RolePred: Open-Vocabulary Argument Role Prediction for Event Extraction 论文解读
Open-Vocabulary Argument Role Prediction for Event Extraction

论文:2211.01577.pdf (53yu.com)
代码:yzjiao/RolePred: Source code for EMNLP findings paper “Open-Vocabulary Argument Role Prediction for Event Extraction” (github.com)
期刊/会议:EMNLP 2022
摘要
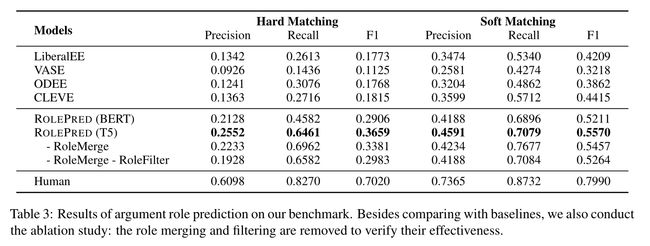
事件抽取中的论元角色是指事件和参与事件的论元之间的关系。尽管事件抽取取得了巨大进展,但现有研究仍然依赖于领域专家预定义的角色。这些研究在扩展到新兴事件类型或没有可用角色的新领域时暴露出明显的弱点。因此,需要更多的注意力和精力来自动定制论元角色。在本文中,我们定义了这一基本但尚未探索的任务:开放词汇论元角色预测。此任务的目标是为给定的事件类型推断一组论元角色。为此,我们提出了一种新的无监督框架ROLEPRED。具体来说,我们将角色预测问题表述为一个填充任务,并为预训练的语言模型构建提示以生成候选角色。通过抽取和分析候选论元,进一步合并和选择特定事件的角色。为了规范这项任务的研究,我们从WikiPpedia收集了一个新的事件抽取数据集,包括142个具有丰富语义的自定义论元角色。在这个数据集上,ROLEPRED大大优于现有方法。
1、简介
近年来,事件抽取取得了很大进展,但大多数现有研究仍然依赖于手工构建的本体(Grishman和Sundheim,1996;Ji和Grishman,2008;Lin等人,2020;Du和Cardie,2020b;Liu等人,2020);Zhou等人,2021;Li等人,2021b)。Propbank(Kingsbury和Palmer,2003)和FrameNet(Baker等人,1998)等事件本体需要数年甚至数十年才能构建。在这种本体论的中心是论元角色,论元角色捕捉了事件和所参与论元的关系。例如,Transport事件类型有5个角色:Agent、Artifact、Vehicle、Origin和Destination。这些角色通常特定于事件类型,语义上有意义的角色名称可以直接提高论元抽取质量。虽然人工构建的本体对于封闭域应用程序来说已经足够了,但它需要额外的人力来扩展到新兴的事件类型或新域。为了克服这一困难,一些研究试图自动诱导给定事件类型的论元角色(Huang等人,2016;Y uan等人,2018;Liu等人,2019a)。这些方法通常定义一个词汇表,包括具有通用语义的可能角色名称,如Time、Place和Value,然后选择一个子集作为论元角色。由于角色名称仅限于有限的词汇,它们不能反映事件类型的独特性,例如地震Magnitude或仪式Host。因此,从开放词汇表中预测角色名称对于广泛覆盖事件语义是必要的。

在本文中,我们介绍了事件抽取的一项基本但尚未探索的任务:开放词汇论元角色预测。此任务旨在为给定事件类型推断一组论元角色名称,以描述事件类型与其论元之间的关键关系。如图1所示,对于Earthquake事件类型,给定一些相关文档,我们希望输出关键论元角色名称,如magnitude、intensity、depth、deaths和injuries。这些语义上有意义的角色可以直接用于下游事件抽取任务(Huang等人,2018;Liu等人,2020;Lyu等人,2021)。然而,这项任务提出了新的挑战:(1)将论元角色预测与论元抽取分离:对于事件抽取,角色和论元是密切相互依存的,其中一个对确定另一个至关重要,预测未知论元的论元角色是一个紧迫的问题;以及(2)从开放词汇表自定义论元角色:为了覆盖各领域,我们需要超越预定义的候选词汇表,并且生成的角色应该针对每个事件类型进行个性化,以便它们能够反映不同事件类型的独特特征。
为了应对这些挑战,我们提出了一种新的无监督框架ROLEPRED。给定一个事件类型和一组文档,ROLEPRED通过三个组件预测论元角色,包括候选角色预测、候选论元抽取和论元角色选择。具体来说,为了将角色与未知论元解耦,我们假设命名实体更可能是论元。基于这一假设,我们将文本中的命名实体视为可能的论元。然后,我们通过将其作为基于填充任务的提示来预测他们的候选角色名称(Raffel等人,2020)。注意,我们允许预训练的模型(Raffel等人,2020)填充可变长度的掩码跨度,而不是一个单独的掩码。然而,这些产生的角色仍然是嘈杂的。因此,考虑到角色和论元之间的相互依赖性,我们使用QA模型抽取论元,以便进一步选择和合并角色。最后,获得特定于事件的角色以用于事件抽取。通过这种方式,生成的角色具有足够的细粒度和事件特定性。
现有的事件抽取数据集对事件类型的覆盖范围有限,对论元角色的细化不够(Grishman和Sundheim,1996;Li等人,2021b;Ebner等人,2020)。因此,为了支持论元角色预测的研究,我们从维基百科收集了一个名为RoleEE的新事件抽取数据集。在统计数据中,我们的数据集包含50个事件类型和142个论元角色类型,远远超过现有数据集中的论元角色数量(MUC-4中的5个(Dodington等人,2004)和RAMS中的65个(Ebner等人,2020))。除了一般角色(如日期和位置)之外,每种事件类型都有个性化角色,如Fire事件的Accelerator和Earthquake事件的Magnitude,它们具有丰富的语义,有助于抽取事件中的详细论元。此外,我们的数据集专注于抽取每个文档中的主要事件,即每个文档一个事件。此设置放弃了事件论元存在于多个连续句子中的限制。散布在整个长文档中的论元将符合实际应用程序,并为事件抽取模型带来更多挑战。我们在此数据集上使用ROLEPRED设置了基准性能,并为未来的工作提供了见解。
2、相关工作
事件本体构建:事件本体是事件发现和抽取的关键前提。在先前的研究中,已经付出了巨大的努力来构建几个高质量的本体,例如FrameNet(Baker等人,1998)、Propbank(Kingsbury和Palmer,2003)和VerbNet(Kipper等人,2008)。然而,构建手工构建的本体是昂贵且耗时的。一些研究人员开始探索自动本体构建。具体而言,在描述不同事件之间关系的事件模式归纳方面取得了很大进展(Cheung等人,2013;Peng和Roth,2016;Li等人,2020;Kwon等人,2020年;Li et al,2021a)。此外,最近的几项研究试图从原始文本中发现新的事件类型(Shen等人,2021;Edwards和Ji,2022)。然而,作为事件本体论的中心,论元角色预测一直是一项未被充分探索的任务。相关研究(Y uan等人,2018年;Liu等人,2019a)将角色名称限制在有限的词汇范围内,从而无法反映不同事件类型的独特特征。因此,在本文中,我们研究了一项重要但具有挑战性的任务:开放式词汇论元角色预测。
事件抽取:句子级事件抽取、文档级事件抽取。
3、方法
ROLEPRED包含三个核心组件:候选角色生成、候选论元抽取和论元角色选择(见图2)。下面阐述了论证角色预测的任务,然后依次描述了每个组成部分。

3.1 任务定义
形式上,给定一个事件类型和一组文档 D D D,每个文档 d ∈ D d∈D d∈D主要描述一个相同类型的事件实例 e e e。论元角色预测的任务旨在预测一组特定于事件的角色 R R R。每个角色 r ∈ R r∈R r∈R是一个短语或具有相似语义的短语集群。
3.2 论元角色生成
实体通常是事件的参与者。因此,在缺少可用论元的情况下,我们引入命名实体来生成论元角色的一些候选对象。具体来说,给定事件类型,对于每个文档 d d d,我们使用现成的命名实体识别工具(Honnibal和Montani,2017)从文本中识别所有实体 A A A。然后,我们将这些实体视为可能的论元,并尝试预测它们的角色。该候选角色生成过程被制定为掩码填充任务。对于每个实体 a ∈ A a∈A a∈A,我们构造一个带有mask词的提示,以输入到预训练的语言模型中。因此,模型通过解码其内部语义知识,将这些mask推断为该实体的角色名称。这种提示的构造如下:
Context. According to this, the < MASK SPAN> of this Event Type is Entity.
这里Context是指从源文档中提到实体的段落。它提供了事件和实体的详细背景描述。请注意,为了避免误导信息,删除实体后的不相关句子。然后,后面是包含< Entity >和< Event Type >占位符的自然语言模板。在推断过程中,这些占位符被具体的事件类型和实体替换。< MASK SPAN >表示长度可变的mask跨度。例如,给定地震的事件类型和下午5:36的实体,构建的提示如下:
The 1964 Alaskan earthquake, also known as the Great Alaskan earthquake, occurred at 5:36 PM AKST on Good Friday, March 27. According to this, the < MASK SPAN> of this earthquake is 5:36 PM.
在这种情况下,hMASK SPANi预计将填充时间,或开始时间作为参数角色。
此外,考虑到实体的一般语义类型:person、location、number或其他,我们稍微改变了提示结构,以流畅自然地支持揭开论元角色的过程。详情见表1。

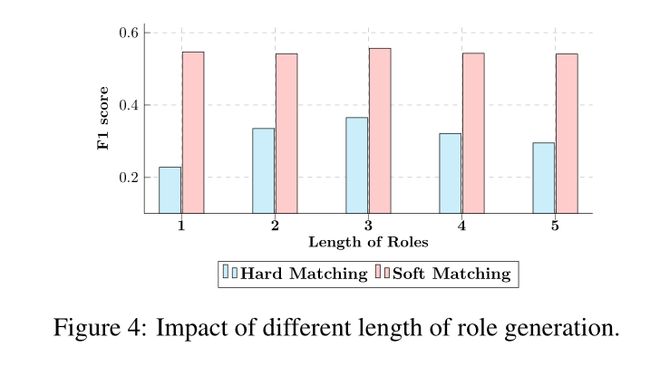
构建的提示被输入到编码器语言模型T5(Raffel等人,2020)中,用于候选角色生成。生成过程对给定先前token和编码器输入的选择新令牌的条件概率进行建模。注意,< MASK SPAN >的长度对于模型填充不是固定的。受SpanBERT(Joshi等人,2020)启发,T5从泊松分布(λ=3)中采样文本跨度数。每个跨度都用一个token替换。通过填充标记文本,该模型可以预测一个跨度中缺少多少token。因此,语言模型生成的角色是根据构建的提示的语义定制的不同长度的短语。与使用单个通用词作为角色名称的现有工作不同(Huang et al,2016;Y uan et al,2018;Liu et al,2019a),我们的角色更细粒度,并且包含更多的语义信息。这支持后续任务,即论元抽取,从文本中抽取事件的更多参与者。最后,语言模型为每个实体生成10个可能的论元角色。对于每个文档,我们集成所有实体的候选角色名称以供进一步选择。
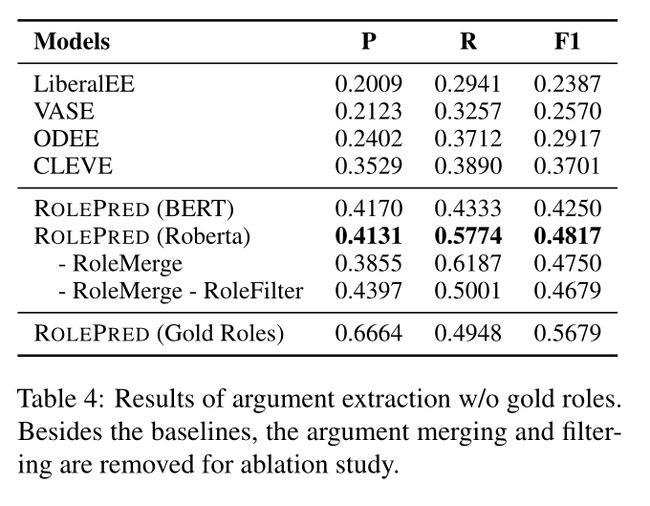
3.3 候选论元抽取
对于事件类型,其显著的论元角色通常由大多数事件实例共享。例如,每一次地震都有震级,但不一定会引发海啸。因此,这给候选词留下了确定相关和突出角色的挑战。直观地说,考虑到论元与事件角色的强烈相互依赖性,论元提供了一个可行的解决方案。按照这些思路,我们首先从每个文档中抽取所有候选角色的候选论元,然后使用这些论元进行角色选择(下一节将详细介绍)。
受一些现有论元抽取工作的启发(Lyu等人,2021),我们将此问题转化为一个问题回答任务。给定事件类型和候选角色,我们构建一个问题,并将其与文档一起输入到标准的双向预训练Transformer(BERT Devlin等人(2018),RoBERTa Liu等人(2019b))。QA模型用于识别每个源文档中的候选事件论元(文本跨度)。关于输入序列,我们遵循以下标准BERT样式格式:
[CLS] What is the Event Role in this Event Type event? [SEP] Document [SEP]
[CLS]是BERT的特殊分类token,[SEP]是分隔符,Document指的是输入文档的上下文token。例如,考虑到大流行的事件类型、伤亡的事件角色以及COVID19的文件,输入序列如下:
[CLS] What is the casualty in this pandemic event? [SEP] The COVID-19 pandemic is an ongoing global pandemic of coronavirus disease. It’s estimated that the worldwide total number of deaths has exceeded five million … [SEP]
在这种情况下,这个论元预计为five million。注意,对于某些角色,给定的文档可能不会提及其论元。也就是说,上述构建的问题可能没有答案。因此,对于每个抽取的答案,我们从QA模型中设置其概率阈值,以过滤掉一些不可靠的结果。此外,由于我们的数据集专注于每个文档的一个主要事件,与句子级事件抽取的相关工作不同(Huang和Ji,2020;Liu等人,2020;Ma等人,2022),我们需要在整个文档中搜索论点。这项任务更具挑战性,值得进一步探索。
到目前为止,在每个文档中,对于每个候选角色,都抽取了一个候选论元。因此,这些论元-角色对可以组成每个文档的一个事件实例。
3.4 论元角色选择
从每个文档中抽取主事件实例后,主要通过两个步骤选择候选角色:论元角色筛选和合并。具体而言,对于一种事件类型,其不同的事件实例可以呈现不同的属性。然而,这些例子通常有几个共同的和重要的论元角色(例如,地震事件的强度和颁奖典礼的主持人)。因此,我们通过涉及相同类型的多个事件实例来判断论元角色的显著性。假设只有当大多数事件实例都有其关联的论元时,角色名称才属于事件类型。
关于论元角色合并,不同的角色可以表示相似的语义,并在事件中共享相同的论元。例如,日期、正式日期和原始日期通常指烟花活动的同一天。通过合并相似的角色名称,我们可以在减少其数量的同时增加其特定性,从而提高后续论元抽取步骤的效率。沿着这条线,我们基于两个角色在事件实例中共享相同论元的频率来确定两个角色的语义相似性。例如,给定暴风雪事件的10个实例,如果两个角色、数据和正式日期在5个实例中与它们的论元相同,则它们的相似度为0.5。我们设置了一个阈值来选择语义上相似的论元角色并合并它们。
4、数据集构建
4.1 数据收集
在新闻界的热门话题中,我们精心挑选了50种具有影响力的事件类型,如地震、内乱和军事占领。为了扩大领域覆盖范围,这些活动类型涵盖了许多领域,包括政治、学术、艺术、体育、军事、天文学和经济学。由于这些事件通常包含丰富的论元角色,因此需要多个句子来描述。因此,它更适合于文档级事件抽取。
论元角色设计:为了构建事件特定的论元角色,我们利用维基百科中的事件列表。这样的列表显示了同一类型的多个事件实例的关键属性。例如,图3显示维基百科列出了最近的大地震。它们的属性可以被视为事件类型的原型论元,例如year、magnitude、location和depth。基于这一观察,我们为每种事件类型搜索一个wiki列表,并将属性用作基本的论元角色集。然后,我们手动处理这些论元角色:(1)将缩写更改为通用全名,如MMI更改为Magnitude,(2)将事件名称更改为触发词(维基百科列表中的名称或事件通常指事件实例的名称,可以视为触发词),以及(3)删除注释,该注释为事件实例添加了额外的细节,但不适合作为论元角色。通过维基百科中的手动标注,我们为每种事件类型设计了自定义的论元角色。

实践论元标注:对于每种事件类型,维基百科列表通常包含多个事件实例。列表中的每一行都显示有关一个事件的信息。每行的值可以被视为事件的论元。例如,“1960 Agadir earyhquake”的震级为5.8级。对事件实例进行进一步清理以确保质量:删除论元不完整(例如,空值或明显错误)的事件实例,删除源文档不可访问的事件实例(文档获取将在下一节介绍)。对于合格的事件,其论元会经过仔细的手工修改:(1)仅保存所选角色的论元,(2)删除论元中的特殊符号或引用,仅保留关键信息,以及(3)丢弃相应文档中未提及的论元(因为它们可能来自其他来源,无法从我们的文档中抽取)。最后,对于每个事件类型,我们获得多个事件实例。
源文件采集。对于每个事件实例,我们采用其维基百科文章作为标注事件论元的源文档。具体来说,维基百科列表通常会提到事件名称,并提供相应维基百科文章的URL。例如,如图3所示,第一次地震事件与维基百科1960年阿加迪尔地震的文章有关。这些文档描述了一个主要事件,通常会提到维基百科列表中的大多数事件论元。否则,这些论元将被清除。我们确保每个事件实例都有一个源文档。此外,删除了少于4句的文件。
4.2 数据分析

5、实验


6、总结
本文研究了一项具有挑战性但至关重要的任务:开放式词汇论元角色预测,并提出了一种新的无监督框架ROLEPRED,作为未来工作的强大基线和精心设计的事件抽取数据集。
限制
然而,尽管非实体论元相对较少,但它们在许多事件中也扮演着重要的语义角色。我们的框架在预测此类非实体论点的角色时可能会受到阻碍。因此,我们的下一步是更广泛地涵盖不同类型论元的角色。
此外,我们的框架将一组相关文档作为输入。它需要足够的事件实例来选择重要角色。此外,生成的论元角色的质量在很大程度上取决于文档选择。因此,对于给定的事件类型,检索有限数量的代表性文档可以被认为是论元角色预测的有趣主题。
此外,大多数现有工作为事件类型而不是单个事件实例定义论元角色。这些论元角色由同一类型的多个事件实例共享。然而,不同的事件实例可以具有个性化特征。例如,震级是所有地震的共同论点,但造成的滑坡数量可能是某些地震的特定作用。这些特定角色可以帮助确定事件提取的指定和重要论元。因此,我们希望在未来的工作中为一个事件实例定制角色。
最近工作
自然语言处理和计算机视觉相关论文总结_Trouble…的博客-CSDN博客