Hadoop / HDFS / Spark / HBase知识点 + 区别
Hadoop
hadoop调度器
Hadoop中常见的调度器有三种,分别为:
FIFO调度器、公平调度器Fair Scheduler、容量调度器Capacity Scheduler(计算能力调度器)
作用是将系统中空闲的资源按一定策略分配给作业。在Hadoop中,调度器是一个可插拔的模块,用户可以根据自己的实际应用要求设计调度器。
考虑因素:
- 作业优先级。作业的优先级越高,它能够获取的资源(slot数目)也越多。Hadoop 提供了5种作业优先级,分别为 VERY_HIGH、HIGH、NORMAL、 LOW、VERY_LOW,通过mapreduce.job.priority属性来设置。
- 作业提交时间。顾名思义,作业提交的时间越早,就越先执行。
- 作业所在队列的资源限制。调度器可以分为多个队列,不同的产品线放到不同的队列里运行。不同的队列可以设置一个边缘限制,这样不同的队列有自己独立的资源,不会出现抢占和滥用资源的情况。
hadoop调度器概念及区别_小学僧来啦的博客-CSDN博客
HDFS 分布式文件系统
适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变
HDFS 优缺点
HDFS优点
- 高容错性: 数据自动保存多个副本。它通过增加副本的形式,提高容错性, 某一个副本丢失以后,它可以自动恢复。
- 适合处理大数据 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据; 某一个副本丢失以后,它可以自动恢复。文件规模:能够处理百万规模以上的文件数量,数量相当之大。
- 可构建在廉价机器上,通过多副本机制,提高可靠性。
HDFS缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储。存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
- 不支持并发写入、文件随机修改。 一个文件只能有一个写,不允许多个线程同时写;仅支持数据append(追加),不支持文件的随机修改。
HDFS 组成架构
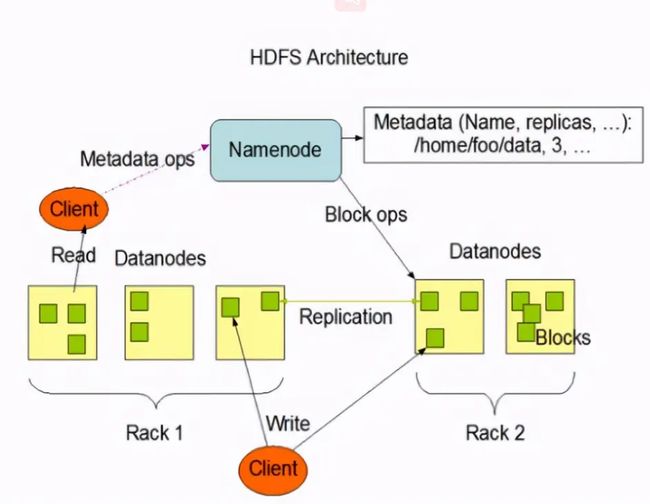
- NameNode(nn):就是Master,它 是一个主管、管理者。 (1)管理HDFS的名称空间; (2)配置副本策略; (3)管理数据块(Block)映射信息; (4)处理客户端读写请求。
- DataNode:就是Slave。NameNode 下达命令,DataNode执行实际的操作。 (1)存储实际的数据块; (2)执行数据块的读/写操作。
- Client:就是客户端。 (1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传; (2)与NameNode交互,获取文件的位置信息; (3)与DataNode交互,读取或者写入数据; (4)Client提供一些命令来管理HDFS,比如NameNode格式化; (5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
- Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不 能马上替换NameNode并提供服务。 (1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ; (2)在紧急情况下,可辅助恢复NameNode。
HDFS 存放策略(面试重点)
数据块
- 每个磁盘都有默认数据块大小,这个数据块就是磁盘存取得最小的单位。
- 磁盘块的大小一般为512字节
- 数据块的大小小于512字节,他的空间也会被占用。
HDSF 数据块
- HDFS也有数据块得大小,大小以前为64M,当前得大小为128M 。
- 如果该块没有存满,不会占用整个数据块得空间。
HDFS 文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数 ( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
块大小设置原则:最小化寻址开销,减少网络传输
寻址时间:HDFS中找到目标文件块(block)所需要的时间。
原理:
文件块越大,寻址时间越短,但磁盘传输时间越长;
文件块越小,寻址时间越长,但磁盘传输时间越短。

- HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
- 如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开 始位置所需的时间。导致程序在处理这块数据时,会非常慢。
- 总结:HDFS块的大小设置主要取决于磁盘传输速率。
副本放置策略:
- 网络拓扑
HDFS 的读写流程(面试重点)
HDFS 写数据流程
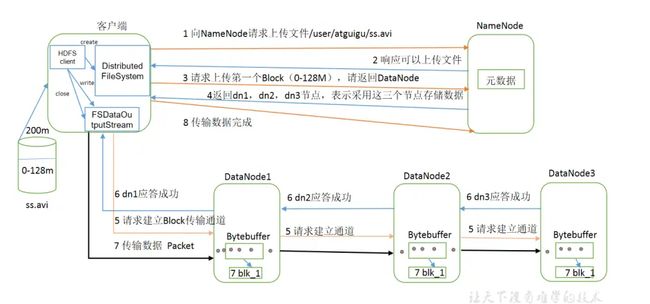
- 客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检 查目标文件是否已存在,父目录是否存在。
- NameNode 返回是否可以上传。
- 客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
- NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。
- 客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
- dn1、dn2、dn3 逐级应答客户端。
- 客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存), 以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet 会放入一个应答队列等待应答。
- 当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务 器。(重复执行 3-7 步)。
HDFS 读数据流程

- 客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查 询元数据,找到文件块所在的 DataNode 地址。
- 挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位 来做校验)。
- 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
HDFS详解 - 哔哩哔哩
Hadoop和Spark比较:
前言
Spark,是分布式计算平台,是一个用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎。
Hadoop,是分布式管理、存储、计算的生态系统;包括HDFS(存储)、MapReduce(计算)、Yarn(资源调度)。
尽管Hadoop具有许多重要的功能和数据处理优势,但它仍存在一个主要缺点。Hadoop的本地批处理引擎MapReduce不如Spark快。
这就是Spark超越Hadoop的优势。除此之外,当今大多数大数据项目都需要批处理工作负载以及实时数据处理。Hadoop的MapReduce并不适合它,只能处理批处理数据。
此外,当需要低延迟处理大量数据时,MapReduce无法做到这一点。因此,我们需要在Hadoop之上运行Spark。借助其混合框架和弹性分布式数据集(RDD),可以在运行Spark时将数据透明地存储在内存中。
您可以在独立模式下在没有Hadoop的情况下运行Spark
Spark和Hadoop更好地结合在一起Hadoop对于运行Spark并不是必不可少的。如果查看Spark文档,则提到如果以Standalone(独立模式)运行Spark,则不需要Hadoop。
在这种情况下,您仅需要Mesos之类的资源管理器。此外,只要您不需要Hadoop生态系统中的任何库,就可以在没有Hadoop的情况下运行Spark,并在具有Mesos的Hadoop群集上独立运行。
没有HDFS的情况下如何运行Spark?
HDFS只是Spark支持的文件系统之一,而不是最终答案。 Spark是集群计算系统,而不是数据存储系统。运行数据处理所需的全部就是一些外部数据存储源来存储和读取数据。
它可能是您桌面上的本地文件系统。此外,除非您在HDFS中使用任何文件路径,否则无需运行HDFS。但是,Spark On Yarn 必须要运行HDFS,因为会使用HDFS存储临时文件。
需要Hadoop运行Spark
Hadoop和Spark不是互斥的,可以一起工作。没有Spark,就不可能在Hadoop中进行实时,快速的数据处理。另一方面,Spark没有用于分布式存储的任何文件系统。
但是,许多大数据项目需要处理数PB的数据,这些数据需要存储在分布式存储中。因此,在这种情况下,Hadoop的分布式文件系统(HDFS)与资源管理器YARN一起使用。
因此,如果使用HDFS在分布式模式下运行Spark,则可以通过连接集群中的所有项目来获得最大的收益。因此,HDFS是Hadoop在分布式模式下运行Spark的主要需求。
结论
因此, 我们得出结论, 我们可以在没有Hadoop的情况下运行Spark 。但是,如果我们在HDFS或类似文件系统上运行Spark,则可以实现数据处理的最大利益。而且,Spark和Hadoop都是开源的,由Apache维护。因此它们彼此兼容。此外,使用第三方文件系统解决方案设置Spark可能会很复杂。
因此,很容易将Spark与Hadoop集成,在Hadoop之上运行Spark是最好的解决方案。
三大分布式计算系统
- Hadoop适合处理离线的静态的大数据;
- Spark适合处理离线的流式的大数据;
- Storm/Flink适合处理在线的实时的大数据。
在Hadoop中运行Spark的不同方法
有三种在Hadoop集群中部署和运行Spark的方法。
- 单机版
- 超过YARN
- 在MapReduce(SIMR)中
独立部署(Standalone)
这是最简单的部署模式。在独立模式下,资源静态分配在Hadoop集群中所有或部分节点上。但是,您可以与MapReduce并行运行Spark。这是Hadoop 1.x的首选部署选择。 在这种模式下,Spark管理其集群。
通过YARN部署
没有预安装,或者在这种部署模式下需要管理员访问权限。因此,这是Hadoop和Spark之间集成的简便方法。这是确保安全性的唯一集群管理器。对于生产环境中的大型Hadoop集群而言,这是更好的选择。
MapReduce(SIMR)中的Spark
在这种部署模式下,不需要YARN。可以在MapReduce中启动Rather Spark作业。
为什么企业更喜欢使用Hadoop运行Spark?
Spark的生态系统包括–
- Spark核心–数据处理的基础
- Spark SQL –基于Shark,有助于数据提取,加载和转换
- Spark流传输– Light API帮助进行批处理和数据流传输
- 机器学习库–帮助实施机器学习算法。MLlib
- Graph Analytics(GraphX)–帮助表示弹性分布式图
- Spark Cassandra连接器
- Spark R集成
MapReduce和Spark比较:
Hadoop MapReduce采用了多进程模型,而Spark采用了多线程模型:
二者在server端采用了一致的异步并发模型,但在任务级别(特指 Spark任务和MapReduce任务)上却采用了不同的并行机制:多进程和多线程
注意,本文的多进程和多线程,指的是同一个节点上多个任务的运行模式。无论是MapReduce和Spark,整体上看,都是多进程:MapReduce应用程序是由多个独立的Task进程组成的;Spark应用程序的运行环境是由多个独立的Executor进程构建的临时资源池构成的。
多进程模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间,不适合运行低延迟类型的作业。多线程模型相反,任务启动速度快。
Spark同节点上所有任务运行在一个进程中,有利于共享内存。这非常适合内存密集型任务,尤其对于那些需要加载大量词典的应用程序,可大大节省内存。
Spark同节点上所有任务可运行在一个JVM进程(Executor)中,且Executor所占资源可连续被多批任务使用,不会在运行部分任务后释放掉,这避免 了每个任务重复申请资源带来的时间开销,对于任务数目非常多的应用,可大大降低运行时间。与之对比的是MapReduce中的Task:每个Task单独 申请资源,用完后马上释放,不能被其他任务重用,尽管1.0支持JVM重用在一定程度上弥补了该问题,但2.0尚未支持该功能。
但是,spark由于同节点上所有任务运行在一个进程中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源。与之相 反的是MapReduce,它允许用户单独为Map Task和Reduce Task设置不同的资源,进而细粒度控制任务占用资源量,有利于大作业的正常平稳运行。
总体上看,Spark采用的是经典的scheduler/workers模式, 每个Spark应用程序运行的第一步是构建一个可重用的资源池,然后在这个资源池里运行所有的ShuffleMapTask和ReduceTask(注 意,尽管Spark编程方式十分灵活,不再局限于编写Mapper和Reducer,但是在Spark引擎内部只用两类Task便可表示出一个复杂的应用 程序,即ShuffleMapTask和ReduceTask),而MapReduce应用程序则不同,它不会构建一个可重用的资源池,而是让每个 Task动态申请资源,且运行完后马上释放资源。
HBase
Hbase:nosql数据库,和mongodb类似
hbase是以hdfs为存储介质的,因此它具有分布式存储拥有的所有优点
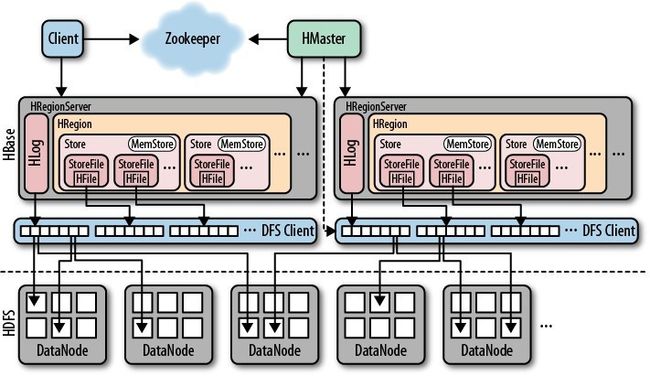
- HMaster负责管理HRegionServer以实现负载均衡,负责管理和分配HRegion(数据分片),还负责管理命名空间和table元数据,以及权限控制
- HRegionServer负责管理本地的HRegion、管理数据以及和hdfs交互。
- Zookeeper负责集群的协调(如HMaster主从的failover)以及集群状态信息的存储
客户端传输数据直接和HRegionServer通信
Hive和HBase区别
Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。Hive本身不存储数据,它完全依赖HDFS和MapReduce。这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能,并将SQL语句最终转换为MapReduce任务进行运行。 而HBase表是物理表,适合存放非结构化的数据。
- 两者分别是什么?
Apache Hive是数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询–因为它是基于MapReduce算法。
Apache Hbase Key/Value,基础单元是cell,它运行在HDFS之上。和Hive不一样,Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务.
- 2. 限制
Hive目前不支持更新操作。另外,由于hive在hadoop上运行批量操作,它需要花费很长的时间,通常是几分钟到几个小时才可以获取到查询的结果。Hive必须提供预先定义好的schema将文件和目录映射到列,并且Hive与ACID不兼容。
HBase查询是通过特定的语言来编写的,这种语言需要重新学习。类SQL的功能可以通过Apache Phonenix实现,但这是以必须提供schema为代价的。另外,Hbase也并不是兼容所有的ACID特性,虽然它支持某些特性。最后但不是最重要的–为了运行Hbase,Zookeeper是必须的,zookeeper是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务。
- 3. 应用场景
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。
大数据面试题汇总
大数据面试(七)_2018年大数据面试题总结 - 哔哩哔哩
引用:
Spark——需要HADOOP来运行SPARK吗? - 曹伟雄 - 博客园
您需要HADOOP来运行SPARK吗? - 知乎
mapreduce与spark的区别--内容详细_奔跑的小鲫鱼的博客-CSDN博客_mapreduce和spark的区别
HDFS 存放策略 - dousil - 博客园
HDFS Block块大小限定依据及原则_小学僧来啦的博客-CSDN博客_hdfs一个文件占用一个block吗
centos7下搭建hadoop、hbase、hive、spark分布式系统架构_腾讯数据架构师的博客-CSDN博客