掌控。而且现在社区以及国内应用都越来越少,官方社区现在对ActiveMQ 5.x维护越来越少,几个月才发布一个版本。而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是ok的,还可以支撑大规模的topic数量,支持复杂MQ业务场景。而且一个很大的优势在于,阿里出品都是java系的,我们可以自己阅读源码,定制自己公司的MQ,可以掌控社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准JMS规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ挺好的 | 号称大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开Kafka,这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输、存储的过程中发挥着举足轻重的作用 |
这里我选用的是RabbitMQ,因为项目规模还是挺小的,达不到10万级的吞吐量,且他的社区活跃性高,功能比较完备。
RabbitMQ
介绍
RabbitMQ是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于AMQP协议的。
Erlang语言最初在于交换机领域的架构模式,这样使得RabbitMQ在Broker之间进行数据交互的性能是非常优秀的
Erlang的优点:Erlang有着和原生Socket一样的延迟
AMQP定义:是具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
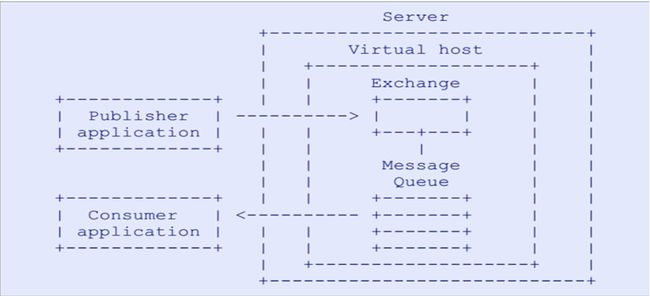
消息模型
所有 MQ 产品从模型抽象上来说都是一样的过程:
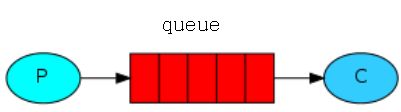
消费者(consumer)订阅某个队列。生产者(producer)创建消息,然后发布到队列(queue)中,最后将消息发送到监听的消费者。
RabbitMQ 基本概念
上面只是最简单抽象的描述,具体到 RabbitMQ 则有更详细的概念需要解释。上面介绍过 RabbitMQ 是 AMQP 协议的一个开源实现,所以其内部实际上也是 AMQP 中的基本概念:

名词解释
Message
消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
Publisher
消息的生产者,也是一个向交换器发布消息的客户端应用程序。
Exchange
交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Binding
绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
Queue
消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
Connection
网络连接,比如一个TCP连接。
Channel
信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
Consumer
消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
Virtual Host
虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
Broker
表示消息队列服务器实体。
从以上可以看出rabbitMQ工作原理大致就是producer把一条消息发送给exchange。rabbitMQ根据routingKey负责将消息从exchange发送到对应绑定的queue中去,这是由rabbitMQ负责做的,而consumer只需从queue获取消息即可。
大致流程如下:

RabbitMQ 安装
一般来说安装 RabbitMQ 之前要安装 Erlang ,可以去Erlang官网下载。接着去RabbitMQ官网下载安装包,之后解压缩即可。根据操作系统不同官网提供了相应的安装说明:Windows、Debian / Ubuntu、RPM-based Linux、Mac
在这里我们在自己的服务器里安装rabbitMQ
用docker安装rabbitMQ
# 拉取rabbitmq镜像
docker pull rabbitmq
# 启动rabbitmq容器
docker run -d --name myRabbitmq -p 5672:5672 -p 15672:15672 -v `pwd`/data:/var/lib/rabbitmq 7471fb821b97
说明:
7471fb821b97 为 IMAGE ID
- -d 后台运行容器;
- –name 指定容器名;
- -p 指定服务运行的端口(5672:应用访问端口;15672:控制台Web端口号);
- -v 映射目录或文件;
RabbitMQ默认禁用了管理界面,需要通过命令重新开启管理界面,
#进入容器
docker exec -it rabbitmq bash
#开启管理界面
rabbitmq-plugins enable rabbitmq_management
记得打开安全组
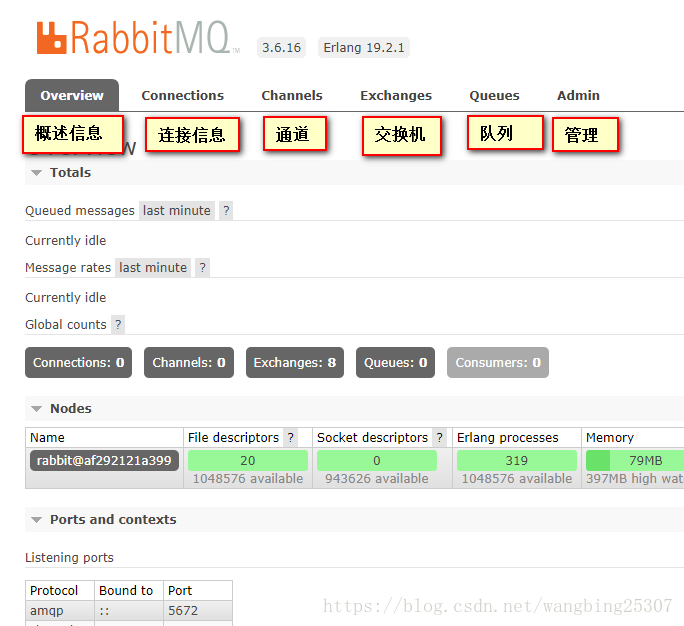
访问15672端口出现下面界面代表RabbitMQ安装成功
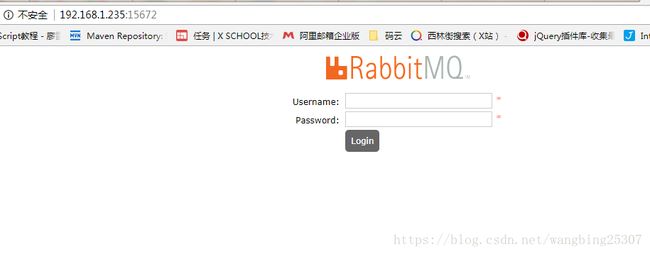
默认账号密码都为guest