Heatmap-based Out-of-Distribution Detection 论文阅读
原文地址
概要
我们的工作将分布失调【out-of-distribution,OOD】检测作为神经网络输出解释问题进行研究。我们学习了一种热图【heatmap】表示,用于检测OOD图像,同时可视化ID和OOD的图像区域。给定一个训练过的固定分类器,我们训练一个解码器神经网络,根据分类器的特征和类预测,生成ID样本零响应的热图和OOD样本高响应的热图。我们的主要创新在于OOD样本的热图定义,即与最近分布样本的归一化差异。热图作为区分ID和OOD样本的边界。我们的方法生成的热图不仅用于OOD检测,而且还用于指示输入图像的分布区域。在我们的评估中,我们的方法在很大程度上优于之前在CIFAR-10、CIFAR100和Tiny ImageNet上训练的固定分类器。
1. 介绍
尽管深度神经网络在标准识别数据集上有惊人的表现,但它们在安全关键问题上还不能被信任,主要原因有两个。首先,它们不一定能很好地泛化到训练分布中没有涵盖的数据【比如数字识别网络只能对分类进行数字0~9的预测,当输入一例非数字图像时则无法被正确识别】。
当深度神经网络接触到这样的非分布OOD样本时,它们通常会做出错误的高置信度预测。其次,它们大多对自己的决定缺乏能被人类理解的解释。如果深度神经网络是一个黑盒模型,并且无法评估预测是否有意义,那么它就不能用于自动驾驶或医学成像等应用。因此,不仅要检测OOD样本,还要突出输入的OOD区域【out-of-distribution regions】,这是至关重要的。
图1:示例 a 是OOD图像,在ID(in-distribution)数据集中找到最接近 a 的图像 b 。热力图 c 是两个图像之间进行归一化之后的结果。蓝色标记了相似的区域,而红色与黄色则突出了OOD图像与ID图像不同的区域。

OOD detection methods可以分为以下两类:
- 通过定义分数的方法来修正模型【设定阈值,低于这个阈值则说明图片不属于训练的分类】。
- 进一步训练模型以区分
ID样本和OOD样本【加大训练强度,在网络中引入ID和OOD的概念】
在我们的工作中,我们专注于固定分类器的OOD检测,因为它很适合实际应用。在这种情况下,神经网络的softmax probability通常作为检测OOD样本的内置基线。然而,过度自信的深度神经网络通常起源于使用预测类概率作为置信度度量【即这种度量方式导致神经网络过于自信】。而由softmax函数表示的概率分布通常对未知输入给出高响应,这种限制可以通过校准置信度或替代评分函数来缓解分类出错的问题。
我们通过依赖第二个模型来生成热图,而热图反过来又用于定义评分函数。因此,我们的模型不仅可以检测OOD样本,还可以指示ID和OOD的图像区域。我们的工作将OOD样本的检测作为输出,解决了输出解释问题【即为什么当前这个图会是OOD样本,通过可视化后便可以得到清晰解释】。解释模型决策的方法注重有助于决策的特征或选择原型图像。
saliency or attention map指出训练过的神经网络在图像中进行预测的位置。另一方面,原型演示了一个类似的训练图像,用于解释神经网络预测。类似于事后解释方法,我们也假设一个已经训练过的模型,不会进一步调整。在可视化解释思想【即结果最好能呈现在眼前】的激励下,我们提出了用于OOD检测的热图生成方法。
我们将OOD检测问题描述为分类器特征空间中的二元分类【即分为ID和OOD】,假设分类器提取的特征具有代表性,以学习OOD特征与ID特征的偏差。给定一个经过训练的固定神经网络分类器,我们的目标是根据分类器的特征和类预测生成热图。因此,我们定义了期望的热图,使得ID样本有zero response。相比之下,OOD样本对于不同于ID的图像区域应具有较高的响应。我们通过在分类器特征空间中寻找最接近的ID图像,并将热图作为归一化图像差【如图1】来创建OOD图像的热图。这样,热图响应就作为ID和OOD图像样本之间的边界【响应高于某个阈值就认为是OOD图像】。
为了进一步延伸我们的想法,我们引入了一个解码器网络来生成热图,输入由分类器提取的特征和类预测组成,而ID和OOD定义的热图组成预期作为输出。最后,基于热图,我们定义了我们的评分函数,它输出样本是ID或OOD。我们的方法生成的热图不仅用于OOD检测,而且还用于基于分类器特征和类预测的ID区域和OOD区域的可视化。
本文的贡献总结如下:
- 我们提出了
OOD检测的热图。学习生成热图是基于我们介绍的解码器,而我们的主要创新之处在于如何为OOD图像样本创建热图【归一化OOD样本与最接近其的ID样本】 - 基于分类器特征和类预测,提出的热图可视化
in和out的图像区域。特别是,对于OOD样品,热图表示与最接近的分布样品的差异,如图1所示。 - 我们提出了使用热图作为输入的
OOD评分函数,与不修改分类器的方法相比,其在CIFAR10,CIFAR-100或Tiny ImageNet上训练得到的是最先进的OOD检测结果。
2. 相关工作
2.1 OOD检测
OOD检测方法旨在识别训练分布中未覆盖的样本,先前关于图像分类的工作主要分为两类:其区别在于分类器参数是固定的还是可修改的。对于固定的深度神经分类器,maxsoft probability【MSP】是检测OOD样本的常用函数。然而,由于深度神经网络对未见样本存在过度自信的问题,仅仅依靠MSP是远远不够的。
ODIN【某种处理方法】通过在OOD样本上验证的temperature scaling and input perturbations来提高softmax分数
Hsu等扩展了温度缩放,使其独立于OOD验证数据;Liu等引入了能量分数来区分预训练分类器的ID和OOD样本,但它也可以用作成本函数来优化分类器以检测OOD样本。另一方面,Lin等通过早期退出策略来实现能量评分,以更快地检测OOD;Sun等人观察到OOD数据会导致正偏斜的激活单元,并通过基于分布内激活值将倒数第二层的激活裁剪到上限来提高OOD数据的检测。
我们还假设了一个固定的,不需要进一步修改的分类器。与前人的工作不同,我们学会了用我们提出的解码器生成的热图来分离ID样本和OOD样本。重要的是,我们的解码器不仅执行OOD检测,而且还通过热图响应提供OOD区域的可视化。据我们所知,这是第一个执行OOD检测的方法,同时根据已经训练好的固定分类器的特征和类预测来说明ID和OOD的图像区域。
在第二类中【分类器参数可修改】,分类器被进一步优化,不仅可以对网络输入进行分类,还可以确定OOD样本,可以利用深度自编码器或旋转预测等自监督方法来学习ID表示。
例如,Zaeemzadeh等通过学习将ID样本嵌入到1维子空间中进行OOD检测,从而依赖于特征压缩。Zisselman等设计了一种基于深度残流网络的网络架构,用于OOD检测,而Huang等则使用基于组的softmax针对大规模OOD检测。此外,还有一些方法在分类器的训练阶段使用OOD训练样本。例如,随机或生成的OOD样本可以映射到均匀分布。相反,Yang等在语义空间中应用聚类来检测OOD训练样本中的ID数据。基于同样的原理,我们也使用OOD样本来训练所提出的解码器,但基本上不修改原始的分类器,我们依靠已经训练好的分类器学习到的特征来区分OOD和ID的样本。
2.2 预测可解释性
有不同的方法来解释神经网络预测。事后分析方法【post hoc methods】通过局部解释或具有可解释代理模型的全局近似对训练模型进行解释。另一个研究方向是通过激活、注意力或显著性映射来可视化原型或突出有助于分类器决策的特征。此外,Liznerski等利用视觉解释突出图像中明显的区域进行异常检测。在这项工作中,我们将OOD检测定义为已训练和固定模型的特征表示中的异常。在这种情况下,我们建议从分类器提取的特征中生成热图,以检测分布不均匀的输入,并可视化输入图像的相应区域。
3. 方法
图2:在我们的方法中,我们的目标是检测OOD样本,同时可视化ID和OOD区域,因此,我们从一个固定分类器的特征z和预测y生成热图【即确定下某一特征以及该样本的预测值就能产生该样本对应的热图】。生成的热图 h ^ i \hat h_i h^i 应该对ID图像 x i x_i xi 没有响应,而热图 h ^ o \hat h_o h^o 应该对OOD图像 x o x_o xo 有高响应【这里的应用就是ID样本零响应,OOD样本高响应,因此这个结果是符合前边设计的】。
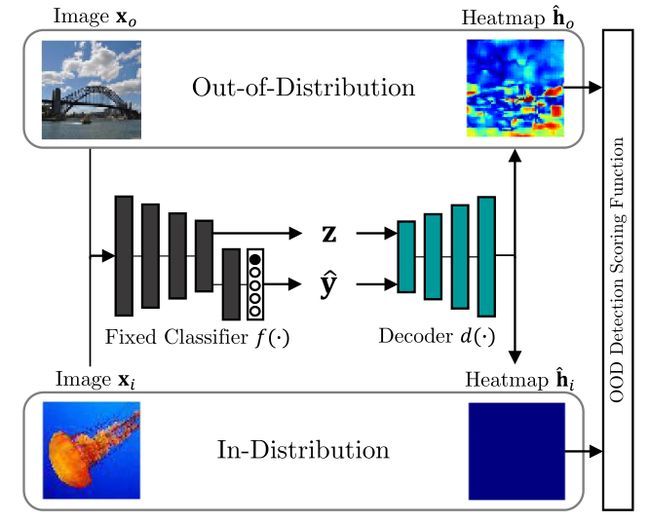
我们的目标是基于预测和分类器 f ( ⋅ ) f(·) f(⋅) 的特征,区分ID的 P i n ( x , y ) P_{in}(x, y) Pin(x,y) 和OOD的 P o u t ( x , y ) P_{out}(x, y) Pout(x,y) 图像样本。我们将这个问题表述为二元分类,我们假设我们可以访问固定分类器 f ( ⋅ ) f(·) f(⋅) 的特征层。在这种情况下,我们介绍了OOD热图【3.1】,它用于发现OOD样本,同时说明ID和OOD的图像区域。
我们的主要创新在于如何为OOD样本形成预期的热图。此外,我们提出了解码器神经网络 d ( ⋅ ) d(·) d(⋅) ,它被训练成从分类器的特征和类预测生成热图【3.2】
最后,我们依靠解码器为每个图像样本生成的热图来计算OOD检测得分【3.3】
从本质上讲,生成的热图指示了ID或OOD预测的相应图像区域。注意,对于评估,我们考虑来自不被 P i n P_{in} Pin 或 P o u t P_{out} Pout 覆盖的不同分布 P t e s t ( x , y ) P_{test}(x, y) Ptest(x,y) 的OOD测试集 D t e s t = { ( x l , y l ) } l = 1 ∣ D t e s t ∣ D_{test} = \{ (x_l, y_l)\}^{|D_{test}|}_{l=1} Dtest={(xl,yl)}l=1∣Dtest∣ 【表达式看起来复杂,其实就是不在范围内的图像集合】
3.1 特征热力图
我们定义期望的热图 h ∈ R w × h × 3 h\in \mathbb{R}^{w×h×3} h∈Rw×h×3 ,其维度与输入图像x相同。对于ID图像,热图不包含OOD信息,因此响应为零。
相比之下,OOD样本的热图对于不同于ID数据的图像区域应该具有较高的响应。我们在图2中提供了热图的说明。因此,热图响应作为ID和OOD图像样本之间的边界。对于ID的图像,指定预期的热图是很简单的,因为我们的目标是获得零响应。然而,目前尚不清楚如何定义OOD样本的热图。下面,我们提出了一种使用ID数据集 D i n D_{in} Din 来定义OOD数据集 D o u t D_{out} Dout 图像的预期热图的方法。
3.1.1 OOD热图
对于OOD数据集 D o u t D_{out} Dout 的每个图像样本 x o x_o xo ,我们的想法是基于ID数据集 D i n D_{in} Din 的最接近的图像样本形成热图。因此,我们依赖于类预测工具 y ^ o \hat y_o y^o 和固定分类器的特征表示 z o z_o zo , z o = f ( x o ; w f ) z_o = f(x_o;w_f) zo=f(xo;wf)。这一过程如下图所示:

图3:预期OOD热图 h o h_o ho 的定义是基于距离 D i n D_{in} Din 最近的ID样品的距离。为了找到最接近的ID样本,我们依赖于类预测 y ^ \hat y y^ 和固定分类器的特征表示z。更准确地说,我们从 D i n D_{in} Din 中寻找具有相同类别的样本 x i x_i xi ,即 y ^ o = y i \hat y_o = y_i y^o=yi 和 z o z_o zo 和 z i z_i zi 之间的最小欧氏距离。
热图解释
热图解释。由于像素值的模糊性和一般复杂的空间,在图像空间中无法直接进行ID和OOD图像的视觉比较。在我们的方法中,解码器学习了从特征空间到像素空间的映射,其中热图表示与最近的ID图像的差异。因此,OOD检测不仅基于特征空间中的信息,还基于解码器学习到的映射回像素空间,提高了OOD检测性能。在图1中,与最近的ID训练样本不同的特征用红色区域突出显示,这些区域又是OOD特征。相反,蓝色表示ID区域的相似特征。
3.2 特征热力图解码器
提出的解码器 d ( ) d() d() ,参数化为 w d w_d wd ,旨在估计热图 h ^ \hat h h^ 。与热图定义类似,我们依赖于特征表示 z z z 和预测概率分布 y ^ \hat y y^ 作为解码器的输入。图2显示了我们的方法的概述。首先,分类器接收从 P i n P_{in} Pin 或 P o u t P_{out} Pout 提取的图像 x x x 作为输入,并输出相应的特征表示 z z z 和预测概率分布 y ^ \hat y y^ 。然后,将特征和one-hot编码的类预测连接起来,然后传递给解码器来估计热图 h ^ \hat h h^。同样,我们只依赖于 z z z 的单一特征表示,这是倒数第二层分类器。在补充材料中,我们增加了一项消融研究【4.6】来验证这一选择。因此,我们使用 H i n H_{in} Hin 和 H o u t H_{out} Hout 集来训练解码器生成热图。
根据定义的热图 h o h_o ho ,热图中的OOD条目的权重较高,比例因子为 1 + α ∣ h o ∣ 1 + α|h_o| 1+α∣ho∣ 。由于ID区域出现频率更高,比例因子的作用是OOD区域在损失计算中权重更高。对于ID样本,我们有效地最小化项 ∥ h ^ i ∥ 2 \left\|\hat{\mathbf{h}}_{\mathbf{i}}\right\|^{2} h^i 2,因为在ID样本中, h i h_i hi 始终为零。在推断过程中,当我们不知道分布时,训练有素的解码器估计热图的 h ^ \hat h h^ ,以说明ID和OOD的图像区域,并定义我们的OOD评分函数。
3.3 OOD评分函数
我们利用生成的热图 h ^ \hat h h^ 来定义OOD评分函数,用于区分ID和OOD图像。由于OOD检测是一个二元分类问题,OOD评分函数描述为:
O O D ( h ^ ) = { 1 1 w ⋅ h ∑ j = 1 w ⋅ h max ( ∣ h ^ j ∣ ) ≤ δ 0 otherwise O O D(\hat{\mathbf{h}})=\left\{\begin{array}{ll} 1 & \frac{1}{w \cdot h} \sum_{j=1}^{w \cdot h} \max \left(\left|\hat{\mathbf{h}}_{j}\right|\right) \leq \delta \\ 0 & \text { otherwise } \end{array}\right. OOD(h^)={10w⋅h1∑j=1w⋅hmax( h^j )≤δ otherwise
其中 j j j 用于在热图像素上迭代, δ δ δ 是将样本分类为ID或OOD的阈值。【函数的意思即传入热图,判断是否属于OOD样本】
4. 实验
我们使用不同的网络架构对标准OOD检测基准进行了详细评估。
因此,我们将我们的方法与在预训练模型上运行的最先进的OOD检测方法进行比较。我们根据到最近的ID训练样本的距离演示了作为ID和OOD图像区域插图的热图。为了进一步解释热图,我们通过影响图像亮度来评估照明条件的效果。最后,我们在一项消融研究中展示了OOD训练数据大小的重要性。
4.1 实验预备
数据集和模型
我们遵循之前的工作,在CIAFR-10和CIFAR100作为分布数据集上评估我们的方法
两个分布数据集的分辨率均为32 × 32。为了覆盖各种各样的OOD样本,我们依赖于以下OOD测试集:iSUN, LSUN-Crop, LSUN-Resize, SVHN, Textures和Places365,所有OOD图像都下采样【调整分辨率,使其与ID一致】到ID图像分辨率。
与之前的工作一样,我们使用8000万小图像数据库作为OOD训练集。在这种情况下,我们在ID数据集上训练深度为40和宽度为2的ResNet18和WideResNet,然后固定分类器权重。此外,我们用ResNet50在Tiny ImageNet上训练作为ID数据库来评估我们的方法在复杂设置上的效果,这里图像的分辨率为64 x 64
对于OOD测试集,我们依赖于iNaturalist, SUN和Textures数据集作为数据库,它们再次被下采样到与ID图像相同的分辨率。对于复杂的设置,我们利用Places365作为OOD训练集。与之前的工作一样,我们使用整个ID测试集进行评估。如文献中所述,每个OOD测试集的OOD样本数量固定为ID数据集大小的 1 5 \dfrac{1}{5} 51 。
解码器架构和训练
解码器网络结构基于DCGAN【Deep Convolutional Generative Adversarial Networks,深度卷积生成对抗网络】发生器。热图被归一化为[−1,1]【即最后图像会映射为这个区间里的一个数字,从而判断其为ID还是OOD】,其中双曲正切作为解码器中的最后一个激活函数。
正如3.2中提到的,我们依赖于分类器的单一特征表示,即倒数第二个分类器层,作为解码器的输入。然后,将特征归一化到[0,1]范围,然后与one-hot编码类预测连接。此外,损失函数的标度因子 α α α 经验选择为5。同时,解码器使用Adam【一种优化训练过程的方法】求解器训练150个epoch,其中学习率设置为0.0002, β 1 β1 β1 为0.5, β 2 β2 β2 为0.999。最后,对输入图像进行200个样本的处理,OOD样品与ID样品的比例经经验选择为 1 5 \dfrac{1}{5} 51 。
CIFAR-10和CIFAR-100数据库都包含50000张训练图像,这意味着OOD训练样本的数量被设置为10000。对于包含100000张训练图像的Tiny ImageNet, OOD训练数据大小为20000。与之前的工作类似,OOD训练图像是随机选择的。
评价指标
我们基于标准指标评估我们的方法,即AUROC, AUPR-Success (AUPR-S),AUPR-Error (AUPR-E)和95% TPR (FPR-95)的FPR。所有指标都独立于OOD检测阈值 δ δ δ ,AUROC对受试者工作曲线ROC下的区域进行积分。
AUPR-Success表示ID样品的精度召回曲线下的面积为正,而AUPR-Error则将OOD样品视为positive,与AUROC指标相比,AUROC解释了阶级不平衡。最后,在95% TPR时的FPR计算95%真阳性率【true positive rate, TPR】时的假阳性率FPR。我们直接将度量应用于各自的OOD检测分数。
与相关工作比较
我们比较了在固定分类器上操作的事后方法,类似于我们的方法
首先,我们采用maximum softmax probability【MSP】。此外,我们使用ODIN和Mahalanobis与我们的方法进行比较。
对于OOIN,我们按照论文的建议将温度设置为1000,并根据最佳结果选择噪声幅度为0.0014。以Mahalanobis为例,仅依靠倒数第二分类器层的特征,我们就获得了最好的结果,噪声大小为0.0028
此外,我们将我们的方法与recent Energy score和ReAct进行了比较,对于能量分数,我们选择没有进一步优化分类器的版本。相反,分数也是基于固定的分类器确定的,因为我们训练了第二个模型,但没有调整分类器。温度设置为作者建议的1。对于相关的方法,我们使用了官方实现。所有方法都在相同的网络架构上进行评估
由于能量评分的作者也使用预训练的WideResNet进行评估,我们额外报告了他们论文的原始结果,标记为Energy *。由于我们的方法基于可训练的模型,与相关方法不同,我们将每个实验进行五次,并报告所有运行的平均值。
4.2 OOD检测结果
表1:比较95% TPR下AUROC、AUPR-Success、AUPR-Error和FPR的OOD检测性能。结果是OOD测试集数量的平均值。我们将我们的方法与不进一步优化分类器但在预训练模型上操作的方法进行比较。*标记的结果摘自原论文。“↑”表示数值越大越好,“↓”表示数值越小越好。
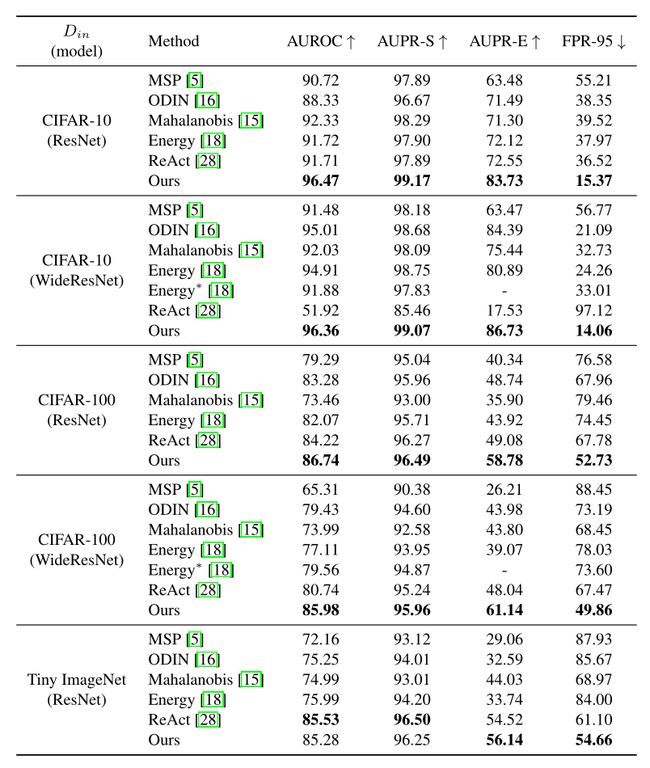
OOD检测结果如表1所示。类似于相关工作,我们报告了各个OOD测试集的平均性能。补充材料中提供了对各个OOD数据集的详细评估。一般来说,类数越大,分辨率越高,难度越大
因此,CIFAR-10的OOD检测不那么复杂,而CIFAR-100的OOD检测则更加困难,并且Tiny ImageNet是我们实验中最复杂的设置。在CIFAR-10中,内置的softmax评分在AUROC和AUPR-S方面已经取得了很好的OOD检测性能。除了ReAct之外,其他相关的方法提高了MSP,特别是在OOD样品的检测(AUPR-E)和FPR-95度量方面。尽管如此,我们在所有情况下都获得了更好的结果,特别是对于FPR-95度量。
对于CIFAR-100,所有方法的OOD检测性能在分布类别为100而不是10时下降。在这里,我们在所有指标上都优于其他方法。对于这两种架构,AUPR-E度量强调了OOD检测,特别是与其他方法相比,有了显著的改进。
最后一个实验,使用Tiny ImageNet作为分布数据集,强调需要分类的类越多,检测OOD样本就越困难【这是自然,因为ID的排除变困难了】。在这种设置中,我们获得了与ReAct相当甚至更好的结果(AUPRE, FPR-95),并且在所有指标上都优于其他方法。
总体而言,指标表明所有方法都有检测ID样本的趋势。与AUPR-E相比,AUPR-S的值更高,这表明了这一点。然而,我们的方法在检测OOD样本方面超过了之前的工作,在大多数情况下,就AUPR-E而言提高了近10%,并且在所有情况下都一致。
4.3 视觉呈现
在图1中,我们演示了用于解码器训练的示例热图定义,a图显示了来自Places365的OOD图像;b图显示了来自Tiny ImageNet的最接近的ID训练样本;c图中展示了产生的热图,蓝色标记了相似的区域,而红色/黄色突出了与ID图像不同的特征。第一行表示far-distribution图像,而第二行表示near-distribution图像。在这里,与第一行热图相比,第二行的热图显示了更温和的响应。
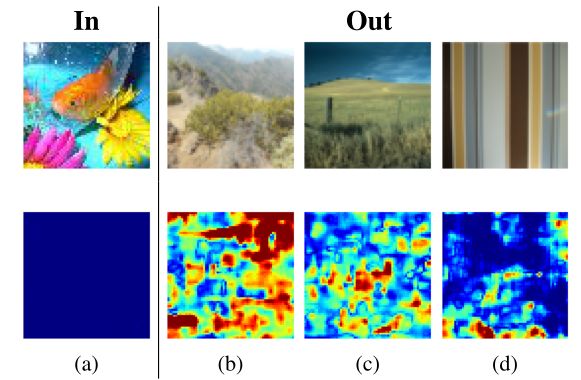
图4:用ResNet在TinyImageNet (a)上训练的视觉结果作为ID数据库(In)。示例来自OOD数据库(Out) iNaturalist (b), SUN (c)和Textures (d)。原始图像显示在最上面一行,而估计的热图显示在最下面一行。蓝色标记ID区域,而红色/黄色突出OOD区域。图4显示了在Tiny ImageNet上训练ResNet的定性结果。第一行显示原始输入图像,而估计的热图在第二行。a图显示了一个微型ImageNet的ID示例。
与原始图像相比,热图显示没有响应。因此,热图条目接近于零,这反过来意味着用分类器提取的特征是ID样本的代表,从b图到d图,我们说明了三个不同的OOD示例,作为在Tiny ImageNet上训练的分类器的输入
在所有情况下,整个图像上的区域都由OOD响应突出显示,表明与最近的ID样本的差异。OOD示例涵盖了不同的OOD类型,包括景观【图b,图c】和纹理【图d】,展示了我们方法的泛化能力。
4.4 亮度影响
神经网络的性能会受到外部因素的影响,如光照条件。因此,我们评估亮度和对比度变化对我们方法的影响。
我们通过提高亮度B(brightness) ={2.0, 2.5}中和降低对比度C(contrast) ={0.1, 0.5}来增加ID测试数据。
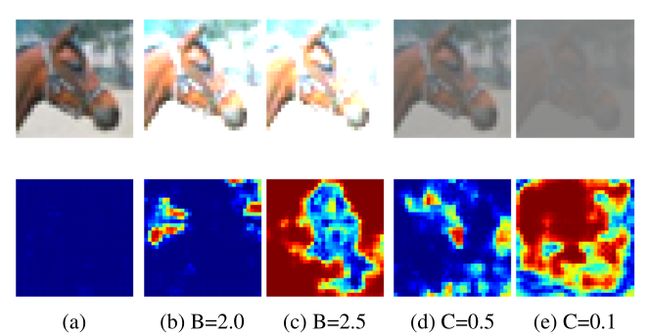
图5:来自CIFAR-10测试集的马的示例图像,对应的热图预测用不同的亮度或对比度值增强。a为未增强的原始图像,b和c中亮度值增加。在d和e中,对比度降低。蓝色标记ID,而红色/黄色突出OOD。
亮度越高,对比度越低,分布中的样本应该被检测为OOD,因为相关特征不再可识别。在图5中,用相应的热图预测可视化了亮度增强和对比度增强的马的例子。热图清楚地显示,对于亮度增强较高的图像以及对比度增强较低的图像,反应较高。随着亮度的增加,图像的分布特征难以识别,因此图像应标记为OOD,这同样适用于对比度降低的图像。
通常,更多的图像区域被可视化为OOD以增加亮度值。对于c图,覆盖马头的像素仍然被标记为分布中,而大多数其他像素被高亮显示为OOD。相比之下,当亮度和对比度不改变时【如a图】,热图条目为零。
对于对比度增强的图像【如图e】,相应的热图也显示了与原始图像相比更大的OOD区域。在补充材料中,我们报告了OOD检测性能评估,其中增加的ID样本被标记为OOD。从定性热图示例中已经可以明显看出,OOD检测性能随着亮度的提高和对比度的降低而增加。
4.5 讨论
总的来说,我们实现了一个可训练的模型来生成热图。由于我们优化了参数化模型,与之前的工作相比,我们自然需要额外的计算工作。然而,热图不仅可以用于检测OOD样本,而且还可以基于分类器特征和类预测来说明ID和OOD的图像区域。
目前,我们的方法是专门为图像分类模型设计的。由于参考图像与类预测相关联,该方法仅限于分类任务。对其他领域的适应,如目标检测,可以在未来的工作中解决。
4.6 消融实验
我们研究了OOD训练数据大小的影响。
由于AUPR-S和AUPR-E将重点放在positive class,我们报告AUROC并在补充材料中提供其他指标。我们在CIFAR-10和CIFAR-100上进行预训练的网络架构作为ID数据集,并将8000万微小图像作为OOD训练集进行消融研究.
如第4.1节所述,OOD训练集大小设置为分布数据集大小的 1 5 \dfrac{1}{5} 51 。我们将分布中的样品数量固定在50K,并改变OOD样品的数量。

图6:交替`OOD`训练集时的`AUROC`结果,`ID`数据集大小是固定的。
在图6中,我们展示了交替使用OOD训练集大小与{500,1000,5000,10000,20000,50000,80000}样本集时的AUROC结果。特别是对于WideResNet架构,当使用少于10K的样本时,性能会大幅下降。在10K到80K 的OOD样本之间,两种数据集和两种架构的AUROC都略有下降。性能的轻微下降可以解释为对OOD样本的日益关注。由于性能下降可以忽略不计,OOD训练集的大小应该至少是分布数据集大小的 1 5 \dfrac{1}{5} 51 倍。
结论
我们提出了一种学习用于OOD检测的热图的方法,它也可以作为in和out图像区域的说明。基于分类器的特征和固定分类器的类预测,我们引入了经过训练的解码器,用于生成ID样本的零响应热图和OOD样本的高响应热图。我们的主要贡献包括OOD样本热图定义,该定义基于与最近分布样本的归一化差异。热图最终作为边界来区分ID和OOD的图像。在我们的评估中,我们表明,与在CIFAR-10、CIFAR-100和Tiny ImageNet上训练的固定分类器方法相比,基于热图响应的OOD评分函数实现了最先进的OOD检测性能。