第四章 文件的内部表示-Unix操作系统设计-读书笔记
文章目录
- 第四章 文件的内部表示
-
- 索引节点
-
- 对索引节点的存取
- 释放索引节点
- 正规文件的结构
- 目录
- 路径名到索引节点的转换
- 超级块
- 为新文件分配索引节点
- 磁盘块的分配
- 其他文件类型
- 本章小结
- 习题
-
-
-
- 数组下标从0开始,那么为什么索引节点号是从1开始的呢?
- iget中睡眠,醒来为什么重新开始循环
- 描述算法,将内存索引节点作为输入,并修改相应的磁盘索引节点
- iget和iput没有要求提高处理机执行级别以封锁中断,这意味着什么?
- 怎么样才能高效的为bmap中对于间接块的循环进行编码?
- 运行下面命令,会发生什么?
- 一个文件系统能包含的文件数目的最大值是什么?
- 应该怎么样设计文件系统和相应的算法以允许任意长度的分量名?
- 考虑把路径名转换成索引节点的算法namei,当搜索在进行时,核心检查出当前工作索引节点是目录索引节点,其他进程有可能删除该目录嘛?核心怎样才能阻止这一点?
- 设计一个通过避免线性搜索来改进搜索路径名的效率的目录结构。考虑两种技术:散列和n元树;
- 理论上讲,文件系统永远不会含有其他索引节点号比被ialloc使用的“铭记”索引节点号小的空闲索引节点。为什么这一断言有可能不成立呢?
- 设计一个通过把常用文件名高速缓冲起来以减少为查到文件名而搜索目录的次数的方案;
- 链接表上一个磁盘块中应存储多少个空闲块号才是最适宜的?
- 谈论用位示图而不是块的链接表来记录空闲磁盘块的系统实现。这一方案的优点和缺点是什么?
-
-
第四章 文件的内部表示
UNIX系统中每个文件都有一个唯一的索引节点index_node,其中包含文件所有者、存取权限、文件长度、文件数据在文件系统中的位置等;
我们在使用文件的时候,使用文件路径来表示文件,核心将文件路径转换成文件的索引节点;
本章的算法的层次处在上一章所解释的高速缓冲算法之上;
iget:返回一个先前标识了的索引节点;
iput:释放索引节点;
其中iget和iput操作的内存中的索引节点;
bmap:做字节偏移量到磁盘块号之间的映射;
namei:做路径名与索引节点的映射;
alloc与free:分配与释放磁盘块;
ialloc ifree:为文件分配及释放索引节点;
索引节点
索引节点存在两份:磁盘上的和内存上的,之所有把其放置到内存上一份是为了做缓冲,提高效率,同时这里做的缓冲完全是使用的第三章的buffer设计;
索引节点以静态形式存在于磁盘上,核心把它们读进内存索引节点表中以操纵它们,由如下字段组成:
- 文件所有者
- 文件类型:正规类型、目录类型、字符设备类型、块设备类型、管道类型
- 文件存取许可权:按照如下三个类型进行权限管理,文件所有者、文件的所有者所在用户组以及其他用户,能分别进行设置;rwx-rwx-rwx 所以你明白了777是什么意思了叭! 然后chmod +x是什么意思貌似页明白咯,x:execute;777也明白什么意思了叭!
- 文件存取时间:文件最后一次修改的时间、最后一次存取的时间、最后一次修改索引节点的时间;
- 文件联结数目:在本目录树中有多少文件名指向该文件,这个在下面的章节中介绍;
- 文件数据的磁盘地址明细表;
- 文件长度;
注意:这里索引节点的缓冲方式和块设备的缓冲方式类似,即都会包含一个空闲表、散列队列用来管理可用和不可用的缓冲节点;
内存中的索引节点拷贝除了磁盘索引节点所包含的那些字段以外,还包含:
- 内存索引节点的状态:是否上锁、是否有进程在等待其变为开锁状态、索引结点的内存版本是否与它的磁盘拷贝不同、文件的内存表示是否与它的磁盘拷贝不同;该文件是否为安装点;状态决定了:有关竞争的条件、索引节点和文件分别与磁盘的统一程度,由此可见,引入高速缓冲之后是增加了很多复杂度的;
- 含有该文件的文件系统的逻辑设备号;个人猜测,不同设备可能拥有不同的文件系统,比如SSD,比如HD,比如Floppy,而且是用户可选的,比如在格式化U盘的时候是有选择选项的;
- 索引节点号,即记录了对应的inode在数组中的下标号;因为磁盘中的索引节点的组织方式是数组结构的,开头包含一张表;
- 指向其他索引节点的指针;
- 引用计数;指示出该文件的活跃实例数目;
那么这个引用计数有什么用呢?
- 只有当索引节点的引用计数为0时它才位于空闲表上,以表示核心能把这个内存索引节点表当作不活跃的索引节点的高速缓冲;
- 反观块设备缓冲区呢?只要缓冲区为开锁状态,它就位于空闲表中了;因为使用完之后都会调用brelse函数,其会将缓冲区放置到空闲表中;
- 难道不是只要索引节点的锁被解开,引用计数就为0了嘛?是这样的;
对索引节点的存取
获取的是内存中的索引节点,也就是说这部分算法直接交互的对象还是buffer,即缓冲区;
[外链图片转存失败(img-YRKw05sl-1567060305156)(en-resource://database/3308:1)]
核心用文件系统和索引节点号来标识特定的索引节点;iget算法和getblk算法如出一辙,核心将设备号和索引节点号映射到一个散列队列上,并且搜索该队列以便找到该索引节点,如果找不到,就从空闲表中分配一个索引节点,并且对它上锁;
然后就去磁盘中找对应的磁盘块号咯,块号=((索引节点号-1)/每块的索引节点数目)+索引结点表的起始块号;
知道了块号之后还需要使用缓冲区里的函数:bread,读出该块,然后计算该索引结点在该块中的字节偏移量:((索引节点号-1) mod (每块的索引节点数目))*磁盘索引节点大小;找到之后,拷贝到内存索引节点中,把它放到正确的散列队列中,并且将它的内存引用计数置为1;
当进程打开一个文件时,它就把索引节点引用计数增1,当引用结束的时候,比如当进程关闭一个文件时,就把索引节点啊引用计数间减1,当减到0的时候,意味着锁结束了;
算法iget,如果核心试图从空闲表中取出一个索引节点,但发现空闲表是空的,则报告一个错误;这与处理磁盘缓冲区是不同的,思考为什么不同?
- 首先文件的index_node是直接和用户相关的,即用户open一个文件,则会涉及到index_node,那么什么时候close呢?由用户决定,核心是无法预测的。
- 而反观磁盘缓冲区,磁盘缓冲区的buffer_head则是完全由核心来管理的,所以不会让iget的进程睡眠,而是直接返回错误,因为如果睡眠的话,核心是无法保证其一定能唤醒的;

算法iget会返回一个上了锁的索引节点数据结构,而且其引用计数比原来大1,上面图片中的文字还是挺重要的,一定记得需要从空闲表中将其摘除出来;
释放索引节点
也是针对的缓冲区里的索引节点,这里和之前高速缓冲不同的地方是加入了空闲统计;

当核心释放一个索引节点时iput,将它的索引节点引用计数值减1;如果该计数值降为0,且它的内存拷贝和磁盘拷贝不同,则还需要写磁盘;
其中文件数据的改变、文件存取时间的改变、文件所有者或存取许可权的改变都会引起它的内存拷贝与磁盘拷贝的不同;
核心会把该索引节点放置到空闲索引节点表中;这里和磁盘缓冲区的算法十分类似。
正规文件的结构
三级索引结构;
索引节点如何管理文件对应的磁盘块的分配?
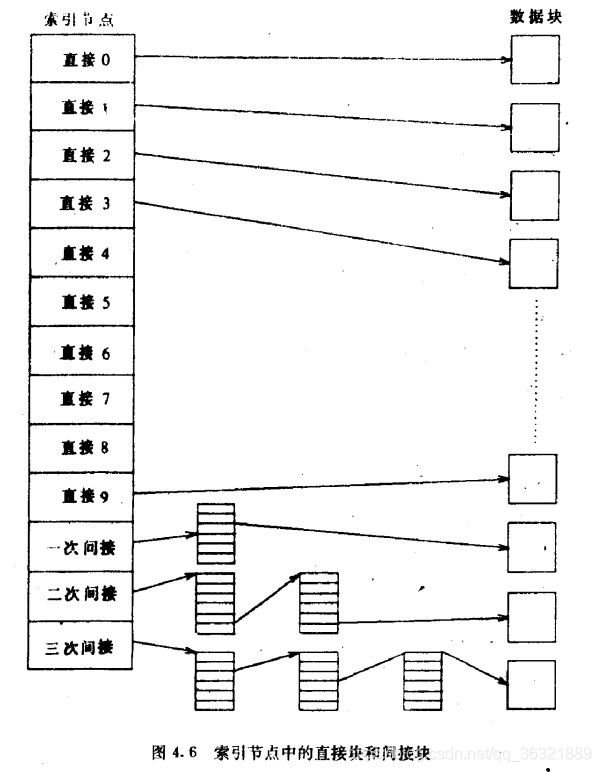
下面的算法完成了从字节流的字节偏移量到磁盘块号的转换,就是算就完事了!!!


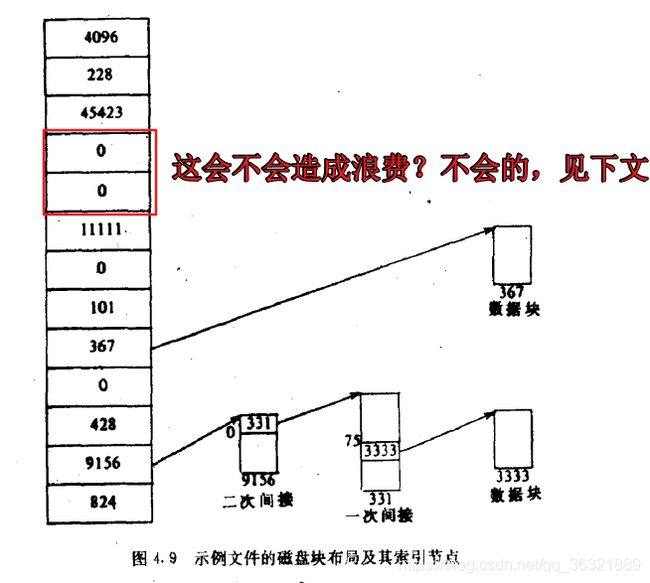
思考大文件的存取,需要读取三个磁盘块才能索引到3级索引的数据,而且中间可能会有等待缓冲的过程,会非常耗时耗力;所以得出结论:读取小文件是很快的,存取大文件是比较费劲的;
这里还是很有学问的,先简单了解下其基本原理和思想叭,华为有做的超级文件系统,据说很牛!!!
所以不要仅仅止步于Unix和Linux0.11,还要有更宽广的视野去探究,探索之外的世界;
目录
目录虽然可以当成普通文件对待,但是目录对应的磁盘块的内容却是不一样的;
目录在文件名到索引节点的转换中扮演了重要角色;
目录也是文件,只是它的数据是一系列登记项,每个登记项由一个索引节点号和一个包含在这个目录中的文件名组成;
UNIX系统V把分量名限制为14个字符,索引节点号占两个字节,所以一个目录登记项长度为16个字节;

每个目录都包含.和…文件名,分别是本目录和它的父目录的索引节点号;
对于目录的权限的解释:
- 读权限:允许进程读这个目录;
- 写权限:允许进程创建新目录登记项或撤销老目录登记项,从而变更目录内容,也就是为该目录增加新文件、删除该目录中的文件;
- 执行许可权:允许进程为寻找 一个文件名而搜索这个目录;
读目录与搜索目录的差别?一个是一层遍历,另一个是多层嵌套遍历?
路径名到索引节点的转换
这一小节实际上讲解的就是:如何根据路径名搜索索引节点;
系统中的第一个进程-0的当前目录是根目录。其他进程的当前目录都是从该进程被创建时它的父进程的当前目录出发的;

上述算法中使用工作索引节点的中间索引节点;
其中的核心是验证工作节点确实是目录;不然就违反了“非目录文件仅能是文件系统树的树叶节点”的要求;同时进程还需要具有搜索目录的许可权;
搜索到之后,释放块brelse(因为遍历该目录下的文件的时候用到了bread),以及释放旧的工作索引节点input,并且分配匹配了分量的索引节点;
关于线性搜索的讨论:

超级块
超级块由如下字段组成,总结来说,文件系统玩的就是inode+磁盘块,而这里的超级块就是inode和磁盘块信息的总结;
- 文件系统的规模
- 文件系统中空闲块的数目
- 文件系统上可用的空闲块表
- 空闲表中下一个空闲块的下标
- 索引节点表的大小
- 文件系统中空闲索引节点数目
- 文件系统中空闲索引节点表
- 空闲索引节点表中下一个空闲索引节点的下标
- 空闲块表的锁字段和空闲索引节点的锁字段
- 用来指示出超级块已经被修改了的标志
为新文件分配索引节点
核心是使用到了超级块中的空闲表;
文件系统包含一个索引节点线性表,如果它的类型字段为0,则说明这个索引节点是空闲的;当一个进程需要一个新的索引节点时,理论上说,核心能搜索索引节点表,以寻找一个空闲节点,但是这样太慢了,很多时候甚至需要去磁盘找,所以,超级块中包含了一个数组,以便把文件系统中空闲的索引节点号缓存起来;

解释下“铭记”的索引节点:如果超级块中没有空闲,即去磁盘搜索,当搜索到超级块装不下时停止搜索,此时记录下最高序号的索引节点,即下次搜索时从铭记索引节点开始;
释放一个索引节点的算法ifree:


P116,的确有竞争条件的地方都比较复杂,所以好好考虑竞争条件,毕竟涉及到IO的地方会频繁涉及到sleep;

磁盘块的分配
mkfs程序把一个文件系统的数据块组织到一张链表中,表中的每个链是一个磁盘块,块中包含的是一个数组,数组的分量是空闲磁盘块号,并且数组中有一个分量是下一个链表的块号,示意图如下,蕴含着一些智慧,别小看这些实现细节,这些实现细节决定了效率呢!
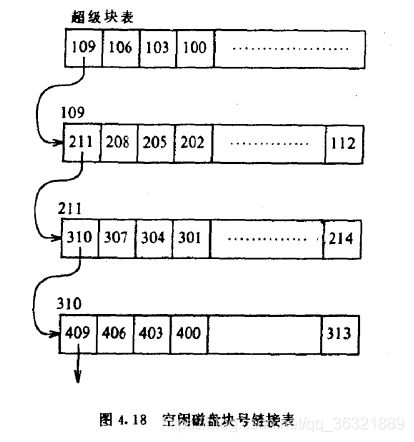
alloc算法:
- 将超级块表中的下一个可用的块分配出去;
- 当所分配的是超级块中的最后一个可用块时,核心将其作为指向包含一张空闲块表的块指针看待,读该块,把新的块号表移到超级块数组中,然后使用原来的块号;
- 问题是:最后一个可用块作为指针指向的块一定包含块号嘛???上面讲的,是mkfs做的工作,将所有块都搞成这样岂不是很浪费时间???不是将所有块都做成那样,就数组边界上的一个块是这样的,很巧妙吧!
- 如果文件系统不包含空闲块了,则调用者进程收到一个错误指示。

程序mkfs试图组织好空闲块号的原始链接表,使得分配给一个文件的那些块号互相靠近,这样读文件时就能减少磁盘寻找时间和等待时间;所以有益于提高性能;
释放磁盘块的算法free:
- 如果超级块表未满,新释放的块号就被放到超级块表中;
- 如果满了,放不开了怎么办?新释放的块就被变成了一个数组块,核心将超级块表写到这块上,并把这块写到磁盘上,然后将新释放的块号放到超级块中作为下一个链表的指针,很巧妙,没有修改数据结构就能起到这样的作用实在厉害;
索引节点和磁盘块的缓冲策略是不一样的,索引节点没有形成链表,而磁盘块的缓冲却形成了链表,所以原因有如下:
- 核心能通过观察一个索引节点的文件类型位来确定索引节点是否是空闲的,但是无法观察磁盘块是否是空闲的;
- 磁盘块作为链接表:一个磁盘块很容易容纳大的空闲块表,但是索引节点却没有何时的地方;
- 用户消耗磁盘块资源比消耗索引节点要快,所以···
其实这些东西,我认为可能需要获得用户使用的具体情况去优化,比如统计出一个比较平均的磁盘块资源消耗次数和索引节点消耗次数,那么再去重新设计,就很优化了;
其实那些所谓的基于AI去优化多少有点扯淡,不过是通过统计数据去重新进行设计,比如缓冲区分配多少,如果才能做到最优,就是利用数学方法去做而已;
其他文件类型
除了目录、普通文件外还有两个文件类型:管道文件和特殊文件;
emmm管道···这种进程间通信方式不应该涉及到IO吧?不造~~~
管道的关键点是先进先出;
特殊文件:
块设备特殊文件和字符设备特殊文件,两种文件都指明了设备,因此它们不引用任何数据;
索引节点含有两个称为主与次的设备号;
主设备号指出终端、磁盘等设备类型;
次设备号指出这类设备的装置号;
本章小结
我只觉得很乱,很乱,很乱,复习了一遍发现理清楚了很多思路;
索引节点有两个版本:磁盘拷贝和内存拷贝;
在系统调用:creat, mknod, pipe, unlink期间,算法ialloc, ifree控制着给文件分配磁盘索引节点;
在进程存取文件时,算法iget, iput控制着内存索引节点的分配;
算法bmap根据字节流中的字节偏移量来确定磁盘块的位置;
算法namei将文件名转换成内部使用的索引节点;
最后核心使用算法alloc和free给文件分配新磁盘块;
算法之间的交互作用所引起的竞争条件是复杂性的体现;
这里使用的算法是:链接表、散列队列、线性数组,这也决定了算法的简明性;
Come On, 复习走起;
习题
数组下标从0开始,那么为什么索引节点号是从1开始的呢?
不造,好像也不是hash函数的原因;
iget中睡眠,醒来为什么重新开始循环
别的进程可能影响了原有的数据,需要重新确定是否满足要求鸭
描述算法,将内存索引节点作为输入,并修改相应的磁盘索引节点
先找内存版本的索引节点
找到之后获取磁盘索引节点号
根据磁盘索引节点号找对应的磁盘号
然后写相应的字节,完事!
iget和iput没有要求提高处理机执行级别以封锁中断,这意味着什么?
意味着可抢占,实时性提高,并且iget和iput中要对应sleep所引起的数据不同步问题
怎么样才能高效的为bmap中对于间接块的循环进行编码?
多用%运算呗
运行下面命令,会发生什么?

很有意思的,chmod -r junk之后ls -ld junk可以运行,ls -l junk运行时发生权限问题;
挺有意义的,原来chmod 可以用±符号来操作鸭
一个文件系统能包含的文件数目的最大值是什么?
最大值,应该非常大吧,首先,一个索引节点能指示10个直接索引,1个1级···,然后将这些直接索引和间接索引所指示的磁盘中的内容全部填上16字节的表项,能填太多太多太多太多了叭!!!!!
应该怎么样设计文件系统和相应的算法以允许任意长度的分量名?
首先绝对不可能任意长度,因为任何一块磁盘的容量都是有上限的;
其次,我知道怎么去扩展文件名,还是采用内核中一贯采用的思想,就是说目录项里不保存文件名,而是保存指针,该指针指向一个磁盘块,该磁盘块保存文件名,如果一个磁盘块1K的话,那么再假设一个字符占1B,那么文件长度就扩展为1024个字符了;
同理,如果你觉得一个磁盘块所能容纳的文件名还是太短的话,目录表项不保存我们之前说的指针了,而是保存指向一个表项,该表项包含直接索引和间接索引,当然间接索引越多,获取对应的长文件名的效率就越低;
考虑把路径名转换成索引节点的算法namei,当搜索在进行时,核心检查出当前工作索引节点是目录索引节点,其他进程有可能删除该目录嘛?核心怎样才能阻止这一点?
当然有可能删除了,因为namei没有对当前工作索引节点加锁,自然可以删除;
如何阻止?那就是对工作节点加锁咯;
设计一个通过避免线性搜索来改进搜索路径名的效率的目录结构。考虑两种技术:散列和n元树;
散列:
- 散列表的关键在于hash函数,也就是说我们要设计一个简单高效的hash函数才行
- 存在这样的hash函数嘛?将文件名映射成数组下标?
- 只能说很难找
所以n元树可能比较靠谱:
- 怎么设计n元树呢?
- 不造,以后再考虑吧,类似于那种2分搜索也能节约时间鸭;
理论上讲,文件系统永远不会含有其他索引节点号比被ialloc使用的“铭记”索引节点号小的空闲索引节点。为什么这一断言有可能不成立呢?
这是为什么呢?
- 首先我们要思考,什么会导致索引节点空闲?
- 文件操作完成了close后会调用一系列函数,导致索引节点空闲
- 每次读完写完之后,都会导致索引节点空闲
- 是的上面的说法都没问题,但是有没有想过空闲索引节点保存在哪里?
- 当然保存在超级块中,如果你产生空闲索引节点的时候,超级块被锁住了怎么办?
- 当然是凉拌了,即不管超级块了,也不会将该空闲索引节点些进去,所以就产生了题目中的问题;
设计一个通过把常用文件名高速缓冲起来以减少为查到文件名而搜索目录的次数的方案;
充其量和buffer.c一样呗,不设计了叭!
链接表上一个磁盘块中应存储多少个空闲块号才是最适宜的?
- 直接全部存满不就完了吗,这个还需要讨论吗???
- 首先,分析下,为什么需要讨论;
- 首先假设全部存满,OK,然后呢?用的时候需要遍历
- 对于那些已经被使用的磁盘块,需要将数组的值置0
- 那么如果是从头向尾遍历的话,问题来了,假设前面1023个全部是0,那么就浪费掉了遍历1023个数组的时间,而且中间还得判断数组的值是否为0;
- 那么继续分析数组过短导致的原因,很简单,数组过短的话,就会导致频繁切换磁盘块,这涉及到IO操作;
- 所以我觉得需要权衡的就是,数组过长导致的空遍历问题和磁盘IO导致的延时问题之间的权衡,磁盘IO又涉及到缓存命中率,所以我个人认为,这个问题最好的解法是
- 拿到用户使用系统的数据,将数组长度不断调整,从而去模拟使用,然后看空遍历所话时间和IO所话时间;
- 一般来讲的话,IO是十分耗时的,如果缓冲命中率不高的话,我觉得1000个空遍历所浪费的时间是能接受的;
谈论用位示图而不是块的链接表来记录空闲磁盘块的系统实现。这一方案的优点和缺点是什么?
先来回想下使用块的链接表来记录空闲磁盘块的方案:
- 首先每个磁盘块被分割成了一个个数组
- 这个数组中记录了每个空闲磁盘块的块号
- 其中,数组头或者说数组尾是特殊的,它指示下一个装载空闲磁盘块的块号
- 该方案最大的灵活点就是在这里,灵活点在于:当遍历到最后一个数组项的时候,再去将下一个链表加载进来,这样我始终仅仅占用了一个磁盘块就能表征所有的空闲磁盘块
那么再来考虑位示图方案:
- 首先,需要多少位来表征所有的空闲磁盘块?
- 假设磁盘占1T,1T/1K=1024x1024x1024个位才能表征所有的空闲磁盘块
- OK,1024x1024x128字节
- OK,1024x128个块,也就是说,我需要这么多个块才能表征所有的空闲磁盘块
- 这些块所占用的磁盘空间是:128MB,还不算太大;
- 128M对于一个机械硬盘或SSD来说,不大,但是对于内存来讲,却是一个不小的数目
- 这是缺点一;
然后再来分析下它的使用过程:
- 当我想获取某个空闲磁盘块的时候,应该怎么操作呢?
- 举个例子0111,表示第2个以及之后的磁盘块全部都是空闲的,不如全体取反
- 1000,表示1,加一就得到了空闲磁盘块号
- 这个效率很高
- 当然这仅仅是4位的情况,对于高位的话,也完全OK;