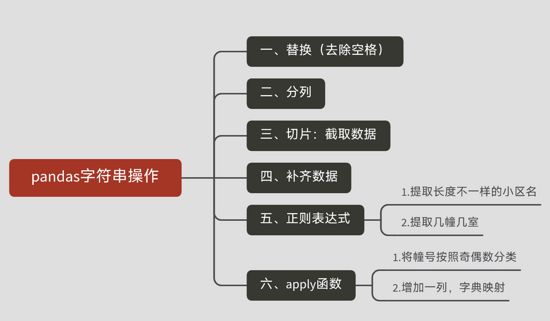
【Python自动化Excel】Python与pandas字符串操作
Python之所以能够成为流行的数据分析语言,有一部分原因在于其简洁易用的字符串处理能力。
Python的字符串对象封装了很多开箱即用的内置方法,处理单个字符串时十分方便;对于Excel、csv等表格文件中整列的批量字符串操作,pandas库也提供了简洁高效的处理函数,几乎与内置字符串函数一一对应。也就是说:
-
单个字符串处理,用Python内置的字符串方法;
-
表格整列的字符串处理,用pandas库中的字符串函数;
本文就以常用的数据处理需求,来对比使用以上两种方式的异同,从而加深对 Python 和 pandas 字符串操作的理解。(本文所有数据都是为了演示用的假数据,切勿当真!)
)
一、替换(去除空格)
场景:在问卷收集的姓名字段中,不少填写者会误输入空格,造成数据匹配不一致的问题。
Python
names = '刘 备、关 羽、 张 飞、赵 云、马 超、黄 忠'
names = names.replace(' ','')
print(names)
output
刘备、关羽、张飞、赵云、马超、黄忠
pandas
df['姓名'] = df['姓名'].str.replace(' ','')
output
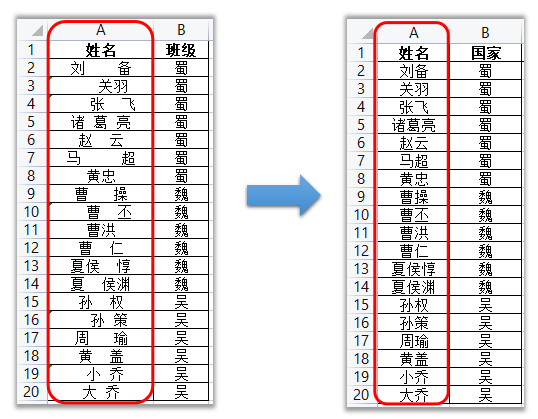
pandas替换空格
二、分列
场景:在问卷收集数据的时候,多选题的数据往往是带有分隔符的。在分类汇总前往往需要按分隔符进行分列。

问卷中多选数据导出
Python
hobbyStr = "足球┋排球┋羽毛球┋篮球"
hobbyList = hobbyStr.split('┋')
output
['足球', '排球', '羽毛球', '篮球']
pandas
# 利用split进行分列,expand = True 返回dataframe;expand=False返回Series
hobbyDf = df['爱好'].str.split('|', expand=True)
# 将hobbyDf 与 df安装索引合并
df2 = pd.merge(df, hobbyDf, how="left", left_index=True, right_index=True)
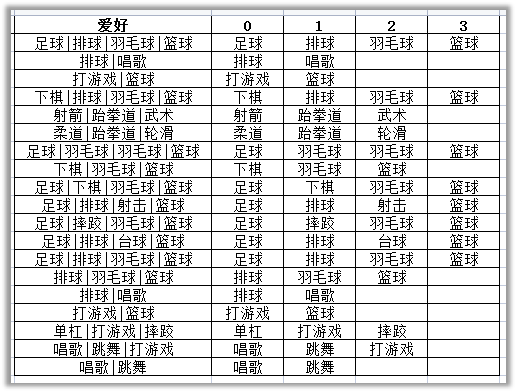
分列、合并、导出Excel后效果
三、切片:截取数据
字符串是由一个个字符组成的序列,在Python中可以直接对字符串进行切片操作,来进行截取数据。
如“XX市四季家园二区22幢203室”,可以看作是下图中16个字符值组成的序列。而切片的语法是:
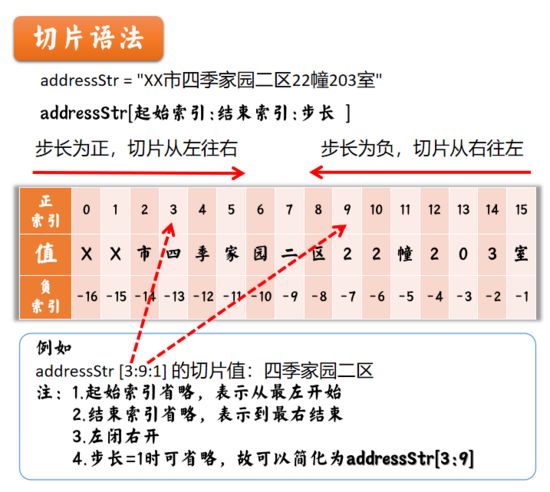
Python切片原理
Python
addressStr = "XX市四季家园二区22幢203室"
print(f"城市:{addressStr[:3]}")
print(f"小区:{addressStr[3:9]}")
output
城市:XX市 小区:四季家园二区
pandas
-
提取城市名称,由于城市名称的字数相同,可以直接切片截取前三个。
df["城市"] = df["地址"].str[:3]
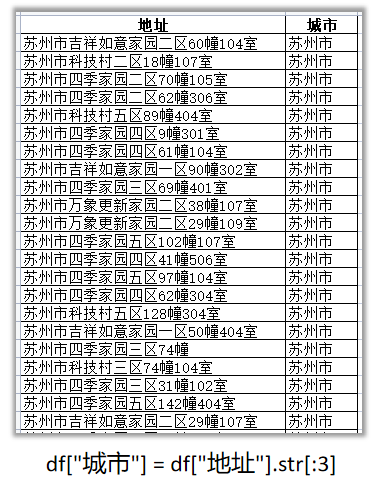
提取城市
-
提取小区名,稍有点复杂。因为小区名称长度是不一样长的。可以利用字符串处理的天花板:
正则表达式。详细处理方法,见下文五、正则表达式示例1。
四、补齐数据
有时候,我们在电脑中按文件名排序的时候,你可能会遇到下面的情况:
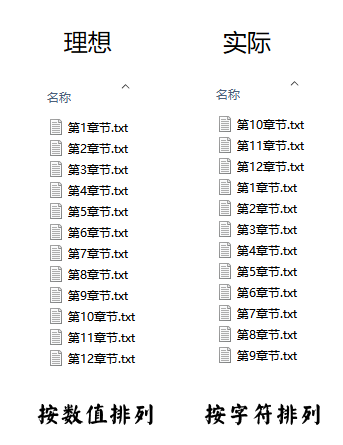
数值排序和字符排序
在不同系统中,我们希望是按数值排序,但偏偏系统却是按字符排序的,如某些车载播放器中。比较好的解决方法就是在前面添加0,补齐数据位数。数据量大的时候,手动修改很麻烦,Python字符串处理的 zfill() 函数就可以解决这个问题。
Python
myStr = "1章节" print(myStr.zfill(4)) # 整个字符串补齐到4位
output
01章节
pandas
df["新文件名"] = "第"+df["文件名"].str[1:].str.zfill(8)

image-20220330005403437
配合 os.rename() 便可以批量重命名。关键代码如下
df.apply(lambda x: os.rename( path + x["文件名"], path + x["新文件名"]), axis=1)
批量重命名演示
五、正则表达式
遇到复杂的字符串处理需求时,Python有优势就可以体现出来了。因为python和pandas有一个超强的字符串处理武器:正则表达式。正则表达式可以匹配字符串的格式特点,如电子邮箱的地址格式、网址的地址格式、电话号码格式等。如何写好正则表达式,这是一门精深的学问,本文介绍几个正则表达式的常用案例,浅尝辄止。
注:Python默认不支持正则表达式语法,而pandas直接支持正则表达式语法,这里重点介绍pandas处理表格数据。
1.提取长度不一样的小区名
思路:
-
提取上面小区名,可以归纳一下地址中小区名的格式特点:
苏州市之后,幢号数字之前的中文字符。 -
Series的str.extract(),可用正则从字符数据中抽取匹配的数据;
## 匹配中文字符的正则表达式: [\u4e00-\u9fa5] pattern = r'苏州市([\u4e00-\u9fa5]+)[0-9]+幢' df["小区"] = df["地址"].str.extract(pattern, expand=False)
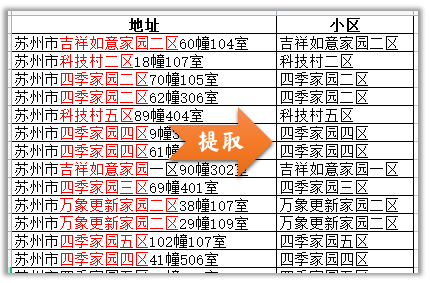
提取小区名
2.提取几幢几室
思路:几幢几室,格式都是 数字+幢 和 数字+室
-
数字可以用
[0-9]或\d来匹配; -
+表示1个或多个。
pattern = r'([0-9]+)幢' df["幢号"] = df["地址"].str.extract(pattern, expand=False) pattern = r'(\d+)室' df["室号"] = df["地址"].str.extract(pattern, expand=False)

提取幢号室号
六、apply函数
apply 函数:可以对 DateFrame 进行逐行或逐列进行处理。
1.增加一列,将幢号按照奇偶数分类
将幢号为奇数的为A区,偶数的为B区
# 定义处理的函数,共apply函数调用,传入的参数为一个Series对象
def my_func(series):
if (series["幢号"]) % 2 != 0:
return "A区"
else:
return "B区"
df["幢号分类"] = df.apply(my_func, axis=1)
上述代码中apply函数,有两个参数
-
第一个参数:处理逻辑的函数名。主要传入名称,这里为
my_func; -
第二个参数:
axis = 1,表示按列处理。即传入的是每一行的Series。
output
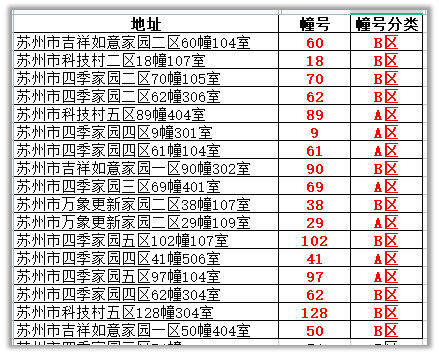
apply映射分类
2.增加一列,字典映射
def my_func2(series):
# 映射字典,key为小区名,value为小区称号
my_dict = {
'吉祥如意家园': '最佳好运小区',
'科技村': '最佳科创小区',
'四季家园': '最佳风光小区',
'万象更新家园': '最佳风采小区',
}
# 每一行小区名称,切片截取至倒数第2个,即-2
nameKey = series['小区'][:-2]
return my_dict[nameKey]
df["小区称号"] = df.apply(my_func2, axis=1)
output

apply匹配映射
结语
本文演示的字符串操作: 替换 、 分列 、 切片截取 、 补齐数据 、 正则表达式 、 apply()函数 常见于数据分析的数据清洗环节, 替换 、 分列 、 切片截取 在Excel中也很容易实现, 正则表达式 可以说是Python处理复杂字符串问题的一大利器, apply()函数 可以实现 自定义函数 处理表格型的数据,十分灵活、威力巨大。由于篇幅有限, 正则表达式 、 apply()函数 本文就点到为止,今后值得整理更多相关案例。