ChatGPT之后我们要做什么?丨文本生成中的知识和控制
导读
ChatGPT出现后,语言理解与生成质量较之前有显著提升,但在知识性、逻辑性、可控性、可解释性方面仍然存在一些问题。如何让现有的聊天机器人拥有人类对话中丰富的先验知识?如何让生成的回复具有更强的交互性?针对这些问题,青源Talk第33期邀请到来自南京航空航天大学计算机科学与技术学院/人工智能学院的李丕绩教授,带来了题为“文本生成中的知识和控制”的主题分享。智源社区将活动要点整理如下。

李丕绩
南京航空航天大学计算机科学与技术学院/人工智能学院教授,博士生导师,2021年度南京航空航天大学"长空学者"获得者。香港中文大学博士,曾任腾讯AI Lab自然语言处理中心高级研究员。研究方向主要为自然语言处理,包括预训练模型、文本摘要、文本生成和对话系统。曾经在相关领域顶级会议如ACL、EMNLP、SIGIR等发表学术论文60余篇。多次受邀担任ACL、EMNLP、EACL、IJCAI等会议的领域主席。在工业界工作期间负责了多个语言理解、文本生成和智能对话相关重要项目的算法研发和产品发布,有丰富的科研落地实践经验。主持或参与多项国家自然科学基金、CCF-腾讯犀牛鸟基金等项目。
知识增强的对话生成
共情对话
人类聊天时有丰富的先验知识,能够快速捕捉上下文场景、语义、情感,理解并推理,最终完成对话。但是对一个模型来讲,是通过标注数据结合优化目标去训练,期望仅仅依靠有限的数据集就想达到超越数据集自身的对话效果,小模型非预训练时代是不可能完成的。在传统简单的聊天技术框架下,为了提升知识泛化、情感捕捉、知识和情感推理的能力,我们做了如下的研究工作。
在开展研究工作之前,我们先对公开数据集进行了统计分析,在一个情感对话的数据集上,统计了对话历史与回复中关键信息的重叠,我们发现重叠很少,这说明目前对话历史与回复中联系还是不够,映射比较稀疏。而后我们在对话历史与回复中加入一些额外的知识概念作为桥梁验证下是否将映射边简单。
常识知识与对话历史、回复有边相连,通过加入这个桥梁我们发现可以比较容易得做出对话历史到回复的映射。另外我们还做了多轮对话中情感转移的统计,以验证对话中的情感转移是否有固定的模式。我们基于上面两项统计,提出了Knowledge-aware Empathetic Dialogue Generation(KEMP)框架,来提升对话中知识与情感的能力。我们用到了ConcetNet外部知识库与NRC_VAD情感词典库。最终这个任务定义为:输入是多轮对话历史,ConceptNet与NRC_VAD,输出是知识合理并且共情的回复。我们将对话历史中的概念去ConceptNet中检索补充对话历史,对对话中的每个词我们都有一个情感向量与原来历史对话中的词向量叠加,构建出的情感上下文图输入到Transformer中。我们也设计了回复中情感预测的任务,保证回复中情感类别的正确性。
实验结果表明,引入外部知识与情感编码,使得生成的回复知识丰富,情感准确,多样性增强。模型结构如图1所示,技术细节参考我们AAAI2022的论文“Knowledge Bridging for Empathetic Dialogue Generation”(https://arxiv.org/abs/2009.09708)。ChatGPT发布后,这个任务的样本我们也在ChatGPT上面进行了测试,ChatGPT完成效果也很好。我们引入知识加入了各种技巧取得不错的效果,但是通用的ChatGPT模型同样具备这个能力,ChatGPT对于情感的理解、上下文的建模都很好。
 图1 KEMP模型
图1 KEMP模型
个性化对话
个性化对话是对话领域的一个子研究方向,也有一些经典数据集,其中PersonaChat数据样式是每一个人都有几句描述个性的信息,所以某一个人在回复时,基本都要围绕自身的个性内容。在做这个任务之初,我们也发现了对话历史与回复中间缺乏知识的桥梁,为了加强回复中个性化不足的问题,提出了Knowledge-aware Personalized Dialogue Generation框架,通过句子级、词语级的主题融合外部的知识来缩小回复与对话历史、个性化描述的差距,进一步提升了回复的质量。模型如图2所示。我们最终也可以得出这样的结论,如果你的任务缺乏知识,你可以设计策略给他加入额外知识,并设计策略避免引入额外噪音,该任务结果往往会有所提升。
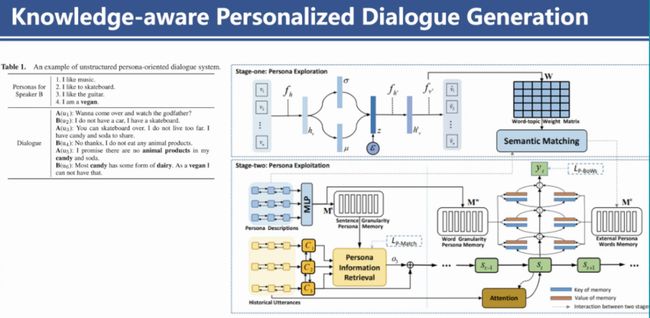 图2 Knowledge-aware Personalized Dialogue Generation模型
图2 Knowledge-aware Personalized Dialogue Generation模型
在做实验过程中,通过分析各个模型生成的结果,我们发现聊天机器人容易变的很自我,生成的聊天内容总是围绕个性化描述展开,可能问题并没有问到,但是回复中总是包含某一些个性化内容或者急切的想生成符号个性描述的内容,这也是因为训练机制和优化目标导致的。
为了缓解个性化聊天机器人比较自我的问题,使得生成的回复比较自然且更具有交互性。我们建模时提出了平衡答与问、说与听的策略,以便更好的进行个性化回复生成。答与问指的是回复的时候不仅仅是直接的回答对方的问题,而且还要有主动提问的行文,这样就有更多轮自然的交互。说与听目的是聊天过程中找到对话双方更多的共同兴趣,围绕这个兴趣看是否可以多轮聊下去,共同的兴趣引入了对话双方的个性,类似于引入了新的个性节点。为了达到这个目标,我们基于强化学习设计了建模策略,引入了两个对话智能体。
回想早期的对话或者文本生成领域,使用LSTM等模型打底去做强化学习训练时,实验常常会有训练失败的情况,模型很快就会距离目标越来越远,模型比较薄比较脆弱。所以我们设计模型是GPT-2的量级,要使用对话语料预训练这个模型,然后复制成两个智能体,使得两个对话智能体一问一答,交互对话,构建了强化学习的环境。
关于强化学习中奖励函数的设计,在平衡问与答方面,第一个是Mutual Benefit Reward,这个奖励函数由两部分组成,其中一点是想要生成回复中的概念尽可能多的包含双方的个性,另一点为了增强对话的连贯性,使得对话不仅仅只是关注于最近的一轮,也关注之前的轮次。第二点是为了缓解稀疏性问题,引入了外部知识库来补充知识的稀疏。
在平衡说与听方面,为了找到对话双方共同的兴趣,一是设计了复制机制,将设计好的概念复制到回复中,二是设计了奖励机制,使得未来多轮的对话能够围绕对话双方的兴趣共同点来展开,也就是生成的词要离各自对话双方的个性信息与历史信息要尽可能的近,且不完全一致。
这个强化学习模型设计思路简洁,但是在实验中比较难训练,即便现在是GPT-2级别,我们发现模型越大越稳定,在经典数据集上实验后证明我们的方法是有效的,技术细节参考我们的SIGIR2022论文“COSPLAY: Concept Set Guided Personalized Dialogue Generation Across Both Party Personas”(https://arxiv.org/abs/2205.00872)。我们后来也测试了ChatGPT的效果,整体结果比较好,但是回复比较长。
如今,个性化对话类的智能产品有Character AI、聆心智能、Glow APP等,可能是通过上下文提示学习来创建个性化的角色,围绕特定的角色与人类进行多轮对话。
此外,在文本生成领域还存在一个挑战,就是长文本的连贯性。以我们在做的故事生成举例,具体研究的步骤是:
(1)给定故事的上下文,利用一个模型抽取核心事件信息;
(2)基于已有训练集,训练一个预测事件线的模型;
(3)推理的时候根据上下文预测后续事件线,丰富最终生成的故事内容。
我们设计的模型是一个两阶段的模型,如图3所示。第一个阶段基于GPT-2训练了事件线预测器,第二阶段根据已有故事预测接下来的事件线,最后解码生成每个事件线的故事内容。在训练基于事件的GPT-2时,使用了Prefix-tuning方式,没有直接扰动原有GPT-2的参数,直接扰动参数会影响效果,通过引入连续的prompt,只更改prompt的参数,使得模型原本的文本生成能力保持同时又具备了事件线序列预测的能力。
此外,我们引入了注意力机制关注到底哪些事件更重要,自动取舍事件。在对话与故事生成的数据集上结果表明,事件预测与推理能力较好,生成的事件符合预期,论文“Event Transition Planning for Open-ended Text Generation”(https://arxiv.org/abs/2204.09453)以Findings形式发表在ACL2022中。最近我们也测试了ChatGPT的故事结尾预测任务,我们发现写的很长,很丰富,很详细。
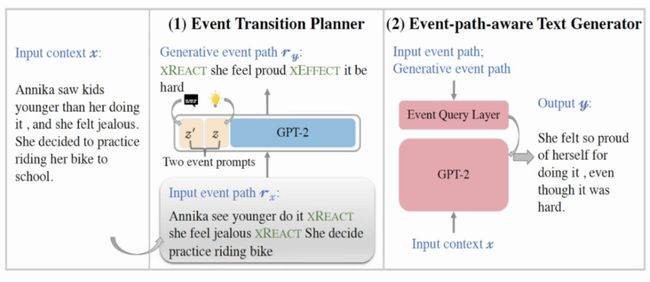 图3 两阶段模型
图3 两阶段模型
对于提升长文本生成语义连贯性的问题,传统的文本生成都是在token级训练一个自回归的语言模型,句子层面就会存在逻辑性、前后不一致等问题。考虑到现在大语料比较好获得,而且句子表示学习的效果也在不断提升,我们就尝试了从句子级别构建预训练模型,我们将一个个句子编码成向量,然后去解码恢复成句子向量,最终解码成词语级别。Sentence Semantic Regression for Text Generation模型结构如图4所示。
不过目前我们没有很好的解决如何将句子向量还原成高质量的句子这个问题。实验结果表明,生成的句子主题稳定,说明句子层次建模能保持长程语义连贯性。但是这个问题似乎在ChatGPT面前也不是问题。
 图4 Sentence Semantic Regression for Text Generation模型
图4 Sentence Semantic Regression for Text Generation模型
符号控制的文本生成
这方面一个工作是在腾讯工作期间做的,模型名字叫SongNet,模型结构如图5所示,任务实际背景是曲子不变的情况下改歌词,这样解决的是一个严格约束的文本生成问题。模型的输入是一个模板,输出是预测生成的文本。在GPT-2这种自回归的生成模型框架下,引入不同的符号控制格式、字数、押韵等,并且设计了全局多头注意力。实验表明,模型面对任意的固定模式的模板,都能生成很好的效果。在保留部分内容补全句子的任务上,效果也不错。
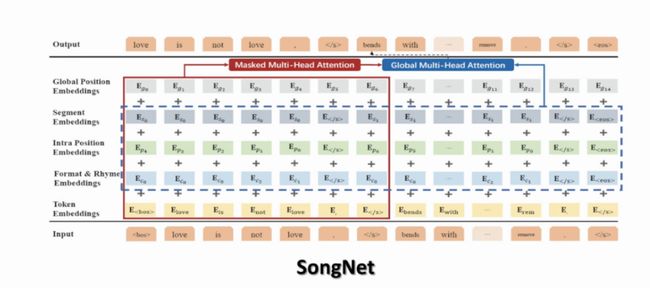 图5 SongNet模型
图5 SongNet模型
ChatGPT之后,做什么?
Neuro-Symbolic Reasoning:ChatGPT出现后,语言理解与生成质量较之前提升明显,但知识性、逻辑性、可控性、可解释性方面还存在一些问题,也是一些推理问题。大语言模型推理能力增强的解决办法,目前已有工作(以下用简称指代):chain-of-thought、self-consistency、least-to-most、self-improve等。ChatGPT模型下,如何把事实性知识或者谓词逻辑关系融入自回归的大语言模型中是值得思考的,ChatGPT中的RLHF规避差样本显然不是解决办法。甚至有时我们人类也不能分辨机器生成文本的正确与否。
Q&A
1、ChatGPT与GPT-4对文本生成或者自然语言处理领域的格局会有哪些影响?
答:我们猜测ChatGPT与GPT-4对大家带来的感受差距可能不会太大,但也说不定。ChatGPT目前已经出圈,对各行业文字工作者会有些影响,比如做广告文案的人员确实能收到比较好的结果,ChatGPT甚至会淘汰一些岗位,目前ChatGPT又接入到搜索引擎中,肯定还是会带来较大变化。ChatGPT或者GPT-4最终可能会被封装成API,提供各种服务,帮助我们收集信息,整理素材。
2、通用大模型与个性化对话模型的区别?
答:通用大模型比如ChatGPT是多任务的,通过设计一些指令可以诱使它变成个性化的模型,个性化对话模型仅仅是某一特性的个性化模型,根据属性的设定去完成特定类型的任务。个性化的模型也有基于大模型改进成专用的。
3、如何区分文本与代码是不是ChatGPT写的?
答:ChatGPT现有生成内容是没有水印等标注加以区分的,有些时候判别难度还是很大的。ChatGPT生成时可能有一部分内容是背出来的,它的多样性在某些场景中有限,也有固定风格,可以从生成的多个样本中去大致观测多样性,如果多样性较差,那么可能就是ChatGPT写的。
4、文本生成整体质量与多样性如何平衡?
答:我觉得在大模型前提下,整体质量已经很高了。要在文本生成质量高的前提下保证多样性,可以根据采样算法调整,采样算法重排的标准可以用奖励函数打分去判定,按照实际需求排序后,多样性能增加。
5、问答任务的前景如何?
答:这个要看看模型的缺点,找到这些大模型没有解决的问题或者解决不好的地方再去改进。比如KBQA问题,测试下ChatGPT模型有哪些问题没有解决好,是否还有专门解决的必要,有必要的话再去研究如何解决。
6、您对人工智能领域有哪些期待与设想?
答:ChatGPT是否最后能做成脑机接口,接入大脑,这样我们每个人大脑就富含有大量的知识,与我们人类交互,我们人类自己产生的内容也可以去更新ChatGPT的中心节点。ChatGPT在构建或者融入元宇宙中是否能起到作用,构建虚拟的场景、环境等。

更多内容 尽在智源社区