Hadoop-HDFS基础知识
Hadoop-HDFS
- HDFS 概述
-
- 1. 背景 定义
- 2. 优缺点
- 3. 组织架构
- 4. HDFS文件块的大小(重点)
- NN和2NN工作机制
-
- 1. Fsimage 和 Edits 解析
- 2. ChickPoint时间设置
- 3. NameNode 故障处理
- 4. 集群的安全模式
- 5. NameNode 多目录
- DataNode
-
- 1. DataNode 的工作机制(重点)
- 2. 数据完整性
- 3. 超时时限设置
- 4. 服役新节点
- 5. 退役旧数据节点
-
- 添加白名单
- 黑名单退役
- 6. DataNode 多目录设置
- Hadoop 2.x 新特性
-
- 1. 集群间数据拷贝
- 2. 小文件归档
- 3. 回收站
- 4. 快照拷贝
- HDFS读写过程(重点)
-
- 1. 读过程
- 2. 网络拓扑—节点距离计算
- 3. HDFS读过程
边学边写,持续更新中
配合目录用
HDFS 概述
1. 背景 定义
解决:管理多台机器上的文件系统。分布式文件管理系统
HDFS是其中的一种
定义:HDFS(Hadoop Distributed File System),文件系统,分布式
适用场景:适合一次写入、多次读出的场景,且不支持文件的修改。适合用于数据分析,不合适作为网盘。
2. 优缺点
-
优点
高容错性:自动保存多副本,且副本可增加
适合处理大数据:数据规模和文件规模巨大
可以构建在廉价机器上,通过多副本机制,提高可靠性 -
缺点
不适合低延时数据访问,比如毫秒级的存储数据,是做不到的
无法高效的对大量小文件进行存储:会占用大量内存存目录和块信息。无论文件多大,在NameNode里都会占用一定内存
不支持并发写入、文件随机修改:仅支持数据追加
3. 组织架构
- NameNode
master,是一个主管、管理者
- 管理HDFS的名称空间
- 配置副本策略;
- 管理数据块(Block)映射信息;
- 处理客户端读写请求。
- DataNode
slave。NameNode下达命令,DataNode执行命令
- 存储实际的数据块;
- 行数据块的读/写操作
- Client:客户端
- 文件切片。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
- 与NameNode交互,获取文件的位置信息;
- 与DataNode交互,读取或写入数据
- Client提供一些命令来管理HDFS,比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
- SecondaryNameNode
并非NameNode的热备。当NameNode挂掉时,它不会马上替换NameNode并提供服务。
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
- 紧急情况下,可以辅助恢复NameNode
4. HDFS文件块的大小(重点)
块的大小可以通过参数 dfs.blocksize 设置
在Hadoop2.X版本中,默认大小是128MB,老版本是64MB,本地运行是32MB
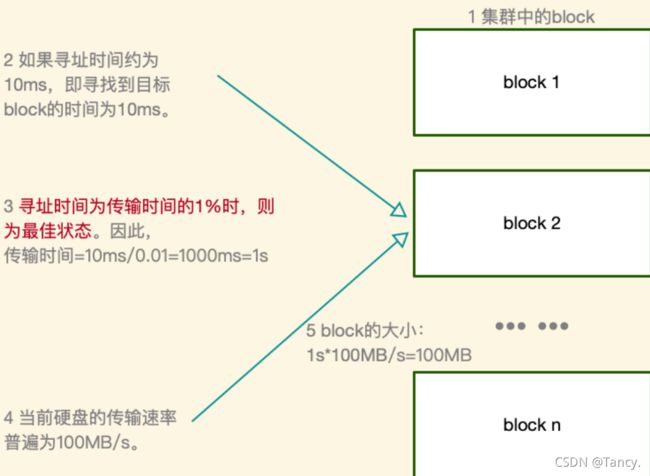
为什么块的大小不能设置太小,也不能设置太大?
- 设置太小,会增加寻找时间
- 设置太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需要的时间。导致程序在处理这块时间会非常慢。
HDFS块的大小设置主要取决于磁盘传输速率
NN和2NN工作机制
理解概念
磁盘 内存
元数据放到内存中(为了访问快),磁盘中也要备份元数据(防止丢失),引入 fsimage
引入edits ,只进行追加(append)操作。保证元数据的更新
先写硬盘 再写内存 保证数据 用追加的方式
合并 fsimage 和 edits,引入 SecondaryNameNode
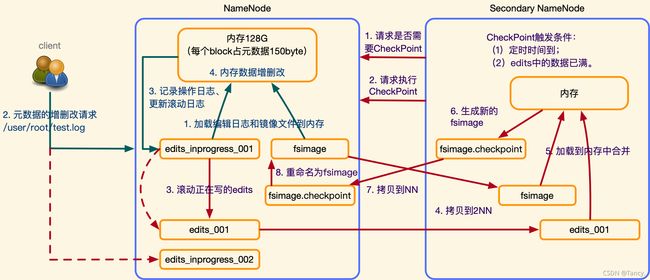
- NN过程
- 加载编辑日志和镜像文件到内存
- 元数据的增删改请求
- 记录操作日志,更新滚动日志
- 内存数据增删改
- 2NN过程
- 请求是否需要CheckPoint
CheckPoint的触发条件
a. 定时时间到
b. edits 中的数据已满
都可以手动设置 - 请求执行 ChecnPoint
- 滚动正在写的edits(重命名,保证用户能继续写)
- 拷贝到2NN
- 加载到内存中合并
- 生成新的fsimage
- 拷贝到NN
- 重命名为fsimage
2NN的作用:帮助NN对 edits 和 fsimage 进行合并
1. Fsimage 和 Edits 解析
查看 fsimage
命令:
hdfs oiv
参数:
-p: 选择文件的处理器
-i: 输入的文件
-o: 输出的文件
例如:bin/hdfs oiv -p XML -i fsimage_xxx -o fsimage.xml
查看 edits
命令:
hdfs oev
参数:
-p: 选择文件的处理器
-i: 输入的文件
-o: 输出的文件
例如:bin/hdfs oev -p XML -i edits_xxx -o edits.xml
可以格式化后重启集群,跑一个案例
2. ChickPoint时间设置
在 hdfs-default.xml 中修改
-
触发条件1:每隔一段时间
通常情况下,2NN是每隔一个小时执行一次,3600秒
,默认值是3600 -
edits已满
每隔1分钟检查一次
默认值是操作数达到一百万,2NN执行一次
3. NameNode 故障处理
- 方法1:将2NN的数据拷贝到NN存储数据的目录
- 杀死NN进程
- 删除NN数据(name)
- 拷贝
- 重启
代码
1. kill -9 进程号
## 用jps 看进程号
2. rm -rf /$HADOOP_HOME/data/tmp/dfs/name
3. scp -r root@hadoop3:/opt/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./
## 这里的目录和虚拟机名字不唯一,根据自己的来
4. /sbin/hadoop-daemon.sh start namenode
- 方法2:守护进程
用-importCheckpoint选项启动 NN 的守护进程,从而完成拷贝
- 缩短CheckPoint的时间,更快见效
kill -9 NameNode PID- 删NN的数据
- 如果2NN和 NN 不在一个节点上,将2NN的数据拷贝到NN的平级路径,并删除
in_use.lock文件(平级路径是方法一中的路径) - 导入检查点数据,执行一会手动结束
./bin/hdfs namenode -inportCheckpoint
4. 集群的安全模式
在安全模式中,只读不可写
集群启动完成后,会自动退出安全模式
在如图所示期间,NameNode处于安全模式

安全模式退出条件
满足最小副本条件 99.9%的块满足最小副本级别(默认值是1)
刚格式化的集群没有任何块,所以NN不会进入安全模式
基本语法
- 查看状态
bin/hdfs dfsadmin -safemode get - 进入
bin/hdfs dfsadmin -safemode get enter - 离开
bin/hdfs dfsadmin -safemode get leave - 等待
bin/hdfs dfsadmin -safemode get wait
5. NameNode 多目录
增加数据可靠性,相当于在本地建了一个2NN
HA后会讲,ZooKeper会讲
在 hdfs-site.xml 文件中增加以下代码
<property>
<name>dfs.namenode.name.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2value>
property>
然后停止集群,删除每个集群的data 和 Logs 中所有文件
格式化集群并启动
DataNode
1. DataNode 的工作机制(重点)
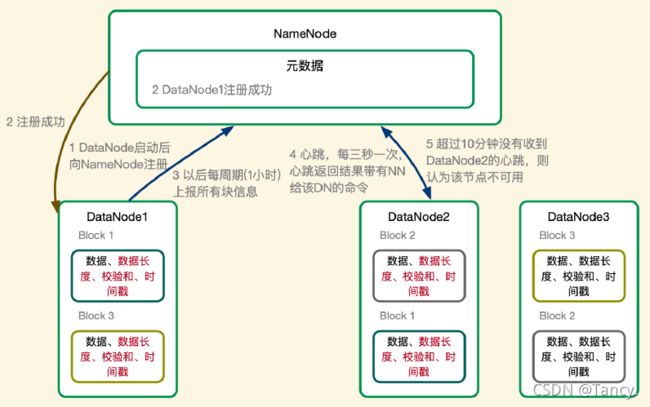
- DataNode 启动后,向NameNode 注册
- 注册成功,NN元数据中写入DN注册成功
- DataNode ==每周期(1小时)==上报所有块消息
- 心跳,每三秒一次,心跳返回带有NN给DN的命令
- 超过10分钟没有收到DN的心跳,则认为该节点不可用,不会再发任何信息
2. 数据完整性
奇偶校验
CRC校验
有 md5sum 校验
sha256sum 校验 更复杂
3. 超时时限设置
一般时间为 10分钟 + 30秒
计算公式
Timeout= 2 * dfs.namenode.heartbeat.recheck-interval + 10*dfs.heart beat.interval
默认的Timeout= 2 * dfs.namenode.heartbeat.recheck-interval 是5分钟
dfs.heart beat.interval默认是3s
可以去 dfs.namenode.heartbeat 文件里更矮
注意心跳的单位是毫秒
4. 服役新节点
解决数据存储容量不足问题
- 新建虚拟机,修改主机名,IP,安装前面的配置要求配置
- 安装 jdk 和 Hadoop,可以用scp分发,注意要删除data和logs,在host中加入该节点 IP
- 启动DataNode
- 启动NodeManager
5. 退役旧数据节点
限制节点加入的方法
添加白名单
添加到白名单的节点,允许访问NameNode
不在白名单的节点,都会被退出
- 在NameNode的$HADOOP_HOME/etc/hadoop路径下创建dfs.hosts⽂件,添加如下已有的主机名
- .在NameNode的hdfs-site.xml配置⽂件中增加dfs.hosts属性:
<property>
<name>dfs.hostsname>
<value>/opt/hadoop-2.7.2/etc/hadoop/dfs.hostsvalue>
property>
- 配置文件分发
xsync hdfs-site.xml - 刷新NameNode
hdfs dfsadmin -refreshNodes - 更新ResourceManager节点
yarn rmadmin -refreshNodes
如果数据不平衡,用该命令实现集群再平衡
sbin/start-balancr.sh
黑名单退役
黑名单上的主机会被强制退出
- 在NameNode的$HADOOP_HOME/etc/hadoop路径下创建dfs.hosts.exclude⽂件,添加主机名称(要退役的节点):
- 在NameNode的hdfs-site.xml配置⽂件中增加
<property>
<name>dfs.hosts.excludename>
<value>/opt/hadoop-2.7.2/etc/hadoop/dfs.hosts.excludevalue>
property>
- 刷新NameNode、ResourceManager:
hdfs dfsadmin -refeshNodes
hdfs dfsadmin -refeshNodes - 查看HDFS的Web UI,退役节点的状态为decommission in progress(退役中);
- 在hadoop5(退役的节点上)上退出DataNode和NodeManager;
- 数据平衡.
注意:不允许⽩名单和⿊名单同时出现同⼀个主机名称.
6. DataNode 多目录设置
每个目录存储的数据不一样,即:数据不是副本
注意和 NamaNode 区别开
- 停止所有组件
- 删除 data 和 logs 文件夹
- 修改配置文件并分发
在 hdfs-site.xml 中,增加以下代码
<property>
<name>dfs.datanode.data.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2value>
property>
- 格式化NameNode;
- 重启集群
Hadoop 2.x 新特性
1. 集群间数据拷贝
-
服务器之间
用scp命令 实现 推 拉 本地主机中转实现两个远程主机文件复制 -
集群间
用distcp 命令实现两个Hadoop集群之间的递归数据复制
例如
bin/hadoop distcp hdfs://hadoop1:9000/user/root/hello.txt hdfs://hadoop2:9000/user/root/hello.txt
2. 小文件归档
因为每个文件都是按块存储
大量的小文件会耗尽NameNode中大部分内存
存储小文件需要的磁盘容量和数据快大小无关
例如:1MB的文件设置128MB的块存储,实际用的是1MB磁盘空间而不是128MB
解决方法之一:HDFS存档文件或HAR文件
它将文件存入HDFS块,减少NameNode内存使用的同时,允许对文件进行透明的访问
具体就说:存档的文件对内是一个个独立的文件,对NameNode是一个整体,从而减少了NameNode的内存
步骤
- 启动YARN进程
sbin/start-yarn.sh - 归档文件
例如:将/usr/root/input⽬录下的数据归档成名为input.har的归档⽂件,并把归档后的⽂件存储到/usr/root/output路径下
bin/hadoop archive -archiveName input.har -p /user/root/input /user/root/output - 查看归档
hadoop fs -ls -R har:///user/root/output/input.har
注意,对har文件的操作,要加上har:// - 解归档文件
就是复制出来
hadoop fs -cp har:///user/root/output/input.har/* /usr/root
3. 回收站
如题,在不超时的的情况下可以恢复数据
防止误删,可备份
默认关闭
大数据只考虑存储
说明
- 默认值fs.trash.interval=0
0 表⽰禁⽤回收站; 其它值表⽰设置⽂件的存活时间 - 默认值fs.trash.checkpoint.interval=0
检查回收站的间隔时间. 如果该值为0,则该值设置与fs.trash.interval的参数值相等. - 要求fs.trash.checkpoint.interval <=fs.trash.interval.
步骤
- 启动回收站 在
core-site.xml中增加以下代码
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
- 修改访问回收站⽤户的名称,默认是dr.who,修改为root⽤户
在core-site.xml中增加以下代码
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 任意删一个,去
/user/root/.Trash/中看 - 恢复回收站数据
hadoop fs -mv /user/root/.Trash/Current/user/ root/input /user/root/input - 清空回收站
hadoop fs -expunge
注意:通过API程序删除的⽂件不会经过回收站,需要调⽤moveToTrash()才会进⼊回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
4. 快照拷贝
相当于对目录做一个备份
不会立即复制所有文件,而是指向同一个文件
当写入发生时,才会产生新文件
记录的是一个差异,根据差异恢复
实际中用的不是特别多
1. 开启指定⽬录的快照:
hdfs dfsadmin -allowSnapshot 路径
2. 禁⽤指定⽬录的快照,默认是禁⽤
hdfs dfsadmin -disallowSnapshot 路径
3. 对⽬录创建快照(当前时间)
hdfs dfs -createSnapshot 路径
4. 以指定名称创建快照
hdfs dfs -createSnapshot 路径 名称
5. 重命名快照
hdfs dfs -renameSnapshot 路径 旧名称 新名称
6. 列出当前⽤户所有可快照⽬录
hdfs lsSnapshotableDir
7. ⽐较两个快照⽬录不同之处(重要)
hdfs snapshotDiff 路径1 路径2
8.删除快照
hdfs dfs -deleteSnapshot 路径 名称
8. 快照恢复
hdfs dfs -cp 源路径 目的路径
HDFS读写过程(重点)
1. 读过程
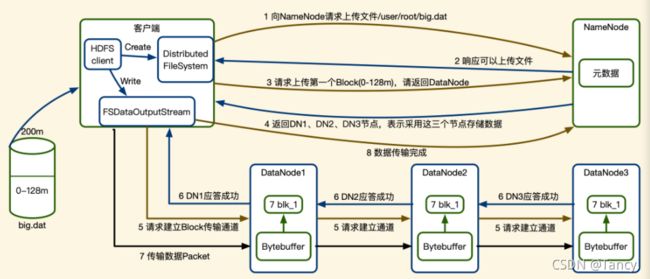
- 客户端请求上传文件(FSDataOutputStream)
- NN回应可以上传
- 请求上传第一个block,请NN返回可用的DN(就近分配)
- NN返回可用的DN节点
- 客户端与DN建立通道
- DN应答成功
- 客户端开始向DN传数据
- 客户端向NN反应传输完成
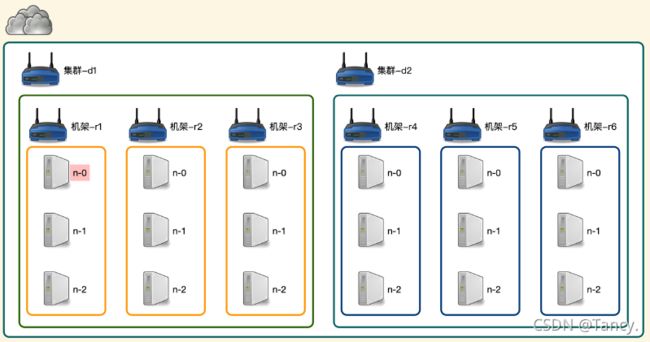
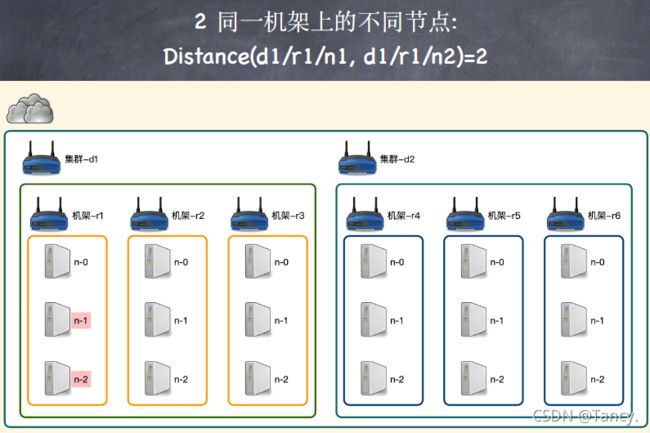
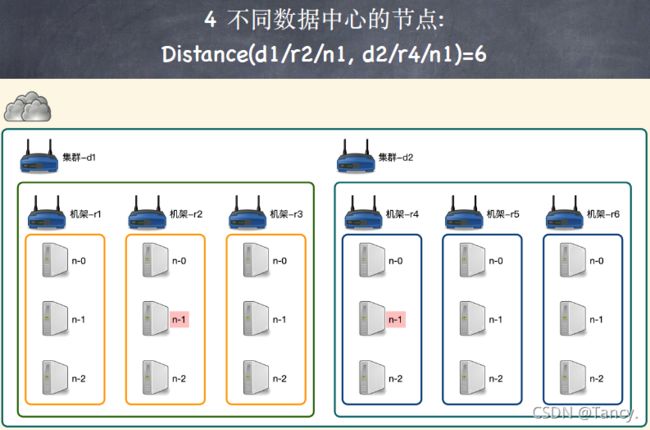
2. 网络拓扑—节点距离计算
在HDFS的写数据过程中,NameNode 会选择距离最近的DataNode 接收数据
节点距离:两个节点到达最近共同祖先的距离总和
3. HDFS读过程

- 客户端请求下载(FSDataInputStream)
- NN返回目标文件的元数据(距离最近)
- 客户端请求读取
- DN传输数据
若有多次,则重复3、4步
cd - 进入
cd $_ 进入刚创建的文件夹
进程号 ps
https://hadoop.apache.org/docs/current/api/