MongoDB分片存储集群支撑海量数据
前言
本篇文章会通过在MongoDB中的主从集群,以及集群之间同步机制和选举,以及如何达到读写分离、CAP分布式理论在mongodb中如何实现,如何使用主从集群等方面去详细解释mongodb应对高并发,分片集群中的概念 ,如何使用分片集群等多方面去解析应对海量数据的解决方法。
主从集群
首先mongodb 集群 :分为主从集群、和分片集群 ,部署多个MongoDB,集群。分为有状态集群、无状态集群。 从是否存放数据来区分。
无状态集群
无需存放数据,所有的访问的数据,都在数据库上的。 并且不用管数据是否一致,数据安全等。

有状态集群(衍生出主从节点)
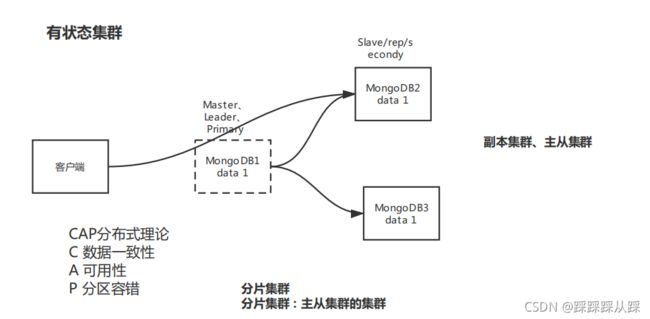
数据存在集群本身的,数据的状态,需要与其他节点进行交互,维护状态。而要解决问题的方案也就是主从集群,master 用来处理写 操作 从节点 ,并且 主节点挂点时,会读从节点上的数据。一旦遇到这个问题就会出现CAP分布式理论。数据一致性理论。 也是主从集群基础起来的分片集群。
概念
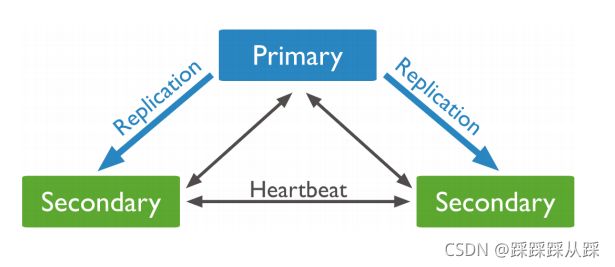
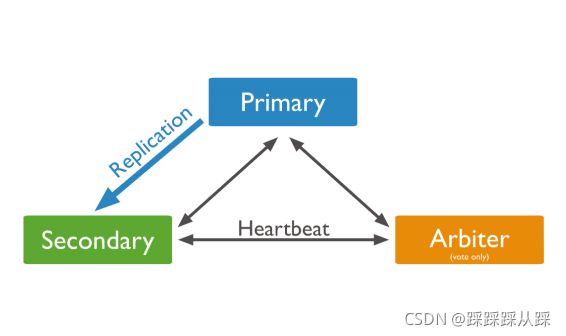
集群同步机制和选举

总的来说 这个 oplog上是个圆环。
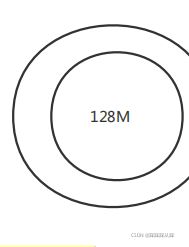
oplogSizeMB,考虑并发大小来定义
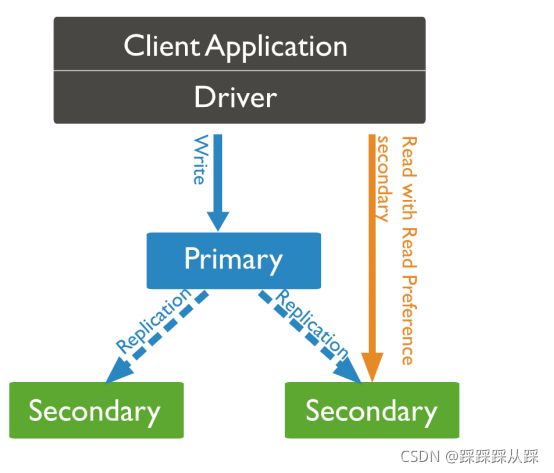
读写分离
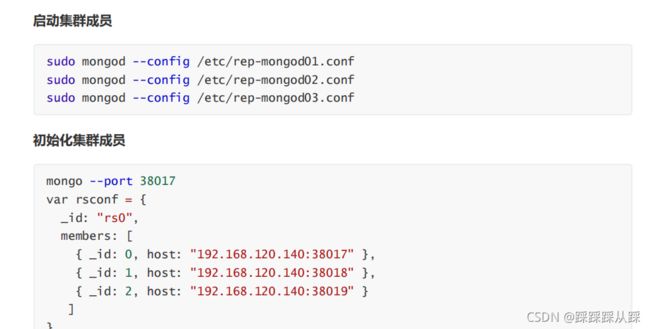
集群搭建
通过命令方式
# 创建备用目录
sudo mkdir -p /mongodb/data01 /mongodb/data02 /mongodb/data03# 第一个节点 sudo mongod --replSet "rs1" --bind_ip 0.0.0.0 --dbpath /mongodb/data01 --port 28018 --oplogSize 128
# 第二个节点
sudo mongod --replSet "rs1" --bind_ip 0.0.0.0 --dbpath /mongodb/data02 --port 28019 --oplogSize 128
# 第三个节点
sudo mongod --replSet "rs1" --bind_ip 0.0.0.0 --dbpath /mongodb/data03 --port 28020 --oplogSize 128- --replSet用来指定同一个集群中的集群名称,集群成员通过集群名字来找到组织。
- --bind_ip表示对集群成员的ip地址进行开放,集群成员之间需要网络通讯,多个地址用逗号分隔。 这里 我们用0.0.0.0来允许所有地址访问,实际环境不建议这么做。
- --dbpath指定数据目录的路径
- --port同一台机器上的伪集群,需要用不同的端口号来启动
- --oplogSize限制每个mongod实例使用的磁盘空间
sudo mongo --port 28019
Exception in monitor thread while connecting to server 127.0.0.1:28019配置文件方式
# 如果是yum安装方式,可以将默认配置文件复制出三个配置文件
sudo cp /etc/mongod.conf /etc/rep-mongod01.conf
sudo cp /etc/mongod.conf /etc/rep-mongod02.conf
sudo cp /etc/mongod.conf /etc/rep-mongod03.conf
# 如果不是,则创建,准备三个配置文件
sudo vim /etc/rep-mongod01.conf
sudo vim /etc/rep-mongod02.conf
sudo vim /etc/rep-mongod03.conf
# 准备目录
sudo mkdir -p /mongodb/dataOne /mongodb/dataTwo /mongodb/dataThreesystemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongod.log
# Where and how to store data.
storage:
dbPath: /mongodb/dataOne
journal: enabled: true
# engine:
# wiredTiger:
# how the process runs
processManagement:
fork: true # fork and run in background
pidFilePath: /var/run/mongodb/mongod.pid # 不同的实例
timeZoneInfo: /usr/share/zoneinfo
# network interfaces
net:
port: 38017
bindIpAll: true
# replication:
replication:
oplogSizeMB: 128
replSetName: "rs0"

具体的可以参考下面的搭建方式包括 分片集群等。
MongoDB集群搭建搭建的pdf 提取码:9h46
使用主从集群
在使用时,不要直接master


并且在使用时,
- 验证主从集群可用性 关闭主节点,集群能否正常提供服务?
- 读写分离 将写操作应用在主节点、读操作应用在次节点
- 读策略 local、available、majority、linearizable、snapshot
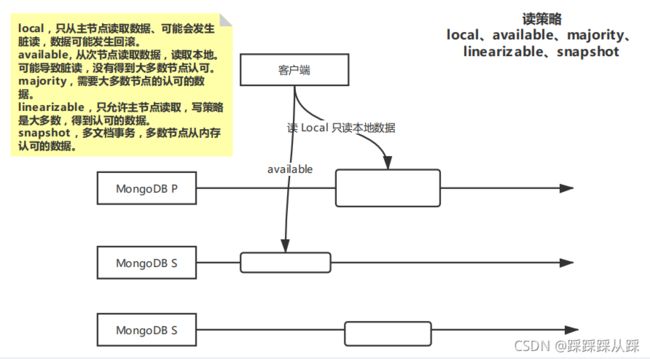
- 写策略 { w:
, j: , wtimeout: }

并用关心写的结果,写进去了,不需要响应的话。
MongoDB分片
本质在于 数据块太大 ,从而使用分片,把数据块拆小;包括根据日期或者 hash 去拆分开

分片集群中得角色:
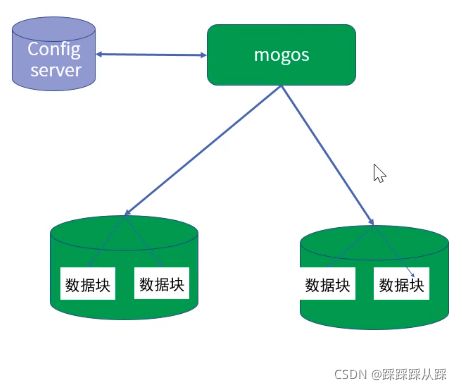
mongos:mongs充当查询路由器 ,在客户端应用程序和分片群集之间提供接口。
config server:配置 服务器 存储集群得元数据和配置设置。从mongodb 3.4开始 必须将服务器部署为副本
shard :每个shard 包含共享数据的子集,每个shard 可以部署为主副本集。

可以带来分而治之的思想。
为什么需要 分片集群,也是存储分布式,数据量大量增加, 单台cpu有瓶颈。
分片集群工作原理
除了分片,还有自带的数据块进行分区的效果
- 请求分流:通过路由节点将请求分发到对应的分片和块中
- 数据分流:内部提供平衡器保证数据的均匀分布,数据平均分布式请求平均分布的前提
- 块的拆分:3.4版本块的最大容量为64M或者10w的数据,当到达这个阈值,触发块的拆分,一分为二
- 块的迁移:为保证数据在分片节点服务器分片节点服务器均匀分布,块会在节点之间迁移。一般相差8个分块的时候触发
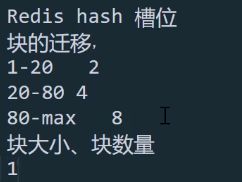
不断拆分,根据不同的数据块大小进行迁移
MongoDB集群搭建搭建的pdf 提取码:9h46

分片注意点与建议
- 热点 :某些分片键会导致所有的读或者写请求都操作在单个数据块或者分片上,导致单个分片服务器严重不堪重负。自增长的分片键容易导致写热点问题;
- 不可分割数据块:过于粗粒度的分片键可能导致许多文档使用相同的分片键,这意味着这些文档不能被分割为多个数据块,限制了mongoDB均匀分布数据的能力;
- 查询障碍:分片键与查询没有关联,造成糟糕的查询性能。
- 不要使用自增长的字段作为分片键,避免热点问题;
- 不能使用粗粒度的分片键,避免数据块无法分割;
- 不能使用完全随机的分片键值,造成查询性能低下;
- 使用与常用查询相关的字段作为分片键,而且包含唯一字段(如业务主键,id等);
- 索引对于分区同样重要,每个分片集合上要有同样的索引,分片键默认成为索引;分片集合只允许在 id和分片键上创建唯一索引;
WiredTiger引擎
- 读写操作性能更好,WiredTiger能更好的发挥多核系统的处理能力;
- MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger使用文档级 锁,由此带来并发及吞吐的提高
- 相比MMAPV1存储索引时WiredTiger使用前缀压缩,更节省对内存空间的损耗;
- 提供压缩算法,可以大大降低对硬盘资源的消耗,节省约60%以上的硬盘资源;
写入原理

配置项
