selenium+opencv 破解顶象滑动验证码
五一闲的蛋疼,就想写个脚本来实现自动体温打卡功能(仅用于学习!!!)
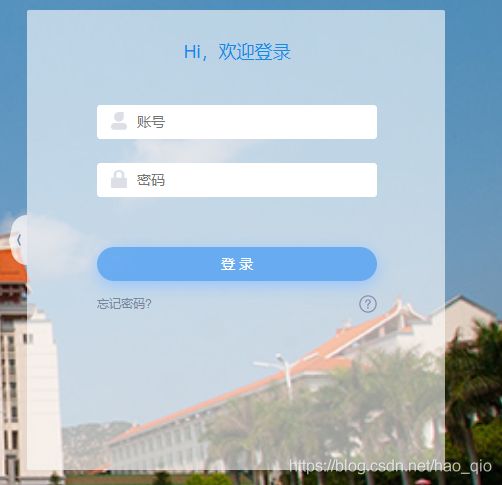
以我的学校的网站为例:
学校的体温打卡网站
实现这个功能需要掌握的基本要求:
爬虫基础 ------- 推荐《Python 3网络爬虫开发实战》这本书
opencv基础 -------- 学习opencv(学到第7节就可以了)+opencv中文文档
python基础
前端基础
配置:
需要导入selenium opencv-python 库和下载chromedriver 驱动器
这些网上的教程都有,我就不多概述了

首先,咱们先点击 “平台账号登录”按钮
接着就会弹出下面的登录框
import time
from io import BytesIO
import requests
from PIL import Image
from selenium import webdriver
from selenium.webdriver import ActionChains
import cv2 #opencv 读取格式是BGR
import matplotlib.pyplot as plt
import numpy as np
url='http://ijg.xujc.com'
browser = webdriver.Chrome() #通过谷歌浏览器驱动
browser.get(url)#获取目标地址
use='111111'
pwd='222222'
button = browser.find_element_by_xpath("//button[text()='平台账号登录']")#获取第一个按钮元素
button.click() # 点击第一个按钮
username = browser.find_element_by_xpath("//div[@class='account']/input")#获取输入用户名元素
password = browser.find_element_by_xpath("//div[@class='password']/input")#输入密码元素
loginbtn = browser.find_element_by_xpath("//span[text()='登 录']")#获取登录按钮
#输入用户名和密码
username.send_keys(use)
password.send_keys(pwd)
loginbtn.click() # 点击登录按钮
完成上述操作后弹出一个顶象验证码

第一步 :获取要匹配的图片和验证码图片


def get_img(self,browser):
time.sleep(1)
'''
获取匹配图片
'''
image1 = browser.find_element_by_xpath("//div[@class='dx_captcha_basic_sub-slider']/img")#获取img元素
location1 = image1.location #获取img元素在页面中的位置,待会要用
img_url = image1.get_attribute('src')#获取img元素里面的src链接
data = requests.get(img_url)#请求链接
with open("front.png", 'wb') as f:
f.write(data.content) #把图片以二进制保存
front = Image.open('front.png').convert("RGBA")#因为保存下来的图片是webp格式,所以要转化为png格式
front = front.resize((50, 50), Image.ANTIALIAS)# 因为下载下来的图片大小为68px*68px,和验证码上的图片大小不相同,得修改图片大小
front.save('front.png', "png") #再次保存图片
image2 = cv2.imread('front.png')#用cv2读取图片
w, h = image2.shape[:2] #获取图片的宽和高,待会要用
'''
因为咱们要获得的验证码图片是canvas元素,并不是img元素,所以只能通过截图的方式获取验证码图片
因此就要得到截取图片的x,y位置 ,宽度,高度
但是咱们截取图片并不用截取整个canvas元素
只要截取下面所展示的图片就可以了(便于之后的模板匹配)
'''
image = browser.find_element_by_xpath("//div[@id='dx_captcha_basic_bg_1']/canvas")
location = image.location # 获取图片的位置
size = image.size # 获取图片的大小
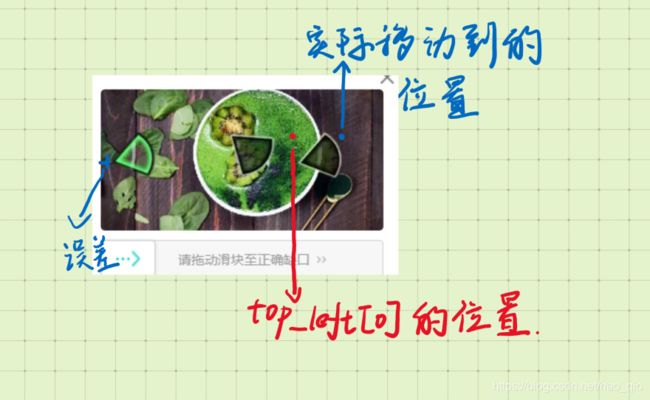
top, bottom, left, right = location1['y'], location1['y'] + h, location1['x'] + w, location['x'] + size[
'width'] #自行理解
screenshot = browser.get_screenshot_as_png() # 获取浏览器页面截图 数据类型以utf-8编码
screenshot = Image.open(BytesIO(screenshot)) # 将utf-8编码转化为二进制,并以图片的方式打开
captcha = screenshot.crop((left, top, right, bottom)) # 进行裁剪
captcha.save("bg.png") # 保存在bg.png中
上面代码执行后获取到的图片:

注意:上面这张图片是png格式,所以有透明通道,待会要把透明部分转化为白色(便于之后模板匹配)

第二步:接着将front.png进行 透明化处理 阈值处理 ,梯度处理,Canny边缘检测



将bg.png 进行梯度处理 , Canny边缘检测


def imagechange():
front = cv2.imread("front.png", cv2.IMREAD_UNCHANGED) # 以png格式打开
w, h = front.shape[:2]
for i in range(w): # 将透明部分变为白色
for j in range(h):
front[i, j][3] = 255
front=cv2.cvtColor(front,6)#将图片进行灰度处理,增加匹配的准确率
ret, th2 = cv2.threshold(front, 5, 255, cv2.THRESH_BINARY_INV) # 将front进行二值化处理
# cv2.imshow('th2.png',th2)
# cv2.waitKey(0)
sobelx = cv2.Sobel(th2, cv2.CV_16S, 1, 0, ksize=1) # 梯度处理
sobelx = cv2.convertScaleAbs(sobelx)
sobely = cv2.Sobel(th2, cv2.CV_16S, 0, 1, ksize=1)
sobely = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0)
# cv2.imshow('th2', sobely)
# cv2.waitKey(0)
th2 = cv2.Canny(sobelxy, 50, 100) #边缘检测
# cv2.imshow('th2', th2)
# cv2.waitKey(0)
cv2.imwrite('th2.png', th2) #将处理后的图片保存到 th2.png
img1 = cv2.imread("bg.png", cv2.IMREAD_GRAYSCALE)#将图片以灰度图打开,增加匹配的准确率
dstx = cv2.Sobel(img1, cv2.CV_16S, 1, 0, ksize=1)# 梯度处理 x轴方向
dstxcmp = cv2.convertScaleAbs(dstx)
dsty = cv2.Sobel(img1, cv2.CV_16S, 0, 1, ksize=1) # 梯度处理 y轴方向
dstycmp = cv2.convertScaleAbs(dsty)
dstxy = cv2.addWeighted(dstxcmp, 0.5, dstycmp, 0.5, 0)#将两张图片进行融合
# cv2.imshow('th2', dstxy)
# cv2.waitKey(0)
dstxy = cv2.Canny(dstxy , 100, 200) # Canny边缘检测
# cv2.imshow('th2', dstxy)
# cv2.waitKey(0)
cv2.imwrite("th1.png",dstxy)#将处理后的图片保存到 th1.png
**
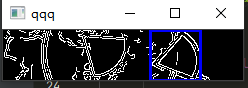
第三步:接着将th1.png ,th2.png进行模板匹配
**
def matchcmp(): #模板匹配
bg = cv2.imread('th1.png')
front = cv2.imread('th2.png')
w, h = front.shape[:2]
img2 = bg.copy()#复制图片,画矩形用
res = cv2.matchTemplate(bg, front, cv2.TM_CCOEFF_NORMED) #TM_CCOEFF_NORMED算法是我经过大量测试后匹配准确度比较高的算法
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h) #top_left[0]为匹配位置的 x坐标 top_left[1]为 y坐标
qqq = cv2.rectangle(img2, top_left, bottom_right, 255, 2)#画矩形
# cv2.imshow('qqq', qqq) #展示匹配到的部分
# cv2.waitKey(0)
print('匹配位置' + str(top_left[0]))
return top_left[0] + w -5 # 返回匹配的位置 这里要加上front.png图片的宽度w,-5是误差
第四步:得到位置后要模拟人移动滑块的速度 先加速后减速
def get_track(distance): #模拟滑动距离
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.3 #时间越大误差越大
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move)) #四舍五入
print("位移" + str(current))
return track #返回的是一个数组
最后就是模拟滑块移动
def move_to_gap(track): #移动滑块
drop = browser.find_element_by_xpath("//div[@class='dx_captcha_basic_slider-cover']")#获取滑块元素
ActionChains(browser).click_and_hold(drop).perform()#按住滑块
for x in track:
ActionChains(browser).move_by_offset(xoffset=x, yoffset=0).perform()#进行水平移动y=0
time.sleep(0.5)
ActionChains(browser).release().perform()#松开滑块
这样的方法匹配的准确率大概是80%,不是很高(我太菜了,如果还有更好的方法可以与我交流)
还有另一种方法是js逆向(网上有教程),这个方法难点就在逆向,如果能破解出来,就不用用到那么多图片处理,直接模板配就完事了,而且匹配准确率几乎100% 只是顶象的加密方法两天换一次…(已经麻了)
后续:
记录下第一次发表博客!!!
顶象验证码的破解真的太难了,他还会检测出是否是自动测试化工具(换了pyppeteer,加了很多绕过检测函数,如下图),还有ip定位(用代理也没用)

一但检测到webDriver或者ip多次登录,顶象就会启用二次验证(文字点选)
