市面上公司做RNA-Seq的一般流程是:
tophat2 ---> Cufflinks ---> Cuffdiff ---> R
- tophat2是把reads回帖到基因组上;
- Cufflinks在计算基因表达量;
- Cuffdiff比较control和treatment找差异基因(生成一个数据框)
后面的富集分析,一般只做GO分析,KEGG pathway 分析,最多再做一个DO分析,公司一般用的是已经成熟的database,这就导致数据分析不完全,而且公司用的数据库很多时候都已经过时了,所以我们需要自己学会做下游的富集分析。
GO分析的理论知识
what is Gene Ontology(GO)? 基因"本体论"
基因本体论是对基因在不同维度和不同层次上的描述。
对基因的描述一般从三个层面进行:
- Cellular component,CC 细胞成分
- Biological process, BP 生物学过程
- Molecular function,MF 分子功能
这三个层面具体是指:
- Cellular component解释的是基因存在在哪里,在细胞质还是在细胞核?如果存在细胞质那在哪个细胞器上?如果是在线粒体中那是存在线粒体膜上还是在线粒体的基质当中?这些信息都叫Cellular component。
- Biological process是在说明该基因参与了哪些生物学过程,比如,它参与了rRNA的加工或参与了DNA的复制,这些信息都叫Biological process
- Molecular function在讲该基因在分子层面的功能是什么?它是催化什么反应的?
So, we will have a gene annotation infarmation.
立足于这三个方面,我们将得到基因的注释信息。
得到GO注释
model organism ---> annotated database
non-model organism ---> search database or blast
- 模式生物 ---> 有标准的注释数据库;
- 非模式生物 ---> 自己搜注释数据库(怎们搜后面具体介绍),搜不到就用blast的办法解决。
做GO分析的思路:
control VS treatment ---> DEG ---> GO enrichment analysis
也就是RNA-Seq先测出各组的基因表达分布:
control gene expression distribution
treatment gene expression distribution
control VS treatment ---> DEG : differential expression genes
通过比较 control 和 treatment 得到差异表达基因
再去做GO富集分析:
DEG ---> GO enrichment analysis
用找到的差异基因去做GO富集分析,希望能从这三方面找到和我们背景不一样的地方。
比如,在疾病研究的时候,进行药物治疗之后某些基因的表达量明显的发生了变化,拿这些基因去做GO分析发现在Biological process过程当中集中在RNA修饰上,然后在此基础上继续进行挖掘。这个例子就是想启示大家拿到差异表达基因DEG只是一个开始,接下来就应该去做GO注释,之后需要进行一个分析看这些注释主要集中在哪个地方。假如我们有100个差异表达基因其中有99个都集中在细胞核里,那我们通过GO分析就得到了一个显著的分布。
GO富集分析原理:有一个term注释了100个差异表达基因参与了哪个过程,注释完之后(模式生物都有现成的注释包,不用我们自己注释),计算相对于背景它是否显著集中在某条通路、某一个细胞学定位、某一种生物学功能。
KEGG enrichment analysis?
把生物体中所有的pathway都要进行富集分析
DO enrichment analysis?
看目标基因是否在某个疾病或某一类疾病当中富集
代码部分
- RNA-seq分析中第一步是:fastq ---> bam (tophat2 , hisat2 , star....);
- 使用 cufflink 输入文件是bam;
- 使用 cutffdiff 做差异表达分析,输入文件是 bam GTF注释文件
这套流程是上游分析,拿到cutffdiff结果之后就可以转到R里进行下一步分析:
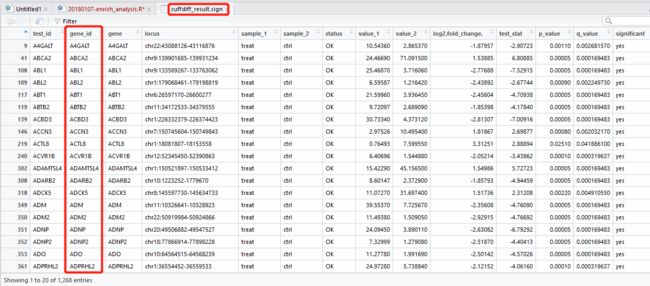
1. load cutffdiff result
cuffdiff_result = read.table(file="./hela_gene_exp.diff",header = T,sep = "\t")
cuffdiff_result$sample_1 = "treat"
cuffdiff_result$sample_2 = "ctrl"
2. select DEG
- I. FPKM1 or FPKM2 > 1
- II. log2(fold change) >1 or < -1
- III. p-value < 0.05
select_vector = (cuffdiff_result$value_1 > 1 | cuffdiff_result$value_2 > 1) & (abs(cuffdiff_result$log2.fold_change.) >= 1) & (cuffdiff_result$p_value < 0.05)
得到差异表达基因,赋值给一个新的数据框 cuffdiff_result.sign
cuffdiff_result.sign = cuffdiff_result[select_vector,]
> dim(cuffdiff_result.sign)
[1] 2739 14
这就说明在这种条件下我们筛选出了2739个差异表达基因,这个其实有点多了。我们只是为了走一下富集分析的流程,所以把条件再加紧一下,筛出一千来个基因去做分析正好:
> select_vector = (cuffdiff_result$value_1 > 1 | cuffdiff_result$value_2 > 1) & (abs(cuffdiff_result$log2.fold_change.) >= 1.5) & (cuffdiff_result$p_value < 0.05)
> cuffdiff_result.sign = cuffdiff_result[select_vector,]
> dim(cuffdiff_result.sign)
[1] 1268 14
网页工具做GO分析
david
打开谷歌 ---> 搜david --->第一个点进去 ---> 就是做GO分析的最常用的网站
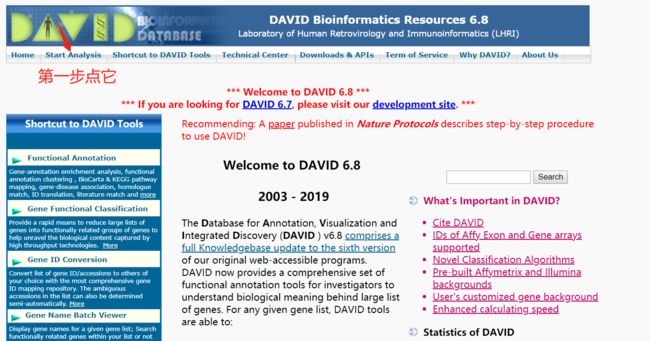
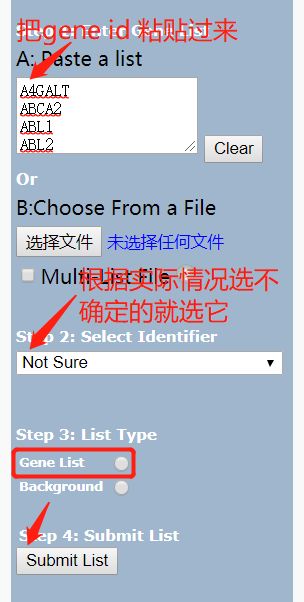
如图,点进去后,把gene list 放进白色的框里

写个代码把 gene id 那一列单独提取出来并保存到本地。
output.gene_id = data.frame(gene_id = cuffdiff_result.sign$gene_id)
write.table(output.gene_id,file="./sign_gene_id.txt",col.names = F,row.names = F,sep = "\t",quote = F)
这时当前文件夹就多了一个名为sign_gene_id.txt里面装有所有gene_id 的txt文件。
Enrichr
还推荐了一个常用的网站 Enrichr
R代码做GO分析
用R可以做一些网站上不能做的东西。
1.准备工作——安装R包
# 安装包
source("https://bioconductor.org/biocLite.R")
BiocManager::install("clusterProfiler") #用来做富集分析
BiocManager::install("topGO") #画GO图用的
BiocManager::install("Rgraphviz")
BiocManager::install("pathview") #看KEGG pathway的
BiocManager::install("org.Hs.eg.db") #这个包里存有人的注释文件
# 载入包dian
library(clusterProfiler)
library(topGO)
library(Rgraphviz)
library(pathview)
library(org.Hs.eg.db)
2.作图前处理——提取symbol ID --> 转换为ENTREZID
DEG.gene_symbol = as.character(output.gene_id$gene_id) #获得基因 symbol ID
防止在做GO分析的时候出现报错,需要将symbolID转换成ENTREZID:用mapIds函数就可以转换ID。
DEG.entrez_id = mapIds(x = org.Hs.eg.db,
keys = DEG.gene_symbol,
keytype = "SYMBOL",
column = "ENTREZID")
这时就已经把symbolID转换成ENTREZID了,但会出现个别的转换不成功的情况,就是图中NA的地方,我们进行以下操作即可去掉:
DEG.entrez_id = na.omit(DEG.entrez_id)

做好准备工作,我们就开始做富集分析
3.GO分析代码
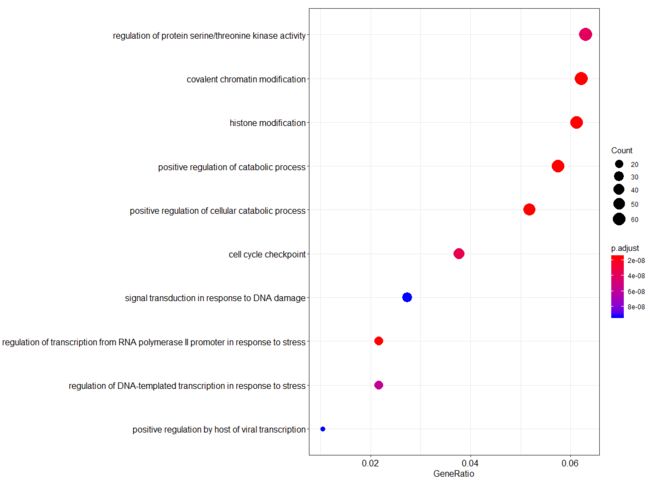
BP(Biological process)层面上的富集分析:
erich.go.BP = enrichGO(gene = DEG.entrez_id,
OrgDb = org.Hs.eg.db,
keyType = "ENTREZID",
ont = "BP",
pvalueCutoff = 0.5,
qvalueCutoff = 0.5)
##分析完成后,作图
dotplot(erich.go.BP)
解读BP层面富集分析图:
横坐标是GeneRatio,意思是说输入进去的基因,它每个term(纵坐标)站整体基因的百分之多少。圆圈的大小代表基因的多少,图中给出了最大的圆圈代表60个基因,圆圈的颜色代表P-value,也就是说P-value越小gene count圈越大,这事就越可信。
CC(Cellular component)层面上的富集分析:
erich.go.CC = enrichGO(gene = DEG.entrez_id,
OrgDb = org.Hs.eg.db,
keyType = "ENTREZID",
ont = "CC",
pvalueCutoff = 0.5,
qvalueCutoff = 0.5)
## 画图
barplot(erich.go.CC)
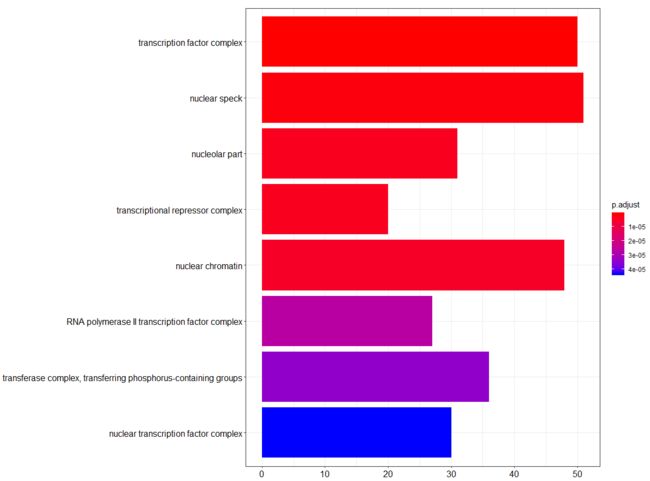
一般GO分析画这两个图就可以了,有时也把GO分析画成树形图,可以更加帮助我们理解。
plotGOgraph(erich.go.BP)

树状图很大,所以我们用代码把它存成pdf,学习下如何用代码
pdf(file="./enrich.go.bp.tree.pdf",width = 10,height = 15)
plotGOgraph(erich.go.BP)
dev.off()
至此,GO分析就做完了 ----> over
KEGG pathway介绍
KEGG: Kyoto Encyclopedia of Genes and Genomes
KEGG是日本主导的一个项目对gene和genome进行了非常详细的注释
KEGG网页分析里面有非常全的注释。
KEGG pathway 分析和上面介绍的GO分析是一样的只是把enrichGO()函数改成 enrichKEGG()
GO分析:enrichGO() —---—> KEGG pathway分析:enrichKEGG()
所以不细讲啦~
DO分析介绍
DO分析用enrichDO()函数,是做疾病的,这里我们做一下:
enrichDO(gene = DEG.entrez_id,ont = "DO",pvalueCutoff = 0.5,qvalueCutoff = 0.5)
非模式生物如何做富集分析
其实这个问题的核心是非模式生物怎样找到org.db数据库(标准注释库)?因为有了注释库后面的分析都一样一样的~
search org.db ----> 套路分析
非模式生物但有参考基因组的情况
以番茄为例,番茄有参考基因组但不在标准注释库里
先安装两个包
source("https://bioconductor.org/biocLite.R")
BiocManager::install("AnnotationHub")
BiocManager::install("biomaRt")
# 载入包
library(AnnotationHub)
library(biomaRt)
自己制作一个OrgDB
hub <- AnnotationHub::AnnotationHub()
使用query在我们制作的OrgDB --> hub里面找到番茄相关的database即org.Solanum_lycopersicum.eg.sqlite 注:Solanum_lycopersicum是番茄的拉丁名和它对应的编号AH59087
query(hub, "Solanum") # Solanum番茄的拉丁名
找到之后把它下载下来:
Solanum.OrgDb <- hub[["AH59087"]]
此时,番茄的database就会赋值到变量Solanum.OrgDb
解决完标准注释库的问题,剩下的和模式生物做富集分析完全一样了~~
GO,KEGG,DO富集分析 - (jianshu.com)