前端面试题型汇总(适合社招两-三年水平)
【本文内容适合做过项目,有实操经验的社招同学,如果需要了解基础面经知识的同学,可以参考我之前写的文章:前端面试题型汇总(适合应届/社招1年水平)】
随着社区流行技术的更新迭代以及工作经验的增加,对于前端开发,我有了新的理解。
接下来总结工作中常见的问题以及面试中实际遇到的问题,整理出面经汇总。
目录
原生JS
ajax,fetch 和 axios
手撕代码题
React
关于fiber结构
React Hooks原理
React Router (V6)
状态管理库
React 与 Vue 的区别
React和Vue2.x、3.x Diff算法的区别
手写常用Hooks
Vue
vue3与react hooks对比
vue的keep-alive原理
网络协议
关于http协议
CDN原理
CDN回源与文件预热
浏览器
各控制面板操作
前端异常监控
打包工具
Webpack
Webpack的构建流程
Webpack Loader
Webpack Plugin
Webpack 热更新
Webpack Proxy 请求代理
Webpack 配置性能优化
Module Federation
Vite
微前端
微前端 - iframe方案
微前端 - qiankun 方案
微前端 - YY EMP方案
微前端 - 各种方案对比
其他
前端模块化
CommonJS
AMD
CMD
ES Modules
关于pnpm
关于workspaces
关于gitlab-ci.yml
2022/12/06 持续更新中... ...
原生JS
ajax,fetch 和 axios
- ajax 通过XMLHTTPRequest对象实现了 局部数据刷新,本身是针对MVC的编程,多用于jquery项目,不符合现在前端MVVM的浪潮,而且嵌套请求,会出现回调地狱问题
- fetch是浏览器原生支持的 一个底层的 api ,解决了回调地狱的问题 , 但浏览器兼容性差(如何提高兼容性)(可以看做ES6下新版本的ajax,不是ajax的进一步封装,而是新增的原生支持的api,没有使用XMLHttpRequest对象)
- axios 是一个可以开箱即用的请求库,为MVVM框架而生 (vue/react),它的本质还是 ajax,基于 Promise 进行封装,既解决回调地狱问题,又能很好地支持各个浏览器。
手写实现Ajax
function fun() { //1.创建核心对象 var xmlhttp; if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest(); } else {// code for IE6, IE5 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } //2. 建立连接 xmlhttp.open("GET", "ajaxServlet?username=tom", true); //3.发送请求 xmlhttp.send(); //4.接受并处理来自服务器的响应结果 //获取方式 :xmlhttp.responseText //当xmlhttp对象的就绪状态改变时,触发事件onreadystatechange。 xmlhttp.onreadystatechange = function () { //判断readyState就绪状态是否为4,判断status响应状态码是否为200 if (xmlhttp.readyState == 4 && xmlhttp.status == 200) { //获取服务器的响应结果 var responseText = xmlhttp.responseText; alert(responseText); } } }
fetch 优点 缺点 浏览器级别原生支持的 api 不支持文件上传进度监测 原生支持 promise api 不支持请求中止 语法简洁 符合 ES 标准规范 默认不带 cookie 已经成为 w3c 规范 往往需要自己封装一层来使用 浏览器兼容性差,需要引入polyfill
axios 优点 缺点 开箱即用,使用快捷 暂无 支持 浏览器 和 node.js 发送请求 前后端发请求 支持 promise 语法 支持中断请求 支持并发请求 支持拦截请求 支持请求进度检测 支持客户端防止 csrf
手撕代码题
手写JS代码
手写实现Promise
基础算法相关实现
React
关于fiber结构
fiber是一种数据结构,也是一个执行单元。
Fiber = { tag, // 标记不同的组件类型 key, // ReactElement里面的key elementType, // ReactElement.type,也就是我们调用`createElement`的第一个参数 type, // 一般是`function`或者`class` stateNode, // 在浏览器环境,就是DOM节点 return, // 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回 child, // 单链表树结构,指向自己的第一个子节点 sibling, // 指向自己的兄弟结构,兄弟节点的return指向同一个父节点 index, ref, // ref属性 pendingProps, // 即将更新的props memoizedProps, // 更新props memoizedState, // 当前状态 dependencies, // 一个列表,存放这个Fiber依赖的context flags, // Effect,用来记录当前fiber的tag,插入、删除、更新的状态 subtreeFlags, deletions, updateQueue, // 该Fiber对应的组件产生的Update会存放在这个队列里面 nextEffect, // 单链表用来快速查找下一下side effect firstEffect, // 自述中第一个side effect lastEffect, // 子树中最后一个side effect lanes, // 当前Fiber更新的优先级 childLanes, // 在Fiber树更新的过程中,每个Fiber都会有一个跟其对应的Fiber // 我们称他为`current <==> workInProgress` // 在渲染完成之后他们会交换位置 alternate, // 用来描述当前Fiber和他子树的`Bitfield` // 共存的模式表示这个子树是否默认是异步渲染的 // Fiber被创建的时候他会继承父Fiber // 其他的标识也可以在创建的时候被设置 // 但是在创建之后不应该再被修改,特别是他的子Fiber创建之前 mode, // 其余为调试相关的,收集每个Fiber和子树渲染时间的 //... }fiber之前,react是通过使用递归去遍历虚拟dom树,找出不同去更新dom,这样就会造成执行栈太深,且无法中途中断的问题,而由于浏览器的渲染线程和js线程的执行是互斥的,如果 js执行的时候,占用时间太久就会引起卡顿。
一般来说浏览器的刷新的频率是60帧每秒,也就是16.6ms刷新一帧,在这一帧中浏览器干了很多事情,比如处理输入事件,处理定时器,页面的滚动,窗口大小的调整,处理RFA(requestAnimationFrame, 浏览器原生API,注册下一帧绘制前的回调),布局和绘制等。
当以上工作做完后,浏览器通常会有一定的剩余时间,而react fiber正是利用这一空闲时间和fiber树的链表形式的数据结构, 实现了在浏览器每一帧的空闲时间去执行处理任务。当在浏览器的这一帧内还有空余时间,那么就去执行fiber,如果执行完一个fiber后,还有时间就继续执行。如果执行完一个任务会,已经没有剩余时间了,那么就让出执行权,同时通过requestIdleCallback(fn, {timeout: 1000})这个API来再注册下一帧空闲时间的回调,来继续紧接着上次的任务继续执行,这样就实现了任务的可中断。
requestIdleCallback这个API是Chrome自己实现的一个api,用来注册在下一帧空闲时间执行的回调函数。这个方法接收两个入参,第一个是要注册的回调函数,这个回调函数会接收一个timeRemaing的方法,这个方法返回当前帧剩余的空闲时间和有没有超时,第二个入参是超时时间,用来告诉浏览器,在这个超时时间到期的时候,不管当前还有没有空闲时间都必须要执行当前的执行任务。(react 没有使用requestIdleCallback这个API,而是自己实现了一个类似的方法。)在react中,定义了fiber节点的类型,包括根fiber,原生元素fiber,文本节点fiber,类组件fiber,函数组件fiber类型,同时也要定义fiber的effectTag类型,也就是表示当前fiber是新增,更新还是删除的类型。
fiber 架构就分为了 schdule(调度)、reconcile(vdom 转 fiber)、commit(更新到 dom)三个阶段。
参考:React 源码学习
React Hooks原理
Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性
至于为什么引入hook,官方给出的动机是解决长时间使用和维护react过程中常遇到的问题
- 难以重用和共享组件中的与状态相关的逻辑
- 逻辑复杂的组件难以开发与维护,当我们的组件需要处理多个互不相关的 local state 时,每个生命周期函数中可能会包含着各种互不相关的逻辑在里面
- 类组件中的this增加学习成本,类组件在基于现有工具的优化上存在些许问题
- 由于业务变动,函数组件不得不改为类组件等
- 放弃面向对象编程,拥抱函数式编程
React 的 hooks 是在 fiber 之后出现的特性,所以很多人误以为 hooks 是必须依赖 fiber 才能实现的,其实并不是,它们俩没啥必然联系,React只是把 hook 存在其 fiber 节点上(而preact 就是把 hook 链表放在了 vdom 上)
hooks 的实现原理其实不复杂,就是在某个上下文中存放一个链表,然后 hooks api 从链表不同的元素上访问对应的数据来完成各自的逻辑。这个上下文可以是 vdom、fiber 甚至是全局变量,在react hooks中是把这个hooks链表存在了其fiber节点上。
推荐阅读:react怎么实现hooks
React Router (V6)
与V5版本的对比
- 1、首先是注册路由的时候v5的Switch改为了Routes
v5: import {Route, Switch} from 'react-router-dom' //引入react-router{/* 注册路由(编写路由链接) */}v6: import {Route, Routes } from 'react-router-dom' //引入react-router...... ...... {/* 注册路由(编写路由链接) */}...... ......
- 2、v6不再支持用Route标签包裹子组件,可以直接使用element属性 也不需要
v5: import {Route, Switch} from 'react-router-dom' //引入react-router{/* 注册路由(编写路由链接) */}v6: import {Route, Routes } from 'react-router-dom' //引入react-router} />
- 3、v6中也不需要exact属性
exact在v5中起到的作用是精准匹配的作用,如果不写的话,
那么 path='/'也会匹配'/about'和'/home'导致的结果就是下面两个路由就没用了
在v6中由于v6 内部算法改变,它默认就是匹配完整路径。
- 4、v6 中,Route 先后顺序不再重要,它能够自动找出最优匹配路径
- 5、在v6中移除了NavLink中的actionclassName的这个属性,actionclassName这个属性是点击对应元素改变为对应的样式,在v6中可以使用三元运算符的方式实现这个功能
navData.isActive?class.active : ""}
- 6、在v6中将Redirect改为Navigate它当匹配不到路由时,需要使用Redirect做重定向,跳转到我们定义的组件(页面)中
v5:v6: } />
- 7、v6 嵌套路由改为相对匹配,不再像 v5 那样必须提供完整路径。
- 8、新增Outelt组件
此组件是一个占位符,告诉 React Router 嵌套的内容应该放到哪里。
子路由
- 9、v6 用useNavigate实现编程式导航,不再使用useHistory
- 10、v6 目前没有prompt组件阻止不期望的导航。
如果在 v6 中要实现相应的功能,必须自己想办法,这可能是目前 v5 唯一的优势。
- 11、更小的体积 8kb
由于代码几乎重构,v6 版本的代码压缩后体积从 20kb 缩小到 8kb。
状态管理库
常见的有redux,react redux,mobx,dva
vue 和 angular 为什么没有像 react 这样纷杂的这么多种状态管理工具?
vue 和 angular 的数据都是响应式的,当数据变更时,什么时候刷新视图,刷新的粒度怎么样,开发者无需关心,这一切交给框架本身去做就好了。所以 vue 基本用 vuex 就够了(最近又出了个Pinia),angular 的数据管理交给 service 也就够了。
而 react 不一样,react 认为 UI 本身只是一个函数(UI = fn(state)),状态怎么变更,什么时候变更,react把这些权利完全交给了开发者。这也就给各种状态管理发挥和想象的空间。造成 react 社区状态管理工具百家争鸣的现象。
Redux
- 核心原理:
reducer纯函数- 使用
Context API- 遵循的是函数式(如函数式编程)的风格
- 单一的全局存储来保存应用程序的所有状态
- 更改只通过动作发生
bundle size小(redux+react-redux约为3kb)要定义 action、reducer,还要通过dispatch来触发更新,模板代码太多。
缺乏计算属性的功能
MobX
- 核心原理:ES6 proxy (可以理解为vue的双向数据绑定)
- MobX是基于观察者/可观察模式的。
- 以真正的 "反应式 "方式管理状态,因此当你修改一个值时,任何使用该值的组件都会自动重新渲染。
- 不需要任何动作或者reducers,只需修改你的状态,应用程序就会反映出来。
- 要求使用ES6代理,意味着不支持IE11及以下版本。
- 类的 get 方法是 Computed,支持计算属性
详细介绍可以看我之前的文章:redux,react-redux,redux-saga,dva的区别与联系
这里主要介绍社区最近流行起来新的状态管理库:Zustand
状态即数据,对于一个原生的 Web 应用来说,某一时刻页面展示的结构和样式取决于此时的状态,状态可能会由于用户交互动作发生变化。对于复杂的 Web 应用来说,一个状态可能影响到页面数十个部分,我们就需要对状态的维护更新机制进行设计,将状态的维护从页面进行解耦,独立到全局来进行,则将这种状态称之为全局状态。显然,对于局部状态来说,页面局部可以完成自治,而对于全局状态来说,则需要一个全局中心化的“数据库”来进行管理。
现在,我们可以知道,状态管理需要提供一个类似中心化的“数据库”,同时对于状态要提供更新机制,而状态可以被多个部分依赖,状态更新的同时依赖方可以及时获取到最新状态。这不就是软件架构中典型的发布/订阅模式吗?所以,先来看看 redux 和 zustand 两者提供的 API,大致就能理解其核心实现的模型。
// Redux createStore(reducer, [preloadedState], [enhancer]) // Store getState() subscribe(listener) dispatch(action) // zustand createStore() // Store getState() subscribe() setState()由此可见,两者提供的核心 API 是非常相近的,从 API 命名的角度来看,其核心实现无疑是基于发布/订阅模式。
两者都有一个
createStore()API 来创建一个中心化的数据存储区,同时创建的 store 实例均会暴露出主动获取状态的 APIgetState(),订阅状态更新的 APIsubscribe(),以及更新状态的 APIdispatch()和setState(),当然 redux 还引入了一个reducer的概念和 API。两者的核心库均只有 1kb 大小,而 zustand 更小,这是因为 zustand 实现更为简单一些,其差异主要集中在状态更新机制上,其次是状态订阅机制。
分场景挑选合适的状态管理工具:
- 如果是小型的项目且没有多少状态需要共享,那么不需要状态管理,react 本身的 props 或者 context 就能实现需求
- 如果需要手动控制状态的更新,单向数据流是合适的选择,例如:redux,zustand
- 如果需要简单的自动更新,双向绑定的状态管理是不二之选,例如:mobx,valtio
- 如果是两个或多个组件之间简单的数据共享,那么原子化或许是合适的选择:,例如:jotai,recoil
- 如果状态有复杂数据流的处理,请用 rxjs
- 如果管理的是复杂的业务状态,那么可以使用有限状态机做状态的跳转管理,例如:xstate
- 如果有在非react上下文订阅、操作状态的需求,那么 jotai、recoil 等工具不是好的选择。
参考文章:react状态管理选哪个
React 与 Vue 的区别
共同点
- 都使用虚拟dom。
- 都是数据驱动视图。
- 把注意力集中保持在核心库,而将其他功能如路由和全局状态管理交给相关的库。(vue-router、vuex、react-router、redux等等)
区别
- 节点的更新
react: 在react中如果某个组件的状态发生改变,react会把此组件以及此组件的所有后代组件重新渲染,不过重新渲染并不代表会全部丢弃上一次的渲染结果,react中间还是会通过diff去比较两次的虚拟dom最后patch到真实的dom上。虽然如此,如果组件树过大,diff其实还是会有一部分的开销,因为diff的过程依然是比较以此组件为根的整颗组件树。react提供给我们的解决方案是
shouldComponentUpdate,以此函数的返回结果来判断是否需要执行后面的diff、patch与update。再实际的开发过程中我们常常会用pureComponent来帮助我们做这一层逻辑判断,但需要注意的是pureComponent的shouldComponentUpdate也只是浅比较,假设比较的类型是object,如果object仅属性发生变化,但是其引用没发生变化那么shouldComponentUpdate会认为两者之间没有任何变化。vue: vue的响应式使用的是
Object.definePropertyapi,并且由于在getter中实现了依赖收集,所以不会像react一样去比较整颗组件树,而是更加细粒度的去更新状态有变化的组件,同时defineProperty也不存在像shouldComponentUpdate中比较引用的问题。vue的更新要比react粒度要更细也更加不用去人为的关心,虽然react可以通过
shouldComponentUpdate实现同样的效果,然而如果state的层级结构比较深那么相应的手动去优化这部分代码也会更加费力,所以在react中我们需要尽量保证整体结构的扁平,去让pureComponent帮助我们自动的对此作出优化。
- 组件的书写方式
react推崇函数式编程,推荐使用JSX这种类式的写法,api很少,而Vue主张声明式的模板写法,通过传入各种options。所以react更容易结合ts一起写,而Vue的学习门槛则更低。
- 组件引用方式
react中render函数是支持闭包特性的,所以我们import的组件在render中可以直接调用。但是在Vue中,由于模板中使用的数据都必须挂在 this 上进行一次中转,所以我们import 一个组件完了之后,还需要在 components 中再声明下。
React和Vue2.x、3.x Diff算法的区别
- 传统Diff算法
处理方案: 循环递归每一个节点传统diff
如上所示, 左侧树a节点依次进行如下对比:
a->e、a->d、a->b、a->c、a->a之后左侧树其它节点b、c、d、e亦是与右侧树每个节点对比, 算法复杂度能达到O(n^2)
查找完差异后还需计算最小转换方式,这其中的原理我没仔细去看,最终达到的算法复杂度是O(n^3)
将两颗树中所有的节点一一对比需要O(n²)的复杂度,在对比过程中发现旧节点在新的树中未找到,那么就需要把旧节点删除,删除一棵树的一个节点(找到一个合适的节点放到被删除的位置)的时间复杂度为O(n),同理添加新节点的复杂度也是O(n),合起来diff两个树的复杂度就是O(n³)
优化的Diff算法
vue和react的虚拟DOM的diff算法大致相同,其核心是基于两个简单的假设:
- 两个相同的组件产生类似的DOM结构,不同的组件产生不同的DOM结构
- 同一层级的一组节点,他们可以通过唯一的id进行区分
(优化的)diff三点策略:
- web UI中DOM节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类型的两个组件将会生成相似的树形结构,拥有不同类型的两个组件将会生成不同树形结构。
- 对于同一层级的一组自节点,他们可以通过唯一id进行区分。
即, 比较只会在同层级进行, 不会跨层级比较
- React优化Diff算法
基于以上优化的diff三点策略,react分别进行以下算法优化
- tree diff
- component diff
- element diff
tree diff
react对树的算法进行了分层比较。react 通过 updateDepth对Virtual Dom树进行层级控制,只会对相同颜色框内的节点进行比较,即同一个父节点下的所有子节点。当发现节点不存在,则该节点和其子节点都会被删除。这样是需要遍历一次dom树,就完成了整个dom树的对比
分层比较 img
如果是跨层级的移动操作,如图
跨层级操作 img
当根结点发现A消失了,会删除掉A以及他的子节点。当发现D上多了一个A节点,会创建A(包括其子节点)节点作为子节点
所以:当进行跨层级的移动操作,react并不是简单的进行移动,而是进行了删除和创建的操作,这会影响到react性能。所以要尽量避免跨层级的操作。(例如:控制display来达到显示和隐藏,而不是真的添加和删除dom)
component diff
- 如果是同类型的组件,则直接对比virtual Dom tree
- 如果不是同类型的组件,会直接替换掉组件下的所有子组件
- 如果类型相同,但是可能virtual DOM 没有变化,这种情况下我们可以使用shouldComponentUpdate() 来判断是否需要进行diff
component vs img
如果组件D和组件G,如果类型不同,但是结构类似。这种情况下,因为类型不同,所以react会删除D,创建G。所以我们可以使用shouldComponentUpdate()返回false不进行diff。
针对react15, 16出了新的生命周期
所以:component diff 主要是使用shouldComponentUpdate() 来进行优化
element diff
element diff 涉及三种操作:插入,移动,删除
不使用key的情况 img
不使用key的话,react对新老集合对比,发现新集合中B不等于老集合中的A,于是删除了A,创建了B,依此类推直到删除了老集合中的D,创建了C于新集合。=
酱紫会产生渲染性能瓶颈,于是react允许添加key进行区分
使用key的情况 img
react首先对新集合进行遍历,for( name in nextChildren),通过唯一key来判断老集合中是否存在相同的节点,如果没有的话创建,如果有的话,if (preChild === nextChild ) 进行移动操作
移动优化
在移动前,会将节点在新集合中的位置和在老集合中lastIndex进行比较,如果if (child._mountIndex < lastIndex) 进行移动操作,否则不进行移动操作。这是一种顺序移动优化。只有在新集合的位置 小于 在老集合中的位置 才进行移动。如果遍历的过程中,发现在新集合中没有,但是在老集合中的节点,会进行删除操作
所以:element diff 通过唯一key 进行diff 优化。
总结:
1.react中尽量减少跨层级的操作。 2.可以使用shouldComponentUpdate() 来避免react重复渲染。 3.添加唯一key,减少不必要的重渲染
- Vue2.x 优化Diff
vue2.0加入了virtual dom,和react拥有相同的 diff 优化原则 vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。
差异就在于, diff的过程就是调用patch函数,就像打补丁一样修改真实dom
- patchVnode
- updateChildren
updateChildren是vue diff的核心
过程可以概括为:oldCh和newCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和newCh至少有一个已经遍历完了,就会结束比较
- Vue 2.x vs Vue 3.x
Vue3.x借鉴了 ivi算法和 inferno算法。在创建VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。(实际的实现可以结合Vue3.x源码看)
原文链接:聊一聊Diff算法(React、Vue2.x、Vue3.x) - 知乎
手写常用Hooks
useInterval
const useInterval = (callback: any, delay: number) => { const fn: any = useRef() useEffect(() => { fn.current = callback },[callback]) useEffect(() => { const fnCurrent = () => { fn.current() } delay && fnCurrent () if (delay) { const id = setInterval(fnCurrent , delay) return () => { clearInterval(id) } } }, [delay]) }useCountDown
const useCountDown = (remain = 0) => { const [count, setCount] = useState(remain) const format = (num: number) => { return num < 10 ? '0' + num : String(num) } useInterval( () => {setCount(count - 1)}, count > 0 && remain ? 1000 : 0, ) useEffect(() => { if (count <= 0) { console.log('@@@倒计时结束') } }, [count]) const info = useMemo(() => { const hour = format(parseInt(String(count / 3600))) const minute = format(parseInt(String((count % 3600) / 60))) const second = format(parseInt(String(count % 60))) return {hour, minute, second} }, [count]) return [info] } // 使用 const PageNode = () => { const [{hour,minute,second}] = useCountDown(10) return (自定义倒计时 {hour}:{minute}:{second}) }useDebounce
const useDebounce = (func: () => void, wait: number) => { const timer = useRef(null) const fn = useRef (func) useEffect(() => { fn.current = func }, [func]) return useCallback(() => { if (!wait) { return } if (timer.current) { // 有正在倒计时的回调则取消 clearTimeout(timer.current) timer.current = null } timer.current = setTimeout(() => { func() }, wait) }, [func, wait]) } // 使用 const funcTest = useDebounce(() => { console.log('@@@@useDebounce输出') }, 1000) useThrottle
const useThrottle = (func: () => void, wait: number) => { const timer = useRef(null) const fn = useRef (func) useEffect(() => { fn.current = func }, [func]) return useCallback(() => { if (!wait) { return } if (!timer.current) { // 没有正在倒计时的回调则设置一个 timer.current = setTimeout(() => { func() clearTimeout(timer.current) timer.current = null }, wait) } }, [func, wait]) } // 使用 const funcTest = useDebounce(() => { console.log('@@@@useThrottle输出') }, 1000)
Vue
vue3与react hooks对比
vue的keep-alive原理
Vue内部将DOM节点抽象成了一个个的VNode节点,所以keep-alive的缓存也是基于VNode节点的而不是直接存储DOM结构。
将需要缓存的VNode节点保存在this.cache中, 在render时,如果VNode的name符合在缓存条件(可以用include以及exclude控制),则会从this.cache中取出之前缓存的VNode实例进行渲染。
type VNodeCache = { [key: string]: ?VNode }; const patternTypes: Array= [String, RegExp] /* 获取组件名称 */ function getComponentName (opts: ?VNodeComponentOptions): ?string { return opts && (opts.Ctor.options.name || opts.tag) } /* 检测name是否匹配 */ function matches (pattern: string | RegExp, name: string): boolean { if (typeof pattern === 'string') { /* 字符串情况,如a,b,c */ return pattern.split(',').indexOf(name) > -1 } else if (isRegExp(pattern)) { /* 正则 */ return pattern.test(name) } /* istanbul ignore next */ return false } /* 修正cache */ function pruneCache (cache: VNodeCache, current: VNode, filter: Function) { for (const key in cache) { /* 取出cache中的vnode */ const cachedNode: ?VNode = cache[key] if (cachedNode) { const name: ?string = getComponentName(cachedNode.componentOptions) /* name不符合filter条件的,同时不是目前渲染的vnode时,销毁vnode对应的组件实例(Vue实例),并从cache中移除 */ if (name && !filter(name)) { if (cachedNode !== current) { pruneCacheEntry(cachedNode) } cache[key] = null } } } } /* 销毁vnode对应的组件实例(Vue实例) */ function pruneCacheEntry (vnode: ?VNode) { if (vnode) { vnode.componentInstance.$destroy() } } /* keep-alive组件 */ export default { name: 'keep-alive', /* 抽象组件 */ abstract: true, props: { include: patternTypes, exclude: patternTypes }, created () { /* 缓存对象 */ this.cache = Object.create(null) }, /* destroyed钩子中销毁所有cache中的组件实例 */ destroyed () { for (const key in this.cache) { pruneCacheEntry(this.cache[key]) } }, watch: { /* 监视include以及exclude,在被修改的时候对cache进行修正 */ include (val: string | RegExp) { pruneCache(this.cache, this._vnode, name => matches(val, name)) }, exclude (val: string | RegExp) { pruneCache(this.cache, this._vnode, name => !matches(val, name)) } }, render () { /* 得到slot插槽中的第一个组件 */ const vnode: VNode = getFirstComponentChild(this.$slots.default) const componentOptions: ?VNodeComponentOptions = vnode && vnode.componentOptions if (componentOptions) { // check pattern /* 获取组件名称,优先获取组件的name字段,否则是组件的tag */ const name: ?string = getComponentName(componentOptions) /* name不在inlcude中或者在exlude中则直接返回vnode(没有取缓存) */ if (name && ( (this.include && !matches(this.include, name)) || (this.exclude && matches(this.exclude, name)) )) { return vnode } const key: ?string = vnode.key == null // same constructor may get registered as different local components // so cid alone is not enough (#3269) ? componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '') : vnode.key /* 如果已经做过缓存了则直接从缓存中获取组件实例给vnode,还未缓存过则进行缓存 */ if (this.cache[key]) { vnode.componentInstance = this.cache[key].componentInstance } else { this.cache[key] = vnode } /* keepAlive标记位 */ vnode.data.keepAlive = true } return vnode } } 使用方法
// 我们想要缓存某个组件,只要用keep-alive组件将其包裹就行。// 包裹component组件缓存动态组件,或者包裹router-view缓存路由页面,也就是keep-alive配合路由守卫(元信息)实现缓存。 { path: "/index", name: 'index', component: () => import(/* webpackChunkName: "index" */ '@/pages/index'), meta: { title: '首页', keepAlive: true } }
网络协议
关于http协议
八股文,需要背诵的同学可参考我这篇文档
网络协议常见概念
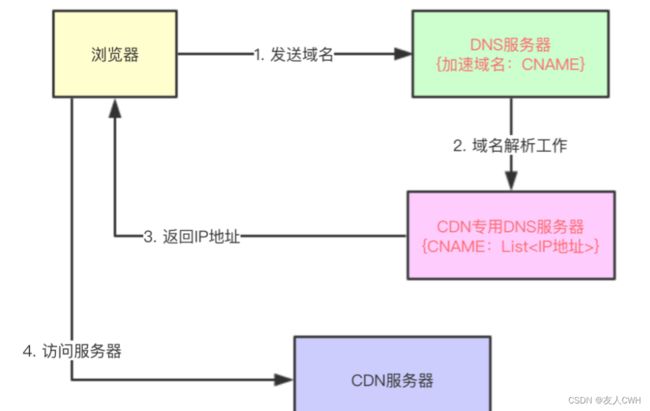
CDN原理
CDN 其实是 Content Delivery Network 的缩写,即“内容分发网络”,它并不是一个网络协议,只是基于 DNS 协议实现的加速功能的网络。(CDN本身就是一种DNS劫持,只不过是良性的。 不同于黑客强制DNS把域名解析到自己的钓鱼IP上,CDN则是让DNS主动配合,把域名解析到临近的服务器上)
CDN是将源站内容分发至全国所有的节点,从而缩短用户查看对象的延迟,提高用户访问网站的响应速度与网站的可用性的技术。它能够有效解决网络带宽小、用户访问量大、网点分布不均等问题。
CDN的原理
域名的权威 DNS 服务器把请求转给 CND 的负载均衡的 DNS 服务器,然后根据 ip返回不同城市的 DNS 服务器,再根据负载来选择一台就近的服务器 的 ip 返回,这样客户端就能从最近的负载最小的服务器拿到资源。
CDN是如何进行处理的
- 当用户点击网站页面上的内容URL,经过本地DNS系统解析,DNS 系统会最终将域名的解析权交给 CNAME 指向的 CDN 专用 DNS 服务器。
- CDN 的 DNS 服务器将 CDN 的全局负载均衡设备 IP 地址返回用户。
- 用户向 CDN 的全局负载均衡设备发起内容 URL 访问请求。
- CDN 全局负载均衡设备根据用户 IP 地址,以及用户请求的内容URL,选择一台用户所属区域的区域负载均衡设备,告诉用户向这台设备发起请求。
- 基于以下这些条件的综合分析之后,区域负载均衡设备会向全局负载均衡设备返回一台缓存服务器的IP地址:
- 根据用户 IP 地址,判断哪一台服务器距用户最近;
- 根据用户所请求的 URL 中携带的内容名称,判断哪一台服务器上有用户所需内容;
- 查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力。
- 全局负载均衡设备把服务器的 IP 地址返回给用户。
- 用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
面试常问
DNS系统怎么在做域名解析时,解析出来一个离用户最近的一个IP地址呢。
普通的DNS系统是做不到的,需要一个特殊的DNS服务器,这个特殊DNS需要知道
- 用户当前所在位置
- 还需要知道用户现在访问的这个域名对应哪些IP地址,以及这个IP地址分别在哪?
第一个问题,直接从用户请求里提取出用户的ip地址,比如这个ip地址被解析为北京电信、上海移动等等。
第二个问题由谁来解决,我们现在考虑的是CDN,CDN提供商肯定知道他们公司在哪些地方部署了机器以及它们的IP地址,所以这个问题只能有CDN提供商来解决,CDN提供商会提供这个特殊的DNS服务器,我们叫做 CDN专用DNS服务器。
只要用户在使用某个域名访问静态资源时,如果用户直接配置自己电脑的DNS地址为CDN专用DNS服务器。那么自然解决了问题,
但是我们需要考虑的是,我们不能要求世界上所有的用户都去修改自己电脑的DNS地址。所以这个时候就要利用DNS中的CNAME了。
用户使用某个域名来访问静态资源时(这个域名在阿里CDN服务中叫做“加速域名”),比如这个域名为“image.baidu.com”,它对应一个CNAME,叫做“cdn.ali.com”,那么普通DNS服务器(区别CDN专用DNS服务器)在解析“image.baidu.com”时,会先解析成“cdn.ali.com”,普通DNS服务器发现该域名对应的也是一个DNS服务器,那么会将域名解析工作转交给该DNS服务器,该DNS服务器就是CDN专用DNS服务器。CDN专用DNS服务器对“cdn.ali.com”进行解析,然后依据服务器上记录的所有CDN服务器地址信息,选出一个离用户最近的一个CDN服务器地址,并返回给用户,用户即可访问离自己最近的一台CDN服务器了。
CDN回源与文件预热
CDN回源
CDN 去源站拉取文件。这个拉取数据的过程就是回源。
常规的CDN都是回源的。当有用户访问某一个URL的时候,如果被解析到的那个 CDN 节点没有缓存响应的内容,或者是缓存已经到期,就会回源站去获取。如果没有人访问,那么 CDN 节点不会主动去源站拿的。
文件预热
首次发布的文件,主动从源站推送到各个 CDN 节点 提前缓存起来,让用户访问到 CDN 时不用回源命中,能快速获取到文件。(预热只支持URL(文件级)进行预热,不支持按目录级预热。原因:预热是首次访问的文件,没有权限能获取到某个文件夹下面有哪些文件。一般各大CDN平台会提供预热功能,按配置填入需要预热的文件即可)
浏览器
各控制面板操作
推荐阅读:
Chrome DevTools 调试指南https://juejin.cn/post/6992388719894331422#heading-26
前端异常监控
推荐阅读:
- 前端异常监控
- 自研异常监控平台
打包工具
Webpack
Webpack的构建流程
webpack 的运行流程是一个串行的过程,它的工作流程就是将各个插件串联起来。在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条webpack机制中,去改变Webpack的运作。
从启动到结束会依次经历三大流程:
- 初始化阶段:从配置文件和 Shell 语句中读取与合并参数,并初始化需要使用的插件和配置插件等执行环境所需要的参数。
- 编译构建阶段:从 Entry 发出,针对每个 Module 串行调用对应的 Loader 去翻译文件内容,再找到该 Module 依赖的 Module,递归地进行编译处理。
- 输出阶段:对编译后的 Module 组合成 Chunk,把 Chunk 转换成文件,输出到文件系统。
tree-shaking 的操作
tree-shaking就是把js文件中无用的模块或者代码删掉。而这通常需要借助一些工具。在webpack中tree-shaking就是在打包时移除掉javascript上下文中无用的代码,从而优化打包的结果。在webpack5中已经自带tree-shaking功能,在打包模式为production时,默认开启 tree-shaking功能,
启动 Tree Shaking 功能必须同时满足三个条件:
使用 ESM 规范编写模块代码
配置
optimization.usedExports为true,启动标记功能启动代码优化功能,可以通过如下方式实现:
配置
mode = production配置
optimization.minimize = true提供
optimization.minimizer数组例如:
// webpack.config.js module.exports = { entry: "./src/index", mode: "production", devtool: false, optimization: { usedExports: true, }, };(如果使用的是webpack2可能你会发现tree-shaking并不起作用,因为bable会将代码编译成Commonjs模块。而tree-shaking不支持commonjs,所以需要配置不转义)
options: { presets: [ ['es2015', {modules: false}] ] }先来介绍一下 commonJS 模块 和 EMS 模块
commonJS 模块
commonJS的模块规范在Node中发扬光大,总的来说,它的特性有这几个:
- 1.动态加载模块
commonJS和es6的最大区别大概就在于此了吧,commonJS模块的动态加载能够很轻松的实现懒加载,优化用户体验。
- 2.加载整个模块
commonJS模块中,导出的是整个模块。
- 3.每个模块皆为对象
commonJS模块都被视作一个对象。
- 4.值拷贝
commonJS的模块输出和 函数的值传递相似,都是值的拷贝
es6 模块
- 1.静态解析
即在解析阶段就确定输出的模块,所以es6模块的import一般写在被引入文件的开头。
- 2.模块不是对象
在es6里,每个模块并不会当做一个对象看待
- 3.加载的不是整个模块
在es6模块中经常会看见一个模块中有好几个export 导出
- 4.模块的引用
es6模块中,导出的并不是模块的值拷贝,而是这个模块的引用
在结合es6模块和commonJS模块的区别之后,我们知道es6的特点是静态解析,而commonJS模块的特点是动态解析的,因此,es6模块的模块之间的依赖关系是高度确定的静态的,与运行状态无关,可以进行可靠的静态分析,因此整个依赖树可以被静态地推导出解析语法树,可以做到在编译时候 分析ESM的模块,可以从代码字面量中推断出哪些模块没有被使用,这就是tree-shaking实现的必要条件。
tree-shaking 实现原理
Webpack 中,Tree-shaking 的实现一是先「标记」出模块导出值中哪些没有被用过,二是使用 Terser 删掉这些没被用到的导出语句。标记过程大致可划分为三个步骤:
Make 阶段,收集模块导出变量并记录到模块依赖关系图 ModuleGraph 变量中(需要配置
optimization.usedExports = true开启)Seal 阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用
生成产物时,若变量没有被其它模块则使用 DCE 工具删除 Dead Code,实现完整的摇树效果
更好地tree-shaking
虽然 Webpack 自 2.x 开始就原生支持 Tree Shaking 功能,但受限于 JS 的动态特性与模块的复杂性,直至最新的 5.0 版本依然没有解决许多代码副作用带来的问题,使得优化效果并不如 Tree Shaking 原本设想的那么完美,所以需要使用者有意识地优化代码结构,或使用一些补丁技术帮助 Webpack 更精确地检测无效代码,完成 Tree Shaking 操作。
- 有意识规避一些不必要的赋值操作
禁止 Babel 转译模块导入导出语句 (Babel 提供的部分功能特性会致使 Tree Shaking 功能失效,例如 Babel 可以将
import/export风格的 ESM 语句等价转译为 CommonJS 风格的模块化语句,但该功能却导致 Webpack 无法对转译后的模块导入导出内容做静态分析)优化导出粒度(即使只用到
default导出值的其中一个属性,整个default对象依然会被完整保留)尽量使用支持 Tree Shaking 的 npm 包(使用
lodash-es替代lodash)更多相关可阅读:Webpack 原理系列九:Tree-Shaking 实现原理
Webpack Loader
Loader本质就是一个函数(函数中的 this 作为上下文会被 webpack 填充,因此我们不能将 loader设为一个箭头函数。该函数接受一个参数,为 webpack 传递给 loader 的文件源内容。),在该函数中对接收到的内容进行转换,返回转换后的结果。因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。
常见的三种方式:
- 配置方式(推荐):在 webpack.config.js文件中指定 loader
- 内联方式:在每个 import 语句中显式指定 loader
- Cli 方式:在 shell 命令中指定它们
loader 支持链式调用(顺序与配置相反),链中的每个loader会处理之前已处理过的资源,最终变为js代码。Loader 可以是同步的,也可以是异步的(异步操作通过 this.callback传递数据,同步操作则直接return数据),可以通过 loader 的预处理函数,为 JavaScript 生态系统提供更多能力。用户现在可以更加灵活地引入细粒度逻辑,例如:压缩、打包、语言翻译和更多其他特性。
常用loader
- style-loader:将css添加到DOM的内联样式标签style里,然后通过 dom 操作去加载 css。 css-loader :允许将css文件通过require的方式引入,并返回css代码。
- less-loader: 处理less,将less代码转换成css。
- sass-loader: 处理sass,将scss/sass代码转换成css。
- postcss-loader:用postcss来处理css。
- autoprefixer-loader: 处理css3属性前缀,已被弃用,建议直接使用postcss。
- file-loader: 分发文件到output目录并返回相对路径。
- url-loader: 和file-loader类似,但是当文件小于设定的limit时可以返回一个Data Url。
- html-minify-loader: 压缩HTML
- babel-loader :用babel来转换ES6文件到ES。
- awesome-typescript-loader:将 TypeScript 转换成 JavaScript,性能优于 ts-loader。 eslint-loader:通过 ESLint 检查 JavaScript 代码。
- tslint-loader:通过 TSLint检查 TypeScript 代码。
- cache-loader: 可以在一些性能开销较大的 Loader 之前添加,目的是将结果缓存到磁盘里
Webpack Plugin
Plugin就是插件,基于事件流框架Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果,从本质上来说,就是一个具有apply方法Javascript对象。apply 方法会被 webpack compiler 调用。
Webpack中的Plugin也是如此,Plugin赋予其各种灵活的功能,例如打包优化、资源管理、环境变量注入等,它们会运行在 Webpack 的不同阶段(钩子 / 生命周期),贯穿了Webpack整个编译周期。
常见plugin
- define-plugin:定义环境变量 (Webpack4 之后指定 mode 会自动配置)
- ignore-plugin:忽略部分文件 - html-webpack-plugin:简化 HTML 文件创建 (依赖于 html-loader)
- web-webpack-plugin:可方便地为单页应用输出 HTML,比 html-webpack-plugin 好用 uglifyjs-webpack-plugin:不支持 ES6 压缩 (Webpack4 以前)
- terser-webpack-plugin: 支持压缩 ES6 (Webpack4)
- webpack-parallel-uglify-plugin: 多进程执行代码压缩,提升构建速度
- mini-css-extract-plugin: 分离样式文件,CSS 提取为独立文件,支持按需加载 (替代extract-text-webpack-plugin)
- serviceworker-webpack-plugin:为网页应用增加离线缓存功能
- clean-webpack-plugin: 目录清理
- ModuleConcatenationPlugin: 开启 Scope Hoisting -speed-measure-webpack-plugin: 可以看到每个 Loader 和 Plugin 执行耗时 (整个打包耗时、每个 Plugin 和 Loader 耗时)
- webpack-bundle-analyzer: 可视化 Webpack 输出文件的体积 (业务组件、依赖第三方模块)
Webpack 热更新
Webpack的热更新又称热替换(Hot Module Replacement),缩写为HMR。这个机制可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
HMR的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 webpack dev server 与浏览器之间维护了一个Websocket,当本地资源发生变化时,WDS 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起Ajax请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起jsonp请求获取该chunk的增量更新。
在Webpack中配置开启热模块也非常的简单,只需要添加如下代码即可。
const webpack = require('webpack') module.exports = { // ... devServer: { // 开启 HMR 特性 hot: true // hotOnly: true } }需要说明的是,实现热更新还需要去指定哪些模块发生更新时进行HRM,因为默认情况下,HRM只对css文件有效。
Webpack热模块的步骤
- -通过webpack-dev-server创建两个服务器:提供静态资源的服务(express)和Socket服务 - express server 负责直接提供静态资源的服务(打包后的资源直接被浏览器请求和解析)
- socket server 是一个 websocket 的长连接,双方可以通信 - 当 socket server 监听到对应的模块发生变化时,会生成两个文件.json(manifest文件)和.js文件(update chunk)
- 通过长连接,socket server 可以直接将这两个文件主动发送给客户端(浏览器)
- 浏览器拿到两个新的文件后,通过HMR runtime机制,加载这两个文件,并且针对修改的模块进行更新
Webpack Proxy 请求代理
在开发阶段, webpack-dev-server 会启动一个本地开发服务器,所以我们的应用在开发阶段是独立运行在 localhost 的一个端口上,而后端服务又是运行在另外一个地址上。所以在开发阶段中,由于浏览器同源策略的原因,当本地访问后端就会出现跨域请求的问题。
解决这种问题时,只需要设置webpack proxy代理即可。当本地发送请求的时候,代理服务器响应该请求,并将请求转发到目标服务器,目标服务器响应数据后再将数据返回给代理服务器,最终再由代理服务器将数据响应给本地。在代理服务器传递数据给本地浏览器的过程中,两者同源,并不存在跨域行为,这时候浏览器就能正常接收数据。
注意:服务器与服务器之间请求数据并不会存在跨域行为,跨域行为是浏览器安全策略限制
Webpack 配置性能优化
- JS代码压缩
- CSS代码压缩
- Html文件代码压缩
- 文件大小压缩
- 图片压缩
- Tree Shaking
- 代码分离
- 内联 chunk
提高Webpack的构建速度
1、优化 Loader 配置
通过配置include、exclude、test属性来匹配文件,通过include、exclude来规定匹配应用的loader
2、合理resolve.extensions
解析到文件时自动添加拓展名,默认情况如下:
module.exports = { ... extensions:[".warm",".mjs",".js",".json"] }当我们引入文件的时候,若没有文件后缀名,则会根据数组内的值依次查找。所以,处理配置的时候,不要随便把所有后缀都写在里面。
3、优化 resolve.modules
resolve.modules 用于配置 webpack 去哪些目录下寻找第三方模块,默认值为['node_modules']。所以,在项目构建时,可以通过指明存放第三方模块的绝对路径来减少寻找的时间。
module.exports = { resolve: { modules: [path.resolve(__dirname, 'node_modules')] // __dirname 表示当前工作目录 }, };4、优化 resolve.alias
alias给一些常用的路径起一个别名,特别当我们的项目目录结构比较深的时候,一个文件的路径可能是./../../的形式,通过配置alias以减少查找过程。
module.exports = { ... resolve:{ alias:{ "@":path.resolve(__dirname,'./src') } } }5、使用 DLL Plugin 插件
DLL全称是动态链接库,是为软件在winodw种实现共享函数库的一种实现方式,而Webpack也内置了DLL的功能,为的就是可以共享,不经常改变的代码,抽成一个共享的库。使用步骤分成两部分: - 打包一个 DLL 库 - 引入 DLL 库
6、合理使用使用 cache-loader
在一些性能开销较大的 loader 之前添加 cache-loader,以将结果缓存到磁盘里,显著提升二次构建速度。比如:
module.exports = { module: { rules: [ { test: /\.ext$/, use: ['cache-loader', ...loaders], include: path.resolve('src'), }, ], }, };需要说明的是,保存和读取这些缓存文件会有一些时间开销,所以请只对性能开销较大的 loader 使用此 loader。
7、开启多线程
开启多进程并行运行可以提高构建速度,配置如下:
module.exports = { optimization: { minimizer: [ new TerserPlugin({ parallel: true, //开启多线程 }), ], }, };来源文章:Webpack常见面试题总结
Module Federation
Webpack5的新特性,模块联邦,可以实现组件级别的模块共享,使应用之间能共享组件开发资源。
根据webpack对模块联邦的描述
Multiple separate builds should form a single application. These separate builds should not have dependencies between each other, so they can be developed and deployed individually.
This is often known as Micro-Frontends, but is not limited to that.
多个独立的构建可以形成一个应用程序。这些独立的构建不会相互依赖,因此可以单独开发和部署它们。
这通常被称为微前端,但并不仅限于此。对比 搬运代码, npm包管理,以及模块联邦的组件复用方案
优点 缺点 搬运代码 cv代码很快
- 可维护行低
- 需要各自维护一套代码
npm包管理更新 传统共享组件的方式,集中到一个组件库中方便管理
- 依赖库、框架重新构建
- 发布更新链路长,所有引用的项目需要重新更新版本、构建、发布
mf组件共享
- 使用组件的项目无需重复构建,更新链路更短,发布了就实时更新
- 编译速度提升,无需重复编译
需要升级Webpack5才能使用 具体如何实现MF
- 首先 MF 应用可以导出一些组件,我们把它叫做一个 container。这个 container 它有一个入口文件,一般叫做 remoteEntry.js,并且 remoteEntry.js 是可以自定义的。它的核心内容主要是两个方法,一个是 get 方法,get 你可以理解为它是这个入口文件里面的组件配置表,MF 资源它导出了哪些组件,它就在 get 方法里面去进行配置,然后你就可以通过这个 get 方法拿到对应的组件资源。
- 另一个是 init 方法,它会去做 shared scope 对象的初始化,将你配置的共享依赖放到 share scope 对象里面去。导出的组件都会分别打包成一个 chunk.js,同时它会去依赖一个 react.js。当访问这个MF组件的时候,它就会把组件的 trunk 以及 react.trunk 一起加载过来。具体的路径:首先是使用项目去加载MF组件,它会先去加载 remoteEntry.js,也就是 container 的入口文件。紧接着,它会去拿到调用 get 方法,再去拿组件具体的 chunk,同时进行 share scope 的创建,以及将 React 放到它本地的 share scope 里面去。
- 如果MF组件和使用MF组件的项目react版本不一致(通过 semver 版本工具库的方式去比较),优先使用MF组件依赖的 React 版本,因为它在执行 init 方法的时候,会去覆盖当前项目的 share scope,将MF组件依赖的 React 版本覆盖掉前台的资源,所以它加载的就是MF组件所依赖的 react.js。
- MF组件的webpack配置需要新增一个 webpack 5 内置的 ModuleFederationPlugin,然后进行这个插件的配置。name 就是导出的资源名称,filename 就是入口文件,exposes 配置是需要导出的组件以及对应的目录,最后再将需要共享依赖的库放到 shared 里去。因为多个版本 React 的运行时实例对于 React 来说是敏感的,一般情况下只能存在一个版本的 React ,所以这里需要将它放到共享依赖里去。如果想要让这个 React 是单例的形式去加载的话,后面还可以再加一个 single time 为 true 的配置。
- 使用项目的webpack也需要新增 webpack 5 内置的 ModuleFederationPlugin,然后配置 remote 远程资源地址,也就是MF组件的 remoteEntry.js的访问地址。使用方式和平常使用的普通 npm 包类似,直接 import 进来就可以了,也可以通过 lazy import 的方式加载进来。
- 更新了MF组件,只需要重新打包发布即可(本身 MF 资源是已经编译过的代码,所以发布MF组件也不需要消耗太多的编译时间),使用了组件的项目因为加载了线上资源,所以会跟着一起更新,这样一来,链路短了很多,实现了实时更新。
项目实操过程:
- 如果使用 MF 的方式来做项目间的组件共享,自然而然就会想到将每一个项目导出的 MF 共享资源集中到一个大池子里面,在这个大池子里面做中心化管理,于是我们就做了一个组件共享平台,让每一个独立的项目都可以发布它的研发资源到这个平台。基于组件共享平台的 MF 共享模式,后台去加载水印组件时就直接去访问了我们的共享平台的资源,前台也是如此,这里和之前的区别只是资源地址变了。另外,基于 MF 平台的组件更新传导链路,其实就是原子组件更新后发布到 MF 平台,依赖 MF 平台资源的两个项目就会实时更新。不再需要本地再重复构建。
- 组件共享平台体系由三个部分构成:
- 首先是一个脚手架工具,称之为 MF-CLI,主要作用是用于本地开发时导入和导出组件库到我们的平台;
- 然后是组件共享平台,主要是存放组件库以及做一些组件的中心化管理;
- 然后是一个 NGINX 转发服务器,它主要做一些跨域处理、缓存处理以及请求转发的工作,这样可以保证目标网站加载资源时是最新的状态。
首先发布一个组件库。用户可以在自己项目的根目录去执行一个 init 命令,然后我们会去生成 mf.config.js,这个 mf.config.js 需要去配置导出的那些组件,再配置一下 Webpack,然后去执行一个 mf export 命令,这样就可以去发布这个组件库。同时组件共享平台会去创建一个组件库,生成一个 OSS 资源,用户就可以通过 NGINX 服务器绑定的对应域名去访问到我们的资源。
那使用资源的时候是怎么做的?首先也是去用户项目的根目录去执行一个 init / import 这个组件库的名称,会拿到对应组件库的配置,之后回来生成 mf.config.js。然后再把远程的组件配置写到 mf.config.js 里面去,再进行一个 webpack 配置,最后你就可以在本地进行开发。当开发去访问这个远程资源的时候,NGINX 服务器在做跨域和缓存的处理,再把相关的资源返回给前端,这就是一个整体的流程。
因为 MF 更新是实时更新,只要发布了就会更新。有时线上的某个 MF 资源非常重要,为了确保发布之后不会出现问题,可以设计个发布控制功能,它可以限制团队里的成员随意发布 MF 资源。在你发布这个组件库的时候,它不会直接去覆盖线上的资源,会先去生成一个测试的 remote,之后它会去消息通知到每一个使用组件库的使用方。使用方拿到这个测试的 remote 就可以根据本地的环境配置,去配置测试环境的 remote,如果测试成功,就可以回到平台进行点击发布上线的按钮,然后去覆盖线上的 remote。为了确保万无一失,我们在覆盖线上 remote 的时候会去生成一个发布记录,这个发布记录你可以将它回滚,如果你发上去后发现有问题,可以拿以前的发布记录再给它回滚一次,它就会把以前的发布内容回滚到线上。
对比其他成熟的微前端框架
比如 qiankun 这种框架,它是以应用级别去进行页面的聚合。MF 则是以 JS 模块这种方式,粒度更细。所以其实也可以去探索基于 MF 的一种微前端的场景。
参考文章:京东零售平台:前端组件资源共享与中心化管理实践
Vite
Webpack基于commonjs,先打包合并然后请求服务器,更改一个模块,其他有依赖关系的模块都会重新打包;
Vite基于es6module,自动向依赖的module发请求,服务端按需编译返回,改动一个模块仅仅会重新请求该模块;
vite基于浏览器原生ES模块导入的开发服务器,在开发环境下,利用浏览器去解析import,在服务器端按需编译返回,完全跳过了打包这个概念,服务器随启随用,当浏览器请求需要的模块时,再对模块进行编译,这种按需动态编译的模式,极大缩短了编译时间,当项目越大,文件越多时,vite的开发时优势越明显。同时不仅对Vue文件提供了支持,还支持热更新,当某个模块内容改变时,让浏览器去重新请求该模块即可,而不是像webpack重新将该模块的所有依赖重新编译,而且热更新的速度不会随着模块增多而变慢。
vite的实现流程
1)通过
koa开启一个服务,获取请求的静态文件内容2)通过
es-module-lexer解析ast拿到import的内容3)判断import 导入模块是否为
三方模块,是的话,返回node_module下的模块, 如import vue返回import './@modules/vue'4)如果是
.vue文件,vite 拦截对应的请求,读取.vue文件内容进行编译,通过compileTemplate编译模板,将template转化为render函数5)通过babel parse对js进行编译,最终返回编译后的js文件
微前端
微前端 - iframe方案
Why Not Iframe
如果不考虑体验问题,iframe 几乎是最完美的微前端解决方案了。
微前端实现的是一个系统集成了多个子应用,这时候就需要考虑到
JS和css的互相影响问题,所以微前端框架很重要的一步就是实现样式隔离、js 隔离。而iframe 最大的特性就是提供了浏览器原生的硬隔离方案,不论是样式隔离、js 隔离这类问题统统都能被完美解决。但他的最大问题也在于他的隔离性无法被突破,导致应用间上下文无法被共享,随之带来的开发体验、产品体验的问题。优点:
- 非常简单,使用没有任何心智负担。
- 隔离完美,无论是 js、css、dom 都完全隔离开来。
- 多应用激活,页面上可以摆放多个iframe来组合业务。
缺点:
- 路由状态丢失,刷新一下,iframe 的 url 状态就丢失了。
- dom 割裂严重,弹窗只能在 iframe 内部展示,无法覆盖全局。
- 通信非常困难,只能通过 postmessage 传递序列化的消息。
- 白屏时间太长,对于SPA 应用应用来说无法接受。
实际项目中使用可以参考这篇文章 微前端实现方案之iframe
微前端 - qiankun 方案
- 基于
single-spa封装,提供了更加开箱即用的 API- 技术栈无关,任意技术栈的应用均可 使用/接入,不论是 React/Vue/Angular/JQuery 还是其他等框架
- HTML Entry 接入方式,让你接入微应用像使用 iframe 一样简单
- 样式隔离,确保微应用之间样式互相不干扰
- JS 沙箱,确保微应用之间 全局变量/事件 不冲突
- 资源预加载,在浏览器空闲时间预加载未打开的微应用资源,加速微应用打开速度
- umi 插件,提供了 @umijs/plugin-qiankun 供 umi 应用一键切换成微前端架构系统 除了最后一点拓展以外,微前端想要达到的效果都已经达到。
拓展知识:
什么是HTML Entry?
直接将子应用打出来 HTML 作为入口,主框架可以通过 fetch html 的方式获取子应用的静态资源,同时将 HTML document 作为子节点塞到主框架的容器中。这样不仅可以极大的减少主应用的接入成本,子应用的开发方式及打包方式基本上也不需要调整,而且可以天然的解决子应用之间样式隔离的问题。
例如:
framework.registerApp('subApp1', { entry: '//abc.alipay.com/index.html'})本质上这里 HTML 充当的是应用静态资源表的角色,在某些场景下,我们也可以将 HTML Entry 的方案优化成 Config Entry,从而减少一次请求,如:
framework.registerApp('subApp1', { html: '', scripts: ['//abc.alipay.com/index.js'], css: ['//abc.alipay.com/index.css'] })
微前端 - YY EMP方案
- 基于Module Federation的能力,实现一个去中心化的应用部署群:每个应用是单独部署在各自的服务器,每个应用都可以引用其他应用,也能被其他应用所引用,即每个应用可以充当host的角色,亦可以作为remote出现,无中心应用的概念,【达到第三方依赖共享,减少不必要的代码引入的目的】。
- 每个微应用独立部署运行,export 导出为 MF 使用,并通过cdn的方式引入主程序中,因此只需要部署一次,便可以提供给任何基于
Module Federation的应用使用。并且此部分代码是远程引入,无需参与应用的打包,【引入的远程应用是编译后的包,可以直接使用,减少主程序的编译时间】。- 动态更新微应用:
EMP是通过cdn加载微应用,因此每个微应用中的代码有变动时,无需重新打包发布新的整合应用便能加载到最新的微应用。【相比npm更新包的版本,更加简便,流程链路更短】- 跨技术栈组件式调用,提供了在主应用框架中可以调用其他框架组件的能力。
- 按需加载,开发者可以选择只加载微应用中需要的部分,而不是强制只能将整个应用全部加载【提供模块名称配置,根据配置匹配此编译中请求的模块】。
- 应用间通信,每一个应用都可以进行状态共享,就像在使用npm模块进行开发一样便捷。
- 生成对应技术栈模板,它能像
create-react-app一样,也能像create-vue-app一样,通过指令一键搭建好开发环境,减少开发者的负担。远程拉取ts声明文件,emp-cli中内置了拉取远程应用中代码声明文件的能力,让使用ts开发的开发者不再为代码报错而烦恼。【配套工具完善】
微前端 - 各种方案对比
原文链接《对比多种微前端方案》

其他
前端模块化
NodeJS之前,由于没有过于复杂的开发场景,前端是不存在模块化的,后端才有模块化。NodeJS诞生之后,它使用CommonJS的模块化规范。从此,js模块化开始快速发展。
模块化的进化过程
- 全局function模式 : 将不同的功能封装成不同的全局函数
作用: 将不同的功能封装成不同的全局函数
问题: 污染全局命名空间, 容易引起命名冲突或数据不安全,而且模块成员之间看不出直接关系
function m1(){ //... } function m2(){ //... }
- namespace模式 : 简单对象封装
作用: 减少了全局变量,解决命名冲突
问题: 数据不安全(外部可以直接修改模块内部的数据)
let myModule = { data: 'www.baidu.com', foo() { console.log(`foo() ${this.data}`) }, bar() { console.log(`bar() ${this.data}`) } } myModule.data = 'other data' //能直接修改模块内部的数据 myModule.foo() // foo() other data
- IIFE模式:匿名函数自调用(闭包)
作用: 数据是私有的, 外部只能通过暴露的方法操作
编码: 将数据和行为封装到一个函数内部, 通过给window添加属性来向外暴露接口
问题: 如果当前这个模块依赖另一个模块怎么办?
// module.js文件 (function(window) { let data = 'www.baidu.com' //操作数据的函数 function foo() { //用于暴露有函数 console.log(`foo() ${data}`) } function bar() { //用于暴露有函数 console.log(`bar() ${data}`) otherFun() //内部调用 } function otherFun() { //内部私有的函数 console.log('otherFun()') } //暴露行为 window.myModule = { foo, bar } //ES6写法 })(window) // index.html文件
- IIFE模式增强 : 可引入依赖
这就是现代模块实现的基石
// module.js文件 (function(window, $) { let data = 'www.baidu.com' //操作数据的函数 function foo() { //用于暴露有函数 console.log(`foo() ${data}`) $('body').css('background', 'red') } function bar() { //用于暴露有函数 console.log(`bar() ${data}`) otherFun() //内部调用 } function otherFun() { //内部私有的函数 console.log('otherFun()') } //暴露行为 window.myModule = { foo, bar } })(window, jQuery) // index.html文件引入多个