基于SpringBoot的API网关实现
目录
一、背景&目标
二、基于SpringBoot的API网关架构
2.1、概要架构图
2.2、架构说明
2.3、实现说明
2.3.2 高性能
2.3.3 高可用
2.3.4 安全性
三、总结
一、背景&目标
在微服务架构已经很普及的今天,API网关是整个微服务体系中是必不可少的基础服务。提到API网关大家可能会想到Zuul、Spring Cloud Gateway等开源API网关,Zuul2.x、Spring Cloud GateWay这些基于Reactor模式(响应式模式)的开源网关在高并发、高可用的需求场景下也已经被很多组织在生产环境中所验证。
我们在实际业务场景中可以直接使用Zuul、SpringCloud GateWay来满足我们业务的需求,即使需要在网关层实现一些具体的业务逻辑,我们也可以在开源的基础上进行二次开发。但如果我们只需要使用API网关核心的能力,同时需要在API层实现一些业务逻辑,我们基于SpringBoot自己来实现API网关,我们可以怎样来实现呢?通过结合实际业务需求以及对开源API网关的的学习,梳理出API网关的核心能力目标,具体如下:
1、基础能力
- 鉴权
- 路由转发
- 标准化返回
- 自定义异常
2、一定的高性能&高可用
- API网关作为微服务体系下的基础服务,API网关本身需要有比较高的性能,完整的一次请求在网关层消耗的时间要尽可能的小。
- 业务服务出现异常时,要能够保证网关不因为雪崩效应导致网关失去处理、自恢复的能力。
3、安全性
- API网关直接暴露在公网,对于恶意IP,API网关服务要有能力对恶意IP进行访问限制。
- API网关要防止业务日志从API网关数据泄露。
二、基于SpringBoot的API网关架构
2.1、概要架构图
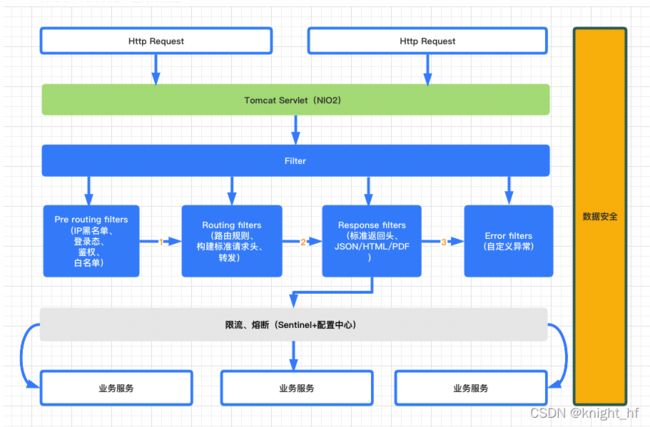
2.2、架构说明
- 基础能力
按照DDD思想,划分为Pre routing filters、Routing filters、Response filters、Error filters四个微观领域,分别对应转发前处理、转发处理、返回处理、错误处理四个方面。
- 高性能
为了满足网关的基础能力,同时保证网关具有一定的高性能,基于NIO2(AIO)模式来构建基础架构。
- 高可用
为了保证网关具有高可用性,使用Alibaba Sentlnel进行限流、熔断降级提高网关服务的健壮性。
- 安全性
为了能够对黑名单IP进行拒绝访问,提供灵活的配置能力。
业务数据日志默认不在网关中日志中记录
2.3、实现说明
2.3.1 基础能力
Pre routing filters
使用Java Filter来实现Pre routing filters相关能力,包括IP黑名单、登录态、鉴权、白名单等过滤器实现。下面是IP黑名单过滤器的示例,可参考:
/**
* 黑名单IP过滤器
*/
@Component
@WebFilter(urlPatterns = "/*", filterName = "backListFilter")
@Slf4j
public class BackListFilter implements Filter, Ordered {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
}
@Override
public void destroy() {
Filter.super.destroy();
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
String remoteAddress="";
String blackList="";
if(blackList.contains(remoteAddress)){
HttpServletResponse response = (HttpServletResponse) servletResponse;
response.setStatus(HttpStatus.FORBIDDEN.value());
PrintWriter out = response.getWriter();
out.write("request refused");
return;
}
// 继续进行后续流程处理
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public int getOrder() {
// 设置Filter执行顺序(越小优先级越高)
return 0;
}Routing filters
转发层主要提供路由解析、标准Header构建、转发能力。
(1)路由解析因为跟具体的业务场景有关,这里不展开描述。简单实用的方式,比如可以根据业务服务在网关侧注册的转发规则进行转发。
(2)HTTP转发组件需要支持GET、POST等常见类型的请求,可以根据实际场景或个人习惯选择一些优秀成熟的HTTP工具,我们此处选择Apache HttpClient作为Http工具。为了提高API网关的转发性能,同时提高网关的可用性,需要对HttpClient进行连接池、超时时间、重试机制、默认Header等配置。参照如下:
/**
* RestTemplate配置类
*/
@Configuration
public class RestTemplateConfig {
/**
* 从连池中获取连接的超时时间
*/
@Value("${httpclient.connection-request-timeout}")
private Integer connectionRequestTimeout;
/**
* 建立TCP连接超时时间
*/
@Value("${httpclient.connect-timeout}")
private Integer connectTimeout;
/**
* TCP连接Socket数据返回超时时间
*/
@Value("${httpclient.socket-timeout}")
private Integer socketTimeout;
/**
* 创建RestTemplate Bean
* @return
*/
@Bean
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate(httpRequestFactory());
return restTemplate;
}
/**
* 通过HttpClient创建Http请求工厂
* @return
*/
@Bean
public ClientHttpRequestFactory httpRequestFactory() {
HttpComponentsClientHttpRequestFactory clientHttpRequestFactory = new HttpComponentsClientHttpRequestFactory(httpClient());
// 缓冲请求数据,默认值是true。通过POST或者PUT大量发送数据时,建议将此属性更改为false,以免耗尽内存。
clientHttpRequestFactory.setBufferRequestBody(false);
return clientHttpRequestFactory;
}
/**
* 创建 HttpClient Bean
* @return
*/
@Bean
public HttpClient httpClient() {
Registry registry = RegistryBuilder.create()
.register("http", PlainConnectionSocketFactory.getSocketFactory())
.register("https", SSLConnectionSocketFactory.getSocketFactory())
.build();
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager(registry);
// 1、连接管理
// 设置整个连接池最大连接数 根据自己的场景决定
connectionManager.setMaxTotal(200);
// 路由是对maxTotal的细分
connectionManager.setDefaultMaxPerRoute(100);
// 2、请求相关配置
RequestConfig requestConfig = RequestConfig.custom()
// 从连接池中获取连接的超时时间,超过该时间未拿到可用连接,会抛出org.apache.http.conn.ConnectionPoolTimeoutException:
// Timeout waiting for connection from pool
.setConnectionRequestTimeout(connectionRequestTimeout)
// 连接上服务器(握手成功)的时间,超出该时间抛出connect timeout
.setConnectTimeout(connectTimeout)
// 服务器返回数据(response)的时间,超过该时间抛出read timeout
.setSocketTimeout(socketTimeout)
.build();
// 3、重试机制
HttpRequestRetryHandler httpRequestRetryHandler = new HttpRequestRetryHandler() {
@Override
public boolean retryRequest(IOException e, int retryTimes, HttpContext httpContext) {
// 重试次数最多2次
if(retryTimes > CommonConstant.HTTPCLIENT_RETRY_TIMES){
return false;
}
// 请求发生一些IO类型的异常时,进行重试
if (e instanceof UnknownHostException || e instanceof ConnectTimeoutException
|| !(e instanceof SSLException) || e instanceof NoHttpResponseException) {
return true;
}
return false;
}
};
// 4、设置默认的Header
List headers = new ArrayList<>();
headers.add(new BasicHeader("Accept-Encoding","gzip,deflate"));
headers.add(new BasicHeader("Connection", "Keep-Alive"));
// 创建httpclient对象
return HttpClientBuilder.create()
.setDefaultRequestConfig(requestConfig)
.setConnectionManager(connectionManager)
.setRetryHandler(httpRequestRetryHandler)
.setDefaultHeaders(headers)
.build();
}
} 3)转发时,因为业务服务返回的数据格式不确定(可能是JSON、HTML、PDF等各种形式),所以为了保证转发的通用性,使用输入流进行数据接收。因为是基于Srping架构的,我们选择org.springframework.core.io.Resource进行数据接收。
restTemplate.exchange(forwardUrl,httpMethod,httpEntity,org.springframework.core.io.Resource.class);Response filters
(1)API网关大部分场景返回的数据结构是JSON类型的数据,但一些特殊的场景需要支持HTML、PDF等格式的数据呈现,这种场景下,就可以根据业务接口Response中的"Content-Type"来统一进行处分处理。
(2)另外如果需要对外提供标准的HTTP Header等信息,也可以在此领域进行处理。
Error filters
API网关核心的使用场景是将业务接口暴露给各种客户端使用,因此标准、统一的错误就显得尤为重要。因为是基于Srping架构的,所以可以结合Spring框架的能力加上自定义异常来实现标准化的异常处理。具体可参照代码:
/**
* 鉴权自定义异常
*/
public class AuthResultException extends RuntimeException {
private static final long serialVersionUID = 1L;
/**
* 设置异常对应的Http状态码,业务错误码,业务提示信息,可指定是否生成详细的错误信息
*/
public AuthResultException(ResultCode resultCode) {
super(resultCode.getMessage());
}
}
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
@ResponseBody
public void handleException(HttpServletRequest request, HttpServletResponse response,Exception e) {
// 鉴权自定义异常,返回401
if(e instanceof AuthResultException) {
result.setErrcode(110002);
result.setMessage("未登录或用户不存在");
response.setStatus(HttpStatus.UNAUTHORIZED.value());
}
}
}2.3.2 高性能
- JAVA的IO方式包括BIO、NIO、NIO2(JDK1.7后新引入,主要实现AIO),为了方便理解,先对这几种IO进行简单的比较。
| 差异 | BIO | NIO | NIO2(AIO) |
|---|---|---|---|
| 1 | 面向流 | 面向通道、缓冲区、选择器(Selectors) | 面向通道、缓冲区、选择器(Selectors) |
| 2 | 阻塞同步IO | 非阻塞同步IO | 非阻塞异步IO |
| 3 | 用户线程直接参与读写,整个数据读写过冲中用户线程都处于阻塞状态 | 用户调用读写方法时是不阻塞的,立刻返回。但需要用户进程来检查IO状态,如果发现有可以操作的IO,那么用户进行还是会阻塞等待内核复制数据到用户进程,它与BIO的主要区别是BIO是全程处于阻塞等待状态。 | 内核线程负责数据读写,内核线程读写数据处于堵塞状态时,不影响用户线程 |
- API网关作为一个基础服务,在客户端与业务服务中间起到了承上启下的作用的,因此我们需要尽量的保证网关的高性能。
我们API网关本质上是基于Tomcat Servelt架构的,Tomcat7.x以上实现了Http11Nio2协议,但默认协议仍然使用的是Http11Nio的协议的,官方文档推荐高版本的Tomcat使用Http11Nio2协议。因此我们将API网关默认的IO协议修改成了Http11Nio2协议,以实现在有限的部署资源的情况下,提高API网关的吞吐量。设置Http11Nio2协议可以参照如下代码。
/**
* 配置tomcat使用Nio2作为IO协议
*/
@Configuration
public class TomcatCustomizer implements WebServerFactoryCustomizer {
@Override
public void customize(ConfigurableServletWebServerFactory factory) {
((TomcatServletWebServerFactory)factory).setProtocol("org.apache.coyote.http11.Http11Nio2Protocol");
}
} - 压测验证
我们在相同的软、硬配置下,使用Http11Nio与Http11Nio2协议分别对单节点进行压测,从服务的吞吐量结果来看,Http11Nio2协议下,吞吐量提高了至少20%以上,特别是并发线程越高的场景下,Http11Nio协议下,请求吞吐量下降很明显。从监控数据来看,在并发越高的场景,Http11Nio协议下CPU的平均使用率更高,基本也说明了在NIO的模式在高并发的场景下IO阻塞是很明显的。
另外我们也发现,Tomcat自身最大的处理线程如果设置的比较大,服务本身的吞吐量也出现了明显的下降,通过对监控的分析,这种情况应该是线程太多导致CPU将大量的时间花费在上下文切换上导致的。
2.3.3 高可用
API网关作为整个微服务体系中的重要的基础服务,我们对API网关在可用性方面的目标是:
- 即使其他业务服务都挂了,网关服务都应该尽可能保证可用;
- 即使网关服务不可用了,在业务服务恢复后,网关也要能够快速自恢复。
要达到以上的目标,API网关必须拥有限流、熔断降级等方面的能力。目前限流熔断的组件主要有SpringCloud Hystrix,Alibaba Sentinel,经过对两者的比较,同时结合公司的技术背景,我们最终选择使用Alibaba Sentinel组件来实现限流、熔断降级。
因为在实现中,我们是基于公司自研的配置中心+Sentinel来实现动态配置的,所以此处不直接将代码贴出来。但是这里有一篇以Apollo为配置中心,同时结合Sentinel的文章,实现思路清晰,讲解详细,需要的同学可以参照。Apollo+Sentinel示例:https://anilople.github.io/Sentinel/#/zh/README
2.3.4 安全性
- API网关作为业务服务暴露数据最重要的途径之一,网关层需要有能力在出现恶意请求时快速切断外部请求以保证公司数据安全的能力。除了借助集团安全风控的整体能力,目前网关层提供了IP黑名单配置能力,以方便快速切断恶意IP的请求。
- API网关作为客户端请求的第一站,在日常排查问题中往往希望网关层能够提供尽可能多日志以方便排查问题,从问题排查的角度提出这个想法无可厚非。但如果考虑到数据安全性,网关层是不应该过多的打印出业务服务的业务数据日志的,因为网关层绝大数情况下是不关注也不了解业务的,如果将业务服务的数据都打印出来,则可能在网关层造成业务数据泄漏。因此结合数据安全性和排查问题的便捷性两个诉求,默认情况下不支持业务数据日志的记录,但在一些特殊的时候可以通过开关打开日志的记录。
- 后面会结合限流组件的能力,提供对特定IP在自动限流的能力,以实现更智能的安全校验。
三、总结
1、API网关作为微服务体系中重要的基础服务,在设计的时候,需要重点考虑可维护性,因此在微观实现层面可以借鉴DDD的思想,将整个流程分为预处理、转发、返回、异常四个领域来实现结构清晰, 易于扩展,提高了可维护性。
2、API网关本身不涉及或者很少涉及业务逻辑,其更多关注的是IO的问题,因此在设计API网关时,需要对BIO、NIO、NIO2、AIO、IO多通道复用等概念有比较好的理解,这样才能结合实际场景选择合适的技术方案。我们对IO的核心概念有了比较好的理解时,你可能也就大概知道了Zuul1.x与Zuul2.x和Spring Cloud GateWay的核心区别,同时对像Redis这样的中间件如何在单线程的情况下做到高性能有了一些理解。
3、准确理解限流、熔断、降级的概念,可以更好的帮助我们选择合适的技术方案来实现高可用。
限流、熔断针对的主体不一样,其中
限流是相对于调用方而言的,当调用方在一段时间内请求量超过某个阀值,则对调用方进行请求限速处理;
熔断是相对于服务方而言的,当依赖的服务出现异常时,如果不进行任何处理,API网关会因为雪崩被某一个业务服务拖垮,进而导致整个API网关时去响应。这种情况下,为了保证API网关的可用性,需要对异常的服务实行快速失败的策略,这种策略就是熔断。
降级是一种结果,对客户端请求限流、或者对依赖方进行熔断的结果都是一种降级。