Java内存模型—JMM详解
目录
什么是JMM?
JMM内存模型
内存交互操作
JMM三大特性
原子性
可见性
有序性
指令重排问题
处理器重排序与内存屏障
数据依赖性
as-if-serial语义
volatile
CAS
ABA问题
什么是ABA问题
如何解决ABA问题
各种锁的理解
公平锁和非公平锁
可重入锁
自旋锁
什么是JMM?
JMM即为JAVA 内存模型(java memory model)。不存在的东西,是概念,是约定。因为在不同的硬件生产商和不同的操作系统下,内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。Java内存模型,就是为了屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。即达到Java程序能够“一次编写,到处运行”。
内存模型描述了程序中各个变量(实例域、静态域和数组元素)之间的关系,以及在实际计算机系统中将变量存储到内存和从内存中取出变量这样的底层细节
Java Memory Model(Java内存模型), 围绕着在并发过程中如何处理可见性、原子性、有序性这三个特性而建立的模型。
JMM从java 5开始的JSR-133发布后,已经成熟和完善起来。
JSR-133规范
即JavaTM内存模型与线程规范,由JSR-133专家组开发。本规范是JSR-176(定义了JavaTM平台 Tiger(5.0)发布版的主要特性)的一部分。本规范的标准内容将合并到JavaTM语言规范、JavaTM虚拟机规范以及java.lang包的类说明中。
JSR-133中文版下载
该规范在Java语言规范里面指出了JMM是一个比较开拓性的尝试,这种尝试视图定义一个一致的、跨平台的内存模型,但是它有一些比较细微而且很重要的缺点。它提供大范围的流行硬件体系结构上的高性能JVM实现,现在的处理器在它们的内存模型上有着很大的不同,JMM应该能够适合于实际的尽可能多的体系结构而不以性能为代价,这也是Java跨平台型设计的基础。
其实Java语言里面比较容易混淆的关键字主要是synchronized和volatile,也因为这样在开发过程中往往开发者会忽略掉这些规则,这也使得编写同步代码比较困难。
JSR133本身的目的是为了修复原本JMM的一些缺陷而提出的。
JMM内存模型
JMM规定了所有的变量都存储在主内存(Main Memory)中。每个线程还有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成。
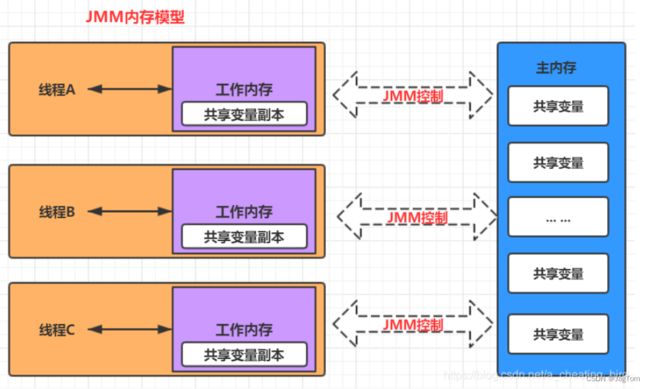
从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
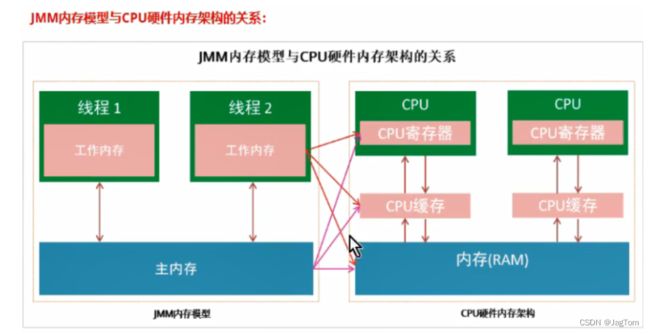
JVM在设计时候考虑到,如果JAVA线程每次读取和写入变量都直接操作主内存,对性能影响比较大,所以每条线程拥有各自的工作内存,工作内存中的变量是主内存中的一份拷贝,线程对变量的读取和写入,直接在工作内存中操作,而不能直接去操作主内存中的变量。但是这样就会出现一个问题,当一个线程修改了自己工作内存中变量,对其他线程是不可见的,会导致线程不安全的问题。因为JMM制定了一套标准来保证开发者在编写多线程程序的时候,能够控制什么时候内存会被同步给其他线程。
内存交互操作
内存交互操作有8种,虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)
- lock (锁定):作用于主内存的变量,把一个变量标识为线程独占状态
- unlock (解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read (读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load (载入):作用于工作内存的变量,它把read操作从主存中变量放入工作内存中
- use (使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令
- assign (赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放入工作内存的变量副本中
- store (存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用
- write (写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
- 不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write
- 不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
- 不允许一个线程将没有assign的数据从工作内存同步回主内存
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
- 一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
- 对一个变量进行unlock操作之前,必须把此变量同步回主内存
画图举例:
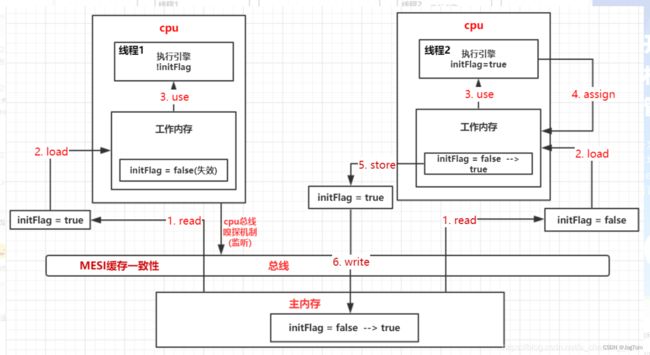
分析:
1、首先,主内存中,initFlag=false。
2、线程1经过 read、load,工作内存处,initFlag = false,use 之后, 执行引擎处 !initFlag = true,此时,卡在while处。
3、线程2同理,经过 read、load 之后,此时工作内存处,initFlag=false,经过 use (initFlag=true)、assign后,initFlag=true。
4、因为线程2处的cpu修改了 initFlag 的值,会 马上回写 到主内存中(经过 store、write两步)。
5、线程1处的cpu 通过 总线嗅探机制 嗅探到变化,会将工作内存中的数据 失效(initFlag=false失效)
6、线程1会 重新 去主内存 read 最新的数据(此时,主内存中的数据 initFlag=true)。
7、那么,线程1在读取最新的数据时,执行引擎处,!initFlag = false,结束循环,输出 “success”。
JMM对这八种操作规则和对volatile的一些特殊规则就能确定哪里操作是线程安全,哪些操作是线程不安全的了。但是这些规则实在复杂,很难在实践中直接分析。所以一般我们也不会通过上述规则进行分析。更多的时候,使用java的happen-before规则来进行分析。
JMM三大特性
Java内存模型是围绕着并发编程中原子性、可见性、有序性这三个特征来建立的,那我们依次看一下这三个特征:
原子性
什么是原子性:一个操作不能被打断,要么全部执行完毕,要么不执行。在这点上有点类似于事务操作,要么全部执行成功,要么回退到执行该操作之前的状态。
为什么会有原子性问题:因为CPU 有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去 CPU 使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
举个例子:你觉得num++是原子性操作吗?看起来它就一行代码,然而反编译之后可以看到num++在内存中操作也是分为了三步操作,那么多线程同时进来就可能在某个步骤被线程的随机调度打断而产生的一系列的问题。
a = true; //原子性
a = 5; //原子性
a = b; //非原子性,分两步完成,第一步加载b的值,第二步将b赋值给a
a = b + 2; //非原子性,分三步完成
a ++; //非原子性,分三步完成:1、读取a的值,2、计算a的值+1,3、赋值

如何保证原子性:1、synchronized一定能保证原子性,因为被其修饰的某段代码,只能由一个线程执行,所以一定可以保证原子操作。2、juc(java.util.concurrent包)中的lock包和atomic包,他们也可以解决原子性问题.
可见性
什么是可见性:一个线程对共享变量做了修改之后,其他的线程立即能够看到(感知到)该变量的这种修改(变化)。
为什么会有可见性问题:根据JMM内存模型,可以看到主内存和线程工作内存之间存在时间差(延迟)问题。
由于线程对共享变量的操作都是线程拷贝到各自的工作内存进行操作后才写回到主内存中的,这就可能存在一个线程A修改了共享变量 i 的值,还未写回主内存时,另外一个线程B又对主内存中同一个共享变量 i 进行操作,但此时A线程工作内存中共享变量 i 对线程B来说并不可见,这种工作内存与主内存同步延迟现象就造成了可见性问题,另外指令重排以及编译器优化也可能导致可见性问题,通过前面的分析,我们知道无论是编译器优化还是处理器优化的重排现象,在多线程环境下,确实会导致程序轮序执行的问题,从而也就导致可见性问题。
如何保证可见性:volatile的特殊规则保证了volatile变量值修改后的新值立刻同步到主内存,每次使用volatile变量前立即从主内存中刷新,因此volatile保证了多线程之间的操作变量的可见性,而普通变量则不能保证这一点。
除了volatile关键字能实现可见性之外,还有synchronized,Lock,final也是可以的。
使用Lock接口的最常用的实现ReentrantLock(重入锁)来实现可见性:当我们在方法的开始位置执行lock.lock()方法,这和synchronized开始位置(Monitor Enter)有相同的语义,即使用共享变量时会从主内存中刷新变量值到工作内存中(即从主内存中读取最新值到线程私有的工作内存中),在方法的最后finally块里执行lock.unlock()方法,和synchronized结束位置(Monitor Exit)有相同的语义,即会将工作内存中的变量值同步到主内存中去(即将线程私有的工作内存中的值写入到主内存进行同步)。
final关键字的可见性是指:被final修饰的变量,在构造函数数一旦初始化完成,并且在构造函数中并没有把“this”的引用传递出去(“this”引用逃逸是很危险的,其他的线程很可能通过该引用访问到只“初始化一半”的对象),那么其他线程就可以看到final变量的值。
有序性
什么是有序性:代码按顺序执行
为什么会有有序性问题:Java语言规定JVM线程内部维持顺序话语义,只要程序结果不受影响,那么执行的指令是可以优化的,可以和编写的代码顺序不一致,这就是指令重排。指令重排可能发生在多个阶段,例如Java源代码编译阶段、内存系统重排序等。但是指令重排有一个原则: as-if-seiral:不管怎么重排序,单线程的程序执行结果不能够被改变,编译器、处理器等都得遵循这个规范和准则。
如何保证有序性:Java提供了两个关键字volatile和synchronized来保证多线程之间操作的有序性,volatile关键字本身通过加入内存屏障来禁止指令的重排序,而synchronized关键字通过一个变量在同一时间只允许有一个线程对其进行加锁的规则来实现。
指令重排问题
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
1、编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2、指令并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3、内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
例如:volatile的有序性是通过禁止指令重排来实现的。为了性能,在JMM中,在不影响正确语义的情况下,允许编译器和处理器对指令序列进行重排序。而禁止指令重排底层是通过设置内存屏障来实现。
处理器重排序与内存屏障
现代的处理器(物理处理器即CPU)使用写缓冲区来临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器排序后对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!
常见处理器允许的重排序类型的列表:
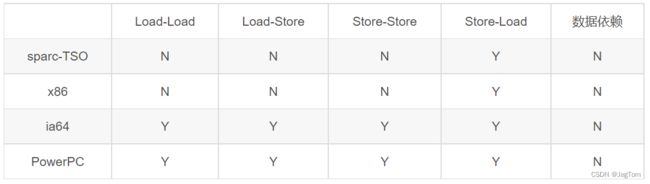
上表单元格中的“N”表示处理器不允许两个操作重排序,“Y”表示允许重排序。
从上表我们可以看出:
- 常见的处理器都允许Store-Load重排序;
- 常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO和x86拥有相对较强的处理器内存模型,它们仅允许对写-读操作做重排序(因为它们都使用了写缓冲区)。
※注1:sparc-TSO是指以TSO(Total Store Order)内存模型运行时,sparc处理器的特性。
※注2:上表中的x86包括x64及AMD64。
※注3:由于ARM处理器的内存模型与PowerPC处理器的内存模型非常类似,本文将忽略它。
※注4:数据依赖性后文会专门说明。
为了保证内存可见性,java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM内存屏障分为四类:
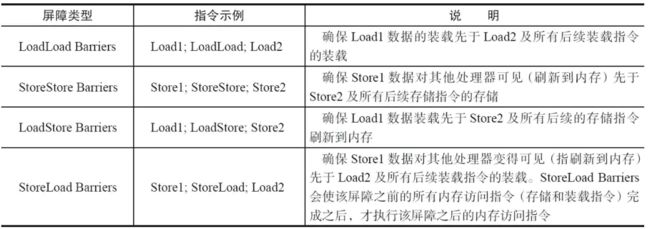
StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
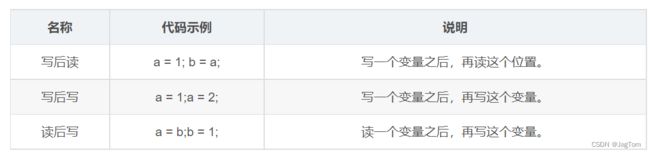
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。但是,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial语义
as-if-serial语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
【例】
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C

如上图所示,A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。下图是该程序的两种执行顺序:

as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
volatile
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
1、保证有序性(禁止指令重排)
Load指令(读屏障):将内存的数据拷贝到处理器缓存
Store指令(写屏障):让当前线程写入缓存的数据可以被其他线程看见
volatile的内存屏障策略:
volatile写之前插入StoreStore屏障;(规则a,防止重排)
volatile写之后插入StoreLoad屏障;(规则c,保障可见性)
volatile读之后插入LoadStore屏障;(规则b,防止重排)
volatile读之后插入LoadLoad屏障;(规则b,防止重排)
LoadLoad Barriers
排队,当第一个读屏障指令读取数据完毕之后,后一个读屏障指令才能够进行加载读取
(禁止读和读的重排序)
StoreStore Barriers
当A写屏障指令写完之后且保证A的的写入可以被其他处理器看见,再进行B的写入操作
(禁止写与写的重排序)
LoadStore Barriers
前一个读屏障指令读取完毕后,后一个写屏障指令才会进行写入
(禁止读和写的重排序)
StoreLoad Barriers
全能屏障,同时具有前三个的类型的效果,但开销较大。
先保证A的写入会被其他处理器可见,才进行B的读取指令
(禁止写和读的重排序)
volatile:在每一个写的volatile前后插入写屏障,读的volatile前后插入读屏障。
写,在每一次写入之前屏障拿到其他的线程修改的数据(因为可见性和重排序)。写入后的屏障可以被其他线程拿到最新的值。
读,在每一个读之前屏障获取某个变量的值的时候,这个值可以被其他线程也获取到。读取后的屏障可以在其他线程修改之前获取到主内存变量的当前值


2、保证可见性
volatile很好的保证了变量的可见性,变量经过volatile修饰后,对此变量进行写操作时,汇编指令中会有一个LOCK前缀指令,这个不需要过多了解,但是加了这个指令后,会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会使得在其他处理器缓存了该内存地址无效
volatile修饰的共享变量在执行写操作后,会立即刷回到主存,以供其它线程读取到最新的记录。
3、不保证原子性
volatile只有写操作是原子性的,也就是数据操作完成后会立刻刷新到主内存中。但是被volatile修饰的变量在读的时候可能会被多个线程读。也就是说int i = 1;i++;
A线程读 i = 1同时B线程也读了i = 1,然后自增完成刷新入主内存。i的值是2。
所以如果该变量是volatile修饰的,那可以完全保证此时取到的是最新信息。但在入栈和自增计算执行过程中,该变量有可能正在被其他线程修改,最后计算出来的结果照样存在问题,因此volatile并不能保证非原子操作的原子性,仅在单次读或者单次写这样的原子操作中,volatile能够实现线程安全。
CAS
在多线程编程时,如果想保证一段代码具有原子性,通过会使用锁来解决,而CAS是通过硬件指令来达到比较并交换的过程;简单来说,CAS是操作系统层上的原子性操作。
CAS在java上的实现方式主要是JUC下的atomic原子类包
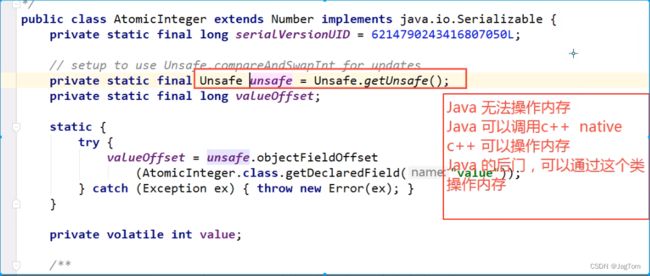
我们知道,Java是无法直接操作内存的,而C++可以,C++没有虚拟机,因此在Java里面有native可以调用C++;
CAS操作原理
CAS包括三个值:
V:内存地址;
A:期望值;
B:新值;
如果这个内存地址V的值和期望值A相等,则将其赋值为B;
例如:public final int getAndIncrement() 原子上增加一个当前值。

这里的原子类方法用了do while,无限循环,其实就是一个标准的自旋锁。
ABA问题
CAS只是比较和交换,失败就返回false 。但是原子类里面的方法会用自旋锁,无限循环,存在三个问题:
1、循环会耗时
2、一次性只能保证一个共享变量的原子性
3、ABA问题
什么是ABA问题
举个例子

如何解决ABA问题
ABA解决思路还是使用乐观锁,版本号,时间戳的思想。对于乐观锁不记得了,可以回顾这篇文章
Mysql—锁:全面理解_JagTom的博客-CSDN博客
在atomic包里面有个类 AtomicStampedReference
这里有个注意事项
这句代码是会有问题的:
![]()
compareAndSet源码,底层是用==进行判断 ,也就是我们在泛型使用包装类的时候要注意,Integer类型的范围是-128~127,超出范围会在堆里面新建一个对象并不会复用对象。
阿里巴巴规范手册:

AtomicStampedReference
public class AtomicStampedReference {
// 定义引用类型,包装值和版本号;
private static class Pair {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static Pair of(T reference, int stamp) {
return new Pair(reference, stamp);
}
}
private volatile Pair pair;
// 比较并交换
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair current = pair;
return
// 先做一次校验,如果在这里都已经不一致,则直接返回false,这里没有加锁,那么它可能会存在并发;
// 可能会有两个线程同时进来,判断并且都成立,则两个线程都会进入到:casPair方法;
// Pair current = pair; 多个线程进入到compareAndSet方法时,都已经保留了当前的pair值,那如果pair被其他线程修改,则另外一个线程去做cas的时候一定会返回false,所以这块是通过这种方式来防止并发的;
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
private static final sun.misc.Unsafe UNSAFE = sun.misc.Unsafe.getUnsafe();
private static final long pairOffset =
objectFieldOffset(UNSAFE, "pair", AtomicStampedReference.class);
private boolean casPair(Pair cmp, Pair val) {
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}
static long objectFieldOffset(sun.misc.Unsafe UNSAFE,
String field, Class klazz) {
try {
return UNSAFE.objectFieldOffset(klazz.getDeclaredField(field));
} catch (NoSuchFieldException e) {
// Convert Exception to corresponding Error
NoSuchFieldError error = new NoSuchFieldError(field);
error.initCause(e);
throw error;
}
}
}
各种锁的理解
lock、synchronized默认都是可重入锁,非公平锁
公平锁和非公平锁
公平锁:非常公平,不能够插队,必须先来后到!
非公平锁:非常不公平,可以插队(默认都是非公平)
public ReentrantLock {
sync = new Nonfairsync(); //默认非公平
}
public ReentrantLock(boolean fair) {
sync = fair ? new Fairsync() : new Nonfairsynco; //如果为true则设置为公平锁
}可重入锁
解释一:可重入就是说某个线程已经获得某个锁,可以再次获取锁而不会出现死锁。
这是可重入锁的概念描述。
解释二:可重入锁又称递归锁,是指同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提是锁对象得是同一个对象),不会因为之前已经获取过锁还没有释放而阻塞。
这是可重入锁的一种表现方式,不代表说某段代码中的锁没有发生嵌套,这个锁就不是可重入锁。
可重入锁是某个线程已经获得某个锁,可以再次获取锁而不会出现死锁。再次获取锁的时候会判断当前线程是否是已经加锁的线程,如果是对锁的次数+1,释放锁的时候加了几次锁,就需要释放几次锁。
代码中的锁的递归只是锁的一种表现及证明形式,除了这种形式外,还有另一种表现形式。同一个线程在没有释放锁的情况下多次调用一个加锁方法,如果成功,则也说明是可重入锁。
自旋锁

Java-concurrency/Java内存模型以及happens-before.md at master · three-body-zhangbeihai/Java-concurrency · GitHub