Serverless 架构模式及演进
简介: Serverless 架构从使用技术上有计算,数据存储,消息通信,我们可从运维性,安全性,可靠性,可扩展性,成本几个角度来衡量架构的优劣。本文会介绍一些常见的业务场景,探讨如何使用 Serverless 架构来支持这些场景。
Serverless 架构
按照 CNCF 对 Serverless 计算的定义,Serverless 架构应该是采用 FaaS(函数即服务)和 BaaS(后端服务)服务来解决问题的一种设计,这个定义让我们对 Serverless 的理解稍微清楚了一些,但是可能也造成了一些争论。

1. 随着需求和技术的发展,业界出现了一些 FaaS 以外的其它形态的 Serverless 计算服务,比如 Google CloudRun,阿里云推出了面向应用的 Serverless 应用引擎服务,这些服务也提供了弹性伸缩能力和按使用计费的收费模式,具备 Serverless 服务的形态,可以说进一步扩大了 Serverless 计算的阵营。
2. 为了解决冷启动影响,FaaS 类如阿里云的函数计算和 AWS 的 Lambda 也相继推出了预留功能。
3. 另外一些基于服务器(Serverful)的后端服务也推出了 Serverless 形态产品,比如 AWS Serverless Aurora,阿里云 Serverless HBase 服务。
因此,Serverless 的界线是有些模糊,但是云服务是在 Serverless 方向上不断演进的。一个模糊的东西如何指导我们解决业务问题呢?Serverless 有一个最根本的理念是:让用户最大化的专注业务逻辑。其它的特征如不关心服务器,自动弹性,按使用计费等等都是为了实现这个理念而服务。Serverless 的理念可以让我们更好地用有限的资源解决真正需要解决的问题,正是因为我们少做了一些事情,转而让别人做这些事情,我们才可以在业务上做的更多。
著名的 Serverless 实践者 Ben Kehoe 这样描述 Serverless 原生心智:
1. 我的业务是什么?
2. 做这件事情能不能让我的业务出类拔萃?
3. 如果不能,我为什么要做这件事情而不是让别人来解决这个问题?
4. 在解决业务问题之前没有必要解决技术问题。
在实践 Serverless 架构时,最重要的心智不是选择哪些流行服务和技术,攻克哪些技术难题,而是时刻铭记在心专注业务逻辑,这样更容易让我们选择合适的技术和服务,明确如何设计应用架构。

Serverless 架构从使用技术上有计算,数据存储,消息通信,我们可从运维性,安全性,可靠性,可扩展性,成本几个角度来衡量架构的优劣。本文会介绍一些常见的业务场景,探讨如何使用 Serverless 架构来支持这些场景。为了让这种讨论不过于抽象,下面会介绍一些具体的技术实现作为参考,但是这些架构的思想是通用的,可以用其它类似产品实现。
静态站点

静态站点的业务需求是比较简单的,它相当于一个信息展示的站点。比如早期网站都是静态展示,如图是1997年的中国黄页,它其实就是一个单层的页面。其特征可以分为三点:
1、它的页面是偏静态的展示信息。
2、其页面更新并不频繁。
3、不确定访问量。
架构的演进
图中所展示出的由云下到云上,由管理服务器到无需管理服务器(即 Serverless)的转变给开发者带来了巨大的受益。如前两种方案需要预算,扩展,实现高可用,自行监控等,而当年中国黄页开发者的业务逻辑只是想单纯的展示信息,让世界了解中国。 正好与 Serverless 原生心智相吻合,即让开发者最大化的去专注业务逻辑。
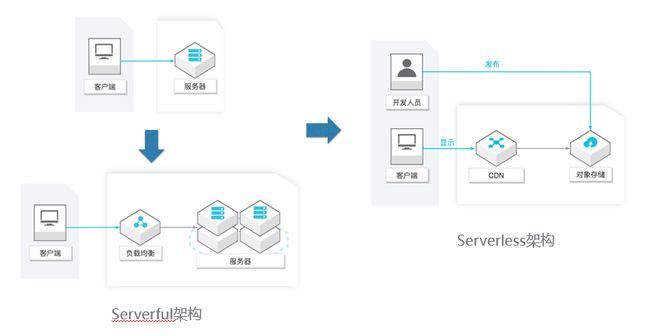
- 买台服务器放在 IDC 机房里托管,运行站点。
- 为了解决高可用的问题又买了负载均衡服务和多个服务器。
- 采用静态站点方式,站长直接将站点由对象存储服务(如 OSS)支持,并使用 CDN 做缓存。
传统架构模式下开发网站,会把网站部署在服务器上,随后再把这个服务器托管到机房,然后用户或者客户端用电脑浏览器去访问这个网站。它所存在弊端就是:如果这个网站出现问题,服务器不再可用,为了维护这个网站的高可用性,会再挂一个负载均衡和两个储备服务器,这就是 Serverful 服务的架构。Serverless架构对于开发人员来说,它只需要把它的静态页面直接发布到对象存储,而对象存储本身就是一个serverless的文件存储服务,它可以存储静态页页面、图片、音频、视频等等,并且做到无限扩展。
Serverless 架构有着其它方案无法比拟的优势:
- 无需管理服务器,比如操作系统的安全补丁升级,故障升级,高可用性,这些云服务(OSS,CDN)都帮着做了。
- 无需对资源做预估和考虑未来的扩展,因为 OSS 本身是弹性的,使用 CDN 使得系统延迟更小,费用更低,可用性更高。
- 按实际使用的资源付费,包括存储费用和请求费用,没有请求时不收取请求费用。
- 安全性:这样一个系统甚至看不到服务器,不需要通过SSH登录,DDOS 攻击也交给云服务来解决。

静态是个好东西,缓存也是软件开发经常用到的技术,虽然有句玩笑是说计算机技术只有两个最难的事情,让缓存失效和命名。但是这也体现了缓存的重要性,只要运用得当,能大大提升系统的性能。
比如说目前很多安卓应用,要发布到如小米应用商店、华为应用商店等各种渠道商,开发者更希望的是打包好一个母包,放在对象存储里,而不是反复做打渠道包维护等重复工作。对用户来说,只需要维护一个母包,然后再维护一个简单的动态计算即可。其实 CDN 不只可以回源到对象存储,还可以回源到动态后端,如 API 网关,函数计算,负载均衡器等,也不止有 CDN 可以这种类型的缓存,还可以使用 Redis,以及进程内的缓存。
单体和微服务
为何会有单体和微服务,因为静态站点的话,它可能只是解决一些展示信息的需求,但是随着业务需求复杂程度增加,就需要动态站点了。比如:
- 淘宝的商品页面,采用静态页面方式管理商品信息是不现实的。商品数量众多,商品上架下架信息更新频繁,商品页面复杂。
- 网易、新浪门户网站, 实时新闻不断更新,评论、点赞, 转发等
静态页面和站点适合用于内容少更新频率低的场景,反之,比如像图中淘宝的一个商品详情页,使用静态站点的页面是不太现实的,原因有下:
1、商品是海量的。
2、更新频繁
3、动态信息来源广泛,如基本信息、价格、运费、销量、库存、评论等是实时变化的。
上面提到的 Serverless 原生心智有助于我们专注业务。比如:
- 是否需要自己购置服务器安装数据库,实现高可用,管理备份,升级版本等,还是可以把这些事情交给托管的服务如 RDS;是否可以使用表格存储,Serverless HBase 等 Serverless 数据库服务,实现按使用的弹性扩容缩容和付费。
- 单体应用是需要自己购置服务器运行,还是可以交给托管服务,如函数计算和Serverless 应用引擎。
- 是否可以通过函数来实现轻量级微服务,依赖函数计算提供的负载均衡、自动伸缩、按需付费、系统监控等能力。
- 基于 Spring Cloud、Dubbo、HSF 等实现的微服务应用是否需要自己购置服务器部署应用,管理服务发现,负载均衡,弹性伸缩,熔断,系统监控等,还是可以将这些工作交给诸如 Serverless 应用引擎服务。
关于架构的演进,经历了 Serverful 单体架构到 Serverful 微服务架构再到 Serverless 微服务架构过程。随着业务的发展,组织规模的不断增大,这时候一般就需要将单体应用中的逻辑拆分成多个执行单元,比如商品页面上的评论信息,售卖信息,配送信息等都可以对应一个单独的微服务;而右图的架构引入了API网关、函数计算或SAE来实现计算层,将大量工作交换云服务完成。Serverless 这种微服务架构的好处是每个单元都能高度自治,单元之间松耦合,易于开发(比如使用不同技术)、部署和扩展。
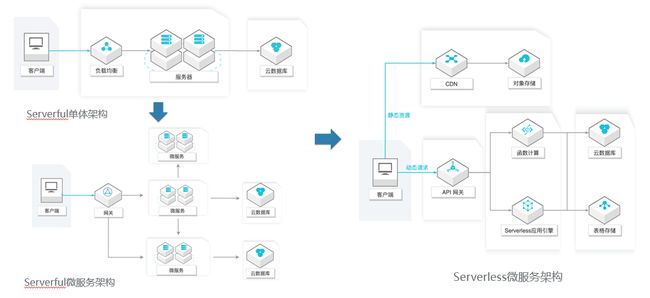
但是这种架构也引入了分布式系统的一些问题,如服务间通信的负载均衡,失败处理,分布式事务等。处在不同阶段不同规模的组织可以选择适合的方式,能解决它面临的首要的业务问题。
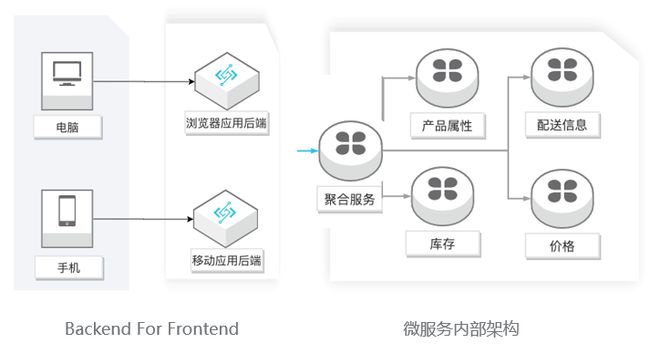
其实这里的商品页面虽然信息繁多,但是相对来说依旧比较简单,主要是因为这里只是涉及到了读操作。这种图显示了系统内部多个微服务的交互。通过提供一个商品聚合服务,将内部的多个微服务统一的呈现给外部。这里的微服务可以通过SAE或者函数实现。
另一个延伸是,我们开始的业务需求没有提到需要支持不同客户端的访问,现实中这种需求是常见的,不同的客户端需要的信息可能是不同的。比如手机可以根据位置信息做相关推荐。如何让手机客户端和不同浏览器都能受益于 Serverless 架构呢?
这又牵扯出了另一个词,BFF,backend for fronted,即为前端定做的后端,这受到了前端开发工程师的推崇,Serverless 技术让这个架构广泛流行,因为前端工程师可以从业务角度出发直接编写 BFF,而无需管理服务器相关的让前端工程师更加头疼的事情。
事件触发
本节通过介绍一个具体的业务场景:对于事件触发类的场景,阐述 Serverless 架构是怎样解决问题的。前面提到的动态页面生成是同步请求完成的,还有一类常见场景,其中请求处理通常需要较长时间或者较多资源,比如用户评论中的图片和视频内容管理,涉及到如何上传图片和处理图片(缩略图,水印,审核等),视频处理以适应不同客户端播放需求等。比如该图中业务场景是一个买家秀,当买家完成了交易,想要发表图片或者视频的评论,买家完成后,后端的服务要对这个图片加水印,然后缩放并且审核;视频也需要做多种格式的转换和审核,因为要适配各种不同的终端。

这种业务特征实际上是非常耗 CPU 的,每次任务执行的时间一般比较长,因此针对于这种业务,我们可能会有一些技术架构的演进。
比如大家所熟悉的抖音,就是用户上传视频的业务场景。在抖音后端也是需要对视频进行统一处理的:如加水印,转码成各种不同的码率或者是长宽分辨率去配适不同的手机。这个业务落户是十分消耗 CPU 计算资源的。同时带宽的压力也很大。这个时候你只能不停地加带宽,加机器,其结果就是运维和维护成本不断增加;第二个问题就是会存在波峰波谷,比如说早上8点钟的地铁时间和中午吃饭的1钟或者晚上8点钟的时候,业务量可能是非常高的,如果你的业务需要1000台机器,但是到了凌晨,这1000台机器可能就用不上,因此便会造成资源的一些浪费,同时你还要处理运维监控,扩弹性,扩缩容等工作。

将架构演进再延伸一下,事件触发能力是 FaaS 非常重要的特性,这种 Pub-Sub 事件驱动模式不是一个新的概念,但是在 Serverless 流行之前,事件的生产者,消费者,以及中间的连接枢纽都是用户负责的,就像前面架构演进中的第二个架构。Serverless 让生产者发送事件,维护连接枢纽都从用户职责中省略了,而只需关注消费者的逻辑,这是 Serverless 的价值。函数计算服务还集成其它云服务事件源,让你更方便的在业务中使用一些常见的模式,如 Pub/Sub,事件流模式,Event Sourcing 模式。
服务编排
前面的商品页面虽然复杂,但是所有的操作都是读操作,聚合服务 API 是无状态、同步的。我们来看一下电商中的一个核心场景——订单流程。
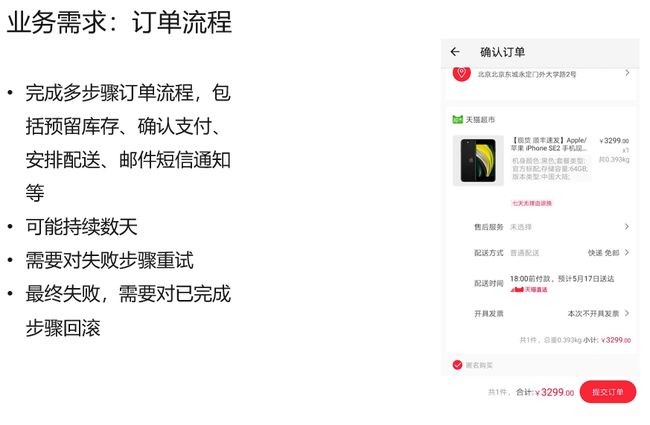
比如说用户在淘宝里面进行了购物,或者说在饿了么下单了外卖,它都是涉及到一个订单的流程。这种订单流程是比商品展示更为复杂的。因为在订单流程里面,它所要保留更多的事情。比如有用户下单时,我们第一步要检查库存,库存储量够的话,然后库存减1 ,随后接通支微信或者说支付宝的服务去支付扣款,单子下来了以后,还要安排物流去配送,同时还要查看物流的详情并进行短信通知等等。

同时在这些代码逻辑中你要写各种重试逻辑。如果说最终失败的话,我们便要对已完成的事情进行回滚,如若用户取消订单,那么需要回滚的则更多。比如说这个钱要退还给用户,这个场景是是非常复杂的,我们可以看一下这个流程怎么发起来的。比如说第一步用户下单之后,其实是走到了这个订单服务,这个订单服务会生成订单号;然后会涉及到买家是谁,卖家是谁。第二步我们会把消息发送到消息总线,其他的这些服务(配送服务、库存服务、支付服务)是订阅到消息总线的。
另一方面它的可观测性、可描述性并不好,其次在编排上,它的复用性很差。如若说开发者改成了另外一个流程的服务,那么这一套就要重新改写了。
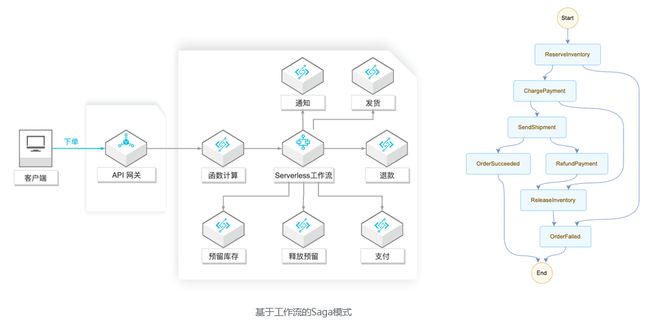
在这个 Serverless 架构里,各个服务直接是独立的,也不通过事件传递信息,而是有一个集中的协调者服务来调度单个业务服务,业务逻辑和状态由集中协调者维护。从网关层下单后,触发函数计算的一次函数执行,函数执行的逻辑会触发一个工作流的执行。就比如说右边这张图其实就是用户自己去编写的,这个流程,就是工作流。
比如说第一步下单,第二步付钱,付钱成功了会如何,付钱失败了应该怎样。整个订单就相当于是右侧流程的执行。而每次流程的执行都是可以被追溯的。你可以理解成他就是个组织者,然后调用其他的云服务。
所以在这个架构,我们可以看出对开发者而言,不需要去做消息总线,从事逻辑的处理,维护数据的一致性等到。他只需要专注他的业务逻辑,把每个流程调用的服务写好,把这些编排的流程写好就可以了。
- 编写大量代码来实现编排逻辑、状态维护和错误重试等功能,而这些实现又很难被其它应用重用。
- 维护运行编排应用的基础设施,以确保编排应用的高可用性和可伸缩性。
- 考虑状态持久性,以支持多步骤长时间运行流程并确保流程的事务性。
如果直接依赖于云上的服务,比如阿里云的 Serverless 工作流服务,这些事情都可以交给平台来做。用户又回到了只需关注业务逻辑的状态。右图是流程定义,我们可以看到这实现了前面基于事件的 Saga 模式的效果,并且流程的复杂度大大简化。
Serverless 技术毫无疑问将会承担更多的责任,让用户更快更好的构建应用。使用 Serverless 架构可以覆盖很多场景,这里只是介绍了 Web 网站前端后端,微服务,事件触发,服务编排等几个场景的架构。Less is more 把事情交给可靠的平台(比如云厂商)去做,让开发者可以更加聚焦自身的核心业务价值,是 Serverless 所一直推崇的理念。
原文链接
本文为阿里云原创内容,未经允许不得转载。