RNN、LSTM、GRU序列模型对比
原文链接:RNN、LSTM、GRU序列模型对比
大家好,我是泰哥。我通过5篇文章对深度学习的基础做了系统性总结,都是追根溯源,从发展的角度去说明每个模型是如何诞生的:
在NLP领域,最常用的应该就是RNN系列的序列模型。本文主要介绍:
- 1 为什么需要RNN
- LSTM与GRU的不同之处
- LSTM的Pytorch代码使用要点
- 双向LSTM的注意事项
1 为什么需要RNN
RNN对具有序列特性的数据非常有效。它能挖掘数据中的时序信息以及语义信息,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
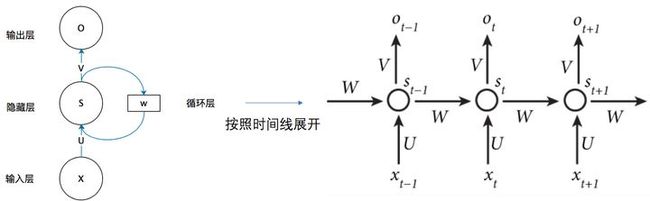
当我们处理视频时,也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列;当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列。
2 LSTM与GRU的不同之处
这个问题是NLP同学准备面试时的必备问题,也是理解RNN系列模型的关键所在。我将他们的不同之处按输入与输出作为区分:
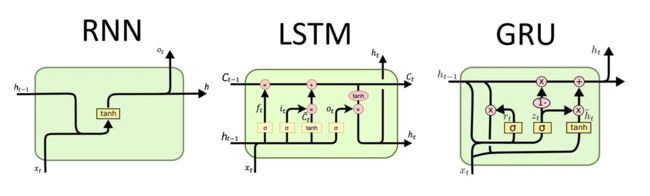
- RNN为2输入,1输出。
两个输入为上一单元输出状态和数据特征,输出为本单元的输出状态。本单元输出有两个作用,第一是在本单元作为输出依据进行后续计算,第二是传入下一个单元。
- LSTM为3输入,2输出。
三输入分别为上一单元的内部状态C、上一单元的输出状态h以及本单元需要输入的数据特征,两个输出为本单元的内部状态C以及本单元的输出状态h。
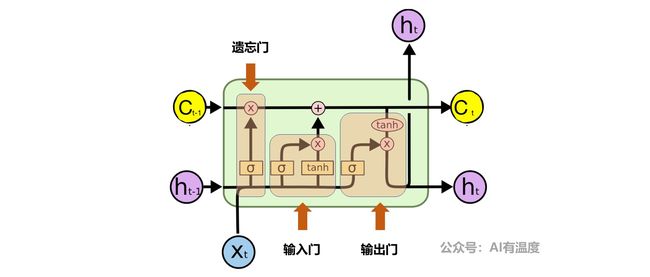
其中LSTM的输入和输出都比RNN多了一个,多的都是内部状态C。它的作用是将过去与现在的记忆进行合并,这就需要遗忘门(过去)与输入门(现在)进行控制,它可以认为是理解LSTM的核心。
而输出门的结构其实与rnn一样,所以大家可以重点理解内部状态C即可。
以上是对LSTM的概况性总结,具体公式推演及详解,建议大家阅读文章:人人都能看懂的LSTM。
- GRU为2输入,1输出
我们可以看到GRU的输入与输入数量与RNN相同,比LSTM少。GRU是在2014年提出的,而LSTM是1997年,GRU是将LSTM里面的遗忘门和输入门合并为更新门。
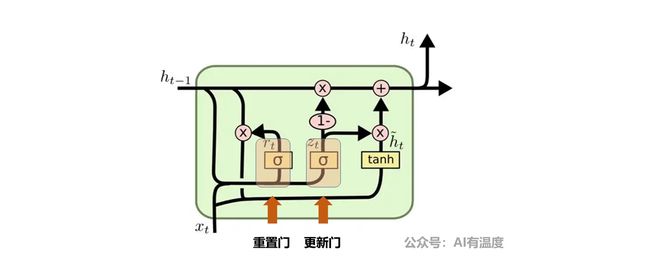
GRU的两个输入为上一单元输出状态以及当前数据特征,输出为本单元的输出状态。
以上是对GRU的概况性总结,具体公式推演及详解,建议大家阅读文章:人人都能看懂的GRU。
3 LSTM的Pytorch代码使用要点
通过官方文档,可知LSMT的参数:torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
input_size:输入数据的形状,即embedding_dimhidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元num_layer:即RNN的中LSTM单元的层数batch_first:默认值为False,输入的数据需要[seq_len,batch,feature],如果为True,则为[batch,seq_len,feature]dropout:dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropoutbidirectional:是否使用双向LSTM,默认是False
实例化LSTM对象之后,不仅需要传入数据,还需要前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
即:lstm(input,(h_0,c_0))
LSTM的默认输出为output, (h_n, c_n)
output:(seq_len, batch, num_directions * hidden_size),batch_first=Falseh_n:(num_layers * num_directions, batch, hidden_size)c_n:(num_layers * num_directions, batch, hidden_size)
假设数据输入为 input ,形状是[10,20],假设embedding的形状是[100,30]
则LSTM使用示例如下:
batch_size =10
seq_len = 20
embedding_dim = 30
word_vocab = 100
hidden_size = 18
num_layer = 2
#准备输入数据
input = torch.randint(low=0,high=100,size=(batch_size,seq_len))
#准备embedding
embedding = torch.nn.Embedding(word_vocab,embedding_dim)
lstm = torch.nn.LSTM(embedding_dim,hidden_size,num_layer)
#进行embed操作
embed = embedding(input) #[10,20,30]
#转化数据为
batch_first = False
embed = embed.permute(1,0,2) #[20,10,30]
#初始化状态, 如果不初始化,torch默认初始值为全0
h_0 = torch.rand(num_layer,batch_size,hidden_size)
c_0 = torch.rand(num_layer,batch_size,hidden_size)
output,(h_1,c_1) = lstm(embed,(h_0,c_0))
#output [20,10,1*18]
#h_1 [2,10,18]
#c_1 [2,10,18]
输出如下:
In [122]: output.size()
Out[122]: torch.Size([20, 10, 18])
In [123]: h_1.size()
Out[123]: torch.Size([2, 10, 18])
In [124]: c_1.size()
Out[124]: torch.Size([2, 10, 18])
通过前面的学习,我们知道,最后一次的h_1应该和output的最后一个time step的输出是一样的
通过下面的代码,我们来验证一下:
In [179]: a = output[-1,:,:]
In [180]: a.size()
Out[180]: torch.Size([10, 18])
In [183]: b.size()
Out[183]: torch.Size([10, 18])
In [184]: a == b
Out[184]:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
dtype=torch.uint8)
4 双向LSTM的注意事项
如果需要使用双向LSTM,则在实例化LSTM的过程中,需要把LSTM中的bidriectional设置为True,同时h_0和c_0使用num_layer*2,观察效果,输出为:
batch_size =10 #句子的数量
seq_len = 20 #每个句子的长度
embedding_dim = 30 #每个词语使用多长的向量表示
word_vocab = 100 #词典中词语的总数
hidden_size = 18 #隐层中lstm的个数
num_layer = 2 #多少个隐藏层
input = torch.randint(low=0,high=100,size=(batch_size,seq_len))
embedding = torch.nn.Embedding(word_vocab,embedding_dim)
lstm = torch.nn.LSTM(embedding_dim,hidden_size,num_layer,bidirectional=True)
embed = embedding(input) #[10,20,30]
#转化数据为batch_first=False
embed = embed.permute(1,0,2) #[20,10,30]
h_0 = torch.rand(num_layer*2,batch_size,hidden_size)
c_0 = torch.rand(num_layer*2,batch_size,hidden_size)
output,(h_1,c_1) = lstm(embed,(h_0,c_0))
In [135]: output.size()
Out[135]: torch.Size([20, 10, 36])
In [136]: h_1.size()
Out[136]: torch.Size([4, 10, 18])
In [137]: c_1.size()
Out[137]: torch.Size([4, 10, 18])
在单向LSTM中,最后一个time step的输出的前hidden_size个和最后一层隐藏状态h_1的输出相同,而在双向LSTM中:
output:按照正反计算的结果顺序在第2个维度进行拼接,正向第一个拼接反向的最后一个输出
hidden state:按照得到的结果在第0个维度进行拼接,正向第一个之后接着是反向第一个
- 前向的LSTM中,最后一个time step的输出的前hidden_size个和最后一层向前传播h_1的输出相同,示例:
#-1是前向LSTM的最后一个,前18是前hidden_size个
In [188]: a = output[-1,:,:18] #前项LSTM中最后一个time step的output
In [189]: b = h_1[-2,:,:] #倒数第二个为前向
In [190]: a.size()
Out[190]: torch.Size([10, 18])
In [191]: b.size()
Out[191]: torch.Size([10, 18])
In [192]: a == b
Out[192]:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
dtype=torch.uint8)
- 后向LSTM中,最后一个time step的输出的后hidden_size个和最后一层后向传播的h_1的输出相同,示例:
#0 是反向LSTM的最后一个,后18是后hidden_size个
In [196]: c = output[0,:,18:] #后向LSTM中的最后一个输出
In [197]: d = h_1[-1,:,:] #后向LSTM中的最后一个隐藏层状态
In [198]: c == d
Out[198]:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
dtype=torch.uint8)
LSTM/GRU使用注意点
- 第一次调用之前,需要初始化隐藏状态,如果不初始化,默认创建全为0的隐藏状态
- 往往会使用LSTM or GRU 的输出的最后一维的结果,来代表LSTM、GRU对文本处理的结果,其形状为
[batch, num_directions*hidden_size],需要注意的是:- 并不是所有模型都会使用最后一维的结果
- 如果实例化LSTM的过程中,batch_first=False,则
output[-1] or output[-1,:,:]可以获取最后一维 - 如果实例化LSTM的过程中,batch_first=True,则
output[:,-1,:]可以获取最后一维
- 如果结果是
(seq_len, batch_size, num_directions * hidden_size),需要把它转化为(batch_size,seq_len, num_directions * hidden_size)的形状,不能够不是view等变形的方法,需要使用output.permute(1,0,2),即交换0和1轴,实现上述效果 - 使用双向LSTM的时候,往往会分别使用每个方向最后一次的output,作为当前数据经过双向LSTM的结果
- 即:
torch.cat([h_1[-2,:,:],h_1[-1,:,:]],dim=-1) - 最后的表示的size是
[batch_size,hidden_size*2]
- 即:
原文链接:RNN、LSTM、GRU序列模型对比