一点就分享系列(理解篇3)—Cv任务“新世代”之Transformer系列 (上篇-通俗详细导读篇)
一点就分享系列(理解篇3)—Cv“新世代”之Transformer系列 (上篇-导读)
最近,在目标检测系列如sparse-rcnn,OneNet等论文模型让人眼前一亮。另一方面,transformer在图像上的应用也让人不能忽视,脸书搞得2个版本dert(启蒙版本)以及后面的T2T-VIT都是颠覆CNN视觉任务的产出。在此之前,需要理解透彻这个算法,该篇目的旨在transformer以其CV模型系列开启视觉任务的“新篇章”,以NLP小白0基础view,讲述我的理解,如有错误,还请批评指正!目录
- 一点就分享系列(理解篇3)—Cv“新世代”之Transformer系列 (上篇-导读)
- 前言
- 一、transformer为何出现
-
- 1.基于网络本质特点
- 2.基于视觉任务特性
- 3.AI领域发展
- 二、最简洁理解transformer
-
- 1.概览结构
- 1.1输入部分-词嵌入和位置编码
- 1.2 Self-Attention
- 1.3优秀的“多头”机制
- 1.4 残差结构和LN归一化层
- 1)LN和BN
- 2)encoder流程
- 1.5 Decoder
- 1)第一个注意力层-Masked-Multi-Head Attention
- 2)第二个注意力层-Multi-Head Attention
- 3)decoder具体流程:(重点讲述Masked在self-attention的计算过程)
- 4)decoder训练过程补充说明
- 三.总结—阅读理解,灵魂拷问:
前言
Google 2017年的论文 Attention is all you need !论文提出了Transformer模型,抛弃传统的RNN和CNN。
阅读本篇,您将获得如下:
1.为什么要用transformer?结合自身感悟谈!
2.transformer是什么?带你一起剖析!对结构BN,LN的理解!
3.最简洁让你理解transformer!
4.transformer在视觉任务中的进展,以及下篇中将涉及到的模型。
以下是本篇文章正文内容
一、transformer为何出现
1.基于网络本质特点
1) CNN在图像上是非常成功的应用,卷积提取高层特征,卷积和池化的平移不变性等,拥有强大的拟合能力,并在残差的结构下得到了进化,更深的网络和更好地弥补上下文的结合,提高的泛化能力。CNN没有什么问题,只是以人的视觉机制来说,似乎看起来,transformer以其注意力机制去更好捕获上下文,更加符合人类的角度,使得特征之间建立更长远的依赖,提取更优的特征,那么研究者们当下,就是想把两者融合,实现1+1>2的效果,毕竟DL一直都存在着后验性。
2)对于RNN,时序性的结果意味着并行计算能力不足,因为BERT的transformer结构将使得注意力机制很好的应用,以及可以同时并行去接受词句(在其内部self-attention中,以向量组成的矩阵实现并行计算,这点是突破RNN的关键)这里后面会在结构里详细说明。
2.基于视觉任务特性
我们之前接触的模型,比如检测系列的yolo,ssd等需要大量的先验anchor和人为干预的后处理nms去筛选BOX,这样不只是加大计算量,带来的精度和人工调整超参也是很耗时的,最终使得任务不够精简,其实并不是人们心中的“完美检测”,而transformer就是以自注意力机制去模仿人类关注应该关注的目标。
那么anchor free 那种以点来取代BOX的做法,在我个人看来,本质上仍旧是指标不治本,anchor base和anchor free的本质都是多个BOX或者多个点,来匹配唯一的目标,即都是多对于一效果。而分割比如论文Segmentation Is All You Need,则无法满足性能需求!(这里给出该论文的叙述,意思一样,但是人家写的好)
边界框(Bounding Box)不应该存在:
虽然 anchor 的存在减少了很多计算量,但是也带来了超参数增加、人为调参过拟合评测数据集、前后景目标类别不平衡等一系列令人头疼的问题。
让我们回到边界框的本质。所有的边界框其实都是一种无限制保证前景物体像素召回率的标注方式,它会尽可能贴着外轮廓,因此会导致背景像素大量进入框内。然而,真实世界的物体可以随意转动,不同的机位拍一个3D 物体出现的结果可以大不相同,因此用框作为一个表征工具来把东西框起来,本身就不稳健。而且,框的标注本身也带有一定的随机性,毕竟要遵守标注规则把框标得非常好可能花的成本也会很高。
非极大值抑制(NMS)不应该存在:
NMS 是一项很神奇的工作,目标检测领域用 NMS作为选框策略已经有大概几十年了,因为没有一项工作能超越它。然而如上所述,既然边界框本身并不稳健,选出的框再优秀也无济于事。更何况选出的框也不会格外优秀,因为真实世界里不可能有一个具体的阈值来控制所有的场景,例如遮挡问题。现实世界中的遮挡问题十分复杂,挡了一部分和挡了一大半完全不是同一种情况。既然如此,用一个单一的阈值怎么可能解决问题?事实上,在之前的工作中,动态调整NMS 的 SoftNMS、动态调整 IoU 的 Cascade RCNN方案都取得了很不错的结果,但前者依然回避了「复杂遮挡」的复杂性,后者参数量激增,速度慢到难以想象。
那么彻底来抛弃anchor和Nms的做法,化繁为简,试想以下,这是否更符合一个更接近人类视觉的模型。
3.AI领域发展
在行业领域也是多模态算法发展的一个成果。将不同任务或处理不同数据的模型trick彼此结合使用,NLP和CV的互相进步就是典型案例了,当下AI的趋势不仅仅只偏向于工程部署落地,大家都会炼丹跑Demo,DL拉低了门槛,但同时也突破了上限,那就是结合业务需求绑定,比如CV和NLP的结合,点云和图像,图像和文本等,也就是基于数据和不同模型方法的多模态趋势,因此不管你是搞啥的,只要有兴趣就可以开始从NLP中transformer开始。
二、最简洁理解transformer
1.概览结构
走个程序,还是要规规矩矩,按照论文开始,毕竟可以盗图用,下面我会以一个最简单方式且附我的理解去说明。
首先,我们全局看下transformer结构:
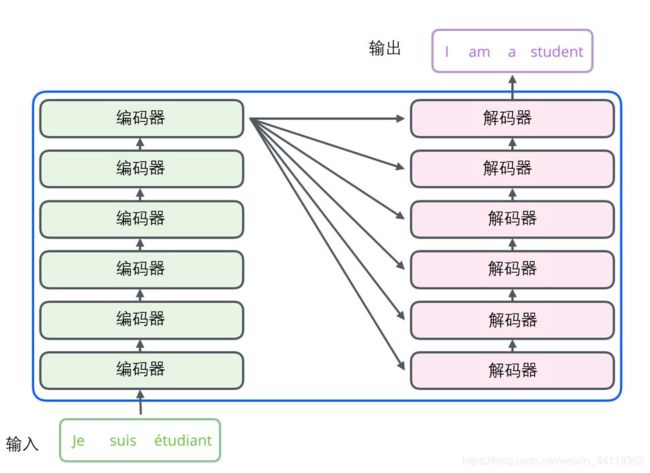 如图,transformer的结构主要就是由多个编解码器组成,且这些编码器和解码器各自的内部构造是完全相同,只是权重参数不同!先分析编码器,按顺序来!
如图,transformer的结构主要就是由多个编解码器组成,且这些编码器和解码器各自的内部构造是完全相同,只是权重参数不同!先分析编码器,按顺序来!

1.1输入部分-词嵌入和位置编码
从这个输入部分开始看,embedding——词嵌入,简单理解为将原始数据转换成向量形式 ,通过一种映射的形式,有独热编码,也有worf2vec等初始化方法(感兴趣的具体自行查阅资料),那么这里的步骤:
- embedding就是做这个词嵌入的向量转换操作!这个过程可以用,例如独热编码来作初始化。
- 可以看到Positional encoding,这个操作是什么呢?顾名思义,补充位置相关信息的!Transformer 因为 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。而RNN的原理是一个句子的词语作为输入,是按照时间顺序串行在网络中的,具有前后顺序的相关性,Positional encoding在transformer中就是弥补这个的。
- 因此,需要构造一个跟输入embedding维度一样的Positional encoding矩阵,这里维度数是按照经验法则,并没有绝对标准!(这是人工设计的参数通过例如独热编码来作的初始化)。和embedding相加是最终的目的,如下公式,该公式是奇数sin和偶数位置cos的计算方式!

其中,PE为二维矩阵,大小跟输入embedding的维度一样,行表示词语,列表示词向量;pos 表示词语在句子中的位置;dmodel表示词向量的维度,i表示词向量位置。
PE(sin,cos,sin,cos,…cos),假设词向量维度是512.那假如有且仅有1个词嵌入操作将单词A,转换成了512维度的向量B[B0,B1,…B512],那么就是:PE+B!,一个新的512维度的向量,多个词的话就是矩阵形式!这个就是transform的输入最终形态.那么也许有人会问这个位置编码公式为什么能够解决位置问题?因为三角函数原理!
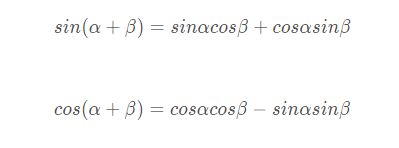
不难看出,由位置编码公式带入到三角函数发现,从数学角度,即由可以由PE表达式去表示 ,也就是PE通过了线性组合去表示了sin(pos+k),答案出来了,最简单的理解来了!
那么如果位置编码公式是表示了词向量的绝对位置,那么三角函数则代表着前后的相对位置,那么以上的结论就是:通过线性变换获取后续词语相对当前词语的位置关系。
换个大白话:这意味着!位置编码不仅表示了绝对位置,同时还表示着相对位置。
1.2 Self-Attention
逃课关键词:框架的结构精髓——矩阵化输入向量并行计算,RNN做不到!
在以上得到编码位置相加后的新向量,进入第2层注意力层,也是核心!它需要调整去分析我们关注目标的权重,那在NLP中,我们如何确定要关注的权重呢?先来说下如何attention?
具体操作:主要计算两个句子之间词与词的相似度,这里词向量的相似度用的是点积(两个词向量越接近,它们的距离和夹角就越小,所以乘积也会越大),所以乘积结果越大越相似!!然后,归一化后作为权重,并通过权重以及另一个句子的各个词向量,结合起来得到用另一个句子表示的该词的词向量。
原始的注意力计算框架是由谷歌提出的,通过这个框架,我们可以计算出权重(也就是分配的注意力),并最终计算出一个对应的attention value,但它不是主角,有兴趣的自行学习理解,给个公式:

注意力机制有多种,这里我们只讲transformer的核心:自注意力机制,这里简单说明下:输入序列和输出序列的内容甚至长度都是不一样的,注意力机制是发生在编码器和解码器之间,也可以说是发生在输入和输出之间。而自注意力模型中的自注意力机制则发生在输入序列内部,或者输出序列内部,也就是该层网络的输入和输出,可以抽取到同一个句子内间隔较远的单词之间的联系,给出关键公式:

这个self-attention 计算过程,如图:
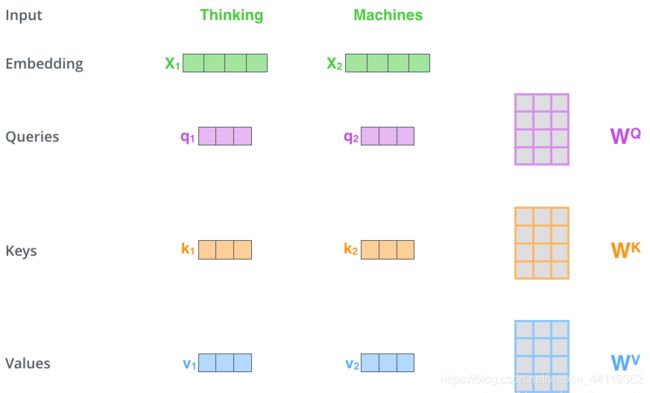
首先,需要3个矩阵,Q为查询向量,K为键向量,V为值向量,
但是在当前经历了输入后,我们只有词向量,如何获取这三个向量呢?
图中以及告诉我们了,在词嵌入后的 所有的词向量X1,X2,都共享一套参数,图中右侧的WQ,WK,WV的可学习参数矩阵——对应相乘,得到的Q,K,V三个向量。这些都是词向量的线性变换得到的!
接下来,按照下图顺序进行计算,很清晰的:用上述提到的相似度计算——点乘
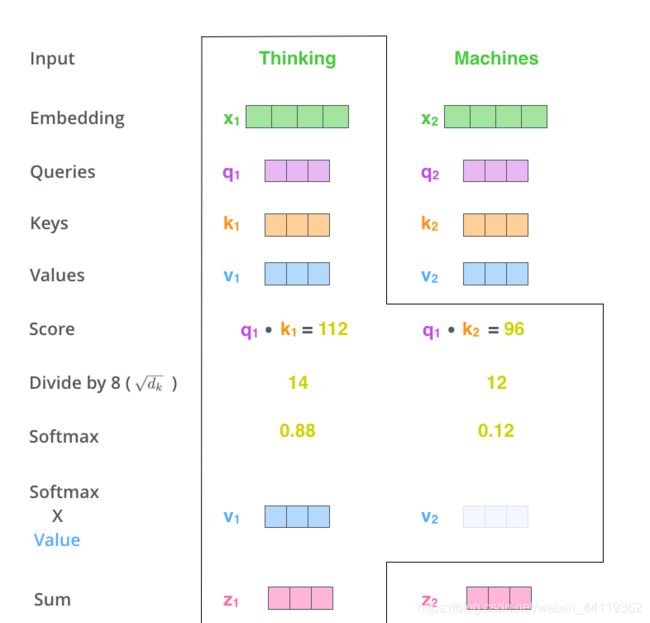 然后将分数除以8(8是论文中使用的键向量的维数(dk=64)的平方根,这会让梯度更稳定?)
然后将分数除以8(8是论文中使用的键向量的维数(dk=64)的平方根,这会让梯度更稳定?)
NLP小白的个人理解:在Q和K相乘后,如果值很大或者很小,在softmax归一化计算后,会影响梯度,那么做这种操作无非就是为了控制方差,稳定梯度。
使用 Softmax 计算每一个单词对于其他单词的 attention 系数
然而实际中,这些计算是以矩阵形式完成的,同时也完成了并行化的计算,如下图: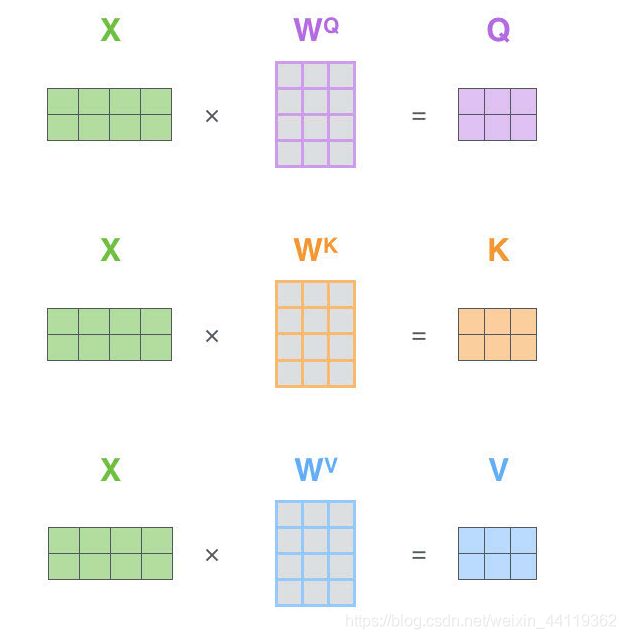
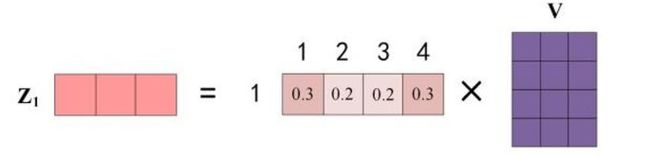
最后一步:按照计算过程的步骤图,对softmax后加权值向量求和然后即得到自注意力层的最终输出。得到的向量Z就可以传给前馈神经网络,具体形式如下盗图所示,助于理解~
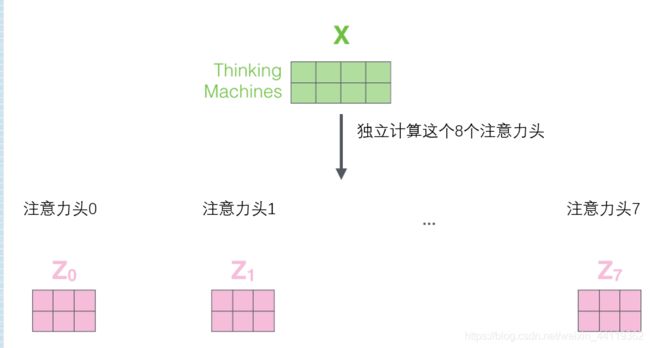
1.3优秀的“多头”机制
这个多头机制,盲猜后续的很多CV论文都会用这种结构去训练!(果然,此时此刻,1个月后的我发现了transformer的产出越来越多,优秀的多头机制在Onenet中也得到了应用)
如下图,就是多加了一套而已。。由于这种操作效果比较好,其实类似于多尺度的思想,只不过这个是多空间,将多头下的输出向量合并——信息融合,就是多头注意力机制的输出,将输入的X分别送进不同的HEAD里面计算,最后拼接起来,做一次liner线性矩阵乘法。

下面具体总结下:
- Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到N个不同的 Self-Attention 中,计算N个输出结果.
- 得到对应的N个输出矩阵之后,Multi-Head Attention 将N个输出contact拼接在一起 ,然后传入一个Linear层,得到 Multi-Head Attention 最终的输出。这里, Multi-Head Attention 输出的矩阵 与其输入的矩阵的维度是一样的。
如下图,是一个2头的Multi-Head Attention实验分析图,绿色代表的层密集一些,代表更关注全局信息,而红色则更关注局部信息。

1.4 残差结构和LN归一化层
每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤,这个CV小伙伴门老掉牙问题,解决的问题就是梯度消失+网络加深,但是小batch还是精度会低,所以才有了各种变相扩大batch的trcik,这里不做讨论,一笔带过!
重点来了LN是一个很重要的点,如果是nlp方向的小伙伴会了解到在NLP的任务BN的使用因为效果较差使用较少,那么为什么呢?关于这点,有很多解释和理论推到,太多的理论就不说了,那么BN为什么在RNN等NLP的任务中不行嘛呢?我会以多个角度讲懂你!
1)LN和BN
我自己的理解是:本质我认为是数据的差异和处理的维度不同!一句话解释:各自学习所关注的维度不同!
- BN的方式是对同一维度的每一个特征做归一化,这个维度很重要!那么(N,C,H,W,)对每 N,H,W的三个维度进行归一化;然后乘归一化的维度个数,C个权重参数;
- LN,其归一化维度是C、HxW维度或者HxW维度或者W维度,归一化时不考虑batch,对输出N个维度的值进行归一化计算,然后乘归一化的维度个数,(比如C x H x W)的权重参数;
- 其次,因为算法就是拟合嘛!BN用Batch内的样本数据方差和均值去模拟全部的数据的方差和均值!这样可能出现一个问题就是当你的batch size较少就效果不好,也就是说“少数不能代表多数”!
上述时对照公式的解释,如果你不会BN公式那就尴尬了 ,我做梦都能背下来的东西呢。。接下来举个例子,帮助大家理解!
在图像中由于训练尺度往往在CNN中固定,那么BN可以达到效果,总归是数据结构的差异,那么RNN中由于样本的词句是不同长度的,比如你有10个句子,前9个句子都有5个词,那么第10个句子有10个词,那么当你用BN计算前9个句子的每个单词的均值和方差时候,当后面的5个词的位置是空的,那么有值得地方就是第10个句子的后5个词了,以偏盖全,就不好了!
上述说明用BN在样本长度不一的情况下,计算的均值和方差实际没有意义了。
我们继续,那么再说LN层,LN处理维度是和BN不同的,盗个图表示下:
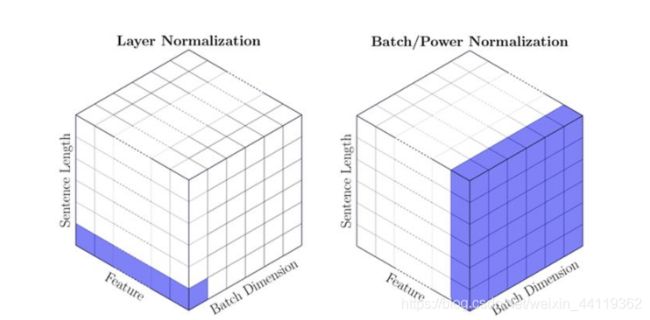
因为每个样本的词句长度不同,而LN的方向明显不同,简单来说,有3个轴,一个是样本数量,一个是样本的特征向量,那么LN保证了在空间中会获得相同的数量(通道数)个数值的归一化方差和均值。(想象一下,BN和LN图中的样本维度其实是不固定的,按着BN的计算方向是断章取义了)
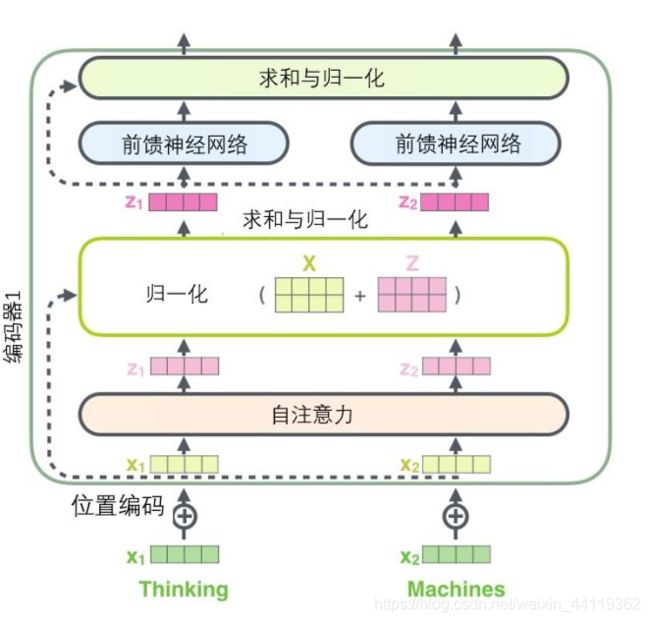
2)encoder流程
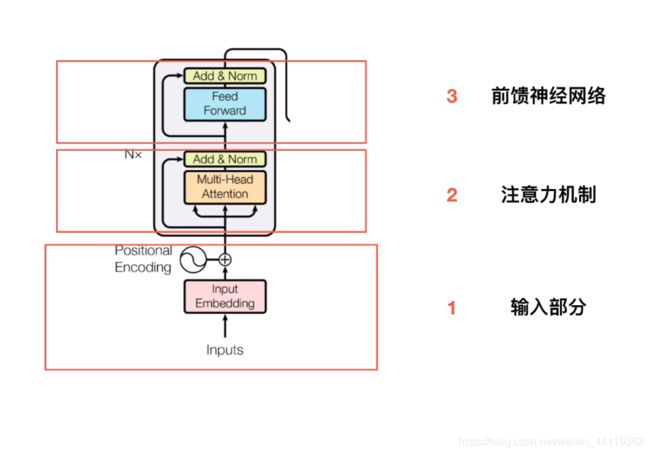
encoder的整体流程,如下图!回顾一遍:
- 经过向量Input, 通过一个Input Embedding的参数矩阵W变为了一个张量Xn ,再加上一个表示位置的Positional Encoding 的向量P,得到一个新张量Xd;
- Xd进入了注意力层,它的第1层是一个上文讲的multi-head的attention。一个sequence 的Xd ,经过一个multi-head的attention,你会得到另外一个sequence ,Output ——张量Xe。
- Add & Norm,把multi-head的attention的layer的输入Xd和输出Xe进行相加以后,再做Layer Normalization,再做Layer Normalization,也就是LN(Xd+Xe)
- 最后是前馈网络和一个Add & Norm Layer,就是LN(Xd+Xe)+FeedForward-Liner(LN(Xd+Xe)),作为1个Block(Xd)
- 实际中网络是有N个**Block(xd)**组成,Block(…Block(Block(xd)).
1.5 Decoder
1)第一个注意力层-Masked-Multi-Head Attention
由于结构和原理计算阐述在encoder部分已经详细说明过,所以这里不做赘述,decoder结构如下图:
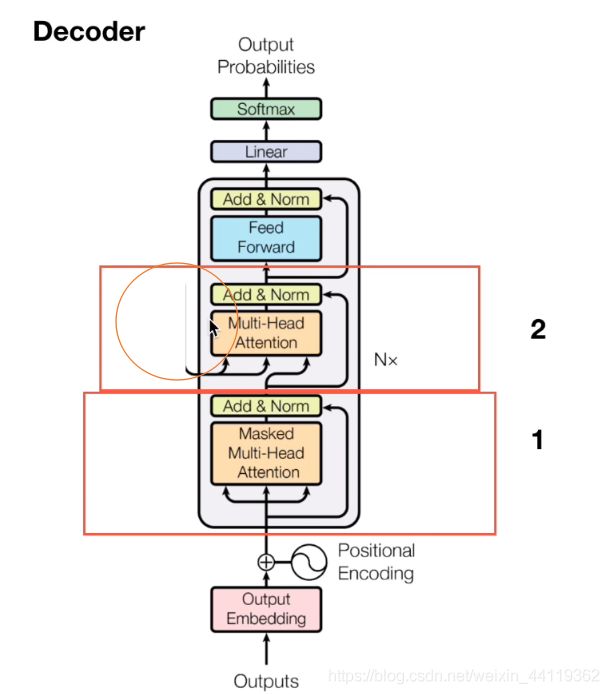
先看下所有的输入input,包括两个部分:一个decoder的output和encoder的输出,这里如上图我画了圈圈的地方就是encoder的输出…所以中间的attention不是self-attention,它的K和V两个向量是来源于自encoder,Q 是docoder的第一层的output。
这里要特别注意一下,编码模块可以并行计算,但解码部分不是一次把所有序列解出来的,而是和RNN一样按照顺序
解出来的,因为要用上一层的输出当作attention的query向量。
这里第一层的多头注意力机制是带有掩码mask的!为什么?
这里说明下deocer解码部分的Masked -多头自注意力层.
逃课关键词:Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译
- masked的意思是使attention操作于已经产生的sequence,也就是在网络的翻译的过程中是顺序输出的,翻译完当前样本的单词,才可以翻译下一个样本单词。
- 通过 Masked 操作防止第了 i 个单词知道 i+1 个单词之后的信息,具体看下图!(简单理解为,做练习题目,一边翻答案一边做.效果能好?)
如图,和encoder区别就是结构上的掩码机制,保证了输出——第i个单词具有前面i-1个共同得到的,那么掩码的精髓就是这个意思… 反之,没有掩盖那么实际推理结果会出现词语重复结果,故需要掩盖机制。
换个角度,这里要分详细来解释:
逃课关键词:Decoder 在训练和推理测试部分是不同的策略:测试类似RNN个个顺序输出,训练则是类似encoder的矩阵并行化策略,且masked是在softmax前计算的
- 在训练时候,因为decoder进行的是并行训练GT和当前对应的输出output是一并输入在decoder中,具体细节就是引入了teaching force 的策略:(使用了teacher force,不管当前翻译的结果是否正确,都使用正确的答案参与后面的decoder的计算中)
训练时,第i次的输入为上次i-1的输出加上输入序列向后移一位(i+1)的gt(每向后移一位就是一个新的单词,那么则加上其对应的embedding),那么如果是第一次输入呢?那么decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的标记单词token,可能是目标序列开始的token(如),也可能是序列结尾的token(如),也可能是其它;
这是techa forcing代码,作为一种有用的训练技巧,主要是因为:
Teacher-Forcing 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大。
Teacher-Forcing 能够极大的加快模型的收敛速度,令模型训练过程更平稳。
缺点,就是会矫枉过正,比如测试时候效果不一定如预期的好。所以mask操作个人理解也是为了缓解这个问题,这个是trick代码:
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
另一个细节就是,在decoder训练中是一次性把目标序列的embedding通通输入到block中,然后在多头attention模块对序列进行mask.
关于Loss流程,小节后面会提到。
- 在测试的时候,是先生成第一个位置的输出,然后有了这个之后,第二次预测时,再将其加入输入序列,以此类推直至预测结束。这样在预测第i个词语时候,需要把第i+1之后的词语盖住,对应上述说的训练防止“作弊”哈哈。
比如,样本序列,输入A,解码器输出B 。
输入前面已经解码的A和 B,解码器输出C。
输入已经解码的,每次解码都会利用前面已经解码输出的所有单词嵌入信息。
2)第二个注意力层-Multi-Head Attention
和encoder结构相同!!不做复述,只是区别在于:其中 Self-Attention 的 K, V矩阵不是使用第一层的注意力输出计算的,而是使用 Encoder 的编码输出来计算的。
整体详细交互结构,如下两图,交互过程:产生的所有的编码器的输出结果是K,V矩阵和decoder的Q矩阵交互!
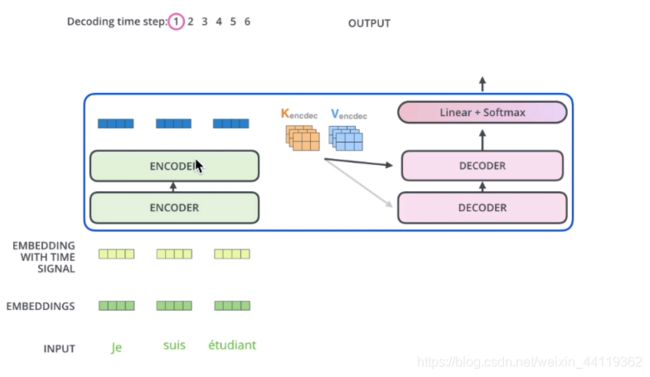

该图和上述交互过程一致,encoder的输出和每一个decoder的交互层都需要对应计算!好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 。
3)decoder具体流程:(重点讲述Masked在self-attention的计算过程)
- 来自上一个decoder的位置输入O,加位置Positional Encoding 的PE ,得到新的解码层输入张量Oi
- Oi 进入到Masked的MUTI-head attention 层,这里Oi 还是经过transformation matrix变为3个矩阵:Q ,K 和V,接着Q和K作attention,将Q转置和K作乘法,得到A矩阵。
- A和构造的Mask矩阵做乘法,掩盖其矩阵的部分元素,Mask矩阵构造为下三角阵M,为什么?写个草图加深理解。
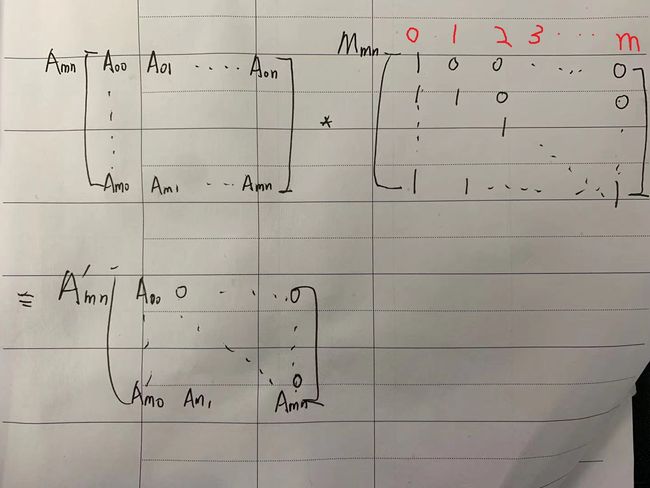
这样通过掩码机制,将后面的词盖住了,得到新的矩阵A”;接着进行注意力层的 常规计算后softmax后,得到B 作为概率矩阵,其中,如果是预测的第i个,那么第i个后面的单词概率得分都为0,因为用了Masked操作。 - B和V矩阵相乘,得到self-attention层的输出Z矩阵。
- 因为是Muti-Heaf,所以要将多个Z矩阵拼接,得到Zi, 进行Liner(Zi),得到Masked-Muti-Headself-attention输出结果Om.
- Om进入Multi-Head Attention,这里就是普通的多头自注意层了,只是其计算的K和V来自encoder的输出信息,Q则是上一个带masked层的输出信息;最终仍然是Liner(softmax(Om)),得到最后的预测结果Oe
- 由于Mask的操作,最终的Oe,每行只预测一个单词,预测第I行则只包含I行前的信息,也就是第N个词,包含前面N-1个词的信息。

4)decoder训练过程补充说明
上述也说到,训练过程比较特殊,采用了teaching force,完成并行化,在进入decoder时候,样本是整个放进去的,首先Encoder端得到输入的encoding表示,并将其输入到Decoder端的第二层不带mask操作的交互层attention,之后在Decoder端接收其相应的输入(见1中有详细分析),经过多头self-attention模块之后,结合Encoder端的输出,再经FFN前馈层,得到Decoder端输出之后,最后经过mlp层就可以通过softmax来预测下一个单词(token),然后根据softmax的Loss反向传播。
你也可以这么理解 ,测试部分类似rnn,就是一个词一个词解出来 ,训练其实一样,完全也可以一个个作,但是作者仿照了encoder并行矩阵运算,但是不能让当前词语被输入的后面词语影响attention到,所以加入了mask。
三.总结—阅读理解,灵魂拷问:
以上transformer的原理重点阐述完毕。
阅读以上所述,您应该有以下理解
- Transformer 与 RNN 不同之处;并且可以并行训练,为什么使用transformer?
- 整体的结构和计算流程;比如模型的参数是否共享?
- 作为模型的输入词向量(NLP基础词嵌入),没有过多讲解,有兴趣可以再深入了解;
- Transformer 不能利用单词的顺序信息的,因此需要在输入中添加位置编码 ,为什么用它?
- transformer的残差结构,优化网络深度,缓和梯度问题。
- 为什么transformer使用BN效果不好?为什么使用LN?
- Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到,具体的计算过程?
- Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种空间维度上的相关系数attention score,还有训练时带来的好处是什么?多头机制是否参与推理呢?
- 编码器和解码器的结果区别,Masked的实际意义和具体操作的作用?训练和测试时候策略?
- 解码器的第二个交互层和编码器的输出关系是如何的?
灵魂10问!作为新时代CV模型系列的”前菜“!