JavaWeb19-线程安全&非安全容器
目录
1.非线程安全容器
2.线程安全容器
3.关于HashMap
PS:HashMap常考知识点:
3.1.HashMap 是线程不安全的,其主要体现:
3.1.1.死循环问题——形成的原因是头插法 + 链表 + 多线程并发 + HashMap 扩容。
3.1.2.数据覆盖问题
3.1.3.无序性问题
3.2.线程安全字典
3.2.1.Hashtable
3.2.2.ConcurrentHashMap
1.非线程安全容器
Java 标准库中很多都是线程不安全的,这些类可能会涉及到多线程修改共享数据,⼜没有任何加锁措施。
- ArrayList -> 可换为Vector (不推荐使⽤) /借助锁
- LinkedList
- HashMap -> 可换为ConcurrentHashMap / Hashtable (不推荐直接使⽤)
- TreeMap
- HashSet
- TreeSet
- StringBuilder -> 可换为StringBuffer
2.线程安全容器
- Vector (不推荐使⽤,性能低)
- Hashtable (不推荐使⽤,是给整个方法全部加了synchronized锁,锁的粒度太大,性能比较低)
- ConcurrentHashMap(并不是给整个方法加锁,性能较高些)
- StringBuffer
3.关于HashMap
PS:HashMap常考知识点:
- 底层数据结构实现。
- 负载因子/扩充因子作用。
- 哈希冲突是如何解决的?
- 是否是线程安全的?为什么?
- 如何解决线程安全问题?①加锁;②使用ConcurrentHashMap来替代HashMap。
- ConcurrentHashMap是如何实现线程安全的?
3.1.HashMap 是线程不安全的,其主要体现:
- 在 jdk 1.7 中,在多线程环境下,扩容时因为采⽤头插法,会造成环形链(死循环)或数据丢失(数据覆盖)。
- 在 jdk 1.8 中,在多线程环境下,会发⽣数据覆盖的情况。
3.1.1.死循环问题——形成的原因是头插法 + 链表 + 多线程并发 + HashMap 扩容。
HashMap jdk 1.7 扩容核⼼源码:
void transfer(KeyStore.Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//通过 key 值的 hash 值和新数组的⼤⼩算出在当前数组中的存放位置
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
} 前置知识:
在JDK1.7中HashMap的底层数据实现是数组+链表的方式:
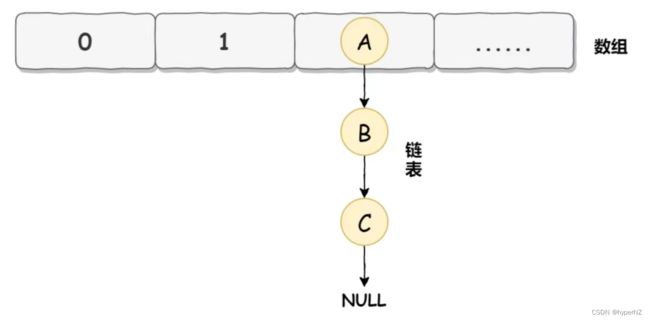
而HashMap在数据添加时使用的是头插入:
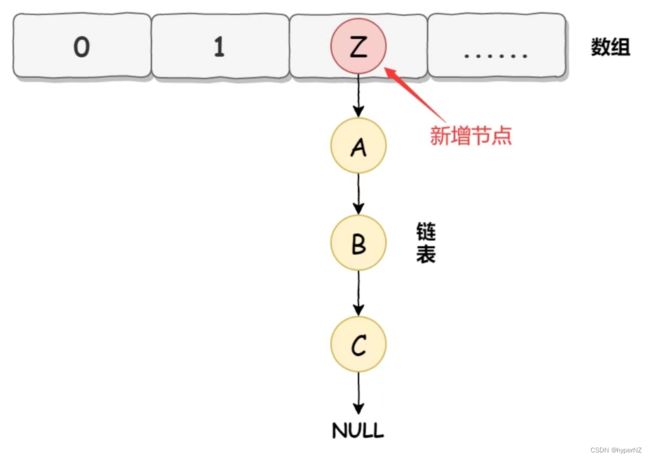
HashMap正常情况下的扩容实现:
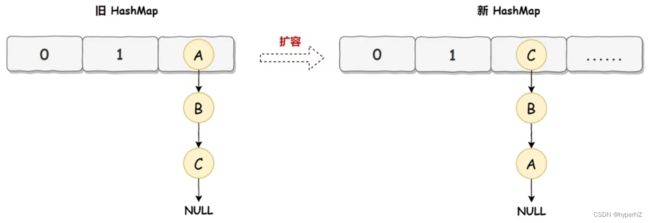
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A。
死循环执行步骤1
死循环是因为并发 HashMap 扩容导致的。线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点:
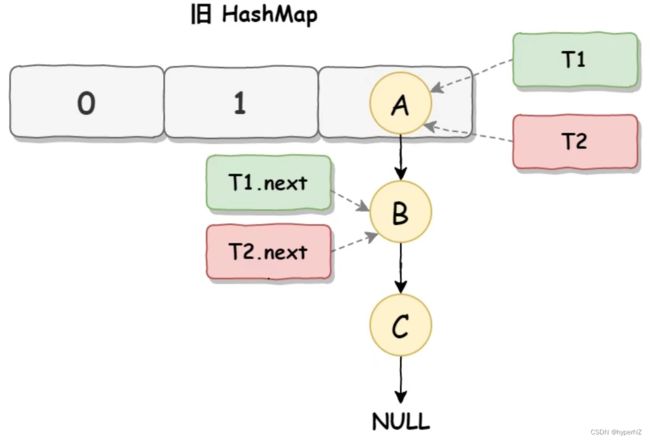
死循环执行步骤2
线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,线程 T1 扩容完成后,因为是头插法,所以 HashMap 的顺序已经发生了改变;而线程 T2 才被唤醒,线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变:
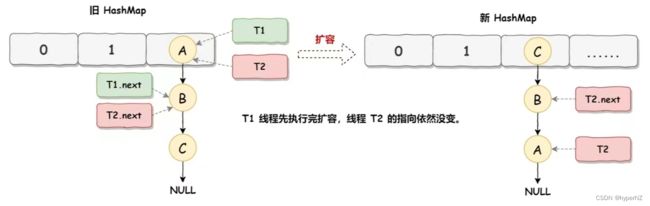
死循环执行步骤3
当线程T1执行完,而线程T2恢复执行时:T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了:
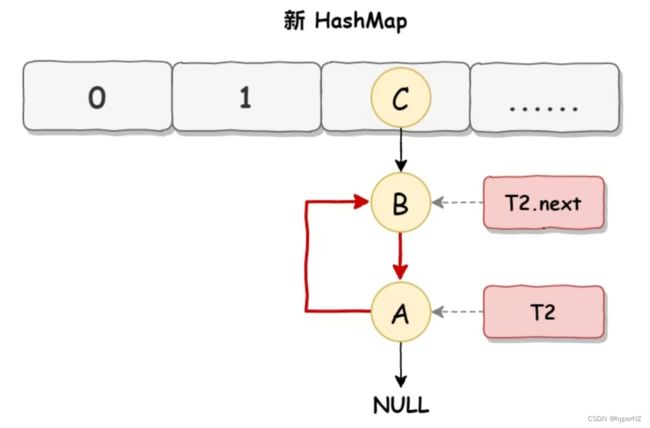
HashMap 死循环的常用解决方案有以下 3 个:
- 使用线程安全容器 ConcurrentHashMap 替代(推荐使用此方案)。
- 使用线程安全容器 Hashtable 替代(性能低,不建议使用)。
- 使用 synchronized 或 Lock 加锁 HashMap 之后,再进行操作,相当于多线程排队执行(比较麻烦,也不建议使用)。
3.1.2.数据覆盖问题
数据覆盖执行步骤1
线程 T1 判断某个位置可插入元素,准备将数据 k1:v1 插入到 Null 处,但还没有真正插入,自己的时间片就用完了,进入休眠状态:
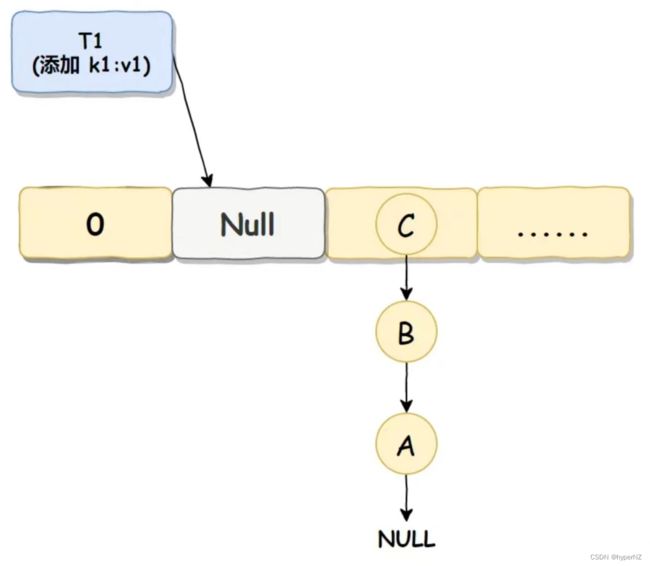
数据覆盖执行步骤2
线程 T2 准备将数据 k2:v2 插入到 Null 处(T2产生的哈希值和T1相同),因为此处现在并未有值,如果此处有值,它会使用链式法将数据插入到下一个没值的位置上,但判断之后发现此处并未有值,那么就直接进行数据插入了:
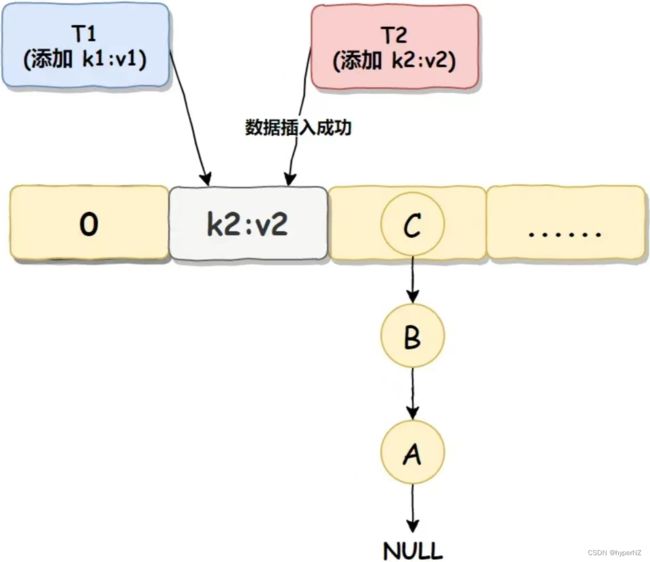
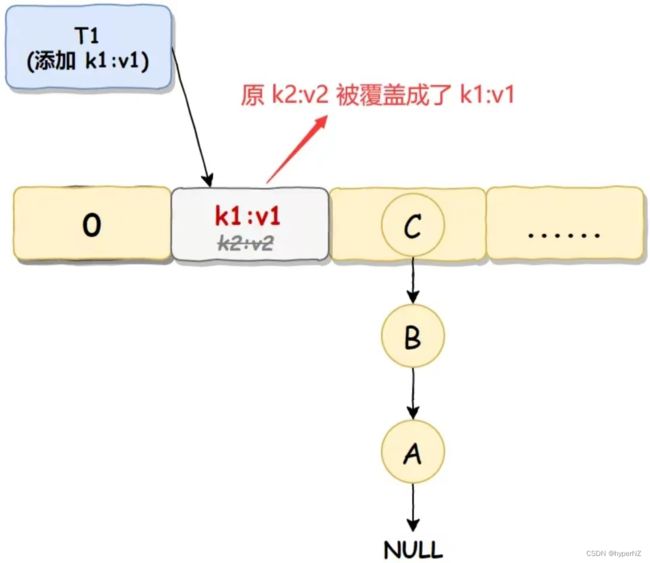
数据覆盖执行步骤3
线程 T2 执行完成之后,线程 T1 恢复执行,因为线程 T1 之前已经判断过此位置没值了,它感知不到现在此位置已经有值了,所以会直接插入,此时线程 T2 插入的值就被覆盖了:
解决方案:
使用ConcurrentHashMap来代替HashMap。
3.1.3.无序性问题
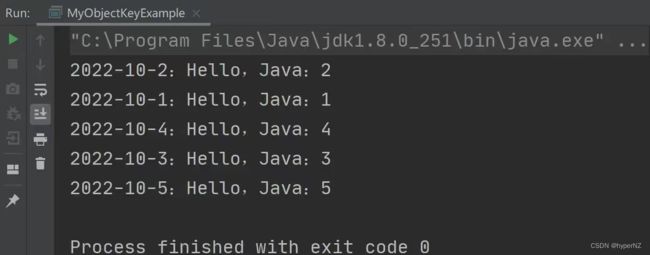
这里的无序性问题指的是 HashMap 添加和查询的顺序不一致,导致程序执行的结果和程序员预期的结果不相符:
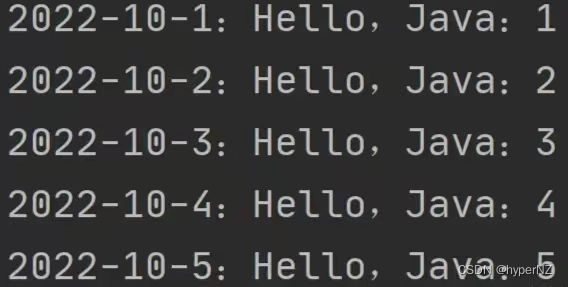
HashMap map = new HashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
}); 添加的顺序:
输出结果:
解决方案:
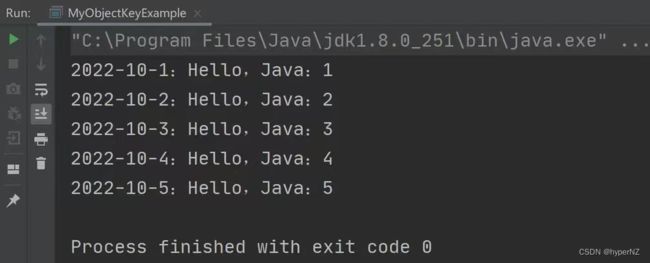
只需将HashMap替换成LinkedHashMap即可。
LinkedHashMap map = new LinkedHashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
}); 
小结:
HashMap 的3个经典问题:其中死循环和数据覆盖是发生在并发添加元素时,而无序问题是添加元素的顺序和查询的顺序不一致的问题。
这些问题本质来说都是对 HashMap 使用不当才会造成的问题,比如在多线程情况下就应该使用 ConcurrentHashMap,想要保证插入顺序和查询顺序一致就应该使用 LinkedHashMap。
3.2.线程安全字典
- Hashtable
- ConcurrentHashMap
3.2.1.Hashtable
- 如果多线程访问同⼀个 Hashtable 就会直接造成锁冲突。
- size 属性也是通过 synchronized 来控制同步,也是⽐较慢的。
- ⼀旦触发扩容,就由该线程完成整个扩容过程。这个过程会涉及到⼤量的元素拷⻉,效率会⾮常低。
3.2.2.ConcurrentHashMap
ConcurrentHashMap 是 HashMap 的多线程版本,HashMap 在并发操作时会有各种问题,比如死循环、数据覆盖等问题。而这些问题只要使用 ConcurrentHashMap 就可以完美解决了,那么 ConcurrentHashMap 是如何保证线程安全的?
JDK 1.7 底层实现
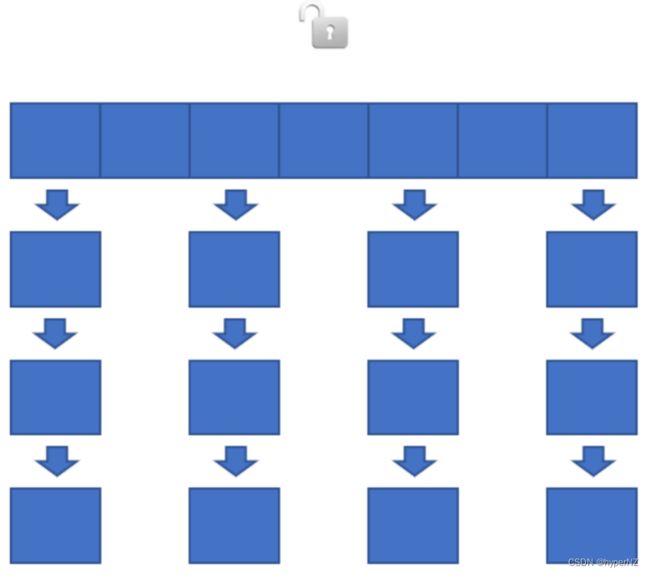
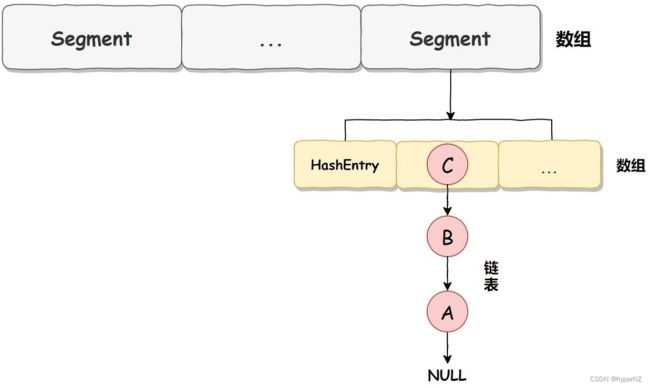
ConcurrentHashMap 在不同的 JDK 版本中实现是不同的,在 JDK 1.7 中它使用的是数组+链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。 大数组 Segment 可以理解为 MySQL 中的数据库,而每个数据库(Segment)中又有很多张表 HashEntry,每个 HashEntry 中又有多条数据,这些数据是用链表连接的:
JDK 1.7 线程安全实现
了解了 ConcurrentHashMap 的底层实现,再看它的线程安全实现就比较简单了。 接下来,我们通过添加元素 put 方法,来看 JDK 1.7 中 ConcurrentHashMap 是如何保证线程安全的,具体实现源码如下:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 Segment 写入前,先确保获取到锁
HashEntry node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
// Segment 内部数组
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
// 更新已有值...
} else {
// 放置 HashEntry 到特定位置,如果超过阈值则进行 rehash
// 忽略其他代码...
}
}
} finally {
// 释放锁
unlock();
}
return oldValue;
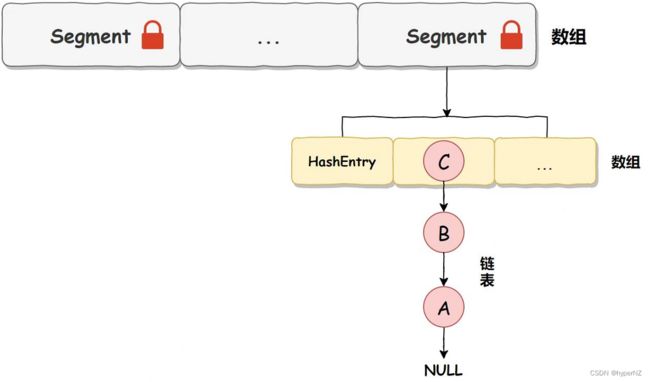
} 从上述源码可以看出,Segment 本身是基于 ReentrantLock 实现的加锁和释放锁的操作,这样就能保证多个线程同时访问 ConcurrentHashMap 时,同一时间只有一个线程能操作相应的节点,这样就保证了 ConcurrentHashMap 的线程安全了。 也就是说 ConcurrentHashMap 的线程安全是建立在 Segment 加锁的基础上的,所以我们把它称之为分段锁或片段锁,如下图所示:
JDK 1.8 底层实现
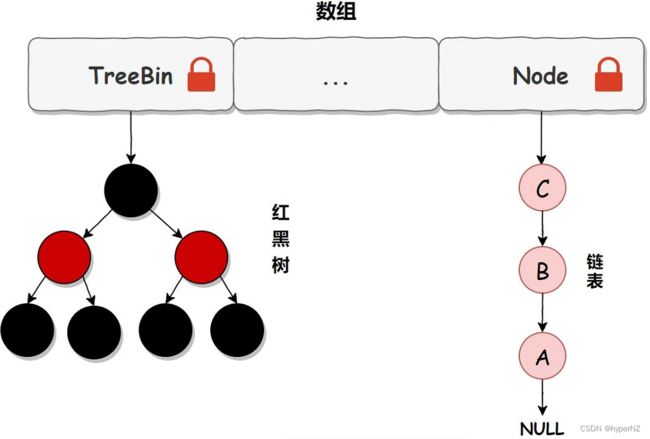
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的,因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下:
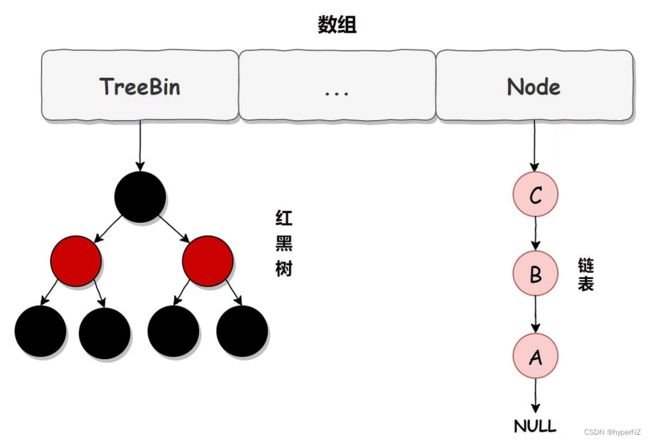
链表升级为红黑树的规则:当链表长度大于 8,并且数组的长度大于 64 时,链表就会升级为红黑树的结构。
PS:ConcurrentHashMap 在 JDK 1.8 虽然保留了 Segment 的定义,但这仅仅是为了保证序列化时的兼容性,不再有任何结构上的用处了。
JDK 1.8 线程安全实现
在 JDK 1.8 中 ConcurrentHashMap 使用的是 CAS + volatile 或 synchronized 的方式来保证线程安全的,它的核心实现源码如下:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 节点为空
// 利用 CAS 去进行无锁线程安全操作,如果 bin 是空的
if (casTabAt(tab, i, null, new Node(hash, key, value)))
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
}
}
// 如果超过阈值,升级为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
} 从上述源码可以看出,在 JDK 1.8 中,添加元素时首先会判断容器是否为空,如果为空则使用 volatile 加 CAS 来初始化。如果容器不为空则根据存储的元素计算该位置是否为空,如果为空则利用 CAS 设置该节点;如果不为空则使用 synchronize 加锁,遍历桶中的数据,替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。 我们把上述流程简化一下,我们可以简单的认为在 JDK 1.8 中,ConcurrentHashMap 是在头节点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了。而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度,具体加锁示意图如下:
总结
ConcurrentHashMap 在 JDK 1.7 时使用的是数据加链表的形式实现的,其中数组分为两类:大数组 Segment 和小数组 HashEntry,而加锁是通过给 Segment 添加 ReentrantLock 锁来实现线程安全的。
而 JDK 1.8 中 ConcurrentHashMap 使用的是数组+链表/红黑树的方式实现的,它是通过 CAS 或 synchronized 来实现线程安全的,并且它的锁粒度更小,查询性能也更高。