Python爬虫实例(1)--requests的应用
Python爬虫实例(1)
我们在接下来的爬虫实例(1)里面将逐步的循序渐进的介绍爬虫的各个步骤。
已及时用到的工具,以及具体情况下的用法。
我们的任务是这样的:
爬取《修真聊天群》小说的内容,并且做出个性化的分析。(PS:这部小说值得一看)
这一节的内容最为基础的,得到小说介绍页的html。
本篇大约15min。建议实操。
修真聊天群

文章目录
- Python爬虫实例(1)
- 前言
-
- 为什么选用requests
- 一、requests的介绍
- 二、requests请求数据
-
- 1.get
- 2.post
- 三、请求的参数
-
- params
- headers
- 三、你的第一个爬虫
-
- 判断get,post
- 判断静态和动态
- 编写代码
-
- 乱码问题
- 四、总结
前言
爬虫的第一个任务,也是最重要的任务,首先我们需要得到网页的内容。
Python爬虫网络库主要包括:urllib、requests、、urllib3、httplib2、
他们的功能其实都是发送报文并接受返回信息(网页内容)。
为什么选用requests
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
requests底层封装了urllib这几个偏底层的库,并修改了接口,很nice。
其实他们的用法差不多,我推荐只用requests,其他的能看懂就行。
一、requests的介绍
详细的教程。
https://www.w3cschool.cn/requests2/
requests.request() 构造一个请求,支撑一下各方法的基础方法
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
所以说接口是很简单的。
安装
pip install requests
二、requests请求数据
1.get
r = requests.get('https://api.github.com/events')
2.post
r = requests.post('http://httpbin.org/post', data = {'key':'value'})
主要是这两个方法。最简单的形式也就是这样了。
区别在于get不需要提交一些用户啦请求信息相关的表单内容。
而post需要提交一些表单内容。
三、请求的参数
当我们百度Python的时候,应该都注意到了搜索出来的结果的url最后就是搜索的内容。
https://www.baidu.com/baidu?tn=monline_3_dg&ie=utf-8&wd=Python
tn=monline_3_dg&ie=utf-8&wd=Python
其实很像Python的字典是不是?
实际上也是一样的原理,储存关系信息。
只不过连接符用的是=和&
所以我们以后也可以自己写url了?是不是很有bi格。
params
除了自己手写这个字符串(连接字符串),也可以使用params参数
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.get("http://httpbin.org/get", params=payload)
>>>> print(r.url)
http://httpbin.org/get?key2=value2&key1=value1
headers
headers包含的是请求的头部信息。让我们来看看头部有什么吧。
F12,选择网络选项。
一开始由于网页已经请求好了。所以没有内容。这个时候点击刷新。
然后就会出来一大堆的信息。
挑一个200返回值的(成功标志)
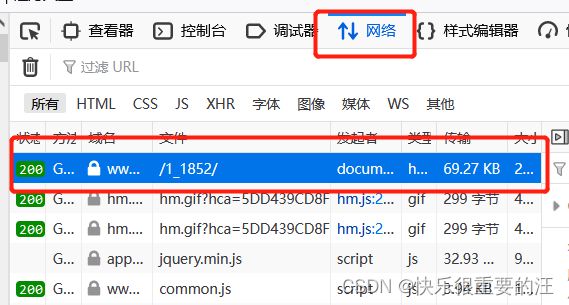
右下角。

常用的头部,大家复制粘贴即可!!!
import random
user_agent = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52"
]
HEADER = {
'User-Agent': random.choice(user_agent), # 浏览器头部
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 客户端能够接收的内容类型
'Accept-Language': 'en-US,en;q=0.5', # 浏览器可接受的语言
'Connection': 'keep-alive', # 表示是否需要持久连接
}
其实就是一个字典
我们可以看到host就是我们的请求网页。
还有比较常见的cookie。
不过最重要的是user-agent,这里是火狐。
headers就是手动的自定义这个里面的关系信息。
那我手动填写user-agent为火狐或者谷歌是不是就相当于我用火狐或者谷歌打开这个网站呢?
答案:是的!!!
这就是headers的意义所在。
三、你的第一个爬虫
爬取百度太无聊了趴。。。而且返回的还做过手脚的,比如期待你的加入。。。
我们还是来试试那个小说
判断get,post
根据目标内容无需提交额外信息,我们选择get。
判断静态和动态
也就是判断内容是不是通过js手段加载的。
随便点击一个内容看看HTML里面有没有,如果有就说明是静态。(大部分情况下如此)
如果没有,那以后高级部分再谈。。。先放弃吧

我算的这一卦,显示同志你正在看我的博文,学习的如痴如醉!!!
编写代码
import requests
'''
为了实现修真聊天群这个小说的爬取
以及后续的分析。
'''
url = 'https://www.zhhbqg.com/1_1852/'
rep = requests.get(url)
print(rep) # 成功的标志
print(rep.text) # 返回unicode类型

乱码问题
因为text输出的是unicode编码的。但是如下图,一般中文网页用ISO-8859-1比较多。
所以会乱码!!!
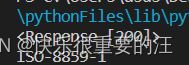
所以解决的方案就是修改输出的编码类型。中文一般用gbk。
url = 'https://www.zhhbqg.com/1_1852/'
rep = requests.get(url)
# 第一种 跟稳妥
print(rep) # 成功的标志
print(rep.encoding) # ISO-8859-1
print(rep.apparent_encoding) # gbk
rep.encoding = rep.apparent_encoding
# print(rep.content)
print(rep.text) # 然后根据response的规则自动转换为gbk
# 第二种 直接转换text字符串为gbk
print(rep.text.encode('iso-8859-1').decode('gbk'))
print(rep.text.encode(rep.encoding).decode(rep.apparent_encoding)) # 直接这样省钱省力!!!
well done!
<Response [200]>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>修真聊天群_修真聊天群(圣骑士的传说)最新章节_全文阅读-笔趣阁</title>
<meta name="keywords" content="修真聊天群,修真聊天群最新章节,圣骑士的传说,修真聊天群在线阅读" />
<meta name="description" content="修真聊天群是圣骑士的传说最新创作的一部情节与文笔俱佳的优秀小说,修真聊天群最新章节来源于互联网网友,笔趣阁提供修真聊天群全文无弹窗在线阅读和修真聊天群全文阅读." />
<meta http-equiv="Content-Type" content="text/html; charset=gbk" />
<meta http-equiv="Cache-Control" content="no-transform" />
<meta http-equiv="Cache-Control" content="no-siteapp" />
<meta http-equiv="mobile-agent" content="format=html5; url=https://m.zhhbqg.com/1_1852/" />
<meta http-equiv="mobile-agent" content="format=xhtml; url=https://m.zhhbqg.com/1_1852/" />
<meta property="og:type" content="novel"/>
<meta property="og:title" content="修真聊天群"/>
<meta property="og:description" content=" 某天,宋书航意外加入了一个仙侠中二病资深患者的交流群,里面的群友们都以‘道友’相称,群名片都是各种府主、洞主、真人、天师。连群主走失的宠物犬都称为大妖犬离家出走。整天聊的是炼丹、闯秘
境、炼功经验啥的。 突然有一天,潜水良久的他突然发现……群里每一个群员,竟然全部是修真者,能移山倒海、长生千年的那种! 啊啊啊啊,世界观在一夜间彻底崩碎啦! 书友群:九洲1号群:207572656 九洲2号"/>
<meta property="og:image" content="https://www.zhhbqg.com/files/article/image/1/1852/1852s.jpg"/>
<meta property="og:novel:category" content="都市小说"/>
我们可以将text的内容临时保存到变量里,或者文件存储一下。
四、总结
简单的不需要用户登录信息或者其他提交信息的,一般使用get就足以胜任。
大部分文本网站就是如此简单。
post需要提交表单信息。但是一般这样的网页都是很爱惜自身内容的,所以大概率也不是post
一份身份信息就能为所欲为的。
这些复杂的情况需要更高的伪装技巧,后续我会详解。
下一节我们讲如何处理得到的html信息。
